一、Introduction of MapReduce(MapReduce 简介)
MapReduce 是 Hadoop 的处理层。MapReduce 编程模型旨在通过将工作划分为一组独立的任务,来并行处理海量数据。你只需将业务逻辑融入 MapReduce 的工作方式中,其余的部分将由框架自动处理。用户提交给主节点的工作(完整作业)会被划分为多个小任务,并分配给从节点执行。
1、How MapReduce Works(MapReduce 的工作原理)
MapReduce 框架完全基于“键值对(key-value pairs)”进行操作,数据以一批“键值对”的形式输入,结果也以一批“键值对”的形式输出,且有时键值对的数据类型可能会不同。
Key 和 Value 类必须实现 Writable 接口,因为它们需要支持序列化操作;而 Key 类还必须实现 WritableComparable 接口,以便框架对数据集进行排序。
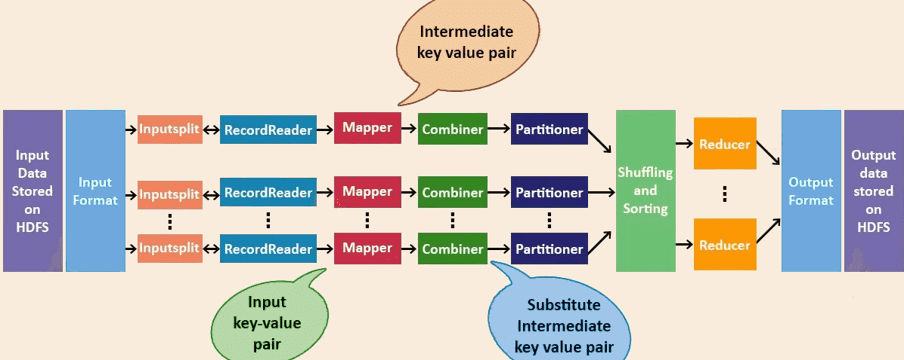
MapReduce 的运行机制包括以下作业执行阶段:Input Files(输入文件)、InputFormat(输入格式)、InputSplits(输入切片)、RecordReader(记录读取器)、Mapper(映射器)、Combiner(合并器)、Partitioner(分区器)、Shuffling and Sorting(洗牌与排序)、Reducer(归约器)、RecordWriter(记录写入器)以及 OutputFormat(输出格式)。
2、MapReduce Inputs and Outputs(MapReduce 输入与输出)
Input Files(输入文件):MapReduce 任务的数据存储在输入文件中,输入文件通常位于 HDFS 中。这些文件的格式是任意的,可以是基于行的日志文件,也可以是二进制格式。
InputFormat(输入格式):InputFormat 处理 MapReduce 中输入部分的内容,以确定 Map 的数量。InputFormat 的功能如下。
- 验证作业输入是否规范。
- 将输入文件划分为 InputSplit(输入切片)。
- 提供一个 RecordReader 实现类,用于将 InputSplit 读取为供 Mapper 处理的内容。
// InputFormat 代码示例
public abstract class InputFormat<K, V> {
// 将输入文件划分为 InputSplit
public abstract List<InputSplit> getSplits(JobContext context) throws IOException, InterruptedException;
// 将 InputSplit 读取为供 Mapper 处理的内容
public abstract RecordReader<K,V> createRecordReader(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException;
}
- 每个 Map 任务会处理一个 InputSplit,默认每个切片的大小为 128M。
createRecordReader方法将每个切片解析为记录,再将记录解析为 <K, V> 键值对。
FileInputFormat(文件输入格式):FileInputFormat 是所有使用文件作为数据源的基类,InputFormat 的实现类。它保存所有作业输入的文件,并实现了一个计算文件分片的方法。
// FileInputFormat 代码示例
public abstract class FileInputFormat<K, V> extends InputFormat<K, V>
InputSplits(输入切片):由 InputFormat 创建,逻辑上表示将由单个 Mapper 处理的数据。每一个切片对应一个 Map 任务,因此 Map 任务的数量等于 InputSplits 的数量。
getLength:返回文件大小。getLocations:返回数据所在的物理位置(如存储节点)。
// InputSplit 代码示例
public interface InputSplit extends Writable {
long getLength() throws IOException;
String[] getLocations() throws IOException;
}
- 在执行 MapReduce 前,原始数据会被划分成多个切片,每个切片作为一个 Map 任务的输入;在 Map 执行过程中,每个切片会进一步被解析为记录(键值对),Mapper 依次处理这些记录。
- FileInputFormat 只对大于 HDFS 块大小的文件进行切片,因此 FileInputFormat 的分区结果可能是整个文件或其一部分。
- 如果文件小于一个 HDFS 块的大小,则不会被切片,这也是 Hadoop 在处理大文件时比处理大量小文件更高效的原因。
- 当 Hadoop 处理大量小文件(小于块大小)时,FileInputFormat 不会将小文件划分切片,因此每个小文件被视为一个切片,会被分配一个 Map 任务,效率较低。
在 Hadoop 中,常用的 Map 输入类型:
-
TextInputFormat(文本输入):是 Hadoop 的默认输入方式。在TextInputFormat中,每个文件(或文件的一部分)被单独输入到一个 Map 中。它继承自FileInputFormat。在该模式下,每一行数据生成一个记录,表示为 <key, value>。key是数据记录在数据片段中的字节偏移量,数据类型为LongWritable。value是每一行的内容,数据类型为Text。
-
SequenceFileInputFormat:用于读取顺序文件(SequenceFile)。顺序文件是 Hadoop 用于以自定义格式存储数据的二进制文件。它有两个子类:SequenceFileAsBinaryInputFormat:以BytesWritable类型读取 key 和 value。SequenceFileAsTextInputFormat:以Text类型读取 key 和 value。
-
KeyValueInputFormat:将输入文件的每一行作为一个独立的记录,并通过查找 TAB(制表符)字符将其分割为 key 和 value。
Custom InputFormat(自定义输入模式):
-
继承
FileInputFormat基类。 -
重写
getSplits(JobContext context)方法。此接口的主要职责是将一堆输入文件分割为多个切片(每个切片由一个
InputSplit对象表示),每个InputSplit都会传递给不同的 Mapper 进行处理。但请注意,这些切片只是逻辑上的分片,实际上并不将文件物理划分成多个部分。一个切片可以表示为一个元组(输入文件路径,起始位置,偏移量)。
// getSplits(JobContext context) 方法定义
public abstract List<InputSplit> getSplits(JobContext Context) throws IOException, InterruptedException;
- 重写
createRecordReader(InputSplit split, TaskAttemptContext context)方法。
这个接口的职责是返回一个读取 InputSplit 切片的 RecordReader 实例,用于从切片中提取 <K, V> 对供 Mapper 使用。
// createRecordReader(InputSplit split, TaskAttemptContext context) 方法定义
public abstract RecordReader<K, V> createRecordReader(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException;
3、Map Output Format(Map 输出格式)
MapReduce 中常用的输出格式如下:
- TextOutputFormat:以纯文本文件的形式输出,格式为
key + "\t" + value(键与值之间用制表符分隔) - NullOutputFormat:类似于 Hadoop 中的
/dev/null,输出被丢弃,相当于写入黑洞,不会生成实际输出文件。 - SequenceFileOutputFormat:输出为 Sequence 文件格式,适用于二进制数据的写入。
- MultipleSequenceFileOutputFormat、MultipleTextOutputFormat:根据 key 的不同值,将数据分别输出到不同的文件中,适用于需要按 key 分类输出的场景。
RecordReader:它与 Hadoop MapReduce 中的 InputSplit 交互,将输入数据转换为适合 Mapper 读取的键值对。默认使用的是 TextInputFormat,将数据每行转换为一个 key-value 对,其中 key 是该行的字节偏移量(一个唯一数字)。RecordReader 会持续读取,直到文件读取完毕。
Mapper:处理 RecordReader 提供的每条输入记录,生成新的键值对。Mapper 的输出(也称为中间输出)是临时数据,不会存储在 HDFS 上,否则会导致不必要的数据副本产生。
Combiner:也称为“小型 Reducer”,在 Mapper 输出的基础上进行本地聚合,减少 Mapper 和 Reducer 之间传输的数据量。
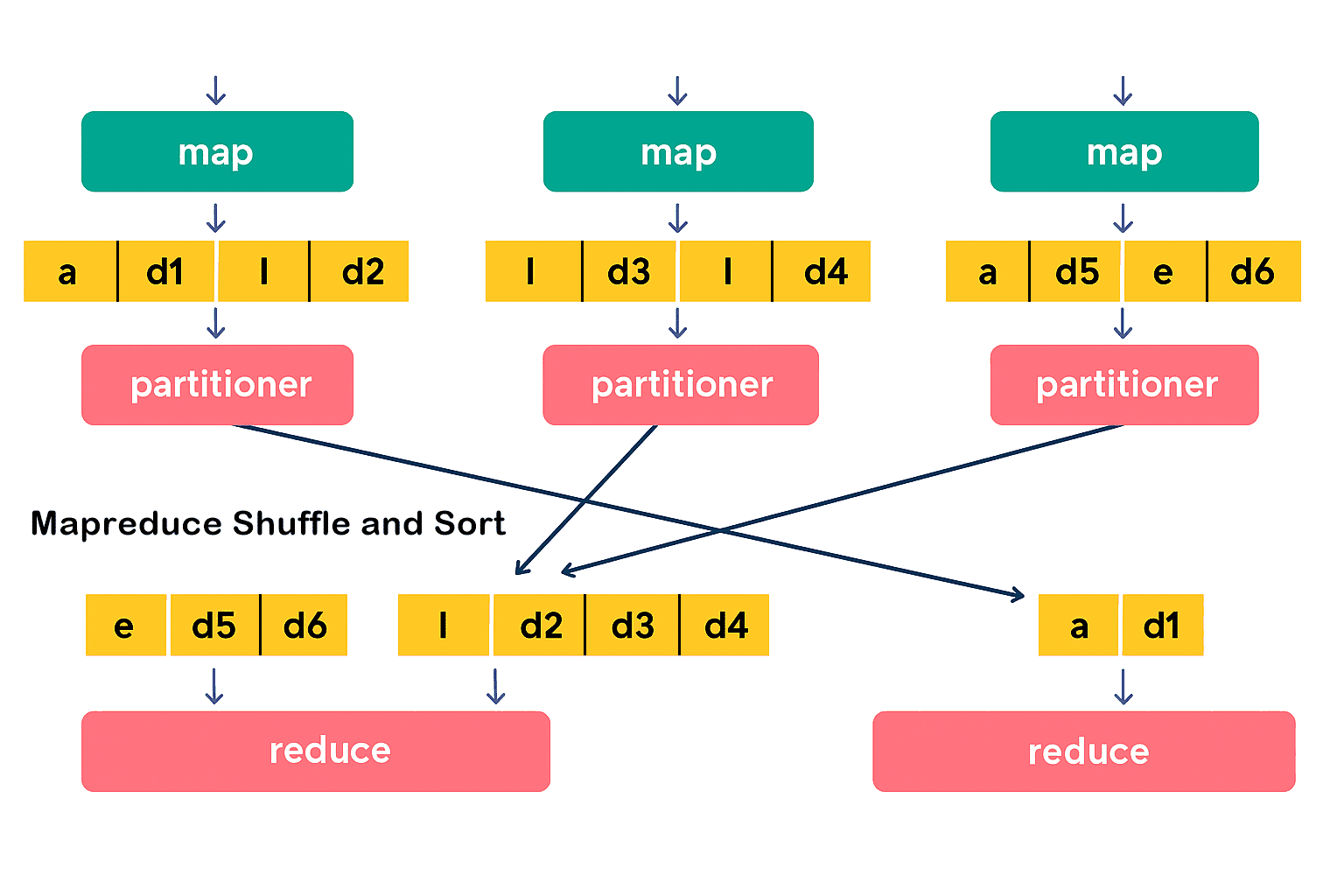
Partitioner(分区器):在 Hadoop MapReduce 中,只有在使用多个 Reducer 时才会用到 Partitioner(如果只使用一个 Reducer,则不需要分区器)。
Partitioner 接收来自 Combiner 的输出数据,并根据 key 对数据进行分区。分区是基于 key 进行的,通常通过哈希函数对 key(或其子集)进行哈希,从而确定数据所属的分区。
在 MapReduce 中,每个具有相同 key 值的记录会被分到同一个分区,然后每个分区被分配给一个 Reducer。分区机制有助于将 Map 阶段的输出数据均匀分配到各个 Reducer 上,提高负载均衡性。
Shuffling and Sorting(洗牌与排序):Shuffling 指将中间输出数据“洗牌”后发送到 Reducer 节点(该节点是普通的从节点,但会运行 Reduce 阶段任务,因此称为 Reducer 节点)。
Shuffling 是数据通过网络进行的物理移动。当所有 Mapper 完成任务后,其输出会被传输到 Reducer 节点,并在该节点上进行合并与排序。
排序完成后的中间数据就是 Reduce 阶段的输入。
Reducer(归约器):Reducer 接收 Mapper 所产生的中间键值对,并对每一个 key 执行归约函数,生成最终的输出结果。Reducer 的输出就是最终结果,会被写入到 HDFS 上。
RecordWriter(记录写入器):该组件负责将 Reducer 阶段生成的键值对写入最终的输出文件。
OutputFormat(输出格式):RecordWriter 将键值对写入输出文件的方式由 OutputFormat 决定。Hadoop 提供的 OutputFormat 实例可以将文件写入到 HDFS 或本地磁盘。因此,Reducer 的最终输出结果是通过 OutputFormat 实例写入到 HDFS 的。
二、Key Processes of MapReduce(MapReduce 的关键处理流程)
一个作业包括 Map、Combiner、Partitioner、Reduce 和 Shuffle 等阶段,用于对大数据进行分析、处理和计算。
1、Mapper(映射器)
Mapper 只能处理以 <key, value> 形式表示的数据,因此在将数据传递给 Mapper 之前,必须先将数据转换成 <key, value> 对。
InputSplits(输入分片):它将物理数据块的表示转换为逻辑形式,供 Hadoop 的 Mapper 使用。例如,读取一个 200MB 的文件需要两个 InputSplit。每个数据块会生成一个 InputSplit,并且每个 InputSplit 会对应创建一个 RecordReader 和一个 Mapper。
不过,InputSplit 的数量不总是与数据块数量完全一致。我们可以通过在作业执行时设置 mapred.max.split.size 属性,来自定义特定文件的分片数量。
RecordReader(记录读取器):它负责持续读取和转换数据为 <key, value> 形式,直到文件末尾。RecordReader 会为文件中的每一行分配一个唯一的字节偏移量作为 key,行的内容作为 value。
生成的 key-value 对会被传递给 Mapper。Mapper 程序的输出被称为中间数据(即 Reducer 能理解的键值对)。
例子:如果数据块大小为128MB,且预计输入数据量为10TB,那么就会有约82000个 Mapper。也就是说,InputFormat 决定了 Mapper 的数量。
因此,Mapper 的数量计算公式为:Mapper 数量 = (总数据大小)÷(输入分片大小)
例如,若数据大小为1TB,InputSplit 大小为200MB,则:Mapper 数量 = (1000 × 1000) ÷ 200 = 5000 个 Mapper。
// Mapper 代码示例
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
// 初始化方法,作业开始时调用,通常用于初始化资源
protected void setup(Context context) throws IOException, InterruptedException {
}
// 处理每条输入记录的核心方法,将输入的 key 和 value 映射成新的 key-value 输出
protected void map(KEYIN key, VALUEIN value, Context context) throws IOException, InterruptedException {
context.write((KEYOUT) key, (VALUEOUT) value);
}
// 清理方法,作业结束时调用,通常用于释放资源
protected void cleanup(Context context) throws IOException, InterruptedException {
}
// 运行方法,控制整个 Mapper 任务的执行流程
public void run(Context context) throws IOException, InterruptedException {
setup(context); // 调用初始化
try {
while (context.nextKeyValue()) { // 迭代读取每个 key-value 对
map(context.getCurrentKey(), context.getCurrentValue(), context); // 调用 map 方法处理
}
} finally {
cleanup(context); // 最后调用清理
}
}
}
2、Partitioner(分区器)
在 Hadoop MapReduce 框架中,Mapper 处理完数据后,Partitioner 需要确定如何将 Mapper 的输出正确分配给各个 Reducer。
默认分区器:
默认情况下,Hadoop 会对 <key, value> 键值对中的 key 进行哈希处理,以确定该数据应该分配给哪个 Reducer。Hadoop 使用的是 HashPartitioner 来执行这个操作。但有时 HashPartitioner 并不能达到理想的效果。
// HashPartitioner 代码示例
public class HashPartitioner<K2, V2> implements Partitioner<K2, V2> {
// 初始化配置项
public void configure(JobConf job) {
}
// getPartition 方法用于根据 key 的哈希值决定分区编号(即选择哪个 Reducer)
public int getPartition(K2 key, V2 value, int numReduceTasks) {
// 先通过 hashCode() 获取 key 的哈希值
// 与 Integer.MAX_VALUE 做与运算,确保结果为正数
// 然后对 Reducer 数量取模,保证结果在 0 ~ numReduceTasks-1 之间
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
其中 (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks 是核心代码,意思是对 key 生成一个哈希码。由于 hashCode() 可能产生负数,而分区编号不能为负数,因此使用该哈希值与 Integer.MAX_VALUE(即 Java 中 Integer 类型所能表示的最大正整数)进行按位“与”运算,以确保结果是正数。然后再对传入的 Reducer 数量 numReduceTasks 进行取模运算,最终得到合法且正确的分区编号。
自定义分区器:
当默认的 HashPartitioner 无法满足特定业务需求,或在实际应用中出现数据倾斜现象时,就需要使用自定义的分区器类,以满足相关的业务要求。
自定义分区器必须实现 Partitioner 接口,并重写两个核心方法:getPartition() 和 configure()。
getPartition()方法用于返回一个整数值,该值位于 0 到 Reducer 总数之间,用于决定当前的<key, value>键值对应该被发送到哪个 Reducer。configure()方法则使用 Hadoop 的作业配置(Job Configuration)来对分区器进行设置,使得分区数量等配置信息可以在上下文和内存中的 Configuration 模块中生效。
3、Combiner(合并器)
Combiner 相当于一个本地的 Reducer。它将 Mapper 输出的大量本地文件进行合并,从而减少 Map 与 Reduce 之间在网络上传输的数据量。
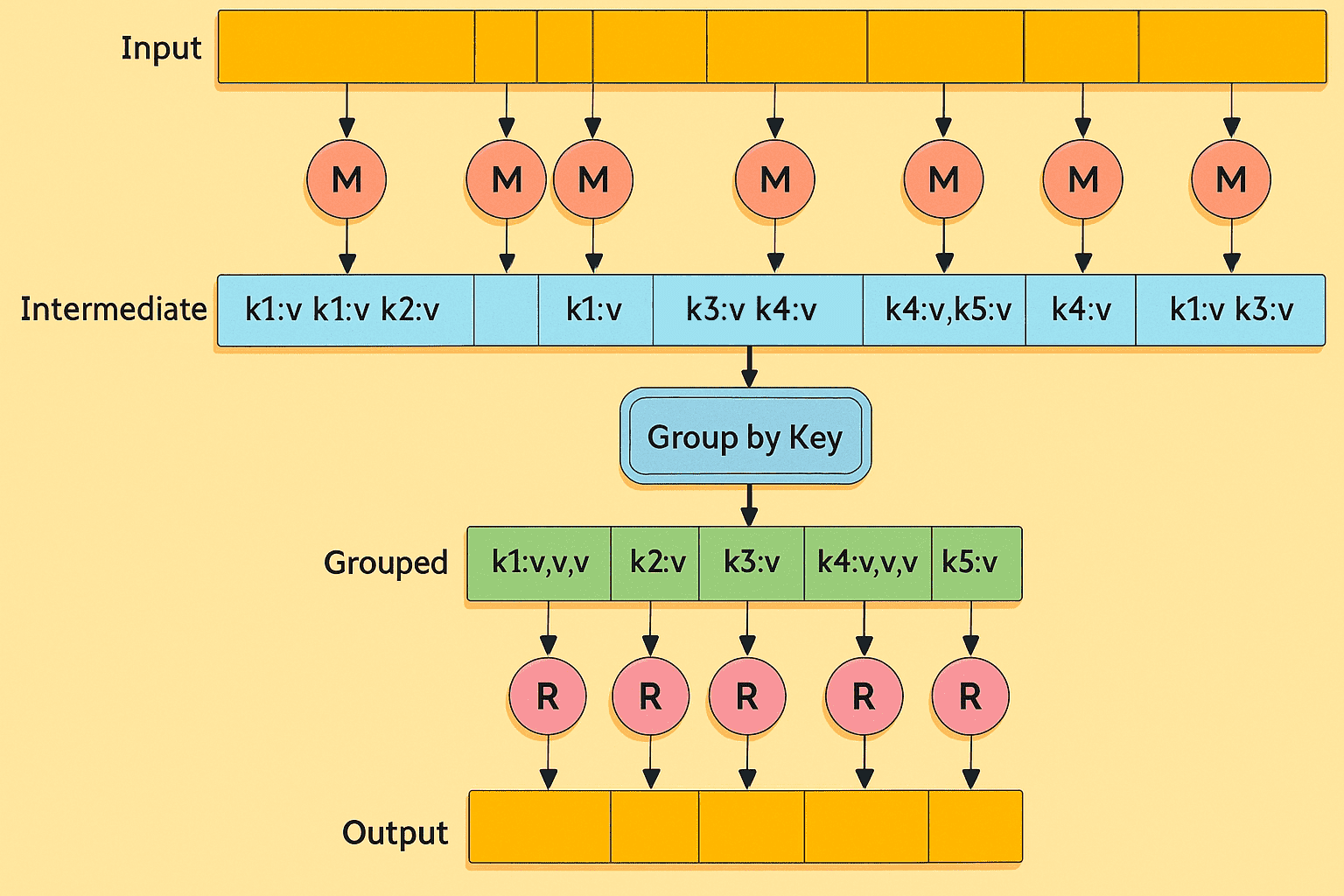
Combiner 最基本的功能是对本地的 key 进行聚合,对 Map 输出的 key 进行排序,并对 Map 输出中的 value 进行迭代计算。例如:
map: (key1,value1) → list(key2,value2)
combine: (key2,list(value2)) → list(key2,value2)
reduce: (key2,list(value2)) → list(key3,value3)
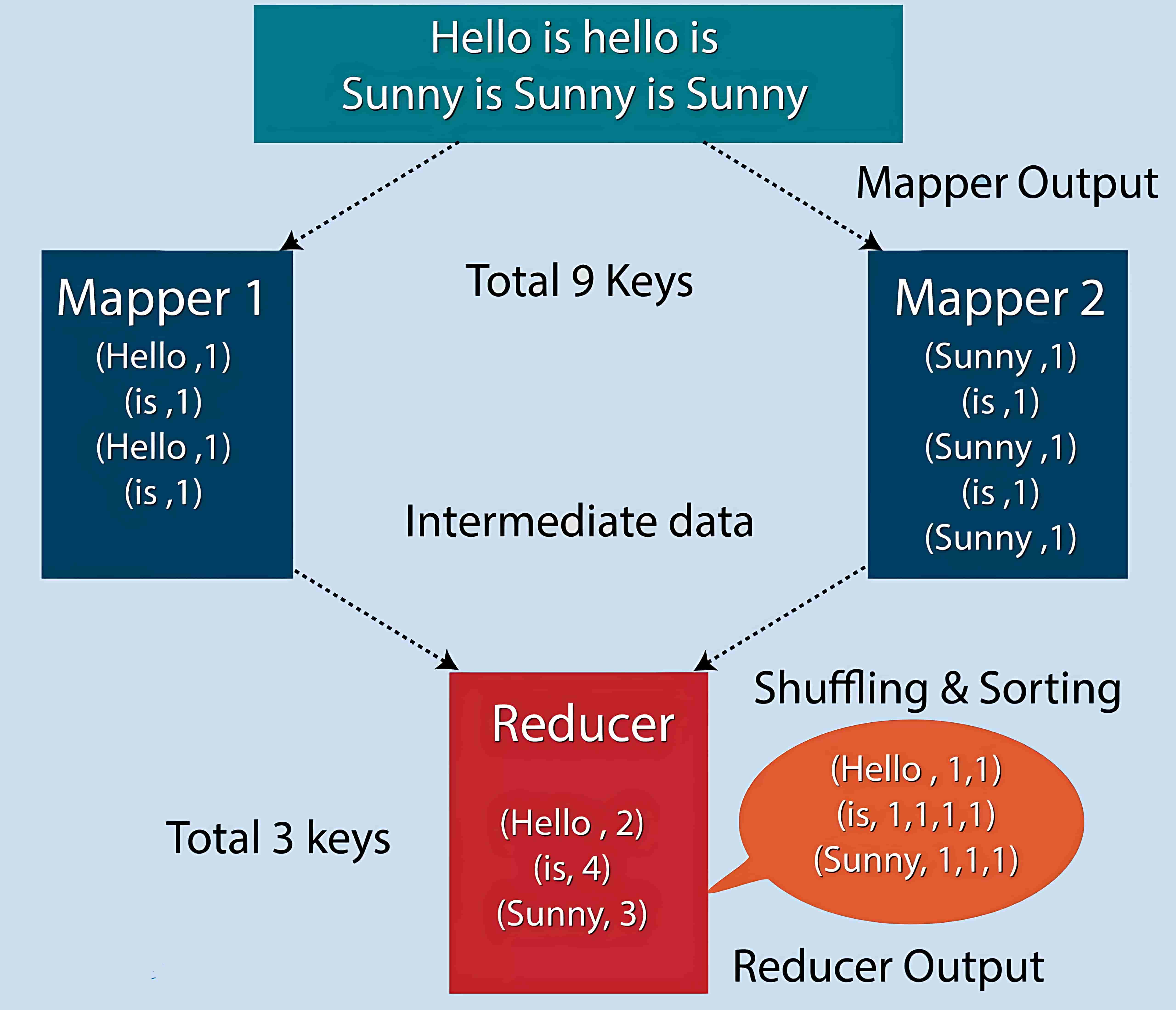
你可以使用 Combiner 在 MAP 端完成本地聚合,以减少网络上传输的数据量,从而提升性能。
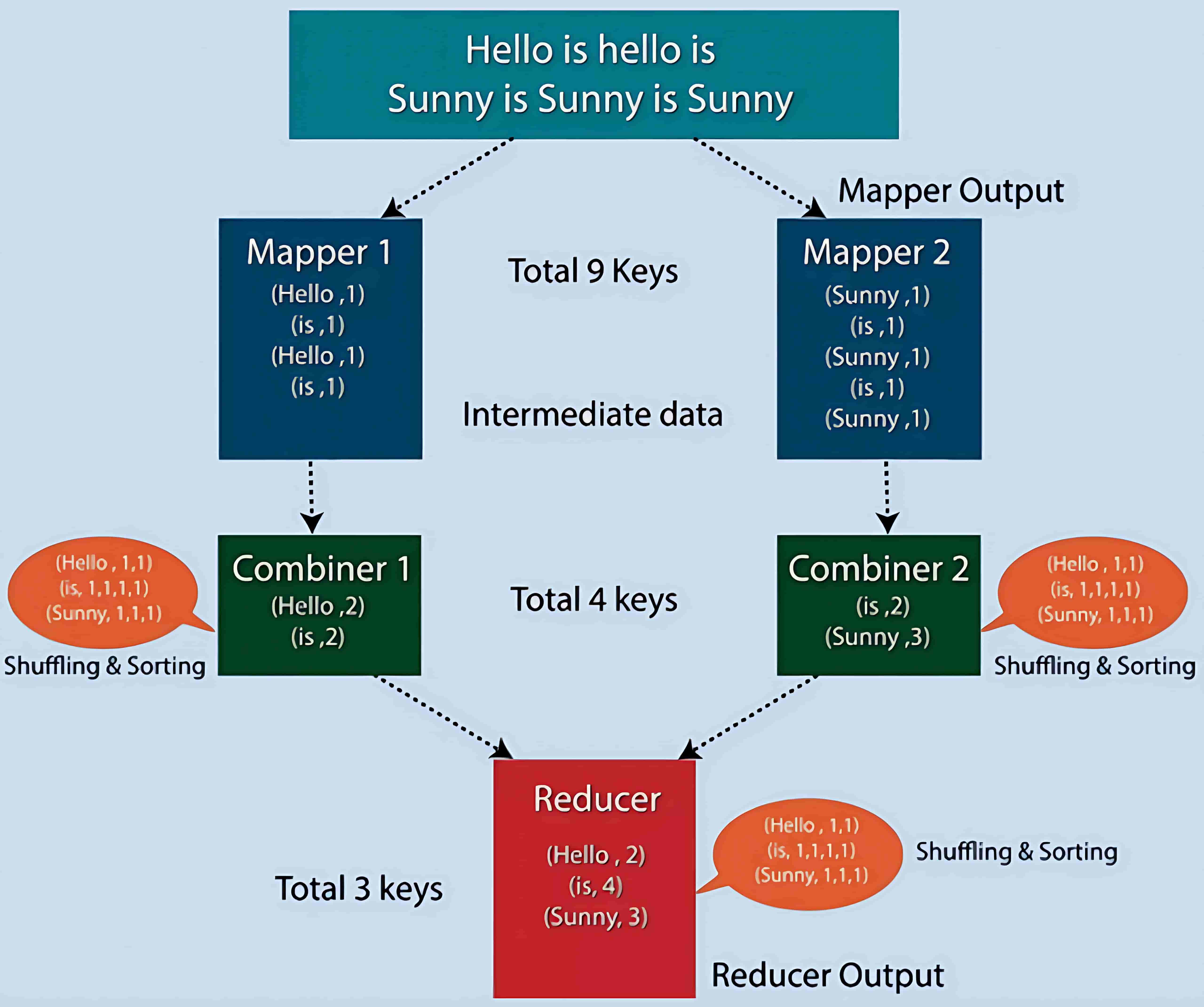
4、Reducer(归约器)
Hadoop 的 Reducer 将由 Mapper 生成的一组中间键值对作为输入,并在每个键值对上运行 Reducer 函数。用户可以以多种方式对这些 (key, value) 数据进行聚合、过滤和组合,以完成各种处理任务。Reducer 首先处理由 Map 函数生成的特定 key 的中间值,然后生成输出(可以是零个或多个键值对)。
每个 key 与 Reducer 之间是一对一映射。由于 Reducer 之间彼此独立,因此可以并行运行。用户可以自行决定 Reducer 的数量,默认情况下 Reducer 的数量为 1。
MapReduce 中 Reducer 的阶段:
如图所示,Hadoop MapReduce 中 Reducer 包括三个阶段:
-
Shuffle 阶段
在此阶段,Reducer 的输入是 Mapper 排序后的输出。在 Shuffle 阶段,框架通过 HTTP 协议从所有 Mapper 中获取对应分区的数据。
-
Sort 阶段
该阶段将来自不同 Mapper 的输入再次根据 key 进行排序,使得相同 key 的数据归并到一起。Shuffle 和 Sort 阶段是并发进行的。
-
Reduce 阶段
在经过 Shuffle 和 Sort 后,Reduce 任务开始对键值对进行聚合处理。通过调用
OutputCollector.collect()方法将 Reduce 任务的输出写入到文件系统中。需要注意的是,Reducer 的输出数据不会再进行排序。
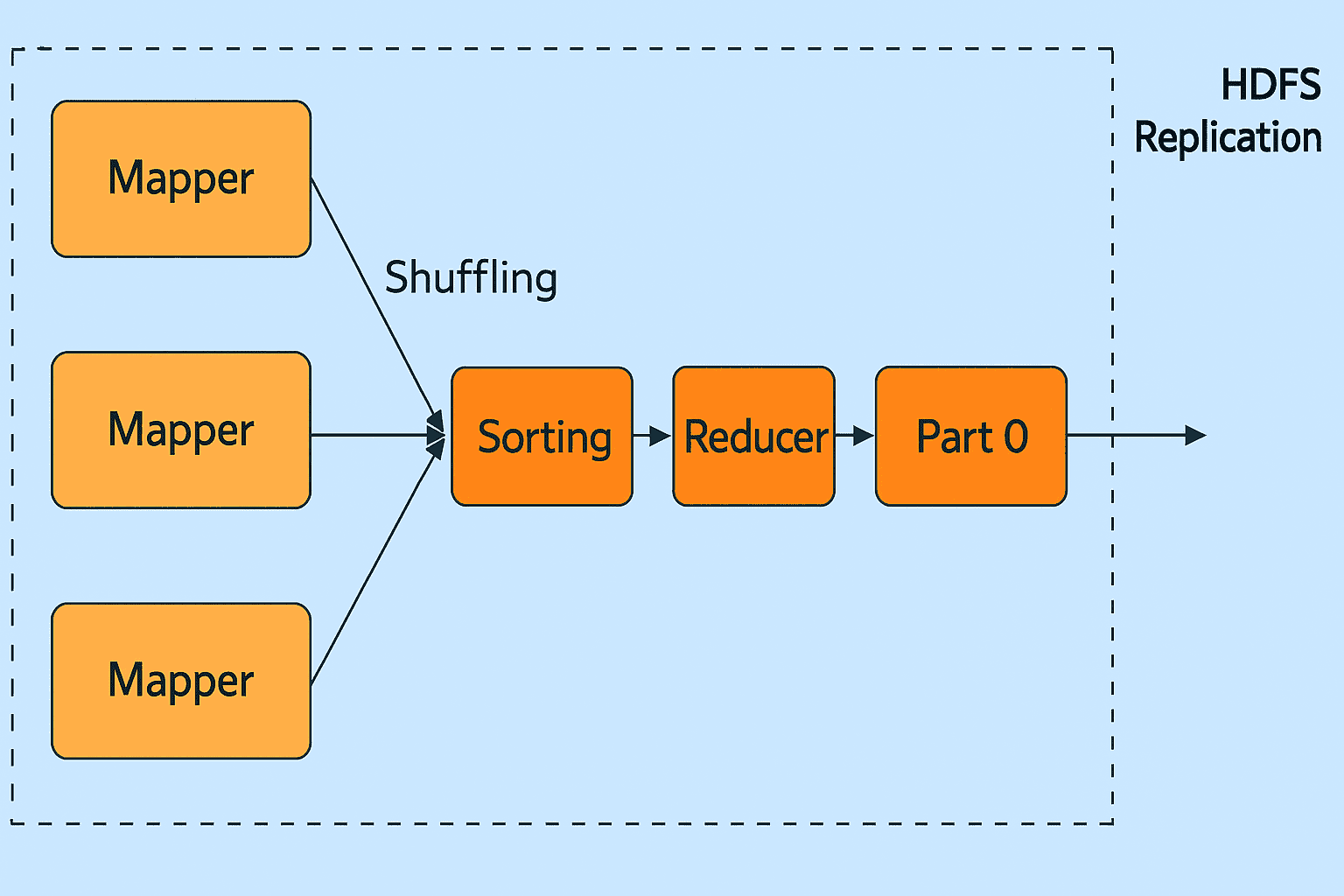
MapReduce 中 Reducer 的数量:
用户可以通过 Job.setNumreduceTasks(int) 方法来设置该作业的 Reducer 数量。
合理的 Reducer 数量通常是:0.95 或 1.75 ×(节点数 × 每个节点的最大容器数)。
- 如果使用 0.95,表示所有 Reducer 几乎可以在所有 Map 任务完成后立刻启动并开始传输 Map 的输出。
- 如果使用 1.75,则一部分较快节点会先完成第一批 Reducer 的工作,然后再启动第二批 Reducer,从而实现更好的负载均衡。
增加 MapReduce Reducer 数量的影响:
- 增加框架的开销(Framework overhead)
- 提高负载均衡能力
- 降低失败带来的代价(成本)
自定义 Reducer 类必须继承 Hadoop 内置的 Reducer 类,并重写其中的 reduce() 方法。
Reducer 类的源码需参考 Hadoop 提供的标准实现。
// 泛型定义:KEYIN 和 VALUEIN 是输入的 key 和 value 类型,KEYOUT 和 VALUEOUT 是输出的 key 和 value 类型
public class Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
// Context 是 Reducer 的上下文对象,用于获取输入数据以及写出结果
public abstract class Context
implements ReduceContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
}
// setup() 方法在 Reduce 任务开始前调用一次,可用于执行初始化操作(如资源创建)
protected void setup(Context context) throws IOException, InterruptedException {
}
// reduce() 是 Reducer 的核心逻辑:
// 对每个 key 调用一次,values 是该 key 对应的所有中间值(来自 Mapper 输出)
protected void reduce(KEYIN key, Iterable<VALUEIN> values, Context context
) throws IOException, InterruptedException {
for (VALUEIN value : values) {
// 将结果写入上下文中,默认将每个 key-value 对原样输出
context.write((KEYOUT) key, (VALUEOUT) value);
}
}
// run() 方法是 Reducer 的执行主流程,由 Hadoop 框架自动调用
public void run(Context context) throws IOException, InterruptedException {
// 首先执行初始化逻辑
setup(context);
try {
// 遍历所有 key,每次处理一个 key 及其对应的所有 value 集合
while (context.nextKey()) {
// 对当前 key 和对应的 value 集合调用 reduce() 处理逻辑
reduce(context.getCurrentKey(), context.getValues(), context);
// 获取当前 key 对应的 value 迭代器
Iterator<VALUEIN> iter = context.getValues().iterator();
// 如果当前的 values 迭代器是 ReduceContext.ValueIterator 类型,
// 说明在处理某些 key 时,value 的数量可能太多而无法全部加载进内存,
// Hadoop 会将一部分 value 临时写入磁盘(称为 backup store 备份存储)。
// 处理完该 key 后,需要调用 resetBackupStore() 方法清空或重置备份存储,
// 以释放磁盘空间并防止数据残留影响后续 key 的处理,保证资源效率和数据正确性。
if (iter instanceof ReduceContext.ValueIterator) {
((ReduceContext.ValueIterator<VALUEIN>) iter).resetBackupStore();
}
}
}
}
}
5、MapReduce Classic Example(MapReduce 经典示例)
下面将使用 Java 编写一个经典的 MapReduce 示例词频统计程序。
打开 IDEA,选择构建一个 Maven 项目。
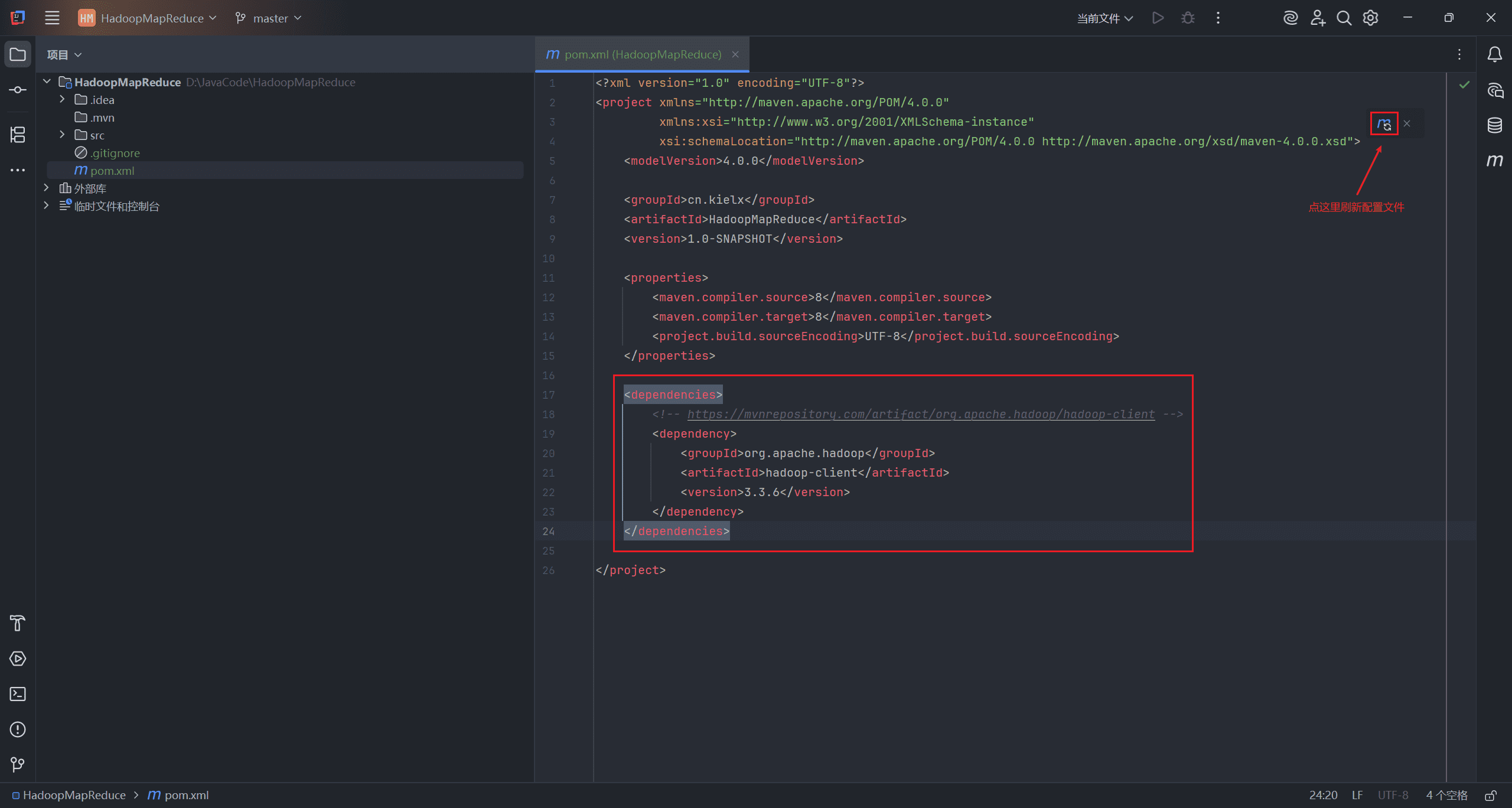
进入 maven 官方官网,搜索 hadoop-client,选择对应的 Hbase 版本,将依赖配置复制下来。
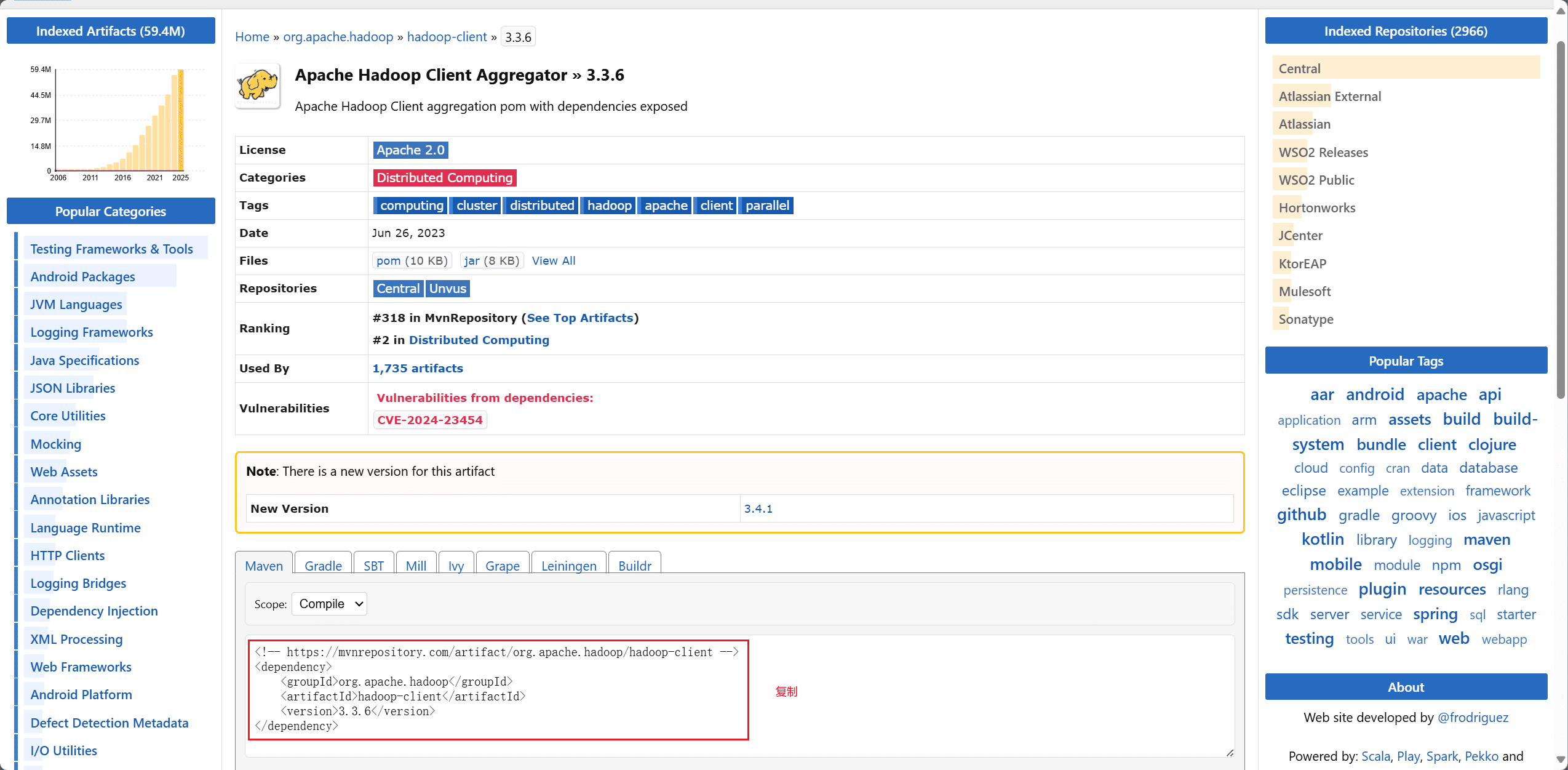
打开项目的 pom.xml 文件。
创建 <dependencies> 标签,将复制的配置粘贴进去,刷新配置文件。
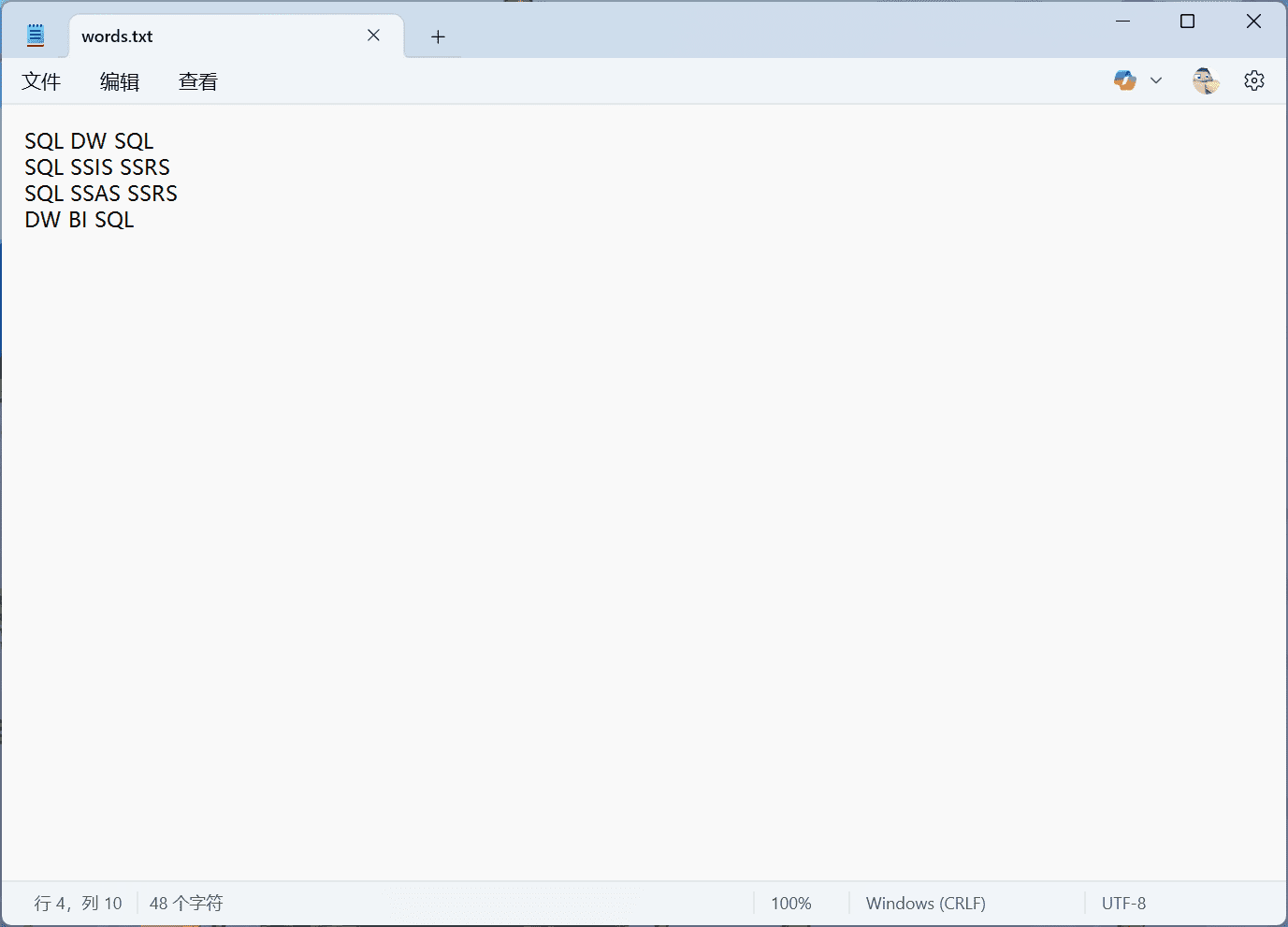
我们来看一个 MapReduce 的示例程序,以便对 MapReduce 环境中的实际运行方式有一个基本的了解。一个经典的入门示例是词频统计(word frequency statistics)。其目标是统计每个词在下列段落中出现的次数(作为 input.txt 文件):
SQL DW SQL
SQL SSIS SSRS
SQL SSAS SSRS
DW BI SQL
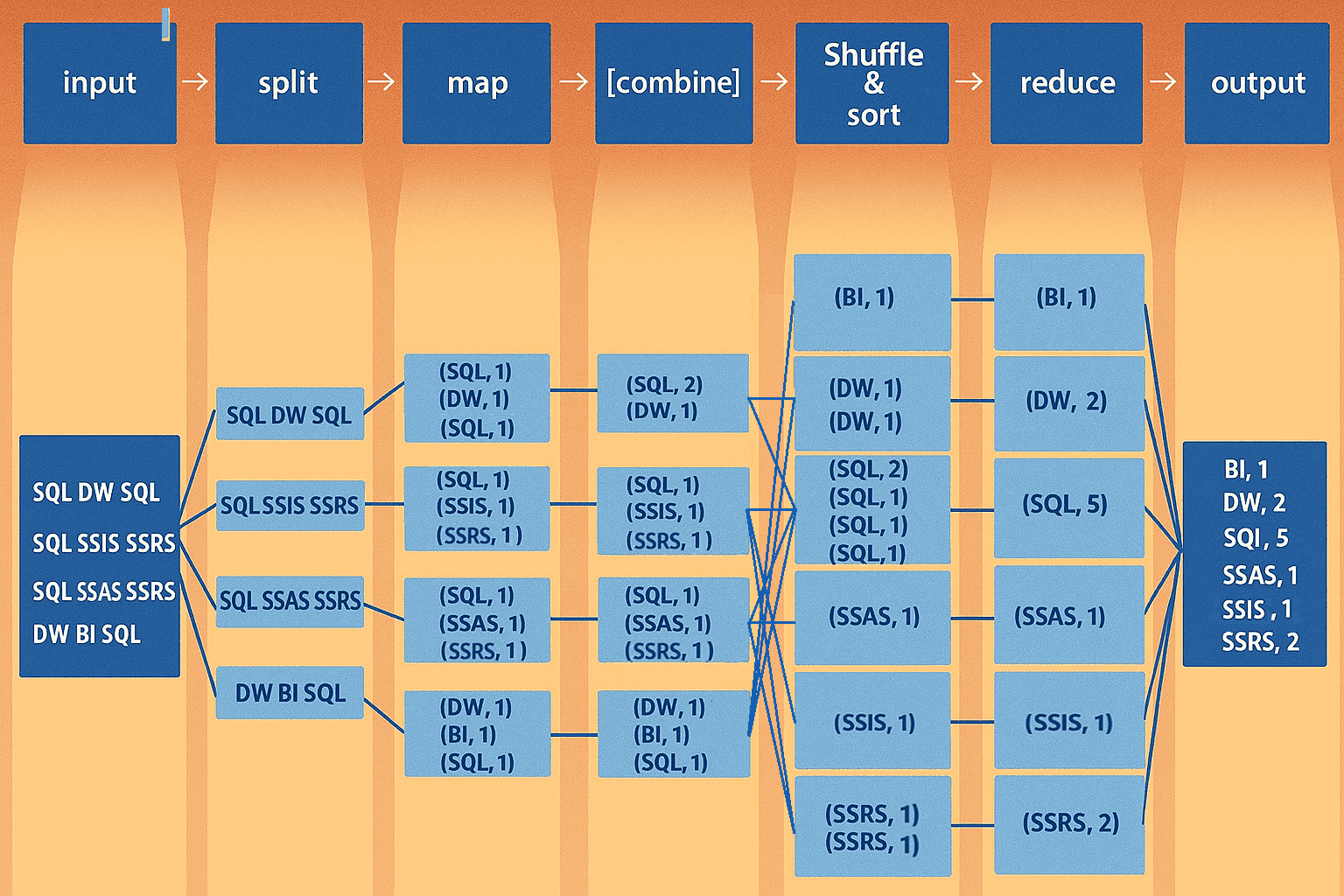
MapReduce 程序解释:
整个 MapReduce 程序基本上可以分为三个部分:
- Mapper 阶段代码
- Reducer 阶段代码
- Driver 代码
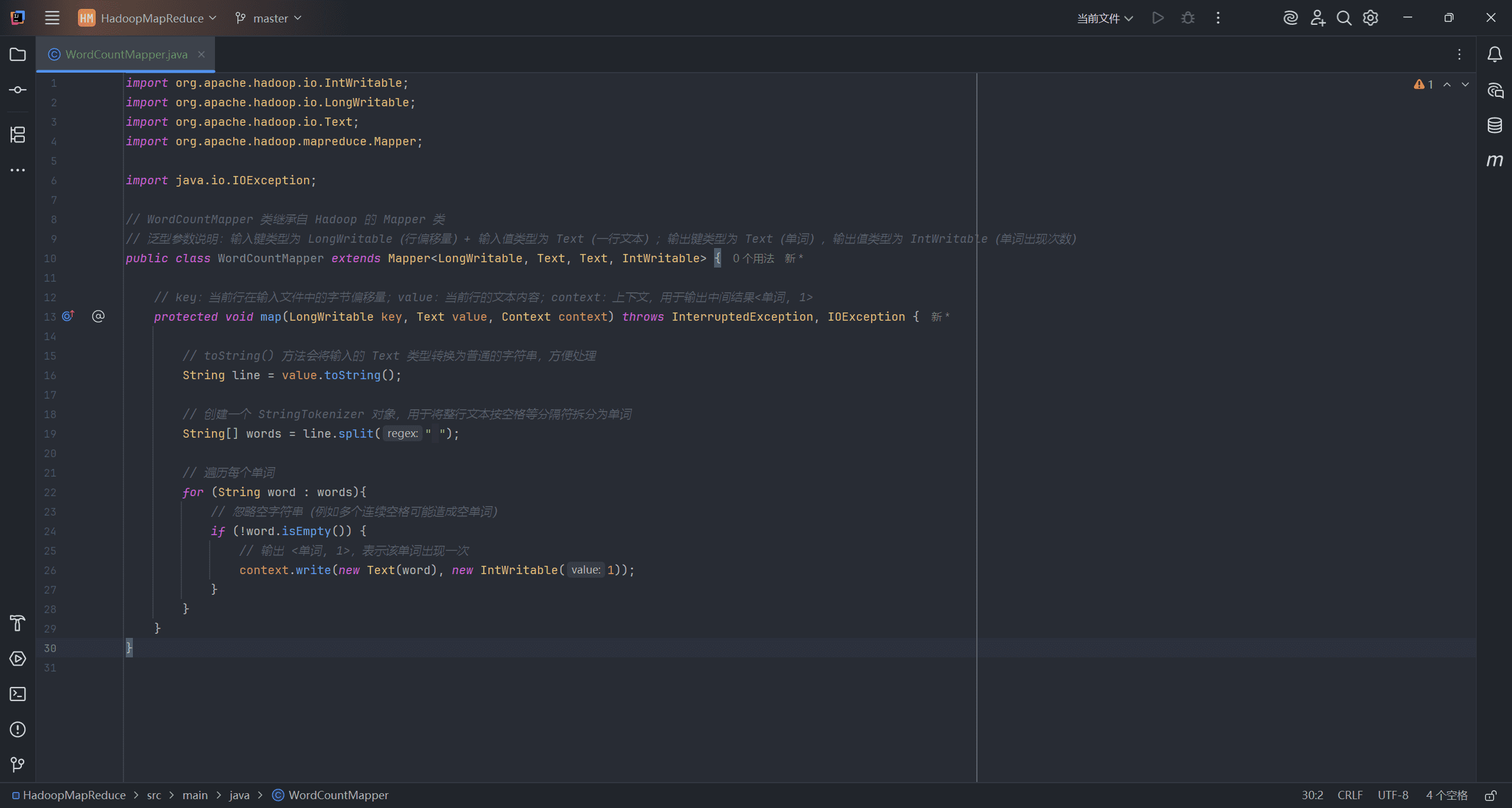
Mapper 阶段代码:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
// WordCountMapper 类继承自 Hadoop 的 Mapper 类
// 泛型参数说明:输入键类型为 LongWritable(行偏移量)+ 输入值类型为 Text(一行文本);输出键类型为 Text(单词),输出值类型为 IntWritable(单词出现次数)
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
// key:当前行在输入文件中的字节偏移量;value:当前行的文本内容;context:上下文,用于输出中间结果<单词, 1>
protected void map(LongWritable key, Text value, Context context) throws InterruptedException, IOException {
// toString() 方法会将输入的 Text 类型转换为普通的字符串,方便处理
String line = value.toString();
// 创建一个 StringTokenizer 对象,用于将整行文本按空格等分隔符拆分为单词
String[] words = line.split(" ");
// 遍历每个单词
for (String word : words){
// 忽略空字符串(例如多个连续空格可能造成空单词)
if (!word.isEmpty()) {
// 输出 <单词, 1>,表示该单词出现一次
context.write(new Text(word), new IntWritable(1));
}
}
}
}
Reducer 阶段代码:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
// WordCountReducer 类继承自 Hadoop 的 Reducer 类
// 泛型参数说明:输入键类型为 Text(单词),输入值类型为 IntWritable(一组表示次数的值);输出键类型为 Text(单词),输出值类型为 IntWritable(总次数)
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
// reduce 方法会被 Hadoop 自动调用,每处理一个单词及其所有的值时执行一次
// key:当前单词;values:该单词出现次数的集合;context:用于输出结果
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws InterruptedException, IOException {
// 用于累加该单词出现的总次数
int sum = 0;
// 遍历所有的值,累加求和
for (IntWritable val : values) {
// get() 方法获取 IntWritable 对象中的 int 值
sum += val.get();
}
// 输出 <单词, 总次数>
context.write(key, new IntWritable(sum));
}
}
Driver 代码:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static void main(String[] args) throws Exception {
// 创建配置对象
Configuration conf = new Configuration();
// 创建 Job 实例,并设置任务名称
Job job = Job.getInstance(conf, "WordCount");
// 设置主类,用于打包 JAR 时指定入口点
job.setJarByClass(WordCount.class);
// 设置 Mapper 和 Reducer 类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 设置 Mapper 输出键值类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 设置 Reduce 输出键值类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
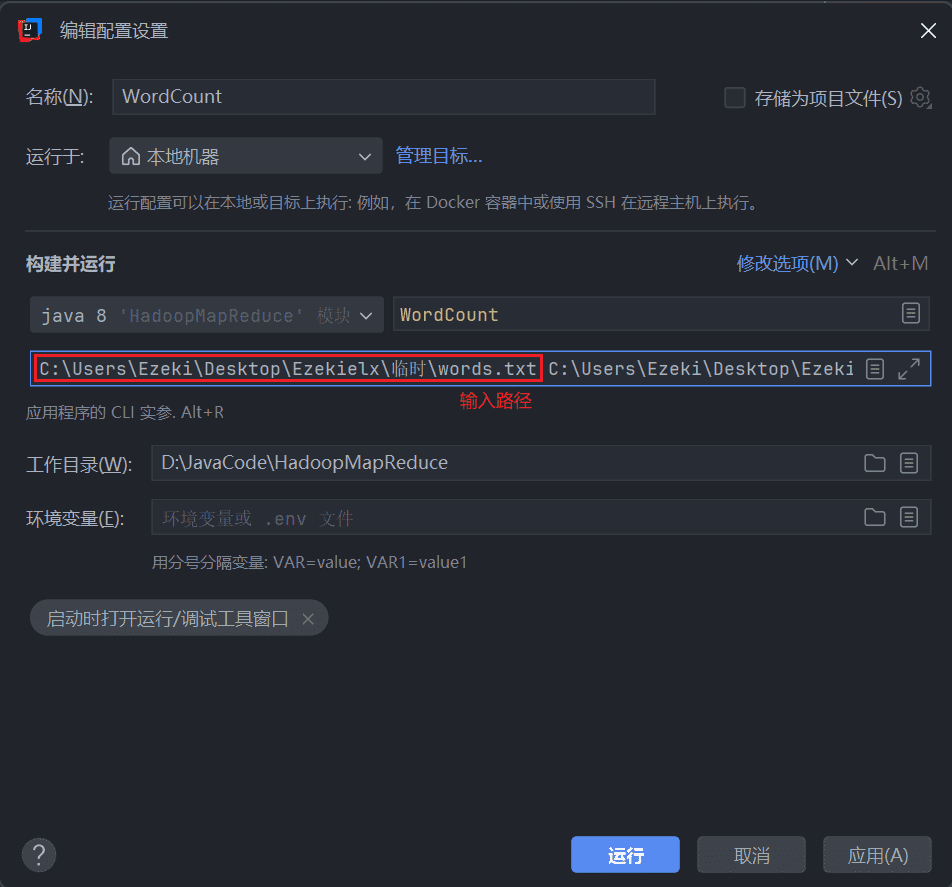
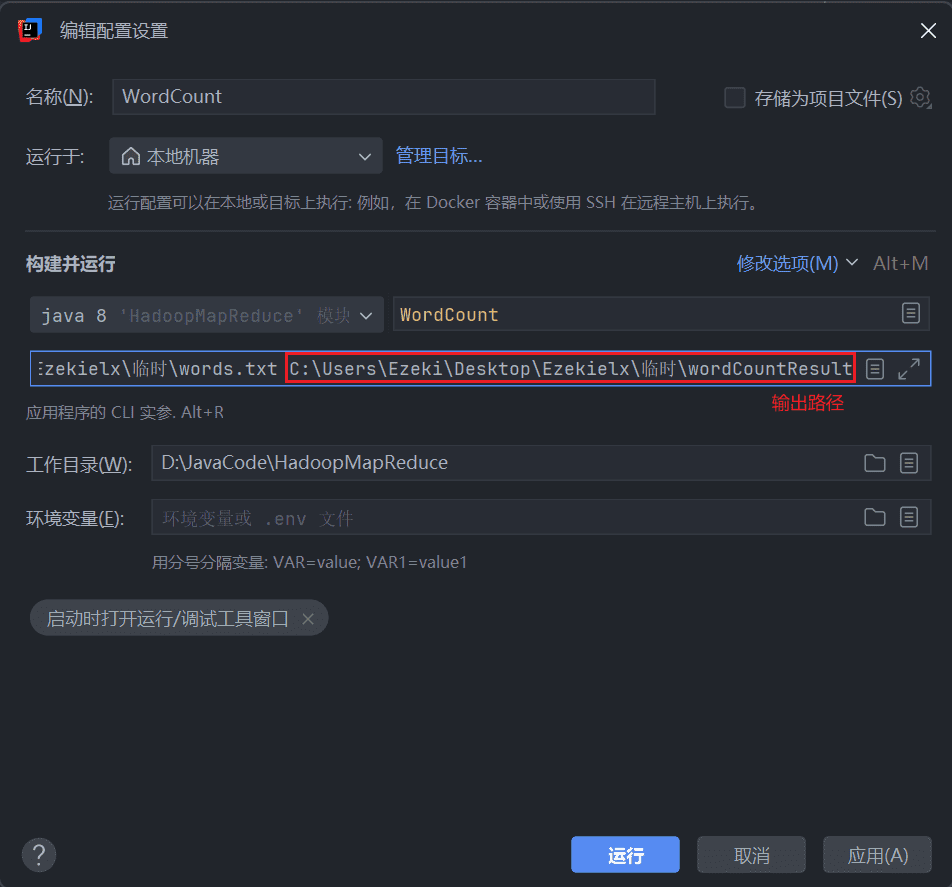
// 设置输入和输出路径(从命令行参数传入)
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
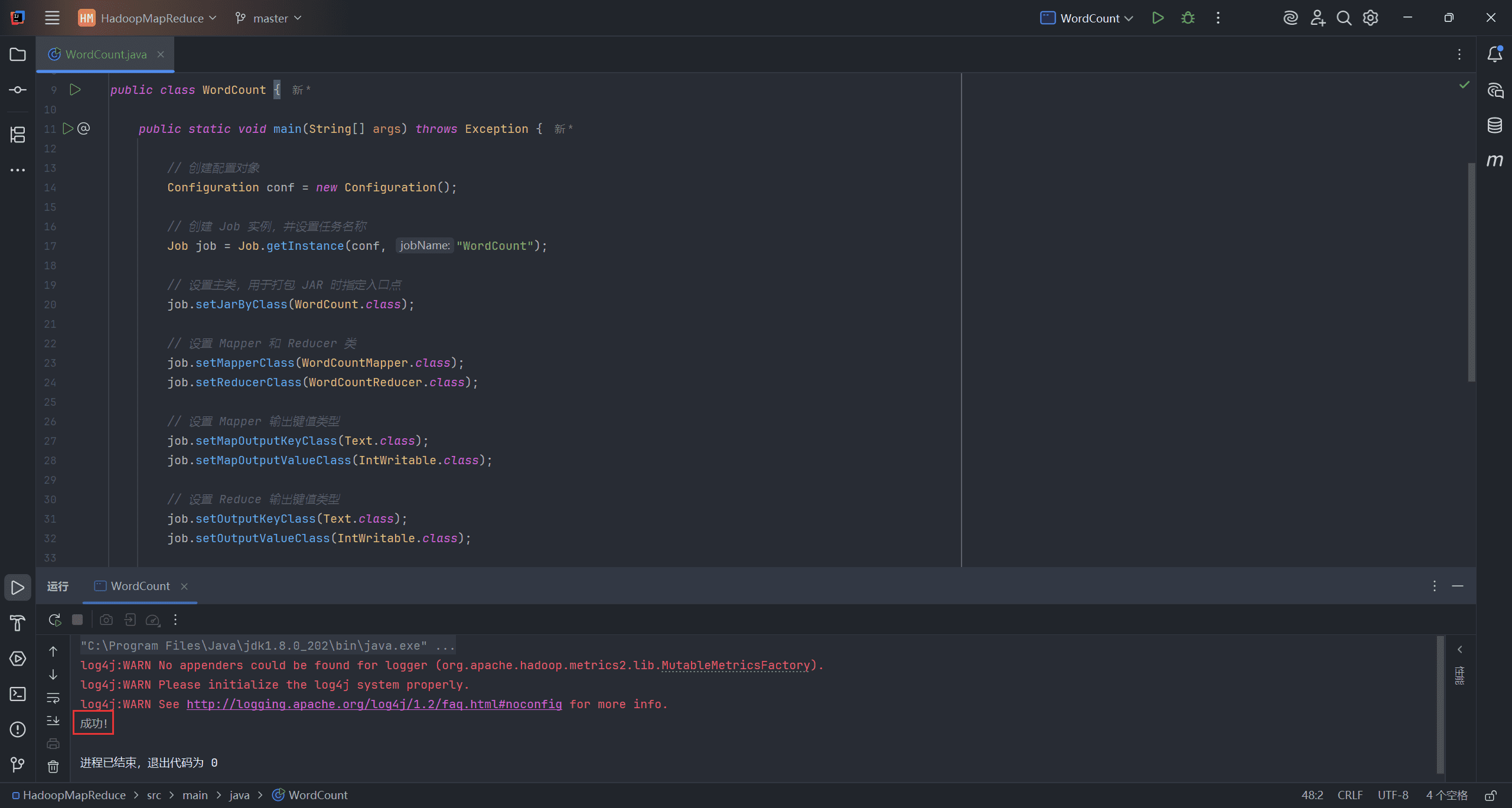
// 提交任务并等待完成
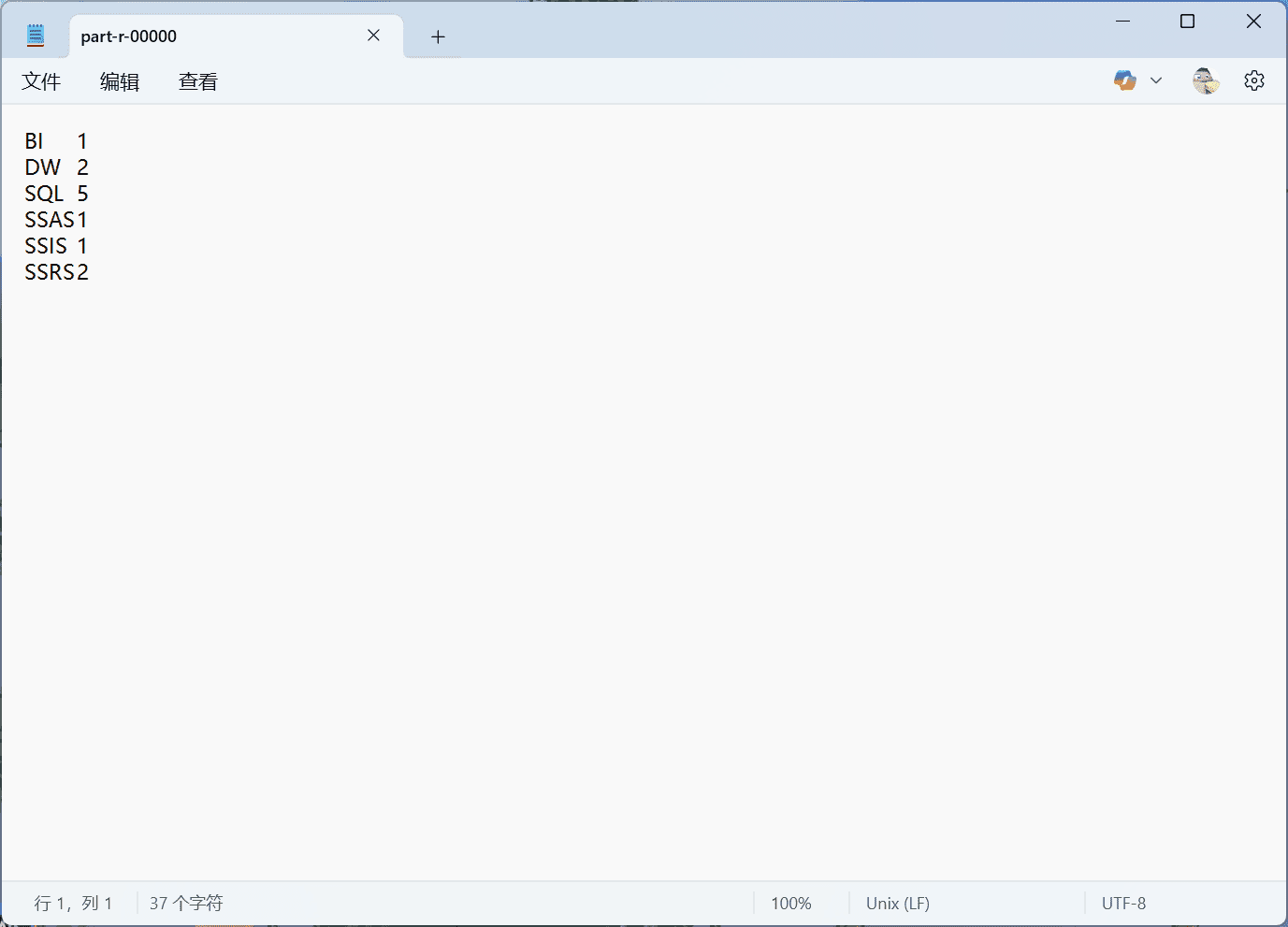
boolean completed = job.waitForCompletion(true);
// 打印结果
if (completed) {
System.out.println("成功!");
} else {
System.out.println("失败!");
}
}
}
三、Introduction to Job Scheduler(作业调度器简介)
Hadoop 系统中的一个重要组件是调度器,它根据一定的策略将系统中的空闲资源分配给各个作业。在 Hadoop 中,调度器是一个可插拔的模块,用户可以根据实际的应用需求自行设计调度器。目前 Hadoop 中常见的调度器有三种:默认的 FIFO 调度器、容量调度器(Capacity Scheduler)和公平调度器(Fair Scheduler)。
-
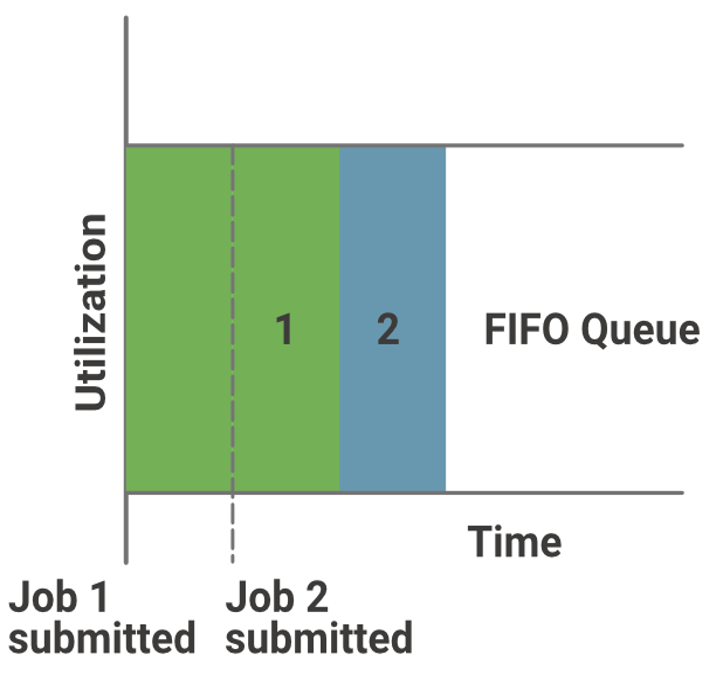
默认调度器 FIFO(先进先出)
在早期的 Hadoop Map/Reduce 计算架构中,JobTracker 使用先进先出(FIFO,First In First Out)算法进行作业调度。所有用户提交的作业都会进入一个队列,JobTracker 根据作业的优先级和提交的先后顺序来选择执行的作业。
**优点:**调度算法简单直接,JobTracker 的工作负载较轻。
**缺点:**忽略了不同作业之间的需求差异。例如,如果某个作业(如大规模数据的统计分析)长时间占用计算资源,那么之后提交的交互式作业可能会被延迟执行,从而影响用户体验。
-
容量调度器(Computing Capacity Scheduler)
在容量调度器中,我们使用多个作业队列来调度任务,也就是说,它允许多个用户共享一个大型的 Hadoop 集群。每个作业队列都有对应的一些 slot(任务槽位)或集群资源,用于执行作业操作。每个队列有自己的 slot 来运行任务。
当只有一个队列中有任务要执行时,该队列的任务也可以使用其他空闲队列的 slot(资源);而当其他队列中有新任务进入时,原本借用的 slot 会被归还,以便新队列使用自己的资源运行作业。
容量调度器还提供了一种抽象机制,可以查看哪个用户或作业占用了更多的集群资源或 slot,以避免某个用户或应用程序过度占用集群资源。
**优点:**非常适合处理多个客户端或有优先级要求的作业在同一个 Hadoop 集群中运行,能够最大化 Hadoop 集群的整体吞吐量。
**缺点:**更加复杂,并非所有人都容易配置和使用。
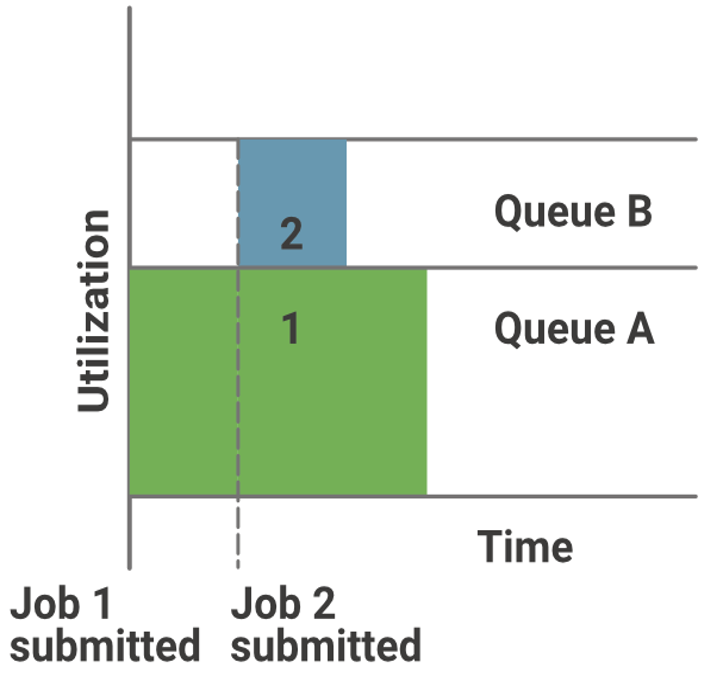
-
公平调度器(Fair Scheduler)
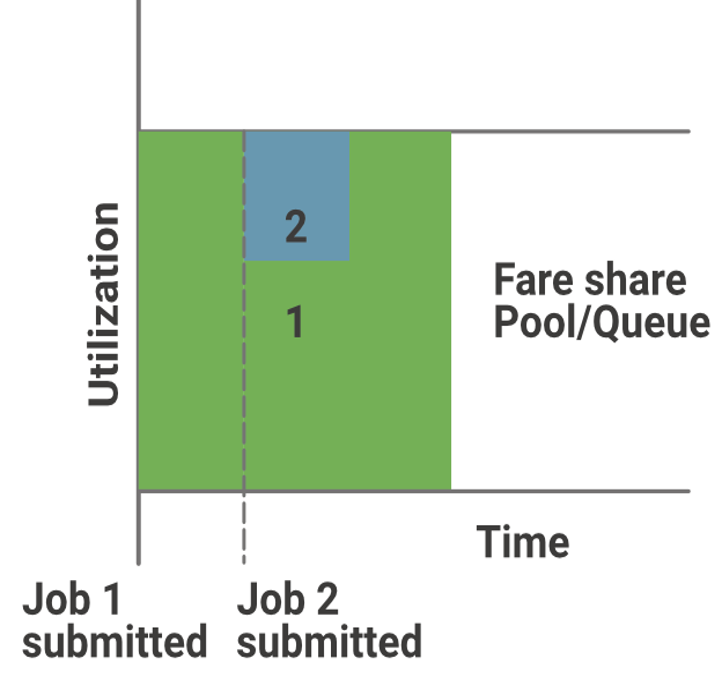
公平调度器与容量调度器非常相似,它在调度时会考虑作业的优先级。有了公平调度器,YARN 应用可以在大型 Hadoop 集群中共享资源,而且这些资源是动态分配的,因此不需要提前指定资源容量。
资源分配的方式确保了集群中的所有应用程序能够获得相等的运行时间。公平调度器主要基于内存来做调度决策,也可以配置为基于 CPU 来运行。
在公平调度器中,如果同一个队列中有高优先级作业出现,调度器会通过替换掉部分已分配 slot(槽位),使得高优先级任务能够与原任务并行处理。
**优点:**分配给每个应用的资源依赖于其优先级,可以限制某个资源池或队列中并发运行的任务数量。
**缺点:**需要进行配置后才能使用。