一、Introduction of Hadoop Shell Commands(Hadoop Shell 命令简介)
Hadoop 分布式文件系统(HDFS)是一种分布式文件系统,基于“一次写入,多次读取”的理念,具有高容错性和高吞吐量。DataNode 负责处理来自文件系统客户端的读写请求。
HDFS 拥有自己的 shell 命令来管理 HDFS 上的文件。且文件的内容无法通过 Linux 命令识别。
1、Top Hadoop Shell Commands(常用的 Hadoop Shell 命令)
HDFS 是通过一组 Shell 命令来访问的,借助这些命令,我们可以执行 HDFS 文件操作,例如移动文件、删除文件、更改文件权限、设置副本因子、更改文件所有权等。

Hadoop 基本命令:查看和创建文件及目录:
| 命令语法 | 示例 | 功能说明 |
|---|---|---|
| hdfs dfs -ls | hdfs dfs -ls / | 列出指定路径下的所有文件和目录。使用 -lsr 进行递归列出,适用于查看目录层级结构。 |
| hdfs dfs -mkdir | hdfs dfs -mkdir /Ezekielx | 创建一个新目录。Hadoop 默认没有用户主目录,因此需要手动创建。 |
| hdfs dfs -touchz | hdfs dfs -touchz /Ezekielx/file.txt | 创建一个空文件(zero-length)。如果文件不存在,则创建;存在则更新访问和修改时间戳。 |
| hdfs dfs -touch | hdfs dfs -touch /Ezekielx/file.txt | 同上,与 touchz 类似,也用于创建空文件并更新时间戳。 |
| hdfs dfs -cat | hdfs dfs -cat /Ezekielx/file.txt | 打印文件内容到标准输出,相当于“读取”文件。 |
| hdfs fs -tail [-f] | hdfs fs -tail /Ezekielx | 输出文件最后 1KB 内容,-f 可用于持续追踪文件更新(类似 Linux 的 tail -f)。 |
| hdfs fs -test -[ezd] | hdfs fs -test -e /Ezekielx/file.txt | 测试文件或目录状态: - -e:判断是否存在; - -z:是否为空文件; - -d:是否为目录。返回 0 表示真,1 表示假。 |
| hdfs fs -text | hdfs fs -text /Ezekielx/file.txt | 将文件内容以文本形式输出,仅支持某些压缩格式(如 zip、TextRecordInputStream)。 |
计数和大小命令:查看目录或文件的总数及其大小。
| 命令语法 | 示例 | 功能说明 |
|---|---|---|
| hdfs dfs -count | hdfs dfs -count /Ezekielx | 统计 HDFS 上目录数量、文件数量及文件大小。 |
| hdfs dfs -du | hdfs dfs -du /Ezekielx | 显示目录中每个文件的大小。 |
| hdfs dfs -dus | hdfs dfs -dus /Ezekielx | 显示目录或文件的总大小。 |
| hadoop fs -du hdfs://master:54310/hbase | hadoop fs -du hdfs://master:54310/hbase | 查看指定路径下所有 hbase 文件的大小。 |
复制和移动命令
| 命令语法 | 示例 | 功能说明 |
|---|---|---|
| hdfs dfs -put | hdfs dfs -put /tools/file.txt /Ezekielx | 从本地磁盘复制文件/文件夹到 HDFS。指定本地路径和 HDFS 目标路径。 |
| hdfs dfs -copyFromLocal | hdfs dfs -copyFromLocal /tools/file.txt /Ezekielx | 同 put 命令,从本地文件系统复制文件/文件夹到 HDFS。 |
| hdfs dfs -copyToLocal | hdfs dfs -copyToLocal /Ezekielx /tools/hero | 从 HDFS 复制文件/文件夹到本地文件系统。 |
| hdfs dfs -moveFromLocal | hdfs dfs -moveFromLocal /tools/file.txt /Ezekielx | 将本地文件移动到 HDFS,移动后本地文件删除。 |
| hdfs dfs -cp | hdfs dfs -cp /Ezekielx /Ezekielx_copied | 在 HDFS 内部复制文件。 |
| hadoop fs -getmerge [addnl] | — | 将源目录内所有文件合并成一个文件并复制到本地。可选参数 addnl 表示每个文件末尾添加换行符。 |
删除命令
| 命令语法 | 示例 | 功能说明 |
|---|---|---|
| hdfs dfs -rmr | hdfs dfs -rmr /Ezekielx_copied | 递归删除 HDFS 中的文件或目录,适用于删除非空目录,会先删除目录内所有内容,然后删除目录本身。 |
| hdfs dfs -rm | hdfs dfs -rm /Ezekielx/file.txt | 删除 HDFS 中的文件或目录。 |
| hdfs dfs -rmdir | hdfs dfs -rmdir /Ezekielx | 删除空目录,仅当目录为空时才能删除。 |
| hdfs fs -expunge | — | 清空回收站,永久删除已删除文件。 |
二、HDFS Read and Write Architecture(HDFS 读写架构)
HDFS 遵循“只写一次,多次读取”的理念。我们来看一下在 HDFS 上是如何执行数据的读写操作的。因此,HDFS 中已存储的文件无法被编辑,但可以通过重新打开文件来追加新数据。
1、HDFS Write Architecture(HDFS 写入架构)
要向 HDFS 写入数据,客户端首先会与 NameNode 交互,以获取写入数据的权限,并获得用于写入数据的 DataNode 的 IP 地址。
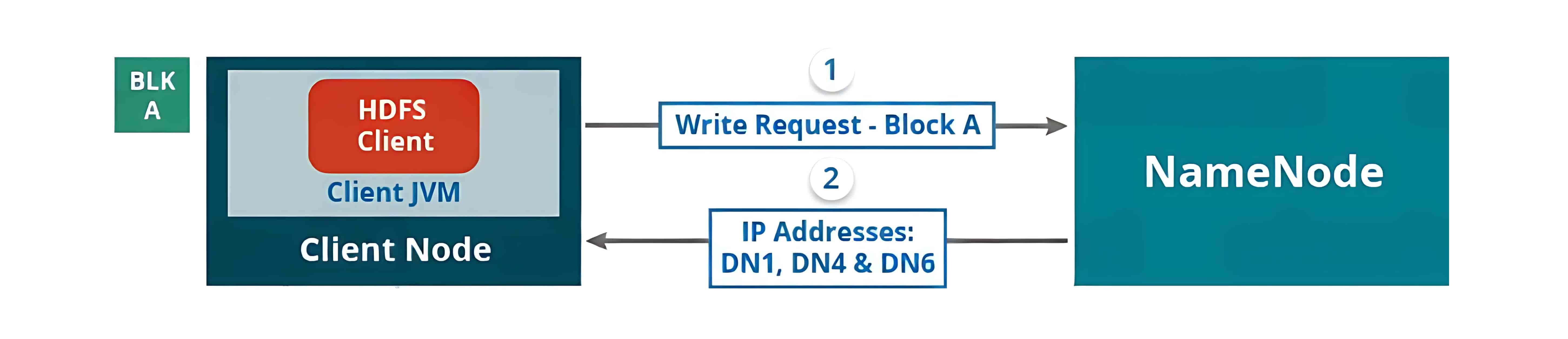
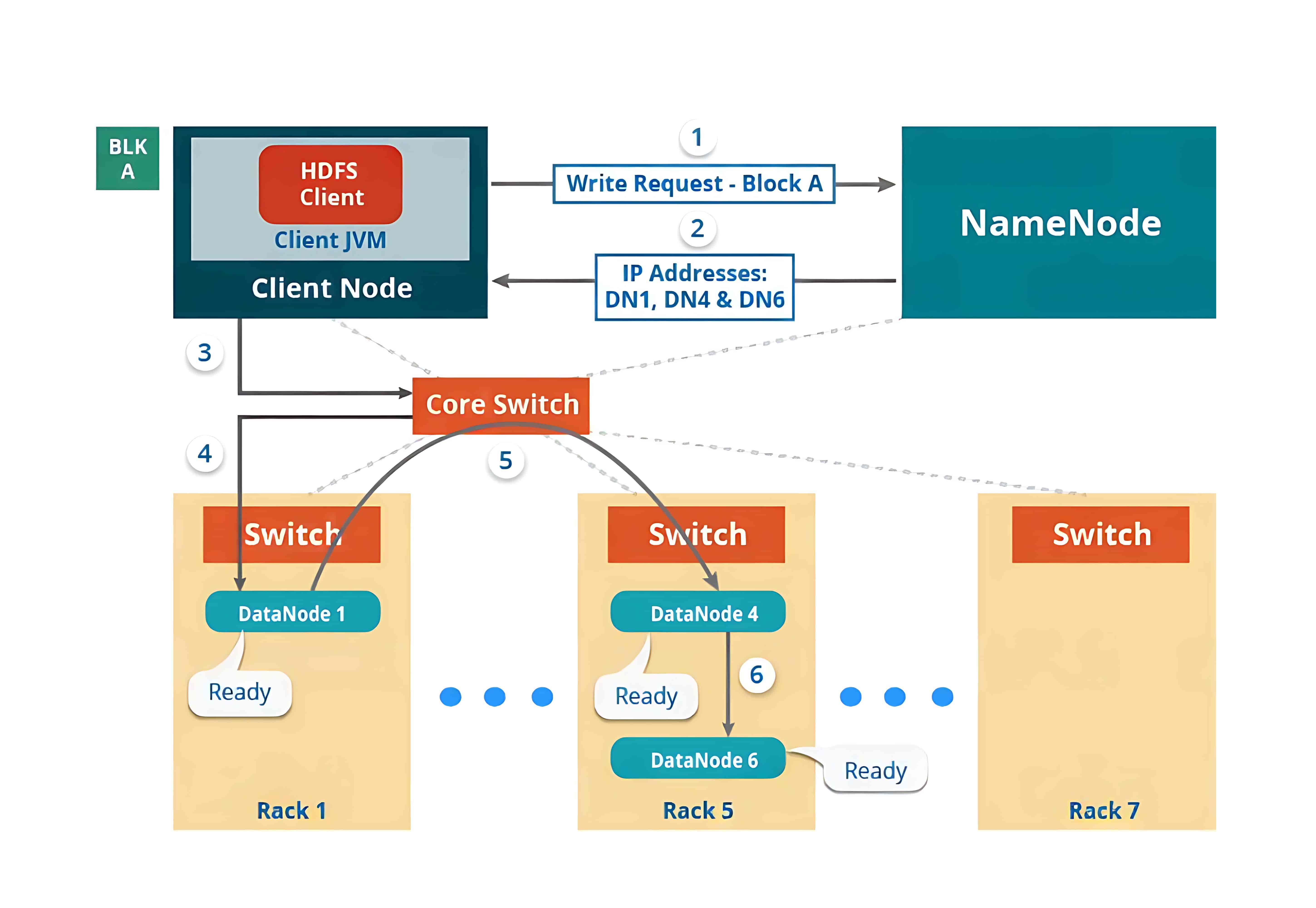
随后,客户端会直接与 DataNode 交互以写入数据。DataNode 根据副本因子(replication factor),将数据块复制到管道中的其他 DataNode。如果副本因子为 3,那么在不同的 DataNode 上至少会创建 3 个数据块副本。
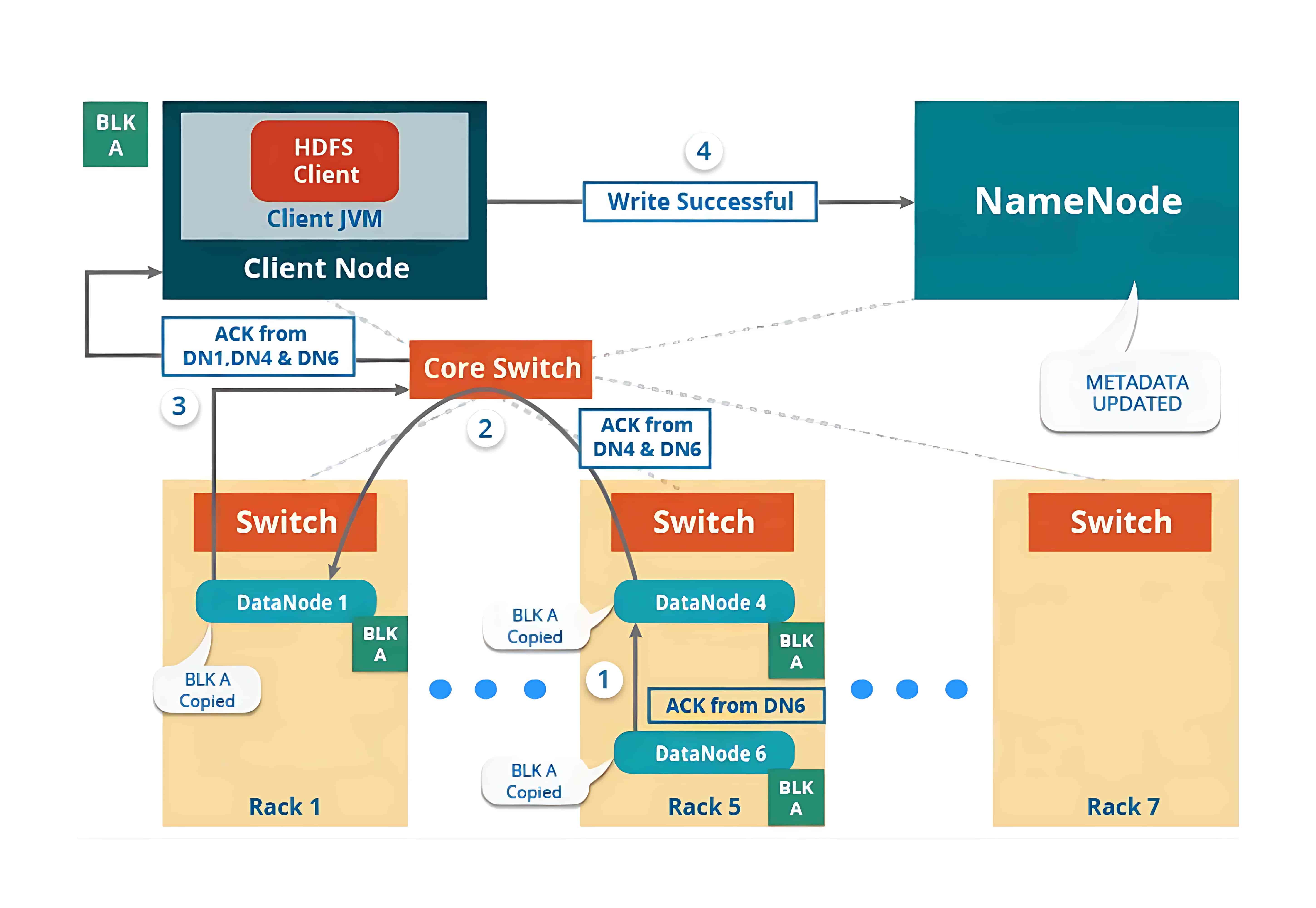
在创建完所需的副本之后,系统会向客户端发送确认信息。这样就在集群中形成了一个数据写入的管道,并将数据复制到设定的副本数量。
2、HDFS Read Architecture(HDFS 读取架构)
HDFS 的读取架构相对来说比较容易理解。我们继续以上面的例子,即 HDFS 客户端想要读取一个文件的情况。读取文件时将会发生以下几个步骤:
- 客户端会向 NameNode 请求该文件的块(Block)元数据信息;
- NameNode 会返回存储该文件各个数据块(如 Block A 和 Block B)所在的 DataNode 列表;
- 然后客户端会连接到这些存储块的 DataNode;
- 客户端会并行地从这些 DataNode 中读取数据(比如从 DataNode1 读取 Block A,从 DataNode3 读取 Block B);
- 当客户端获取到所有所需的数据块后,会将这些块组合起来还原成完整的文件。
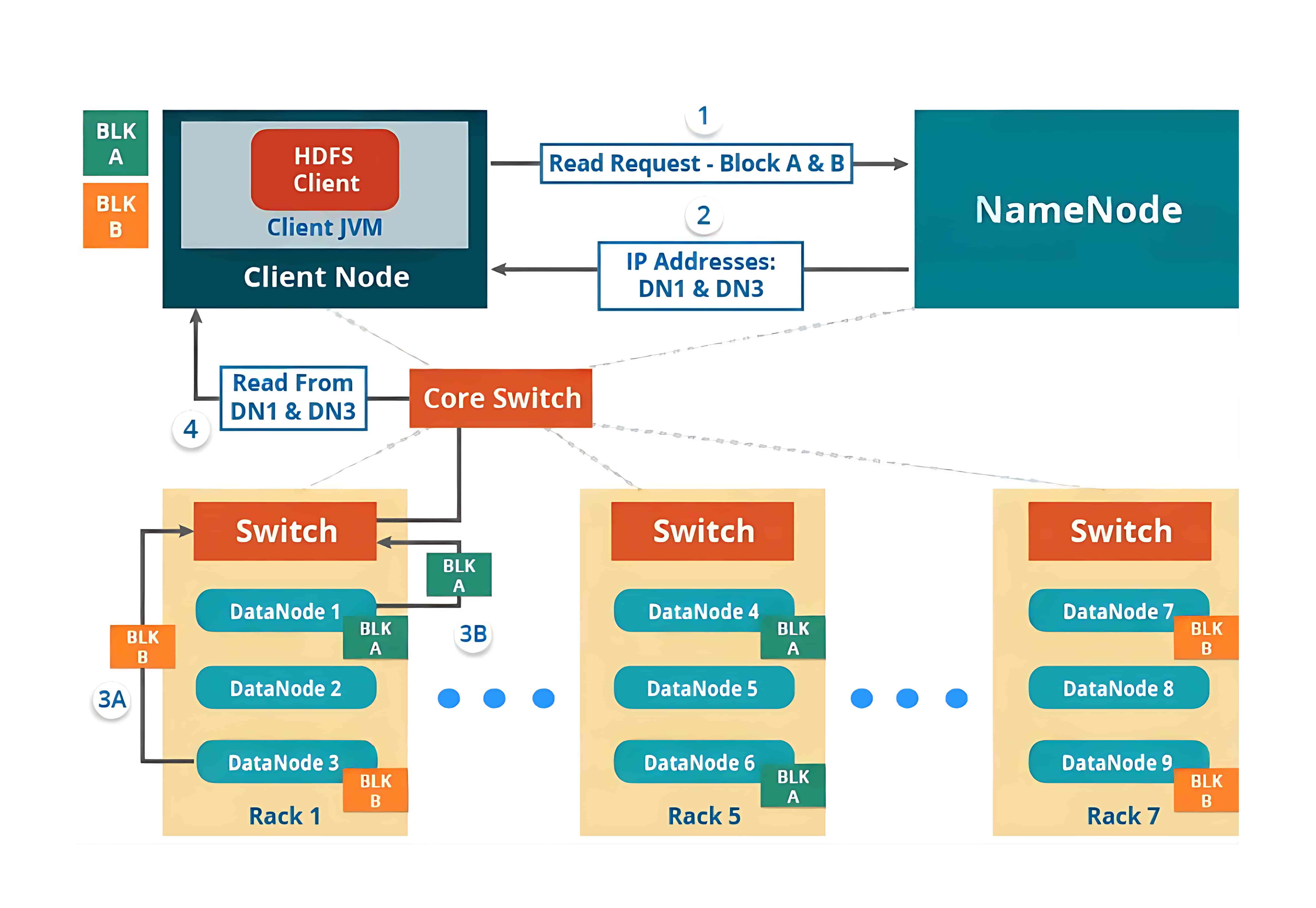
在处理客户端的读取请求时,HDFS 会选择距离客户端最近的副本。这样可以减少读取延迟和带宽消耗。
三、JAVA Application Interface HDFS Operations(Java 应用程序接口的 HDFS 操作)
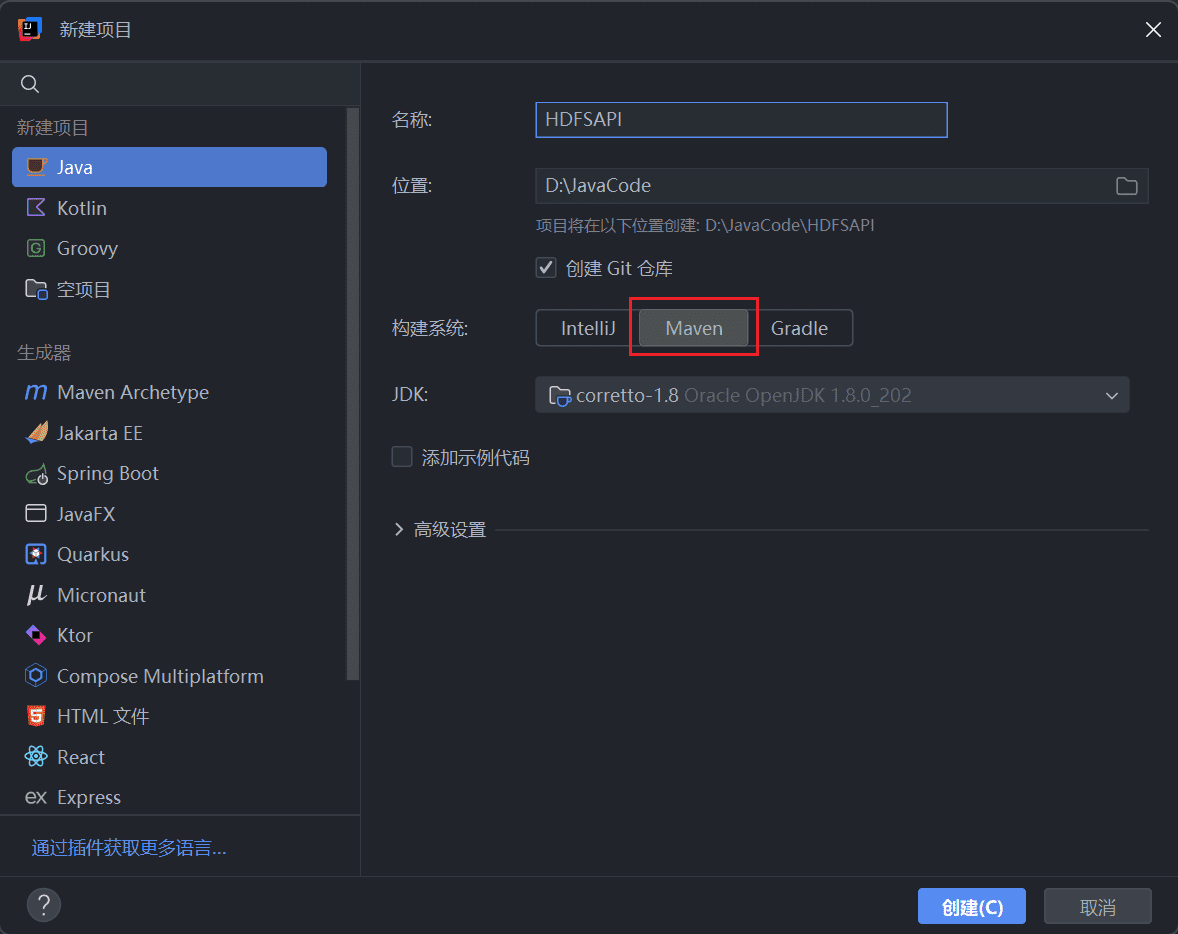
1、创建 Maven 项目
下面将介绍通过 Java 应用程序接口来对 HDFS 进行的一系列操作。
打开 IDEA,选择构建一个 Maven 项目。
进入 maven 官方官网,分别搜索 hadoop-common、hadoop-hdfs,选择对应的 Hbase 版本,将依赖配置复制下来。
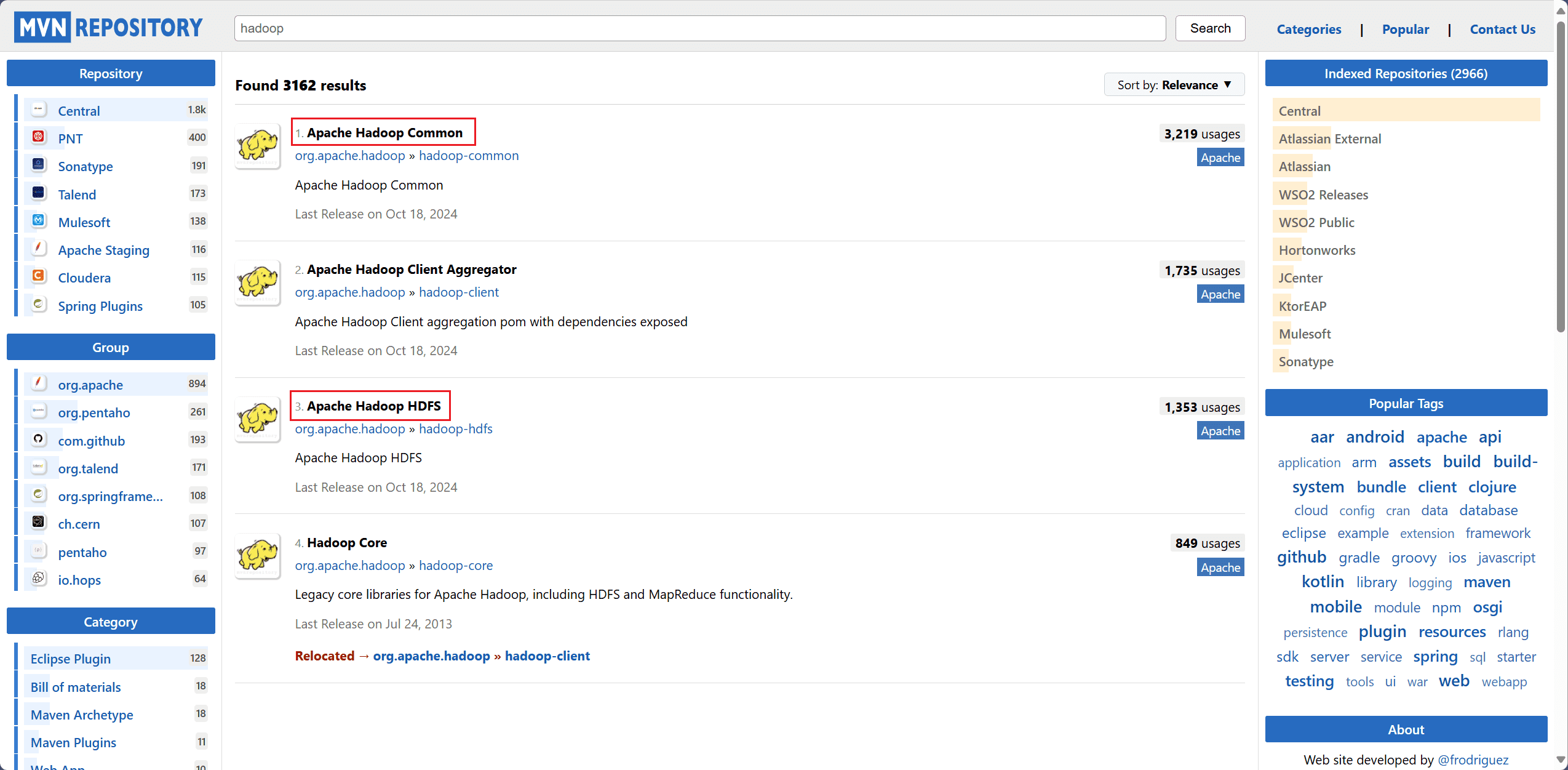
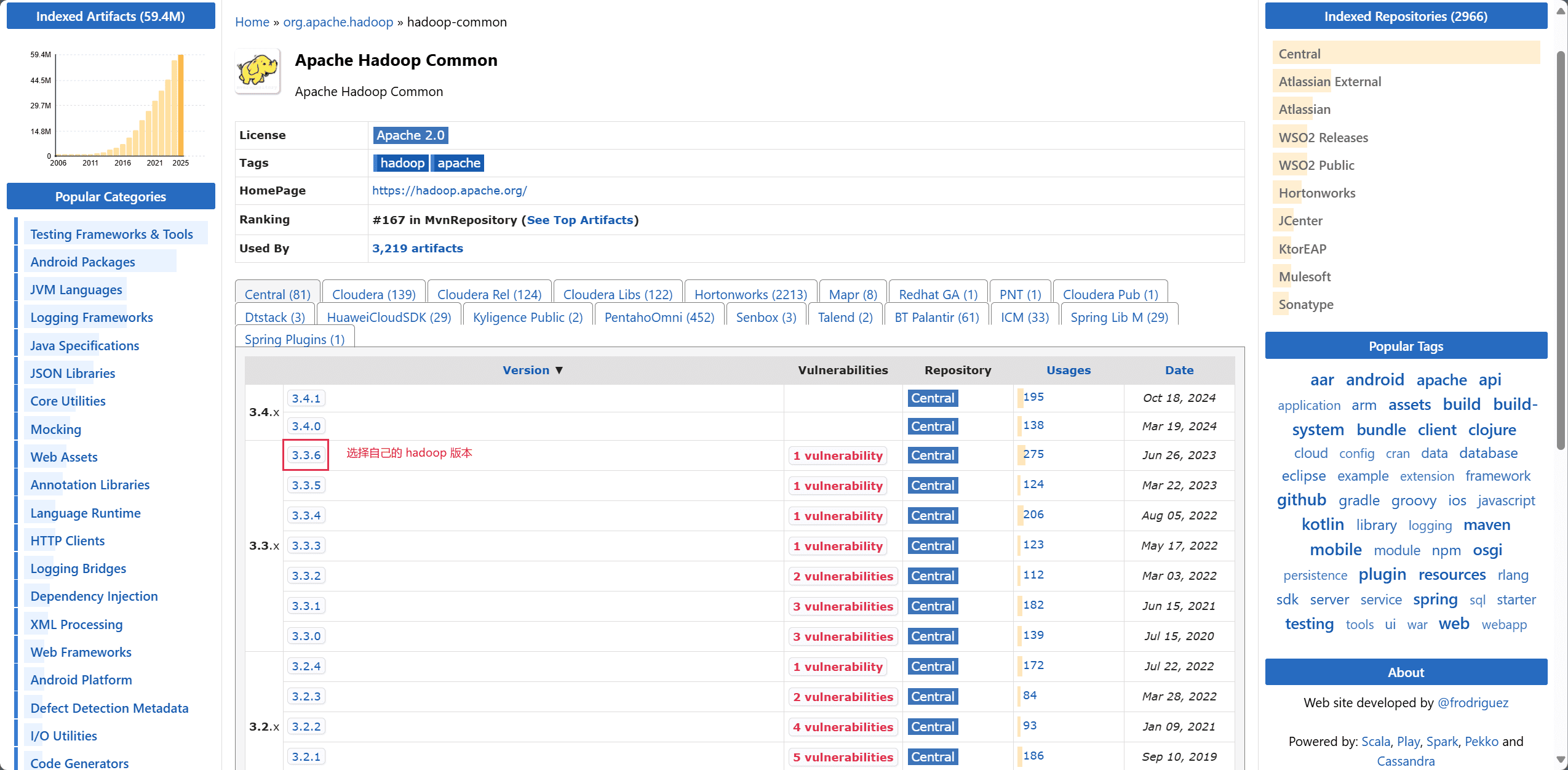
打开项目的 pom.xml 文件。
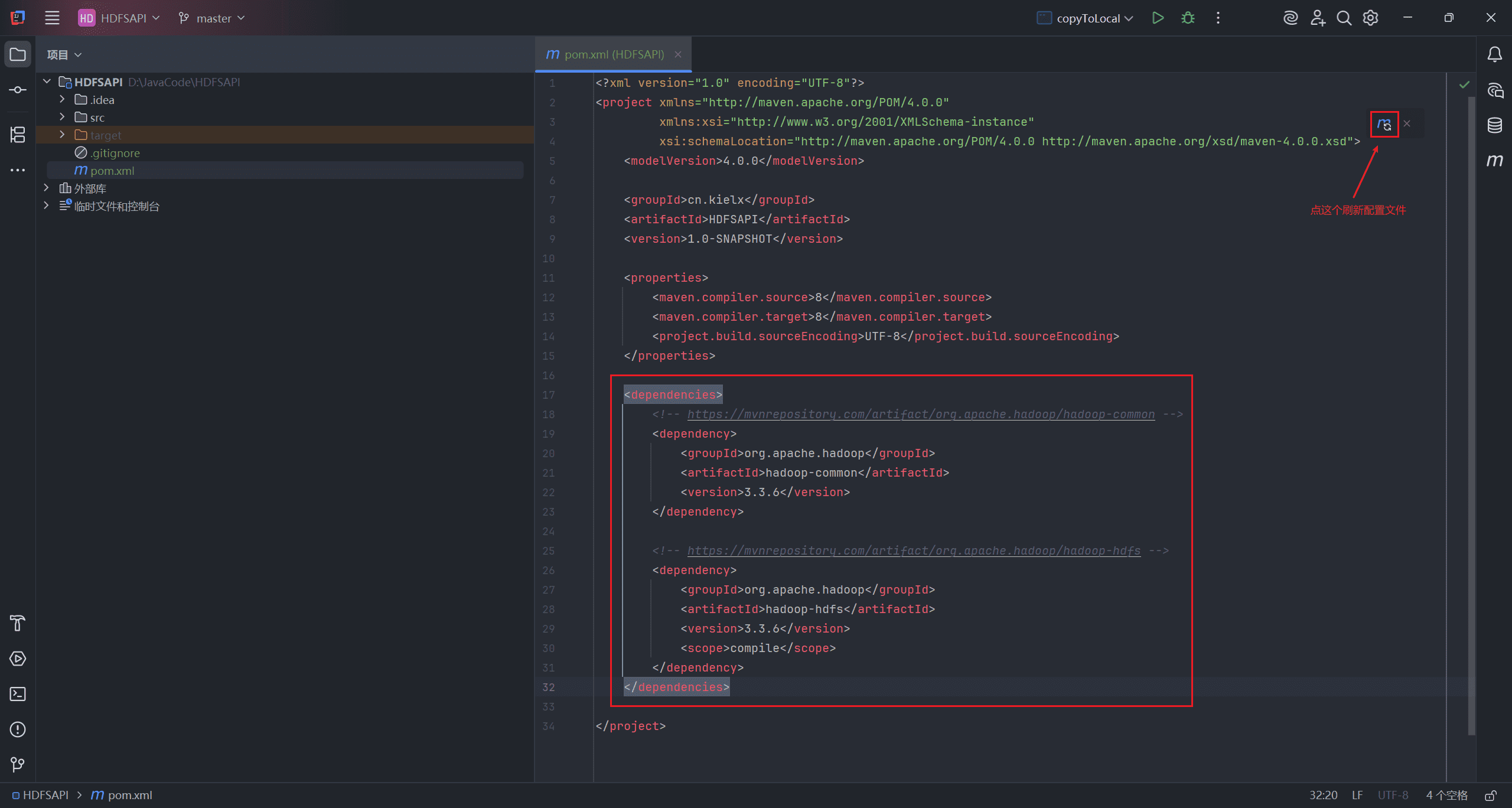
创建 <dependencies> 标签,将复制的配置粘贴进去,刷新配置文件。
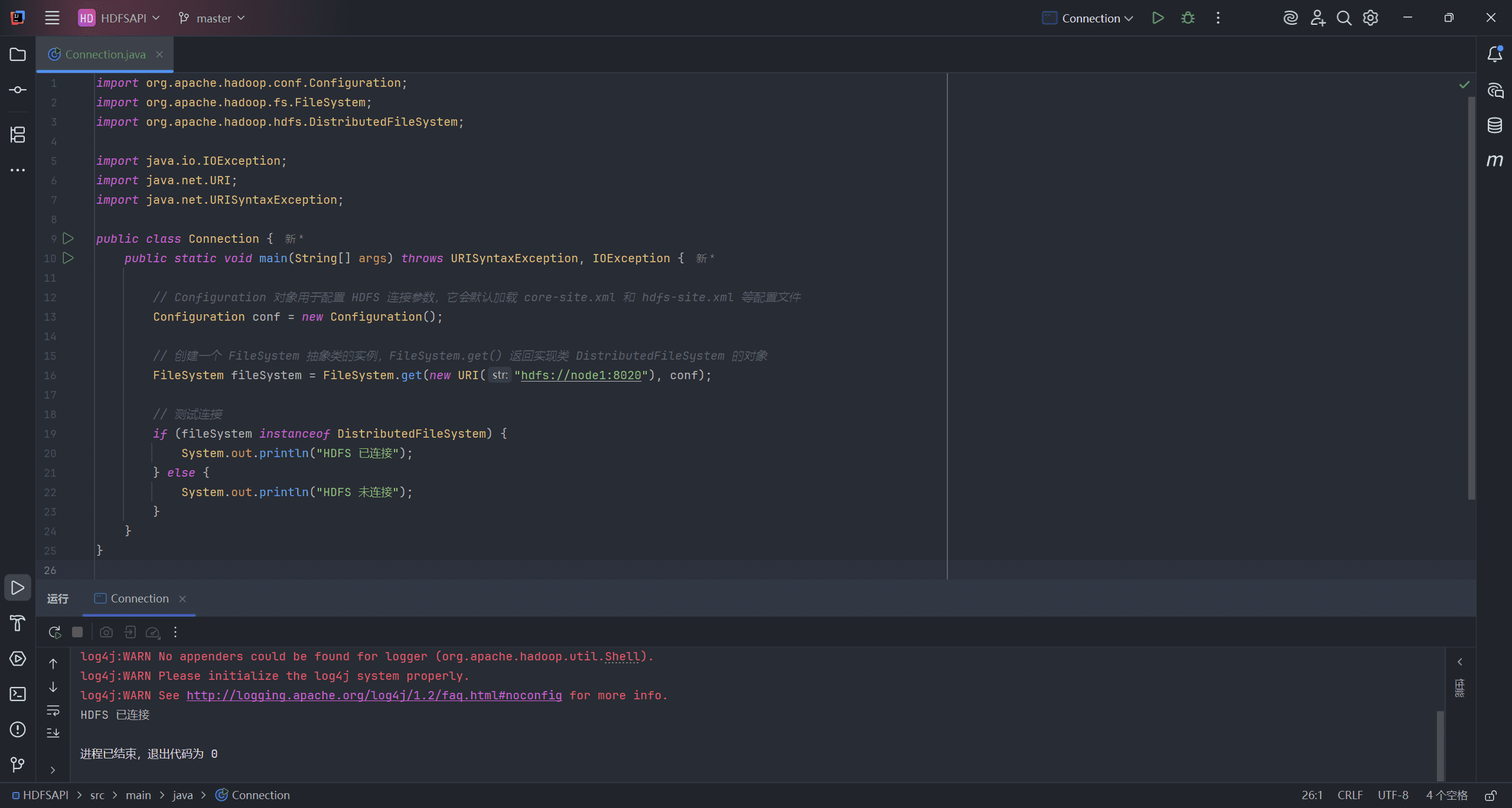
Hadoop 中的文件操作类基本上都位于 org.apache.hadoop.fs 包中。这些 API 支持的操作包括:打开文件、读写文件、删除文件等。
Hadoop 类库中面向用户的接口类是 FileSystem,它是一个抽象类,不能直接实例化。只能通过调用它的静态 get 方法并传入相关参数来获取具体的实现类实例。比如 DistributedFileSystem 就是 FileSystem 用于操作 HDFS 的实现类。
例如:FileSystem.get(new URI uri, Configuration conf)。
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.hdfs.DistributedFileSystem;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class Connection {
public static void main(String[] args) throws URISyntaxException, IOException {
// Configuration 对象用于配置 HDFS 连接参数,它会默认加载 core-site.xml 和 hdfs-site.xml 等配置文件
Configuration conf = new Configuration();
// 创建一个 FileSystem 抽象类的实例,FileSystem.get() 返回实现类 DistributedFileSystem 的对象
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:8020"), conf);
// 测试连接
if (fileSystem instanceof DistributedFileSystem) {
System.out.println("HDFS 已连接");
} else {
System.out.println("HDFS 未连接");
}
}
}
2、Client File Writing Operation(客户端文件写入操作)
客户端写入文件的过程:
-
HDFS 客户端通过 DistributedFileSystem APIs 发送创建请求。
-
DistributedFileSystem 会通过远程过程调用向 NameNode 发送请求,在文件系统的命名空间中创建一个新文件。
例如:
public FSDataOutputStream create(Path f, Progressable progress)。 -
DistributedFileSystem 会返回一个
FSDataOutputStream对象,供客户端开始写入数据。当客户端写入数据时,DFSOutputStream会将数据分割成若干数据包,并将它们写入一个内部队列,该队列称为数据队列。
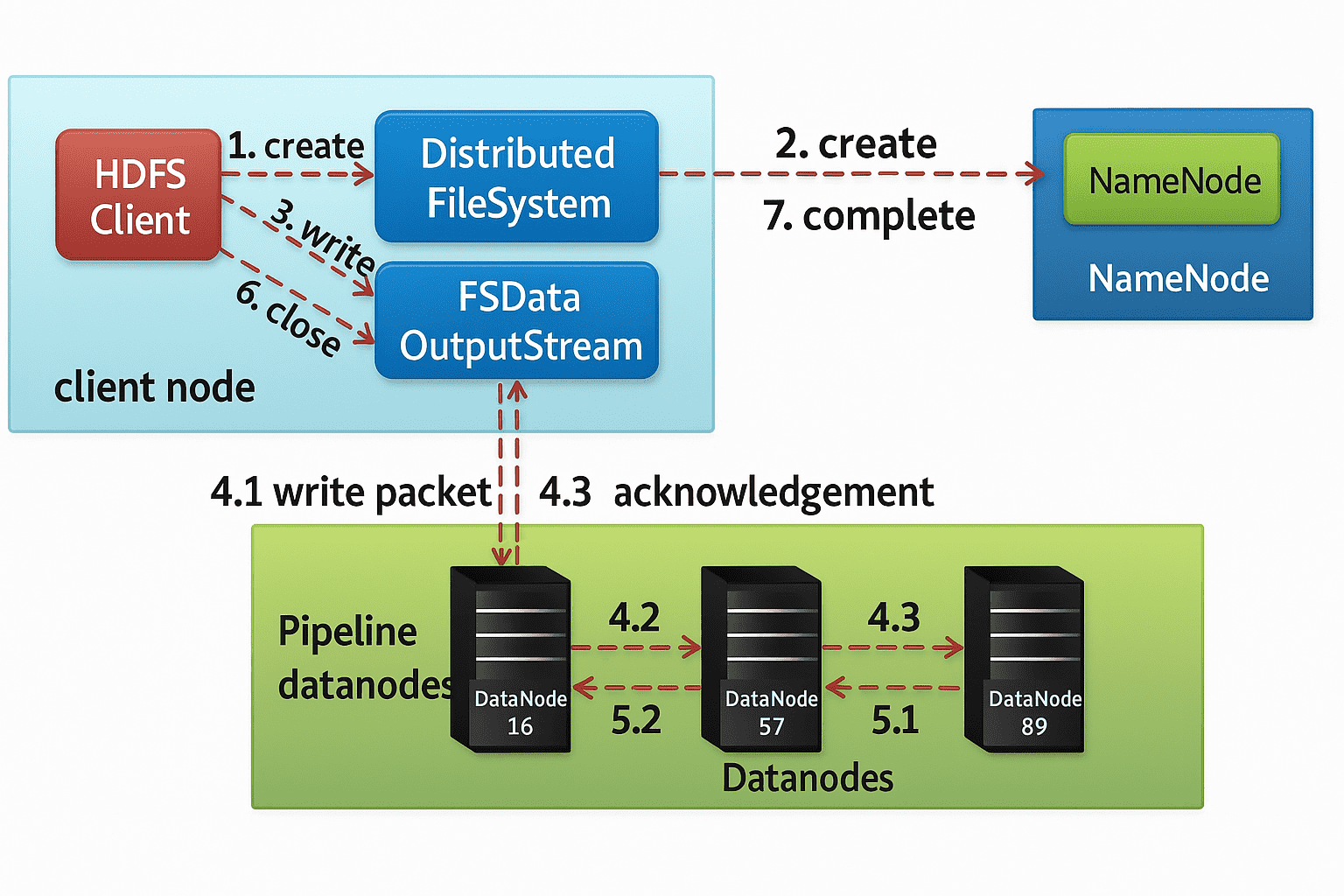
- DataNode 列表组成一个数据传输的流水线(pipeline),这里我们假设副本因子(replication level)为 3,因此流水线中会有三个节点。DataStreamer 会将数据包(packet)传输到流水线中的第一个 DataNode,该节点在存储数据包的同时,会将其转发给流水线中的第二个 DataNode。同样地,第二个 DataNode 也会存储数据包,并将其转发给流水线中的第三个(也是最后一个)DataNode。
- DFSOutputStream 还维护了一个内部队列,用于保存那些正在等待各个 DataNode 确认(acknowledge)的数据包,该队列被称为 ack 队列(ack queue)。
- 当客户端完成数据写入后,会调用流的 close() 方法。
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import java.io.*;
import java.net.URI;
import java.net.URISyntaxException;
public class writeToFile {
public static void main(String[] args) throws URISyntaxException, IOException {
// 与 HDFS 建立连接
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:8020"), conf);
// 创建一个输入流,从本地路径读取文件 "Data.txt",使用 BufferedInputStream 提高读取效率
InputStream inputStream = new BufferedInputStream(new FileInputStream("hdfs://node1:8020/Ezekielx/Data.txt"));
// 创建输出流,在 HDFS 上创建目标文件/MyData/dependencies.txt
OutputStream outputStream = fileSystem.create(new Path("hdfs://node1:8020/Ezekielx/Data.txt"));
try {
// 将输入流的数据复制到输出流。参数:输入流, 输出流, 缓冲区大小(4096字节), 是否关闭流(false表示不自动关闭)
IOUtils.copyBytes(inputStream, outputStream, 4096, false);
} finally {
// 无论是否发生异常,都要关闭输入流和输出流,释放资源
IOUtils.closeStream(inputStream);
IOUtils.closeStream(outputStream);
}
}
}
3、Client File Read Operation(客户端文件读取操作)
客户端读取文件的过程:
- 客户端通过 FileSystem 的 open() 函数打开文件。
- 分布式文件系统通过 RPC 调用元数据节点,以获取文件的数据块信息。对于每个数据块,元数据节点返回持有该数据块的数据节点的地址。
- 分布式文件系统将 FSDataInputStream 返回给客户端,用于读取数据。
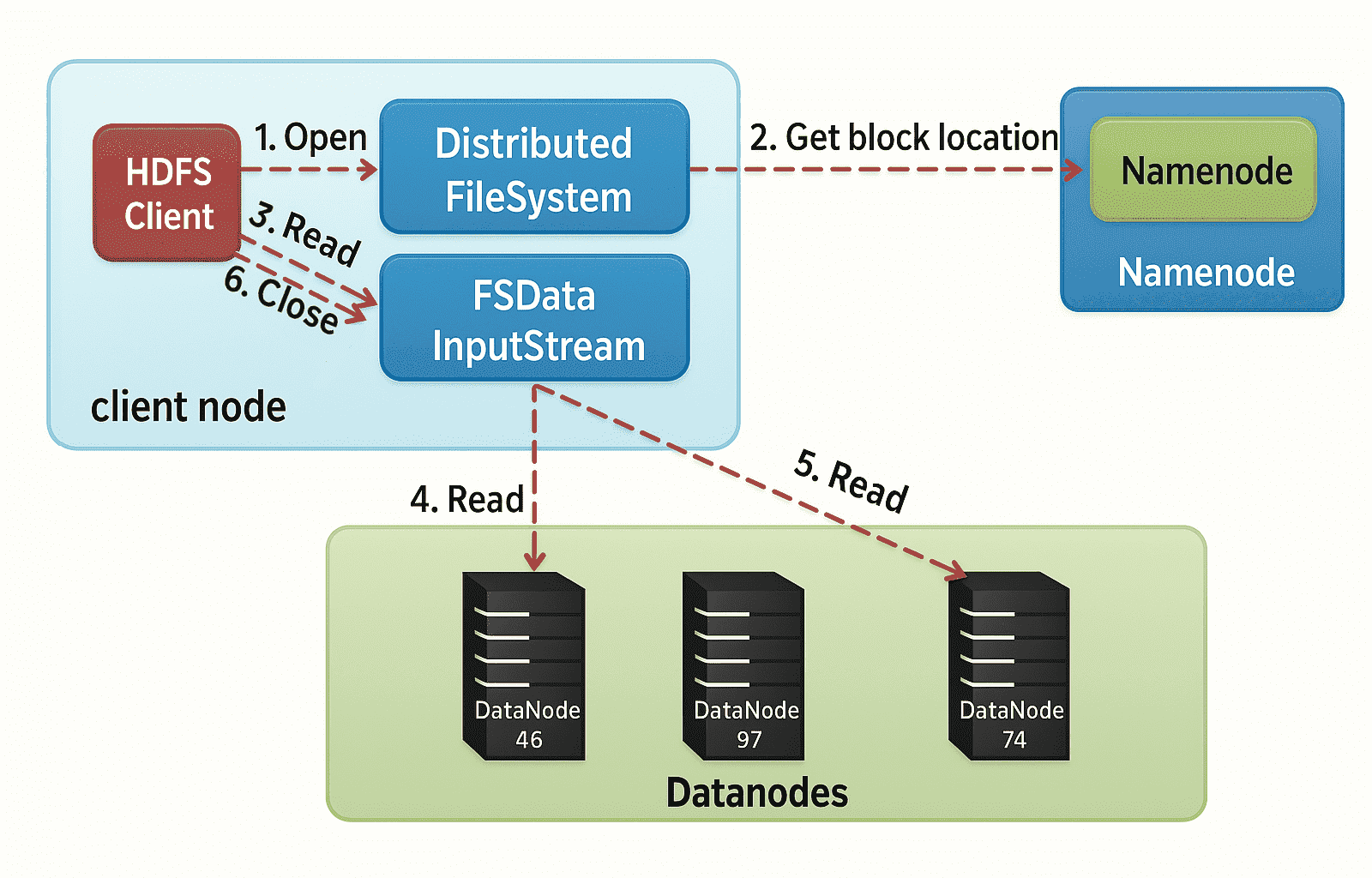
- 客户端调用流的 read() 函数开始读取数据。
- DFSInputStream 连接到存储该文件第一个数据块的最近数据节点,从该数据节点读取数据到客户端。
- 当一个数据块读取完成后,DFSInputStream 会关闭与该数据节点的连接,然后连接文件中下一个数据块的最近数据节点。客户端读取完数据后,会调用 FSDataInputStream 的 close() 函数。
- 在读取数据的过程中,如果客户端无法与某个数据节点通信,它会尝试连接包含该数据块的下一个数据节点。
- 失败的数据节点会被记录,后续将不再尝试连接这些节点。
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import java.io.*;
import java.net.URI;
import java.net.URISyntaxException;
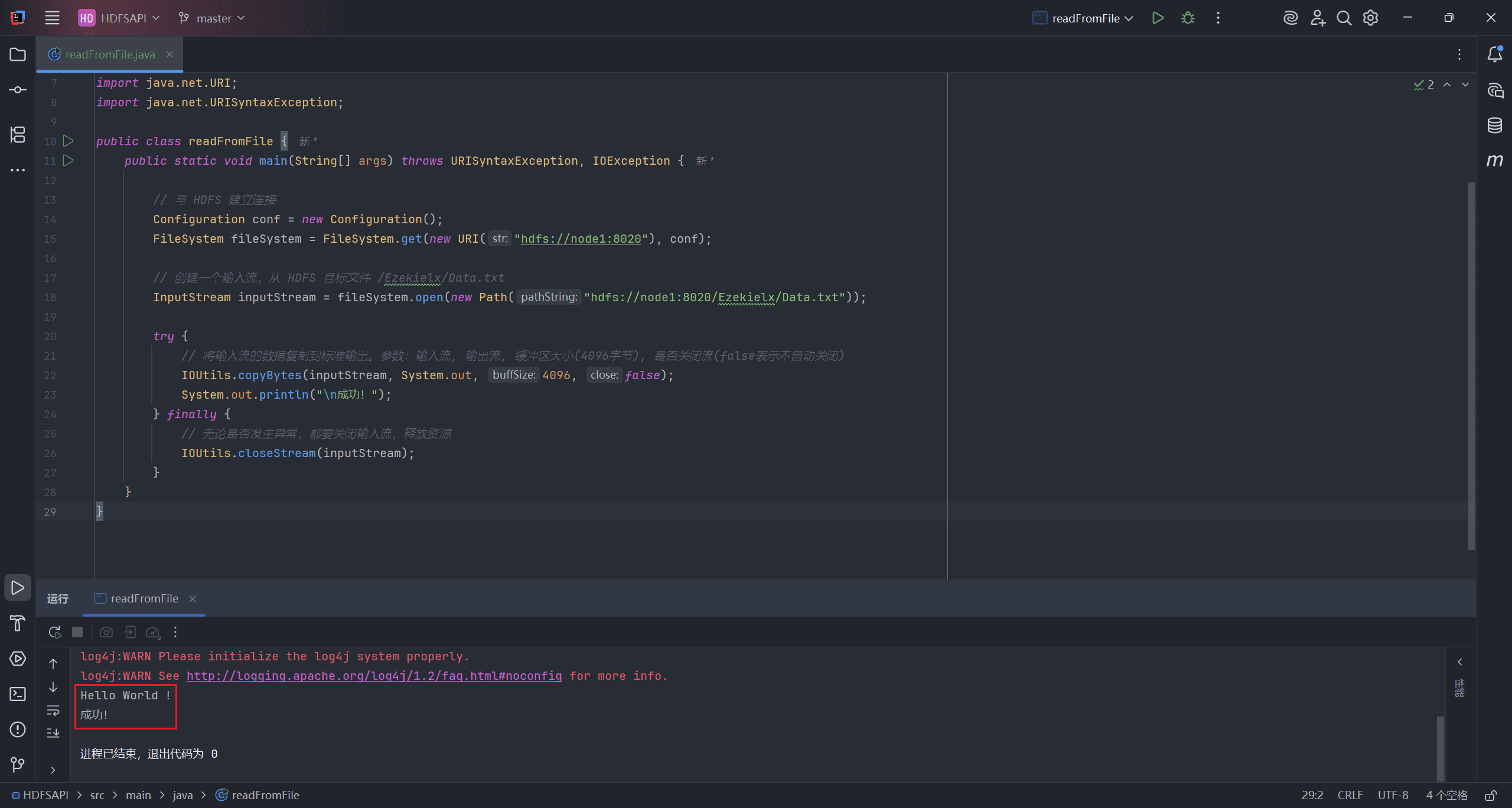
public class readFromFile {
public static void main(String[] args) throws URISyntaxException, IOException {
// 与 HDFS 建立连接
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:8020"), conf);
// 创建一个输入流,从 HDFS 目标文件 /Ezekielx/Data.txt
InputStream inputStream = fileSystem.open(new Path("hdfs://node1:8020/Ezekielx/Data.txt"));
try {
// 将输入流的数据复制到标准输出。参数:输入流, 输出流, 缓冲区大小(4096字节), 是否关闭流(false表示不自动关闭)
IOUtils.copyBytes(inputStream, System.out, 4096, false);
System.out.println("\n成功!");
} finally {
// 无论是否发生异常,都要关闭输入流,释放资源
IOUtils.closeStream(inputStream);
}
}
}
4、Upload Files locally to HDFS(将本地文件上传到 HDFS)
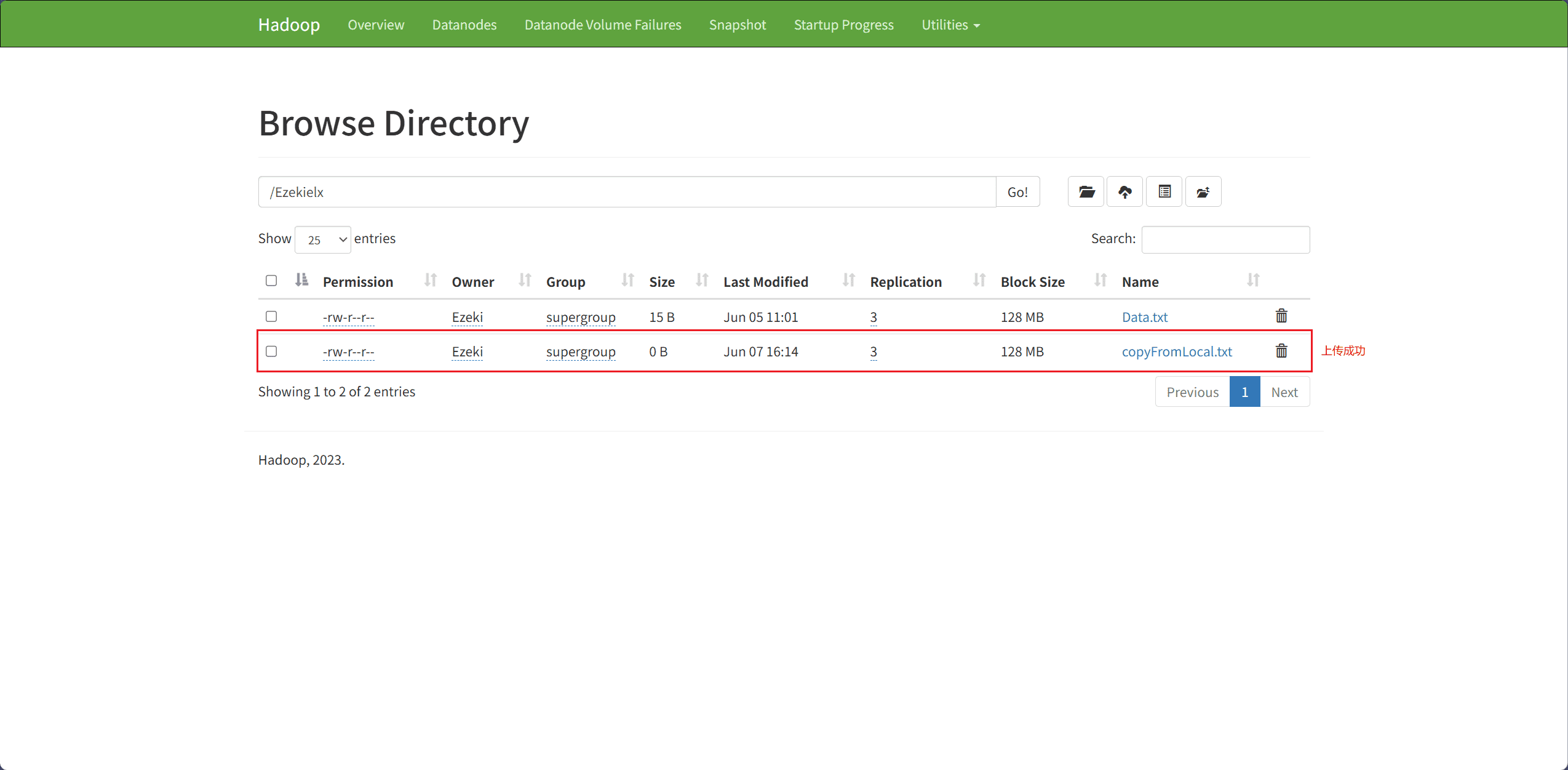
文件上传主要通过 copyFromLocalFile 接口完成。
src表示本地文件路径dest表示目标路径(HDFS 上的路径)
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
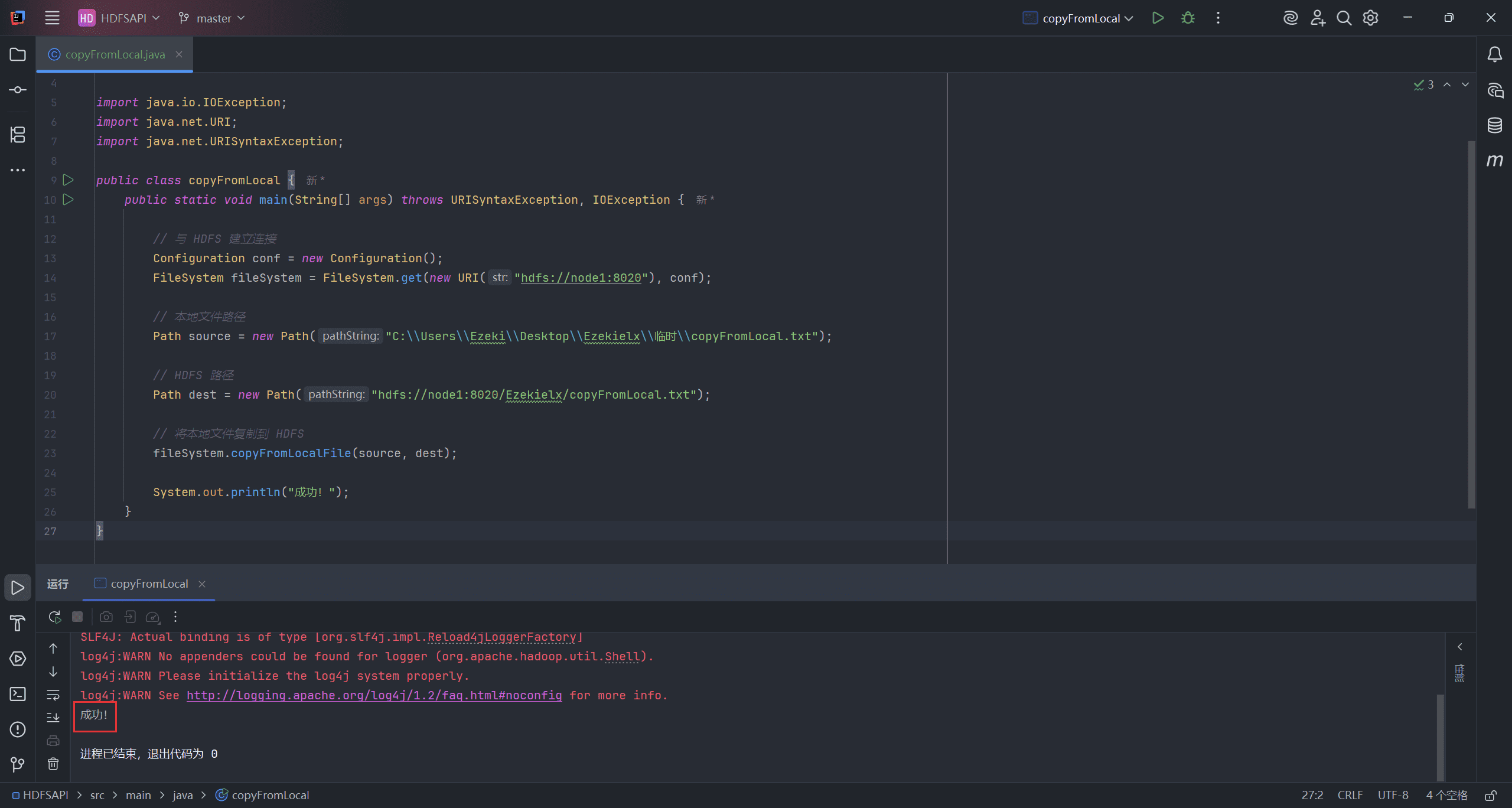
public class copyFromLocal {
public static void main(String[] args) throws URISyntaxException, IOException {
// 与 HDFS 建立连接
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:8020"), conf);
// 本地文件路径
Path source = new Path("C:\\Users\\Ezeki\\Desktop\\Ezekielx\\临时\\copyFromLocal.txt");
// HDFS 路径
Path dest = new Path("hdfs://node1:8020/Ezekielx/copyFromLocal.txt");
// 将本地文件复制到 HDFS
fileSystem.copyFromLocalFile(source, dest);
System.out.println("成功!");
}
}
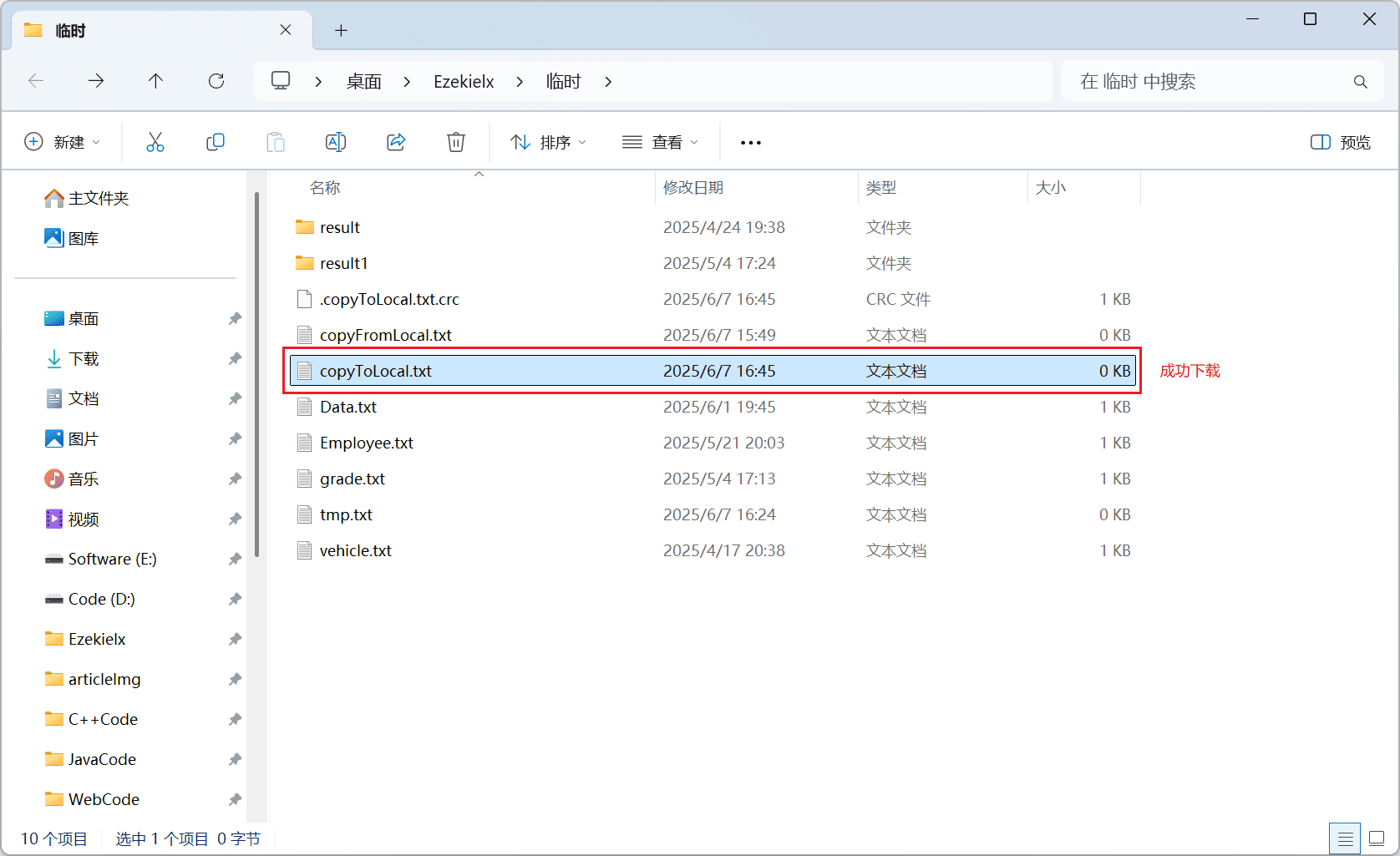
5、Download Files from HDFS to Local(从 HDFS 下载文件到本地)
文件下载主要通过 copyToLocalFile 接口完成。
src表示源路径(HDFS 上的文件路径)dest表示本地路径
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
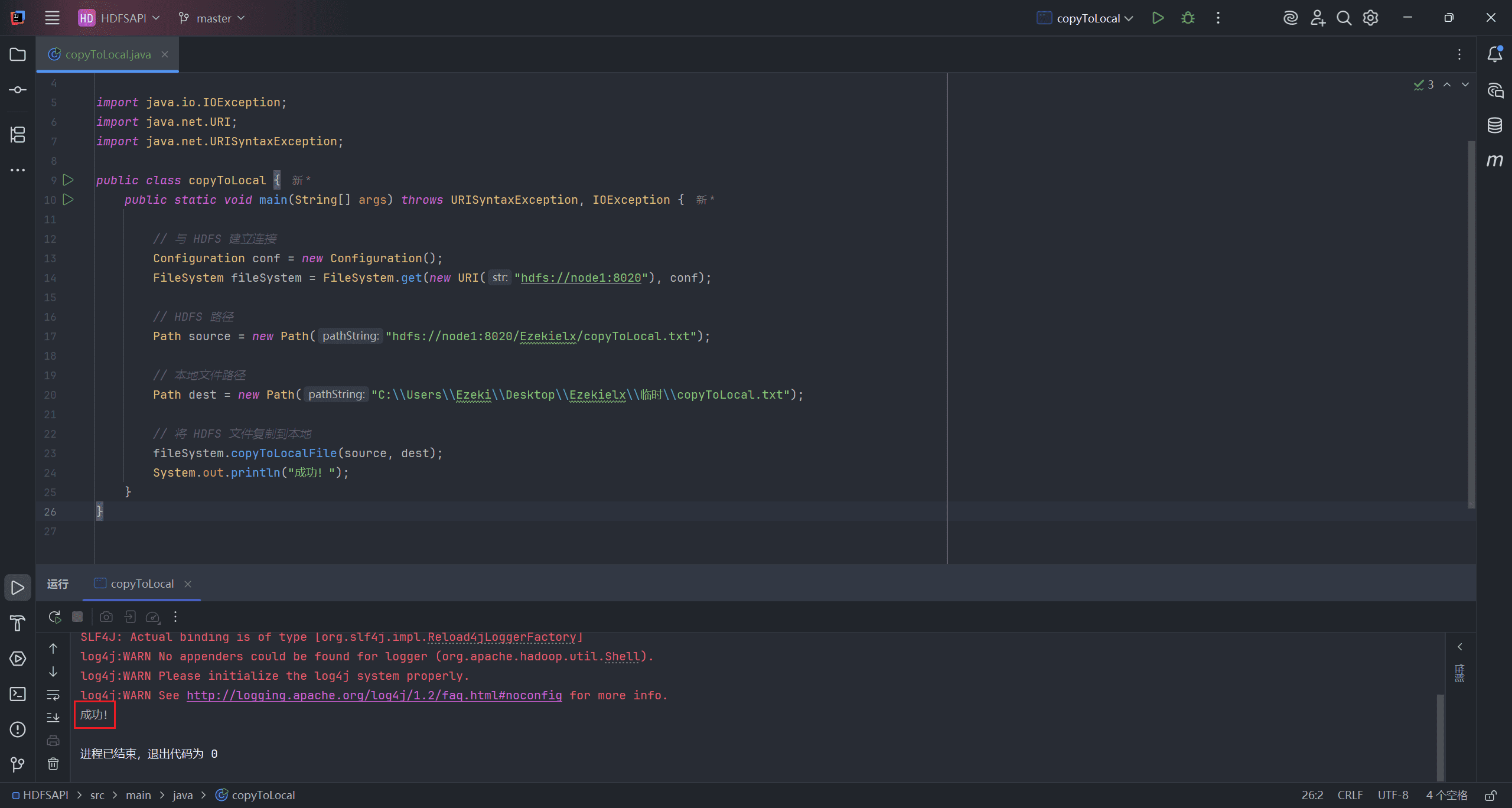
public class copyToLocal {
public static void main(String[] args) throws URISyntaxException, IOException {
// 与 HDFS 建立连接
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:8020"), conf);
// HDFS 路径
Path source = new Path("hdfs://node1:8020/Ezekielx/copyToLocal.txt");
// 本地文件路径
Path dest = new Path("C:\\Users\\Ezeki\\Desktop\\Ezekielx\\临时\\copyToLocal.txt");
// 将 HDFS 文件复制到本地
fileSystem.copyToLocalFile(source, dest);
System.out.println("成功!");
}
}
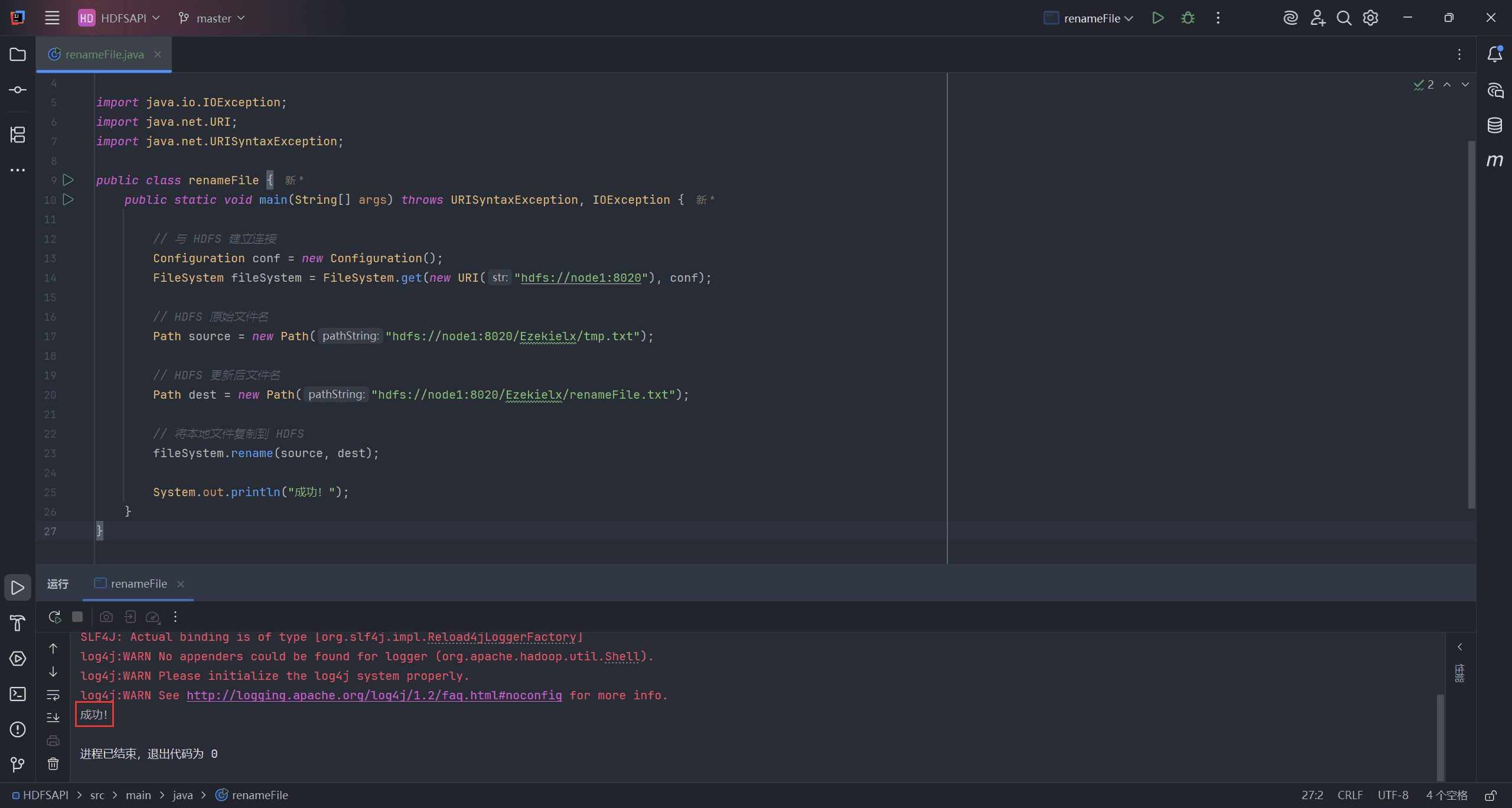
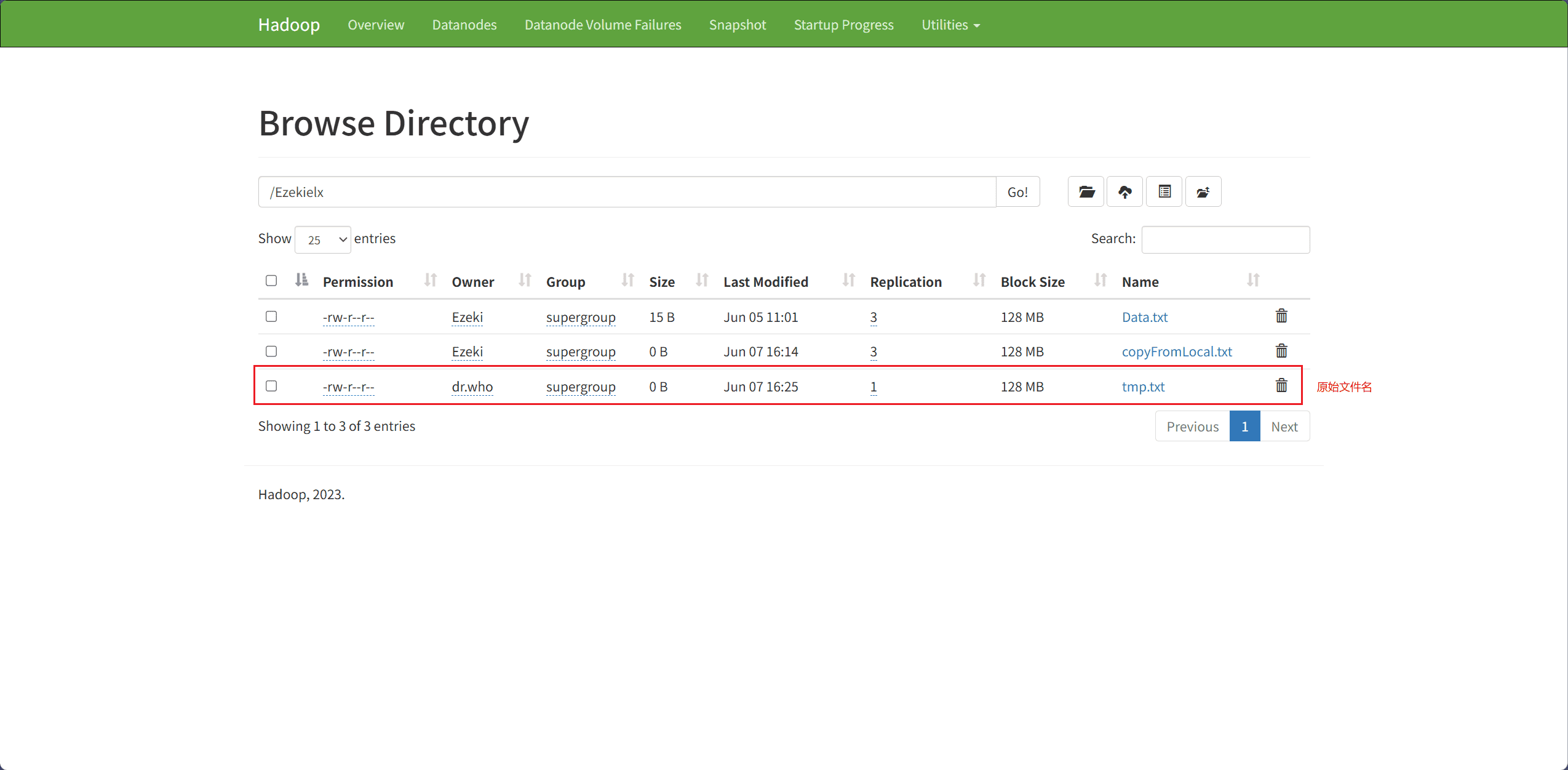
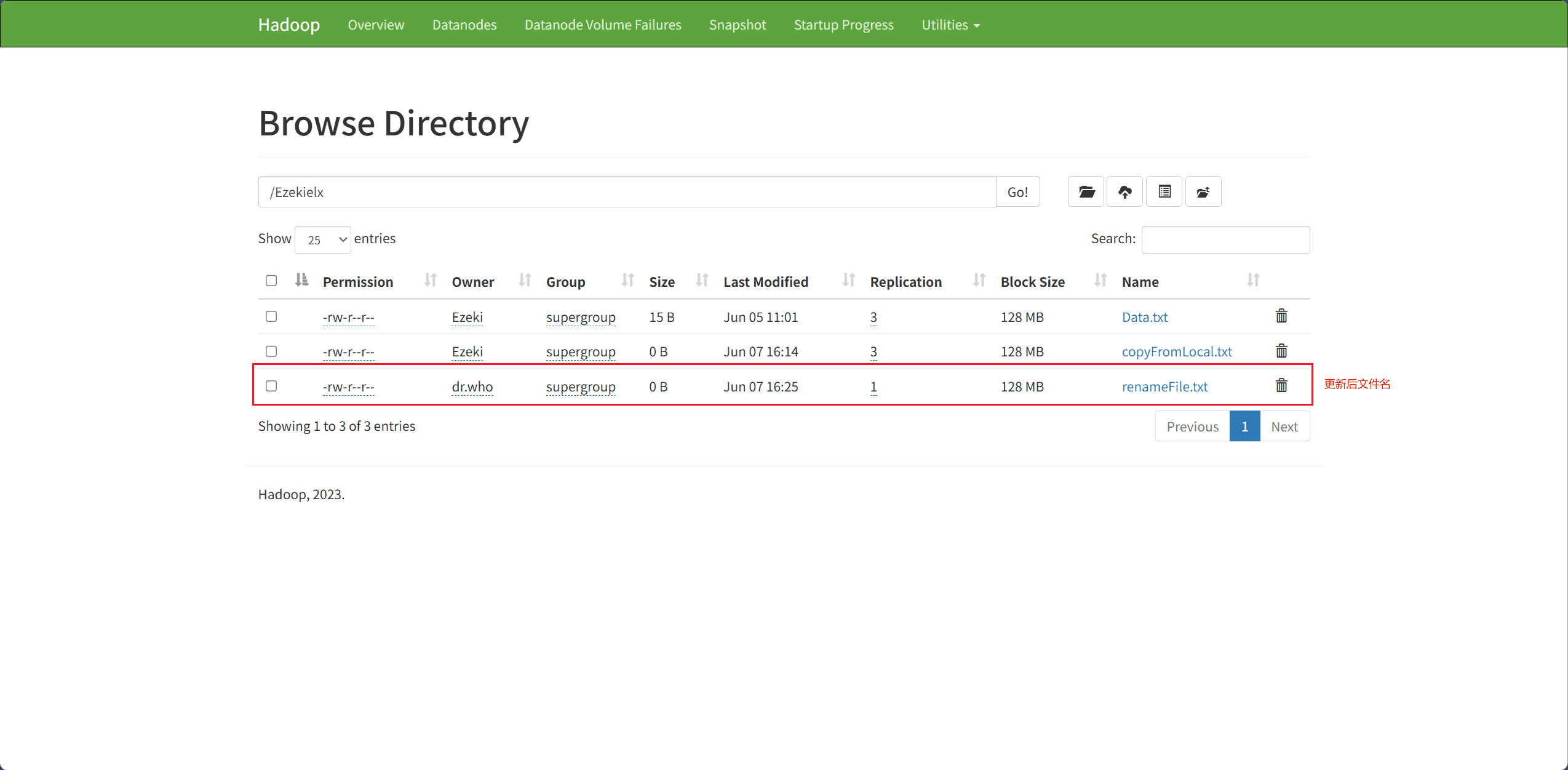
6、Rename File(重命名文件)
文件重命名主要通过 rename 接口完成。
src表示原始文件名,即要被重命名的文件dest表示重命名后的文件名
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class renameFile {
public static void main(String[] args) throws URISyntaxException, IOException {
// 与 HDFS 建立连接
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:8020"), conf);
// HDFS 原始文件名
Path source = new Path("hdfs://node1:8020/Ezekielx/tmp.txt");
// HDFS 更新后文件名
Path dest = new Path("hdfs://node1:8020/Ezekielx/renameFile.txt");
// 将本地文件复制到 HDFS
fileSystem.rename(source, dest);
System.out.println("成功!");
}
}
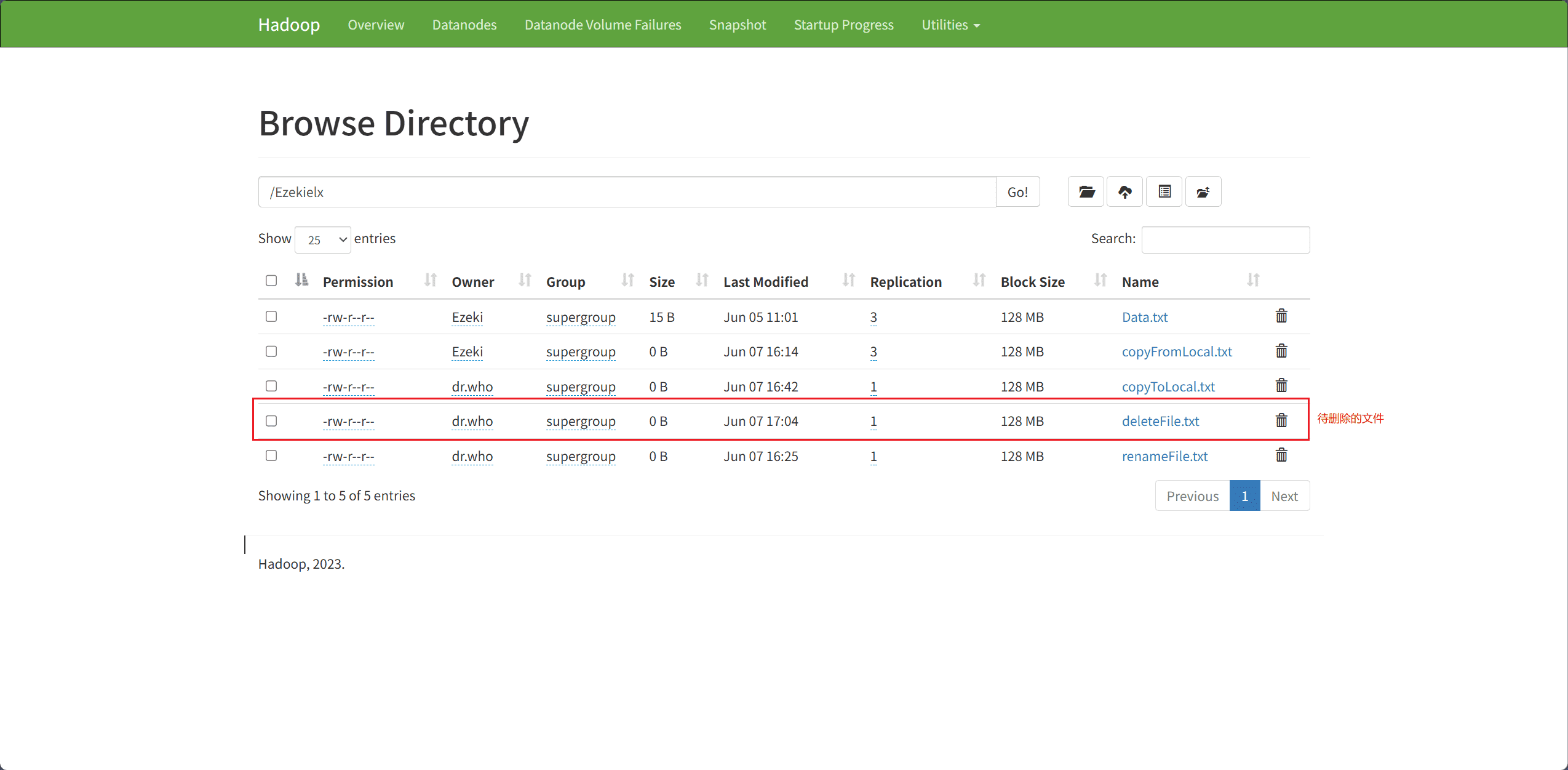
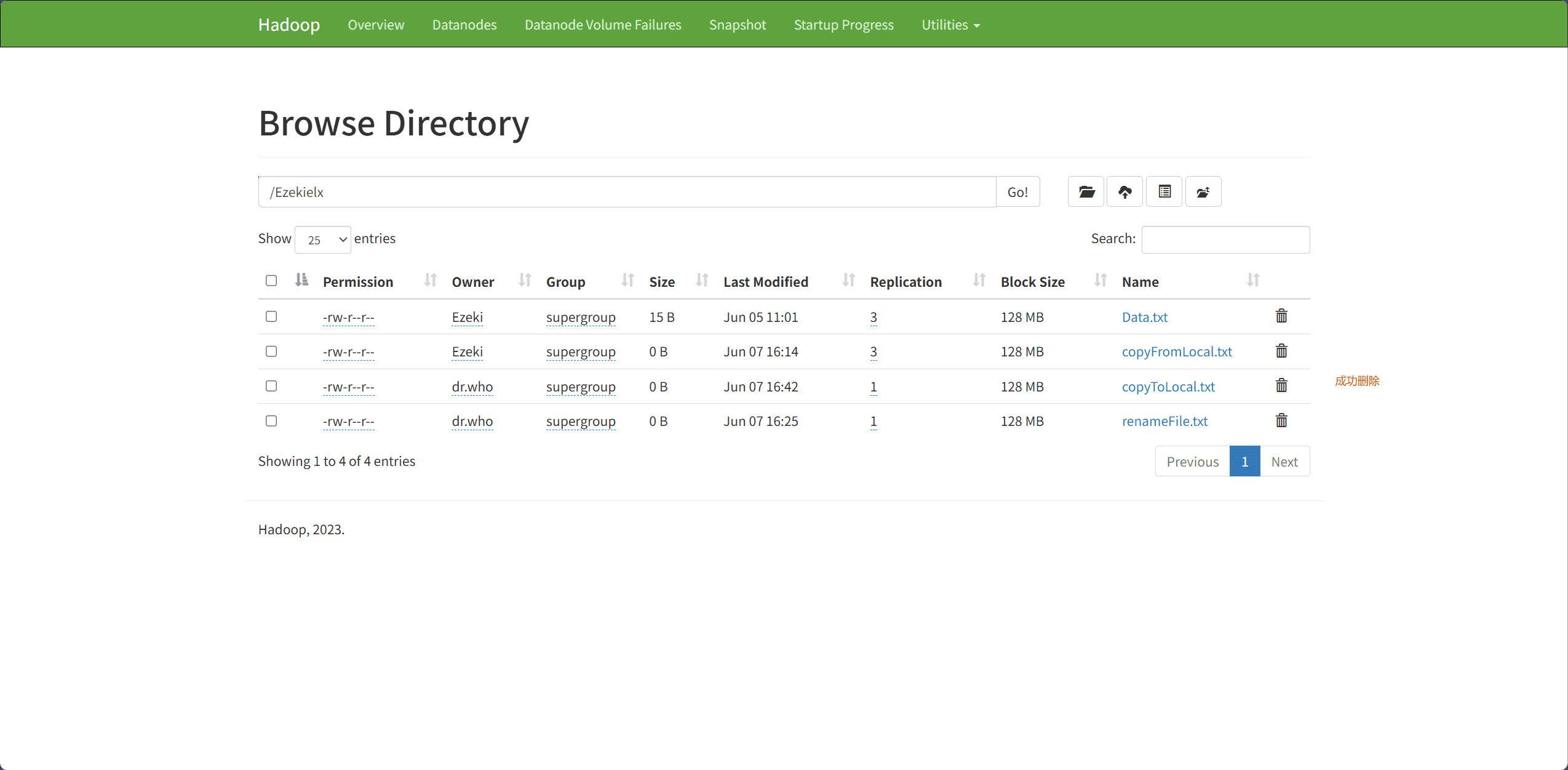
7、Delete Files & Directory(删除文件和目录)
文件和目录的删除主要通过 delete 接口完成。
path表示删除文件和目录的路径
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
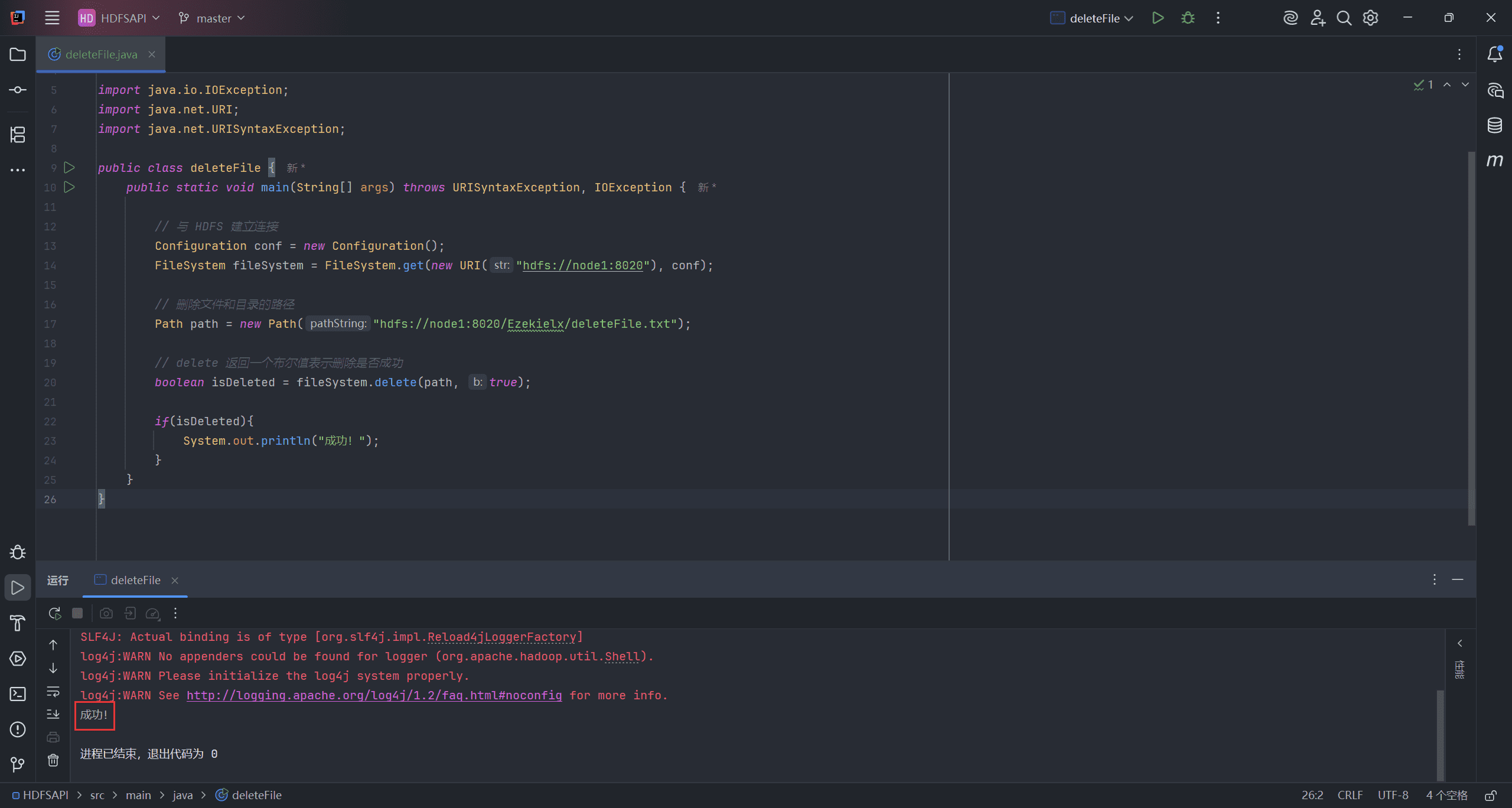
public class deleteFile {
public static void main(String[] args) throws URISyntaxException, IOException {
// 与 HDFS 建立连接
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:8020"), conf);
// 删除文件和目录的路径
Path path = new Path("hdfs://node1:8020/Ezekielx/deleteFile.txt");
// delete 返回一个布尔值表示删除是否成功
boolean isDeleted = fileSystem.delete(path, true);
if(isDeleted){
System.out.println("成功!");
}
}
}
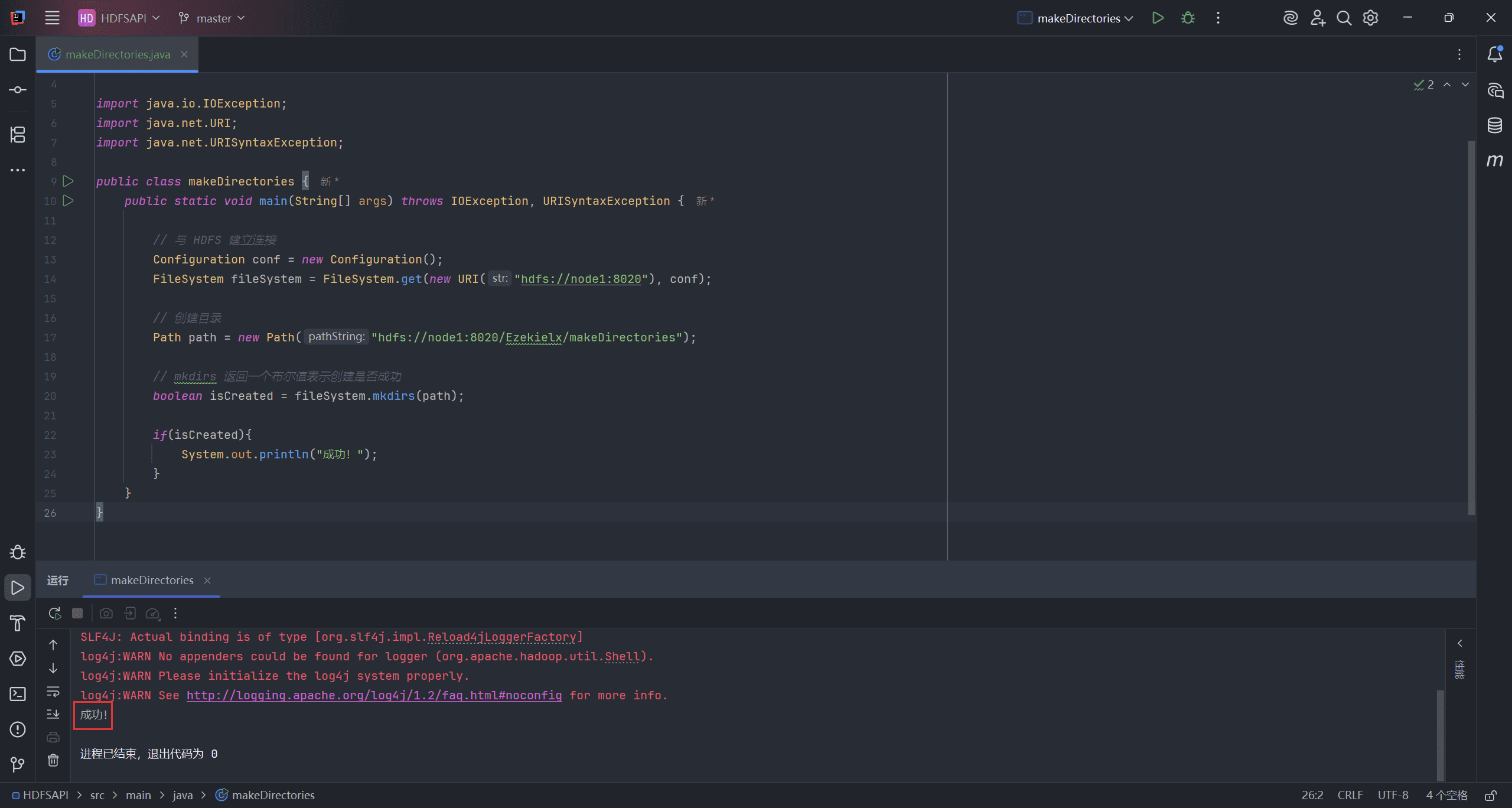
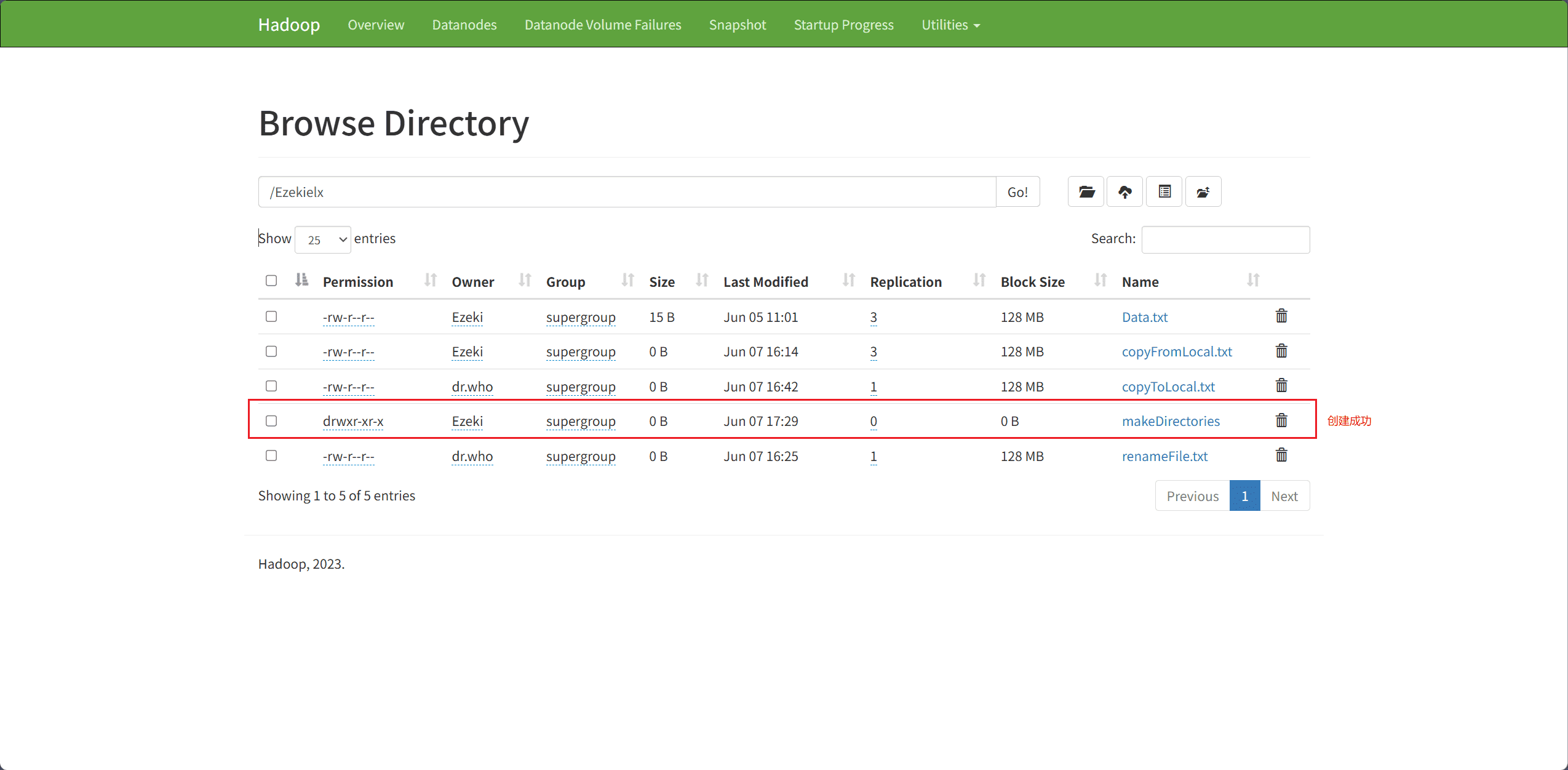
8、Create directories(创建目录)
目录的创建主要通过 mkdirs 接口完成。
path表示创建目录的路径
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class makeDirectories {
public static void main(String[] args) throws IOException, URISyntaxException {
// 与 HDFS 建立连接
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:8020"), conf);
// 创建目录
Path path = new Path("hdfs://node1:8020/Ezekielx/makeDirectories");
// mkdirs 返回一个布尔值表示创建是否成功
boolean isCreated = fileSystem.mkdirs(path);
if(isCreated){
System.out.println("成功!");
}
}
}
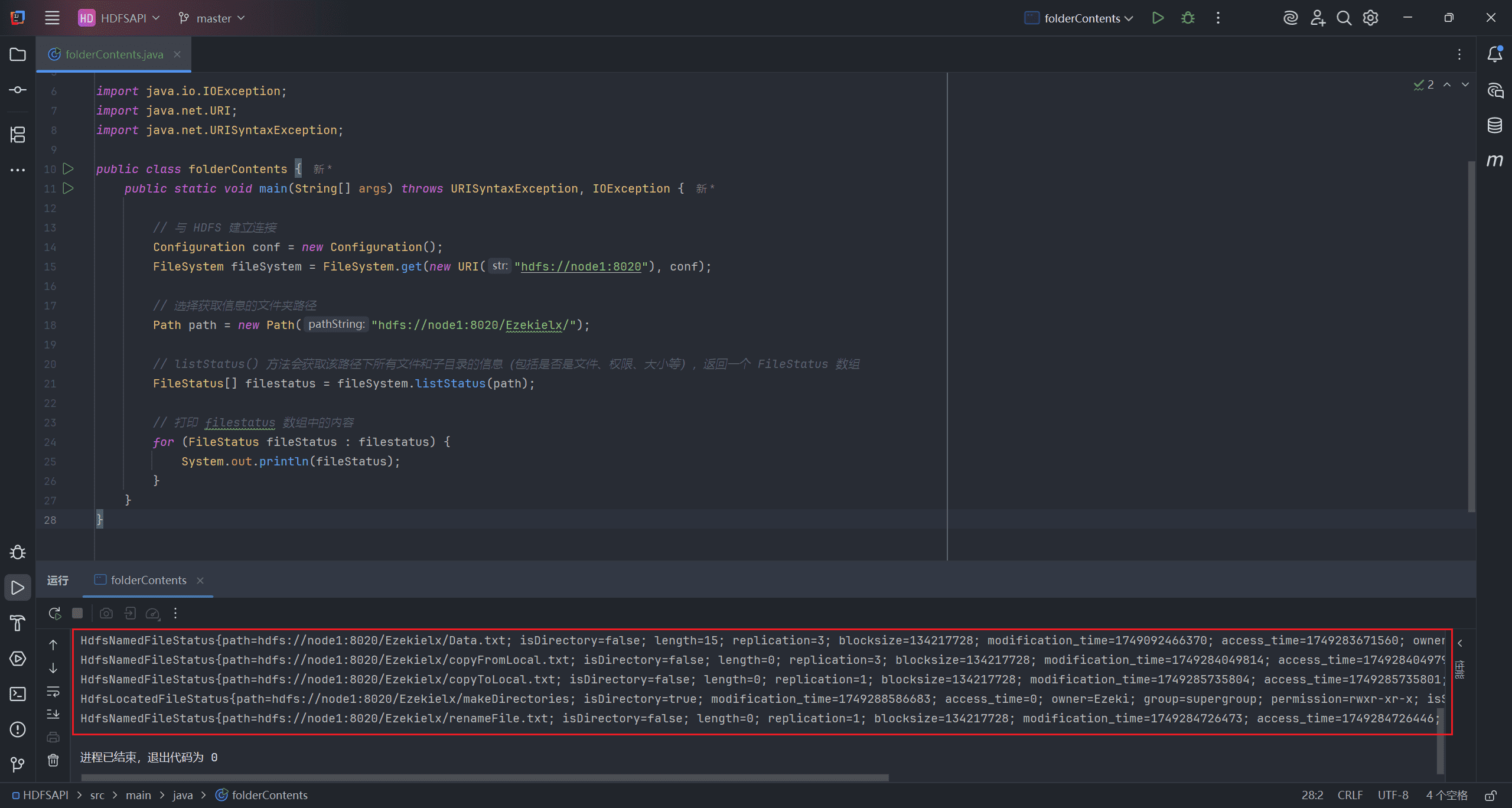
9、List Folder Contents(列出文件夹内容)
获取文件夹内容主要通过 listStatus 接口完成。
path表示选择获取信息的文件夹路径
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class folderContents {
public static void main(String[] args) throws URISyntaxException, IOException {
// 与 HDFS 建立连接
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:8020"), conf);
// 选择获取信息的文件夹路径
Path path = new Path("hdfs://node1:8020/Ezekielx/");
// listStatus() 方法会获取该路径下所有文件和子目录的信息(包括是否是文件、权限、大小等),返回一个 FileStatus 数组
FileStatus[] filestatus = fileSystem.listStatus(path);
// 打印 filestatus 数组中的内容
for (FileStatus fileStatus : filestatus) {
System.out.println(fileStatus);
}
}
}