一、Hadoop Architecture and Components(Hadoop 架构和组件)
Hadoop 采用主从拓扑结构。在这种拓扑结构中,我们有一个主节点(Master Node)和多个从节点(Slave Nodes)。主节点的功能是向各个从节点分配任务并管理资源,而从节点执行实际的计算。从节点存储真实数据,而主节点存储元数据(即关于数据的数据,即记录数据存放位置)。
1、Hadoop Core Components(Hadoop 核心组件)
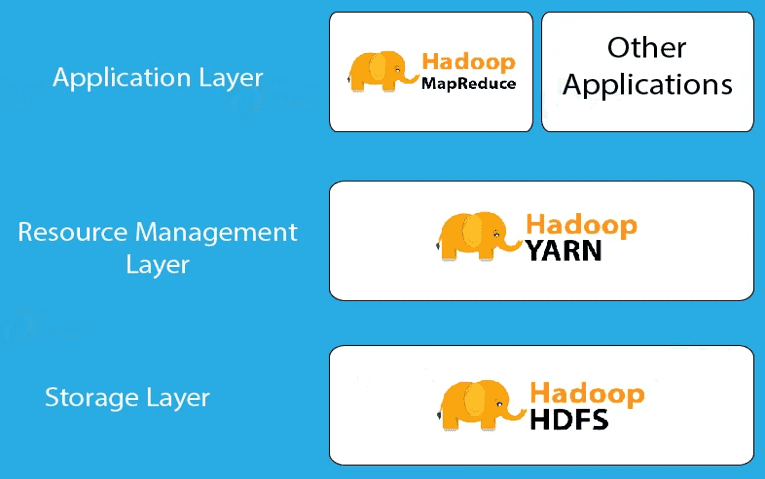
Hadoop 是一个框架,允许在多个节点系统上存储大规模数据。Hadoop 架构通过多个组件实现数据的并行处理:
- Hadoop HDFS:在多个从节点上存储数据。
- Hadoop YARN:用于Hadoop集群的资源管理。
- Hadoop MapReduce:用于分布式数据处理。
2、Hadoop Architecture(Hadoop 架构)
- HDFS(Hadoop 分布式文件系统):Hadoop生态系统中的主要存储单元。HDFS 使 Hadoop 能够快速访问数据,并具备良好的扩展性。
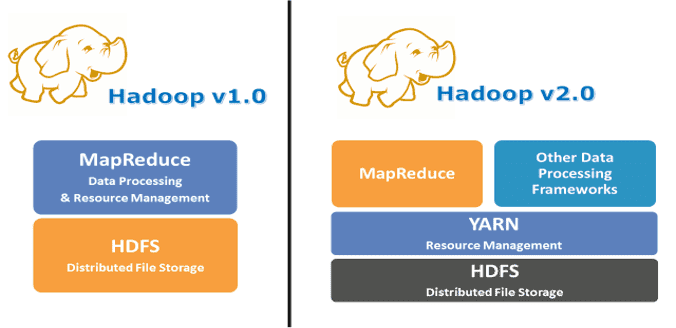
- YARN(Yet Another Resource Negotiator):是 Hadoop 2.0 版本后引入的更新,负责资源管理和作业调度。
- MapReduce:是一种基于 Java 编程语言的软件数据处理模型,由 Map(映射)和 Reduce(归约)两部分组成。 MapReduce 处理流程可以执行各种大数据操作,如数据过滤和排序等。
二、Hadoop HDFS Architecture(Hadoop HDFS架构)
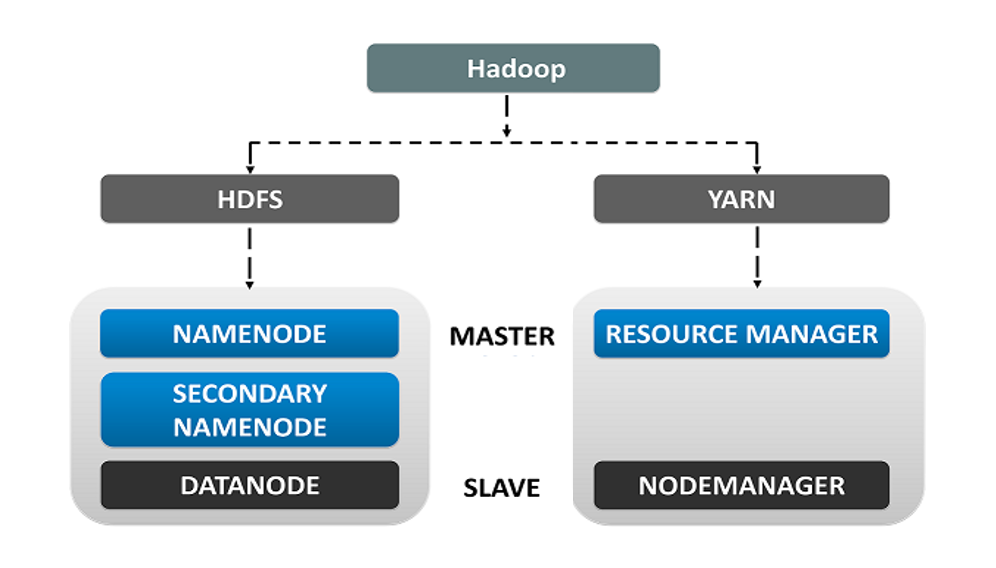
HDFS(Hadoop Distributed File System,Hadoop 分布式文件系统)是 Hadoop 的数据存储系统。HDFS 将数据单元拆分为更小的单元,称为数据块(Blocks),并以分布式方式存储。HDFS 运行两个守护进程:主节点(NameNode)和从节点(DataNode)。
1、HDFS Core Components(HDFS 核心组件)
HDFS 由以下 3 个组件组成:
- NameNode:在内存(RAM)和磁盘上存储元数据。
- Secondary NameNode:在磁盘上存储 NameNode 的元数据副本。
- DataNode:以数据块的形式存储实际数据。
Client(客户端):客户端是一个充当服务提供者的客户端(如命令行或程序),它请求资源并向 Hadoop 集群发送请求。具体职责如下
- 文件共享:当文件上传到 HDFS 时,客户端会将文件拆分为多个数据块并存储到 DataNode 中。
- 与 NameNode 交互:获取文件位置信息。
- 与 DataNode交互:执行数据的读取或写入操作。
- 提供 HDFS 管理命令:如启动或关闭 HDFS,以及使用
start-all.sh命令启动集群。
NameNode 和 DataNode:
- NameNode(主节点):HDFS 的核心组件,负责存储元数据、监控从节点的运行状态,并向 DataNode 分配任务。
- DataNode(从节点):存储实际数据,并通过 心跳机制 向 NameNode 报告其运行状态和任务状态。如果 DataNode 未能响应NameNode,则该节点被视为失效,并由 NameNode 将任务重新分配给其他可用的 DataNode。
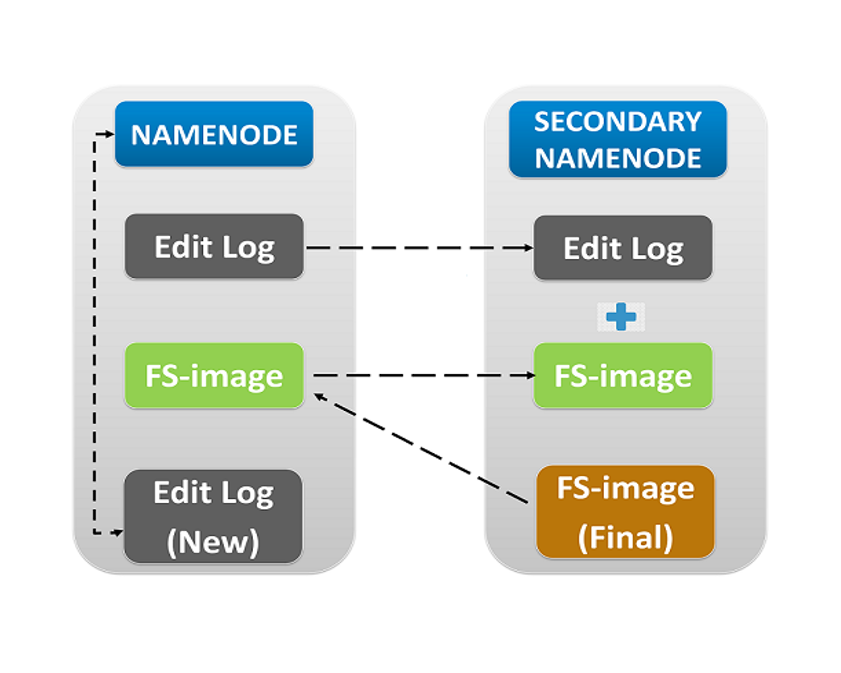
- Secondary NameNode(辅助NameNode):并不是 NameNode 的备份,而是充当缓存(Buffer),定期将 NameNode 的 **Edit-log(日志)**合并到 **FS-image(文件系统快照)**中,以减少 NameNode 的存储负担。
2、Block in HDFS(HDFS 数据块)
HDFS 是 Hadoop 的存储层,数据分布在多个服务器上。**数据块(Block)**是计算机系统中最小的存储单元。在 Hadoop 中,默认的数据块大小为 128MB。这些数据块会被随机分配并存储在不同的从节点(DataNode)上。HDFS 会将大规模数据拆分成多个 128MB 的数据块,并分布存储在多个机器上。

3、Replication Management(HDFS 复制管理)
HDFS 具有很高的容错能力,它采用**副本机制(Replication)**来处理故障,即同一份数据会在不同的 DataNode 上存储多个副本,以确保即使某个 DataNode 失效,数据仍然可以从其他节点读取。
为了提供容错能力,HDFS 使用复制技术,将数据块(Blocks)复制多份,并存储在不同的 DataNode 上。**副本因子(Replication Factor)**决定了每个数据块的副本数量,默认值为 3,但可以根据需求进行配置。
复制管理规则
- 同一个 DataNode 上不能存放相同的数据块。
- 在启用机架感知(Rack Awareness)模式时,同一数据块的所有副本不能存放在同一个机架(Rack)上。
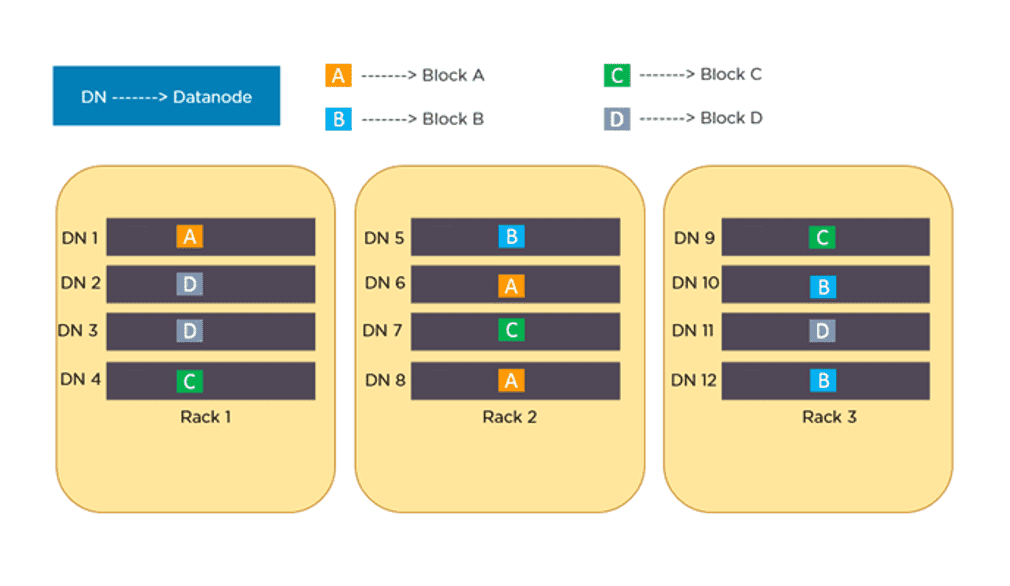
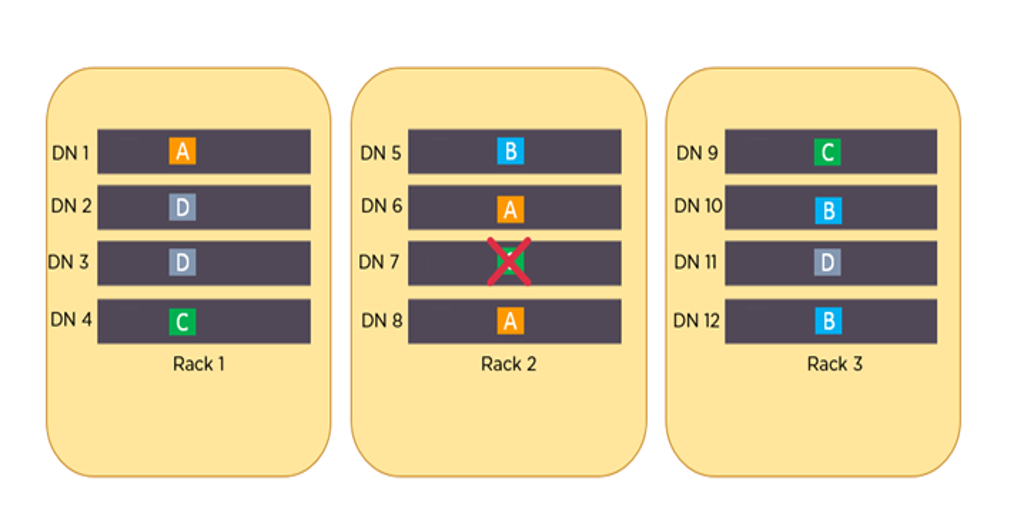
例如,假设数据块 A、B、C 和 D 被复制 3 次,并分布在不同的机架上。如果 DataNode 7 宕机,仍然可以从 Rack 1 的 DataNode 4 和 Rack 3 的 DataNode 9 访问数据块 C,从而确保数据的高可用性。
4、Advantages and Disadvantages of HDFS Architecture(HDFS 架构的优缺点)
优点
✔ 高容错性:数据会自动存储多个副本,丢失后可自动恢复,提高系统可靠性。
✔ 适合大数据处理:可处理 PB 级别数据,支持存储超过百万个文件。
✔ 支持流式数据读取:确保数据一致性,适用于大规模数据处理。
✔ 可部署在低成本硬件上:通过**多播机制(Multicast Mechanism)**提高可靠性,降低硬件成本。
缺点
✘ 不适用于低延迟数据访问:例如毫秒级存储需求的应用场景。
✘ 不适合存储大量小文件:小文件会占用大量 NameNode 内存,导致存储效率低下。小文件的查找时间可能超过读取时间,不符合 HDFS 的设计目标。
✘ 不支持并发写入和随机修改:
- 文件只能由一个线程写入,不支持多线程同时写入。
- 仅支持追加写入(Append),不支持随机修改文件内容。
三、Hadoop's YARN Architecture(Hadoop YARN 架构)
Hadoop YARN(Yet Another Resource Negotiator)是 Hadoop 的集群资源管理层,负责资源分配和作业调度。YARN 作为 Hadoop 2.0 版本引入的组件,是 Hadoop 体系结构中HDFS 和 MapReduce 之间的中间层。
1、Why YARN?(为什么需要 YARN?)
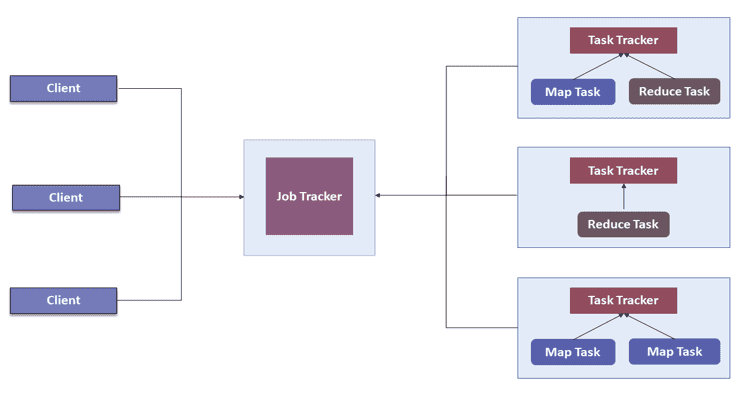
在 Hadoop 1.0(MRV1,MapReduce Version 1)中,MapReduce 同时执行数据处理和资源管理的功能。
MRV1 架构的问题:
- Job Tracker 负责资源分配、调度和任务监控。它将 map 和 reduce 任务分派给多个下级进程,称为 Task Trackers。Task Trackers 会定期向 Job Tracker 报告进度。
- 这种设计由于只有一个 Job Tracker,因此在扩展性方面存在瓶颈。实际上,在拥有 5000 个节点、4 万个并发任务的集群上,这种架构就已经达到极限。
- 除了扩展性的问题外,MRV1 在计算资源的利用率方面也不高。同时,Hadoop 框架也被限制在只能运行 MapReduce 类型的任务。
为了解决上述问题,在 Hadoop 2.0 中引入了 YARN。
YARN 的基本思想是将资源管理和作业调度的职责从 MapReduce 中分离出来。YARN 开始让 Hadoop 能够运行非 MapReduce 类型的作业。
2、YARN Core Components (YARN 核心组件)
YARN 包含以下几个关键组件:
- ResourceManager(资源管理器):每个集群一个
- ApplicationMaster(应用主控):每个应用一个
- NodeManagers(节点管理器):每个节点一个
- Container(容器)
YARN 的基本原理是将资源管理和作业调度/监控功能分离到不同的守护进程中:
NodeManager(NM):监控容器的资源使用情况(如 CPU、内存、磁盘、网络等),并定期向 ResourceManager 发送信号(前面提到过的心跳机制)。
ApplicationMaster(AM):管理单个应用的资源需求,与调度器交互以获取所需资源,并与 NodeManager 协作来执行和监控任务。
Container(容器):容器封装了一组资源(如内存、CPU 和网络带宽),YARN 根据资源情况进行分配。容器为应用分配使用特定资源的权限。
ResourceManager(RM):集群资源的总管,负责跟踪集群中所有可用资源及各个 NodeManager 的资源贡献情况。包含两个主要子组件:
- Scheduler(调度器):根据应用需求,为不同的运行中应用分配资源。这是一个“纯调度器”,不会监控应用状态,也不会重新调度因软硬件错误失败的任务。
- Application Manager(应用管理器):接收客户端提交的作业,并在 ApplicationMaster 失败时进行重启。
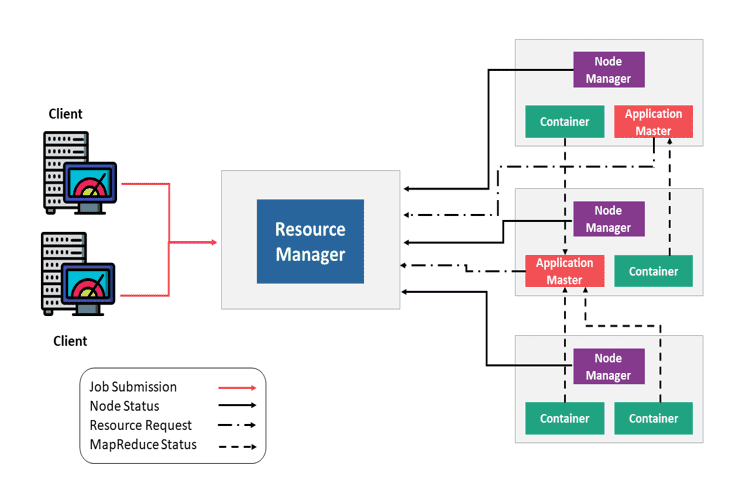
Hadoop YARN 的应用提交过程:
- 提交作业
- 获取 Application ID
- 创建 Application Submission Context(应用提交上下文)
- 启动容器启动流程
- 4a. 启动容器
- 4b. 启动 ApplicationMaster
- 分配资源
- 启动容器执行
- 6a. 创建容器
- 6b. 启动任务
- 执行应用
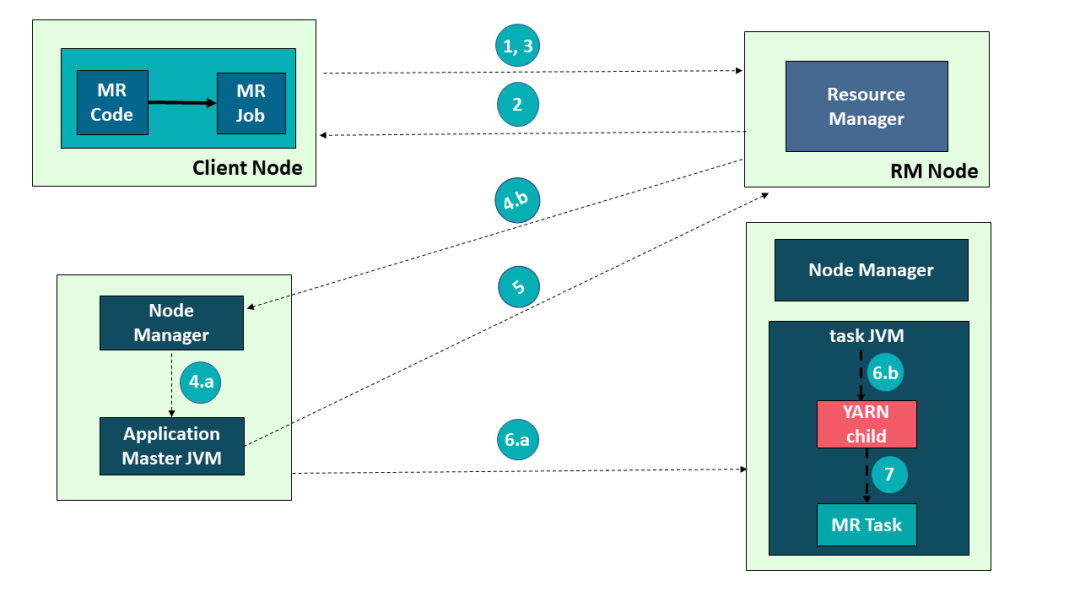
Hadoop YARN 中的应用执行流程
Apache Hadoop YARN 的应用执行涉及以下步骤:
- 客户端提交一个应用程序
- ResourceManager 分配一个容器来启动 ApplicationMaster
- ApplicationMaster 向 ResourceManager 注册
- ApplicationMaster 向 ResourceManager 请求更多容器资源
- ApplicationMaster 通知 NodeManager 启动容器
- 应用程序代码在容器中执行
- 客户端通过 ResourceManager 或 ApplicationMaster 来监控应用程序状态
- 应用程序完成后,ApplicationMaster 向 ResourceManager 注销
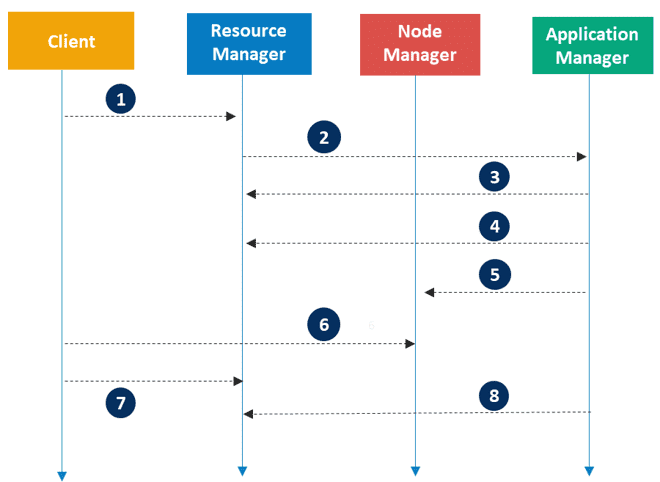
四、Hadoop's MapReduce Architecture(Hadoop 的 MapReduce 架构)
MapReduce 是 Hadoop 的处理层,它是一种编程模型,设计用于通过将工作划分为一组独立任务来并行处理海量数据。
你只需将业务逻辑嵌入 MapReduce 的工作方式中,其他的事务由框架自动完成。用户将一个完整的作业提交给主节点,主节点再将其分解为若干小任务并分发给从属节点执行。
1、Traditional Way for parallel and distributed processing(传统的并行和分布式处理方式)
我们来了解一下在没有 MapReduce 框架之前,传统方式是如何进行并行和分布式处理的。
举个例子:假设我们有一个天气日志,记录了从 2000 年到 2015 年每天的平均气温。现在我们想要计算出每一年中气温最高的一天。
我们会将数据拆分成更小的部分或数据块,并将它们存储在不同的机器上。然后,我们会在各自的机器上找出其对应部分中气温最高的一天。最后,我们将每台机器返回的结果汇总,得出最终的输出。
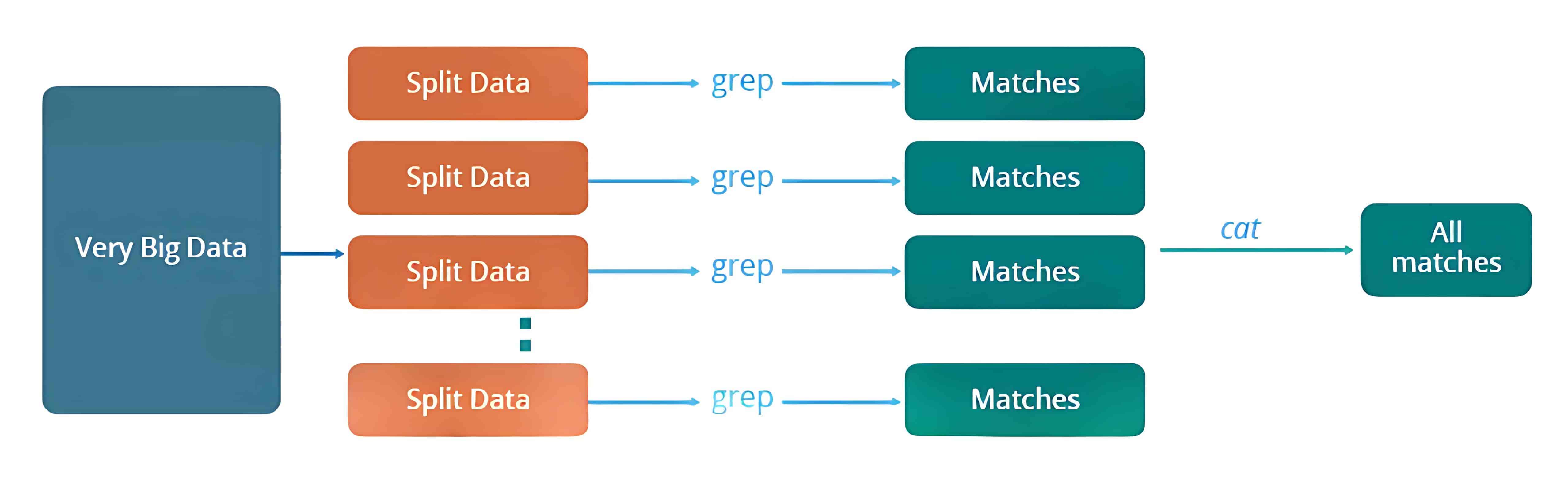
下面是这种传统方法所面临的一些问题:
- 关键路径问题:如果某台机器处理任务出现延迟,整个处理流程都会被拖延。
- 可靠性问题:如果某台正在处理部分数据的机器发生故障怎么办?
- 数据平均划分问题:如何将数据合理地拆分,使每台机器分到的任务量大致相等?
- 分块失败问题:如果某个数据块所在的机器未能返回结果,那就无法计算出最终结果。
- 结果汇总问题:需要有一种机制来将每台机器产生的中间结果进行汇总,得到最终结果。
为了解决这些问题,我们有了 MapReduce 框架。它允许我们执行这样的并行计算,而无需担心诸如可靠性、容错等系统设计问题。因此,MapReduce 为开发者提供了灵活性,可以只关注代码逻辑,而不必考虑底层系统的复杂性。
MapReduce 是一种编程框架,允许我们在分布式环境中对大规模数据集进行分布式和并行处理。MapReduce 由两个核心任务组成:Map 和 Reduce。
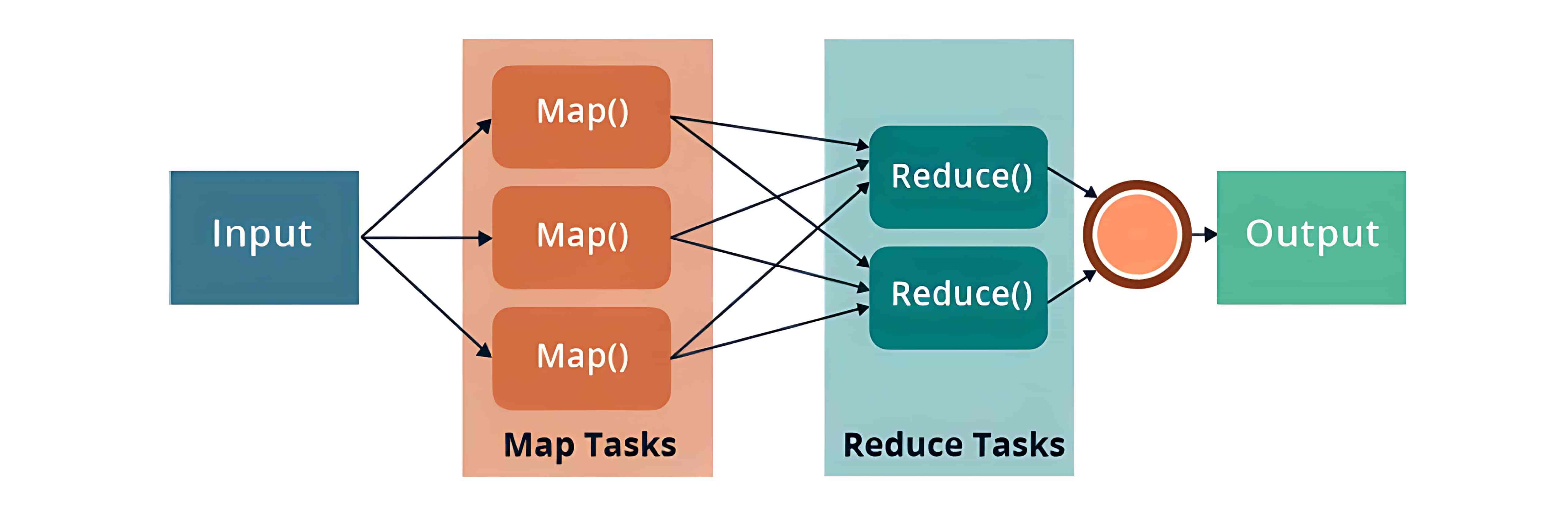
MapReduce 的优点:
- 把计算任务放到数据所在的地方执行,减少数据传输。
- 多个任务同时处理数据,提高处理速度。
2、MapReduce Components(MapReduce 组件)
MapReduce 模型包括三个主要阶段:
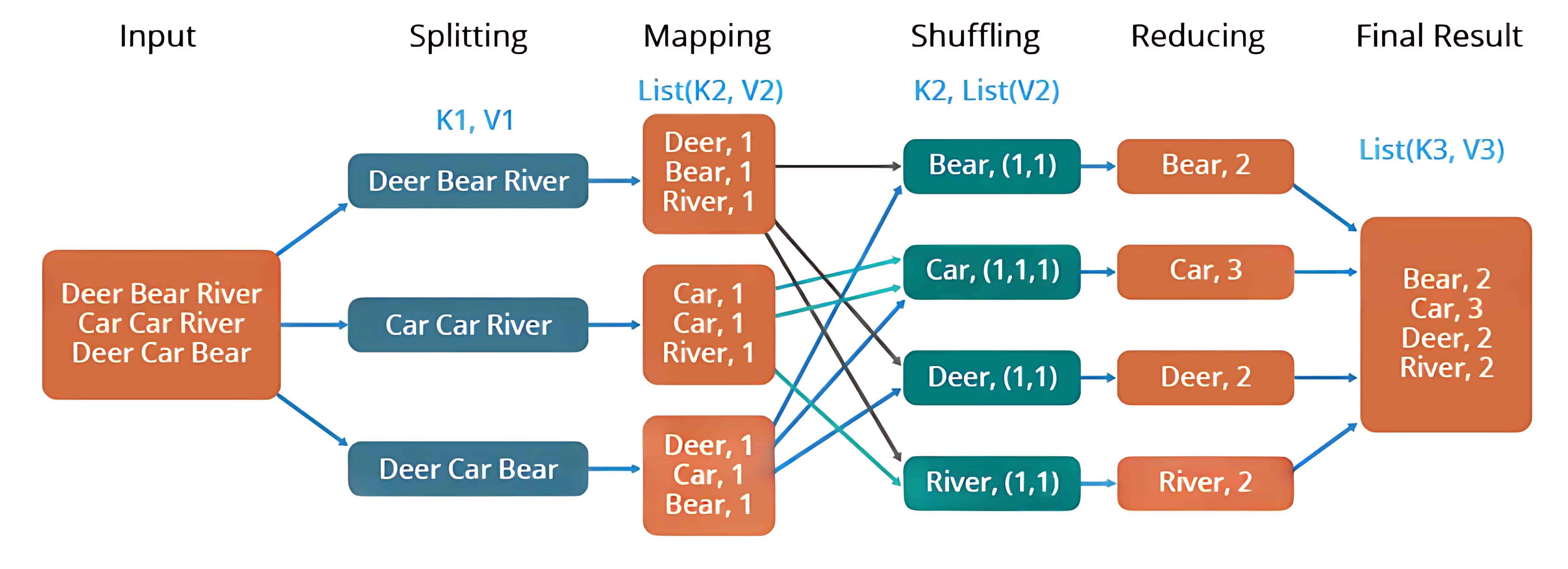
- Mapper(映射器):首先是 Map 任务,即将分布在多个数据节点上的多个数据块进行读取和处理。Mapper 函数接受的输入是键值对形式 (k, v),其中键 k 表示每条记录的偏移地址,值 v 表示整个记录的内容。Mapper 阶段的输出同样是键值对形式,记作 (k’, v’)。
- Shuffle 和 Sort(洗牌与排序):各个 Mapper 的输出 (k’, v’) 会进入 Shuffle 和 Sort 阶段。在这个阶段,会去除重复的值,并根据相同的键对不同的值进行分组。该阶段的输出仍然是键值对形式,表现为键与值数组的组合 (k, v[])。
- Reducer(归约器):Reducer 接收来自多个 Map 任务的键值对。然后,它将这些中间数据元组(即中间键值对)进行聚合,最终生成一组更小的键值对作为最终结果,并写入 HDFS 的输出目录中的一个文件中。
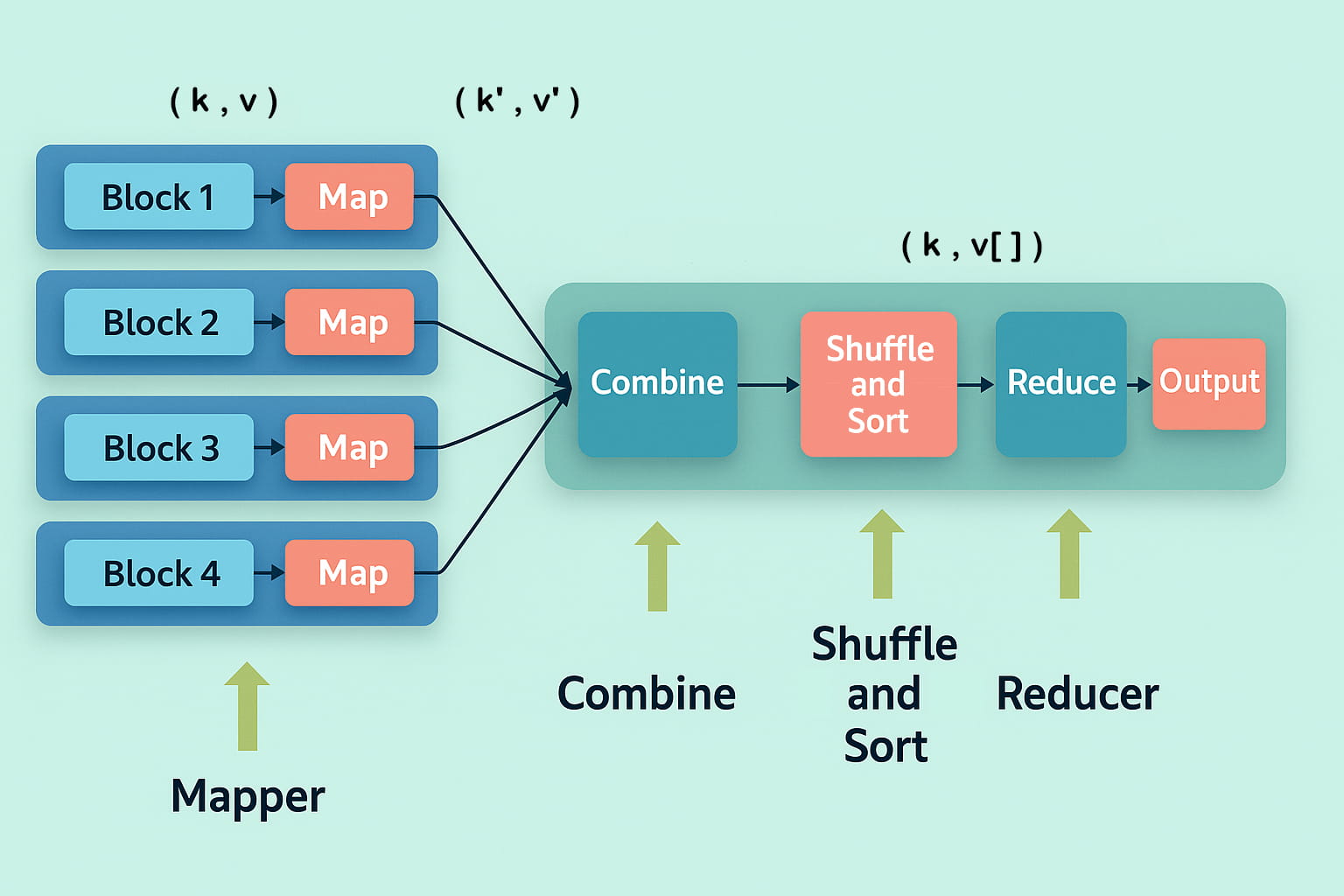
示例:比如统计一组文本文件中每个单词出现的次数,整个过程可以理解为如下所示: