一、Overview of Hadoop Operating Modes(Hadoop 运行模式概述)
Hadoop 的四种主要运行模式:
- 本地运行模式(Local Runtime Mode)
- 伪分布式运行模式(Pseudo-Distributed Operating Mode)
- 完全分布式运行模式(Fully Distributed Operating Mode)
- 高可用(HA)运行模式(High Availability Operating Mode)
1、Hadoop Local operation mode(本地运行模式)
默认情况下,Hadoop 将以非分布式模式运行,作为一个单独的 Java 进程,这种模式称为本地(Standalone)模式。在此模式下不会运行任何守护进程,所有程序都在同一个 JVM 中执行。由于在本地模式下更容易进行 MapReduce 程序的测试与调试,因此该模式适用于开发阶段使用。
2、Hadoop pseudo-distributed mode(伪分布式运行模式)
概述
Hadoop 可以运行在单节点上,每个 Hadoop 守护进程以独立的 Java 进程形式运行,这种模式称为伪分布式模式(Pseudo-Distributed Mode)。在该模式中,所有 Hadoop 进程都运行在同一台服务器节点上,用于模拟一个完整的分布式环境,通常应用于实验学习阶段。
当 Hadoop 伪分布式集群启动后,会出现五个主要的进程,分别如下:
- NameNode
- DataNode
- SecondaryNameNode
- ResourceManager
- NodeManager
HDFS 守护进程(HDFS Daemon Process)
HDFS(分布式文件系统)用于解决海量数据的存储问题。NameNode、DataNode 和 SecondaryNameNode 是 HDFS 正常运行所必需的核心进程。
YARN 守护进程(Yarn Daemon Process)
YARN 是 Hadoop 3.x 中的资源管理系统。要使 YARN 正常工作,必须启动 ResourceManager 和 NodeManager 两个进程。
3、Hadoop Fully distributed mode(完全分布式运行模式)
Hadoop 运行在一个集群上,在该集群中,每个服务器节点上的 Hadoop 守护进程都以 Java 进程的形式运行。这种模式被称为完全分布式模式(Full-Distributed Mode)。该模式通常用于实验验证阶段和企业级部署调试阶段。
在完全分布式模式下,集群中的进程总数与伪分布式模式相同,即以下五个核心进程:
- NameNode
- DataNode
- SecondaryNameNode
- ResourceManager
- NodeManager
4、Hadoop HA Running Mode(高可用运行模式)
在 Hadoop 2.x 中引入了高可用(High Availability, HA)集群的概念,以解决 Hadoop 1.x 中的**单点故障(Single Point of Failure)**问题。如你所知,HDFS 架构遵循主/从拓扑结构,其中 NameNode 作为主节点(Master Daemon),负责管理其他被称为 DataNode 的从节点。
这个唯一的主节点 NameNode 成为了系统的瓶颈。虽然引入 Secondary NameNode 能在一定程度上防止数据丢失,并分担部分 NameNode 的负载,但它并没有真正解决 NameNode 的可用性问题。
HDFS 高可用架构(HDFS HA Architecture):
高可用架构通过引入两台 NameNode,并采用主/备(Active/Passive)配置,解决了 NameNode 的可用性问题。因此,在一个高可用的 Hadoop 集群中会同时运行两台 NameNode:
- Active NameNode(活跃 NameNode)
- Standby/Passive NameNode(备用/被动 NameNode)
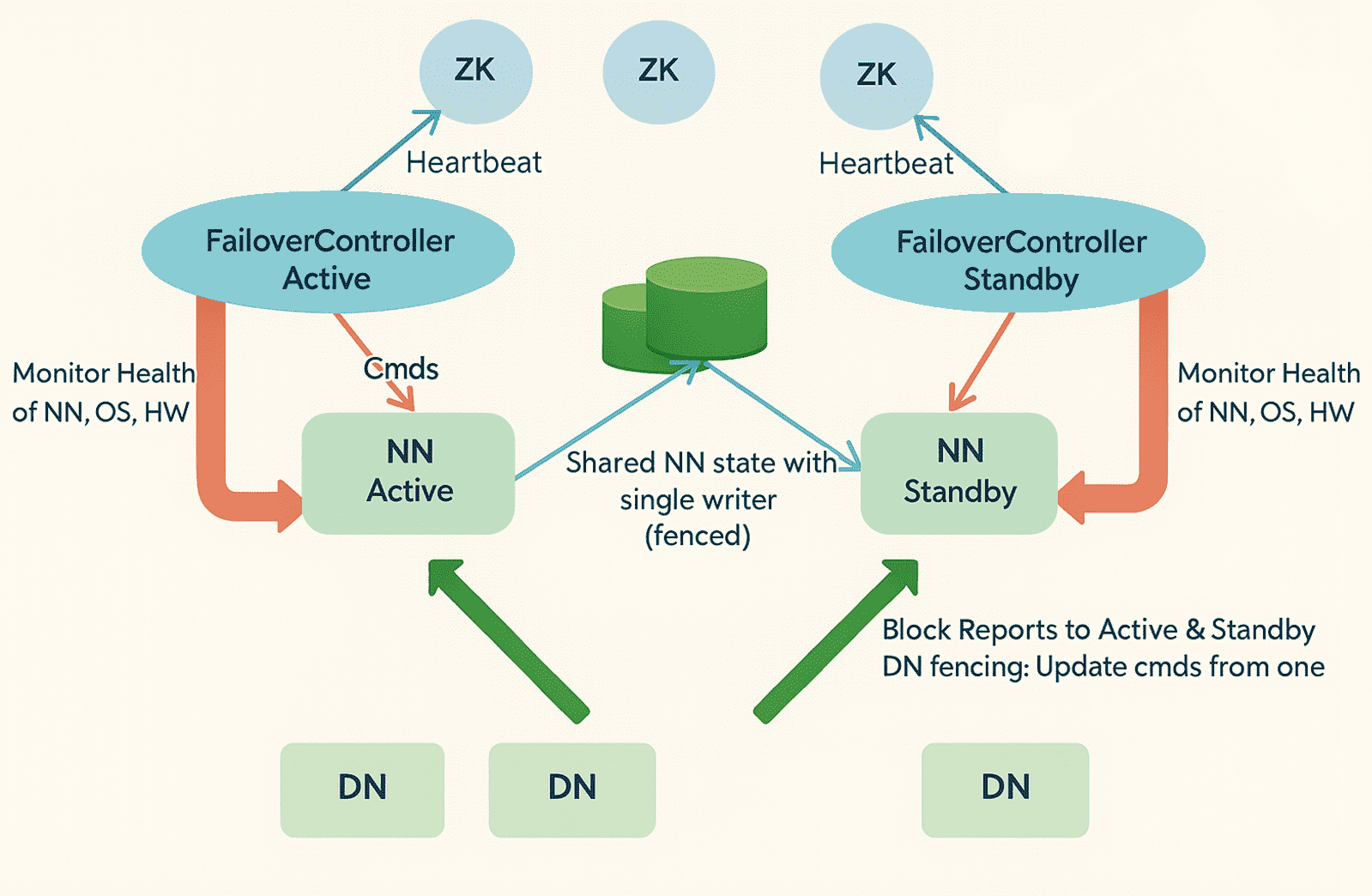
如果其中一个 NameNode 出现故障,另一个 NameNode 可以接管其职责,从而减少集群的宕机时间。Standby NameNode(备用 NameNode) 起到了主节点的备份作用(不同于 Secondary NameNode),它为 Hadoop 集群提供了故障转移(failover)能力。因此,借助 StandbyNode,当 NameNode 崩溃时可以实现自动故障转移,也可以在维护期间进行手动故障转移。
在保持 HDFS 高可用集群一致性方面,主要存在两个问题:
- Active NameNode 和 Standby NameNode 必须始终保持同步,也就是说它们应拥有相同的元数据。这可以确保当发生故障时,能够将 Hadoop 集群恢复到崩溃前的命名空间状态,从而实现快速故障切换。
- 同一时刻只能存在一个 Active NameNode,因为两个 Active NameNode 会导致数据损坏。这种情况被称为脑裂(split-brain),即集群被分裂成多个部分,每个部分都认为自己是唯一的活跃集群。为避免这种情况,需要执行**Fencing(隔离)**操作。Fencing 是一种机制,用于确保在任何时刻只有一个 NameNode 处于活跃状态。
高可用(HA)架构的实现方式:
在 HDFS 高可用架构中,我们同时运行两台 NameNode。因此,可以通过以下两种方式之一来配置 Active(活跃)和 Standby(备用)NameNode:
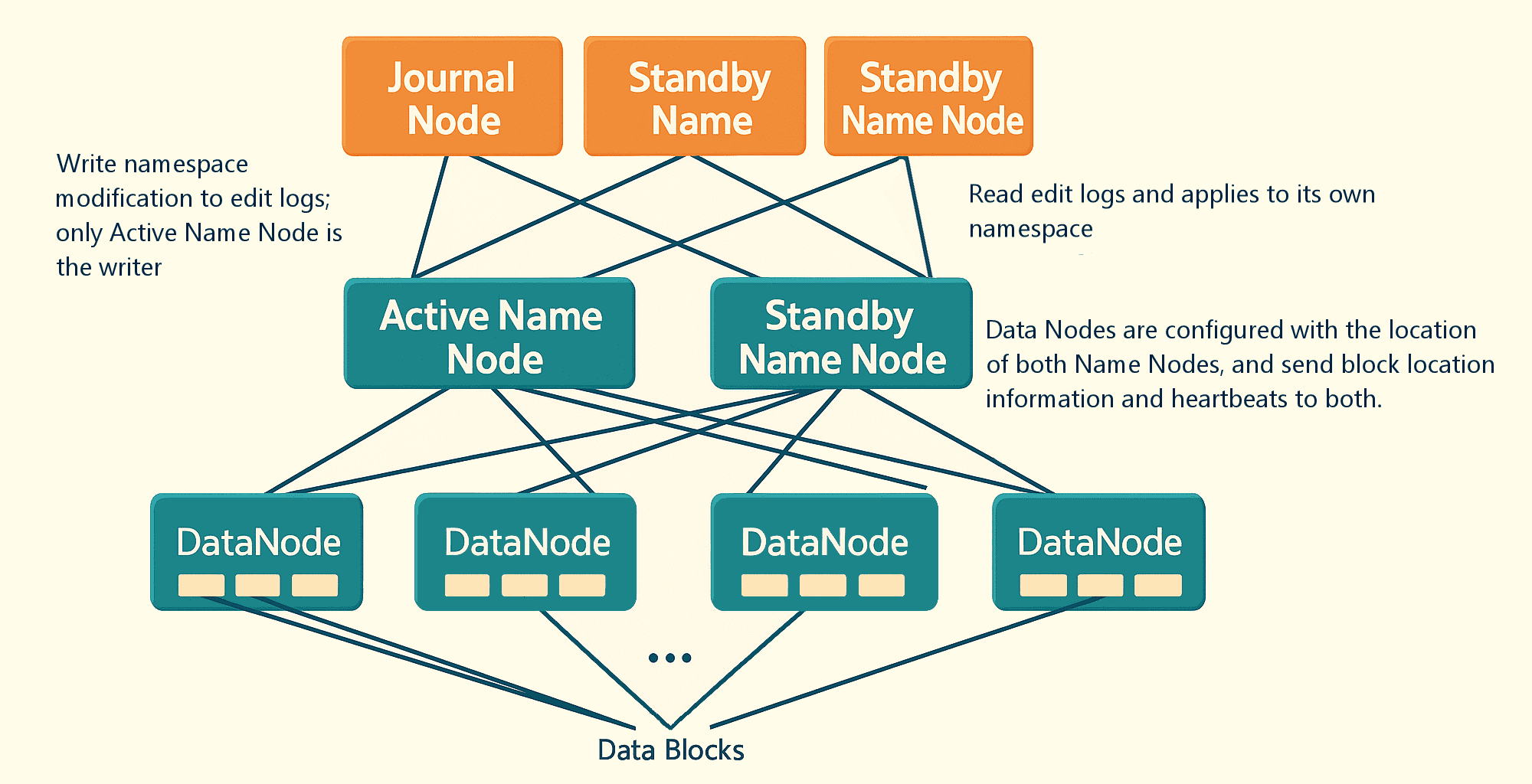
使用 Quorum JournalNodes(法定日记节点):
- Standby NameNode 与 Active NameNode 通过一组独立的节点或守护进程(称为 JournalNode)保持同步。这些节点接收来自 Active NameNode 的请求,并将信息复制到网络中的其他节点中,从而在某个 JournalNode 故障时提供容错能力。
- Active NameNode 负责将编辑日志(EditLogs)更新写入 JournalNodes。
- Standby NameNode 持续读取 JournalNodes 中的 EditLogs 所做的更改,并将其应用到自身的命名空间中,确保与 Active NameNode 保持一致。
- 在发生故障切换(failover)时,Standby NameNode 会确保在接管为新的 Active NameNode 之前,已从 JournalNodes 更新了所有元数据信息。这样可以确保当前命名空间的状态与切换前保持一致。
- 所有 DataNode 都能访问两个 NameNode 的 IP 地址,并将心跳信息和数据块位置信息发送给两个 NameNode。由于 Standby NameNode 始终掌握最新的块位置信息,因此在发生故障切换时能够迅速接管,实现快速切换(低宕机时间)。
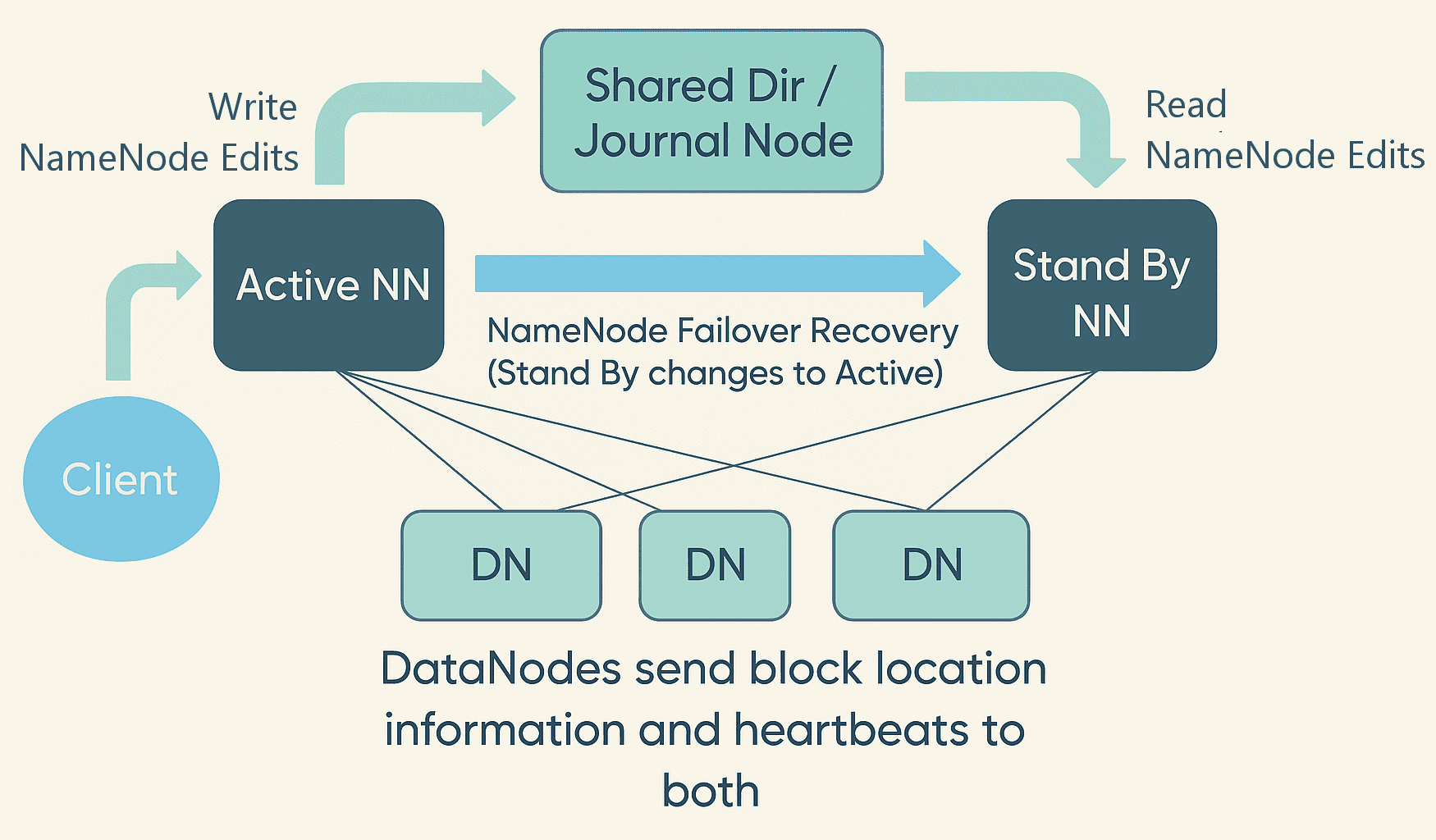
使用共享存储(Using Shared Storage):
- Standby NameNode 和 Active NameNode 通过使用一个共享存储设备保持同步。Active NameNode 会将对其命名空间所做的任何修改记录到该共享存储中的 EditLog 文件中。Standby NameNode 通过读取共享存储中的 EditLog 中的变更,并将这些更改应用到自己的命名空间中,从而保持一致性。
- 在发生故障切换(failover)时,Standby NameNode 首先使用共享存储中的 EditLog 更新自己的元数据信息,然后接管 Active NameNode 的职责。这样可以确保当前命名空间状态与故障发生前保持一致。
- 管理员必须配置至少一种 Fencing(隔离)机制,以避免“脑裂”(split-brain)场景的发生。
- 系统可以采用多种隔离机制,包括终止原 Active NameNode 的进程,或撤销其对共享存储目录的访问权限等操作。
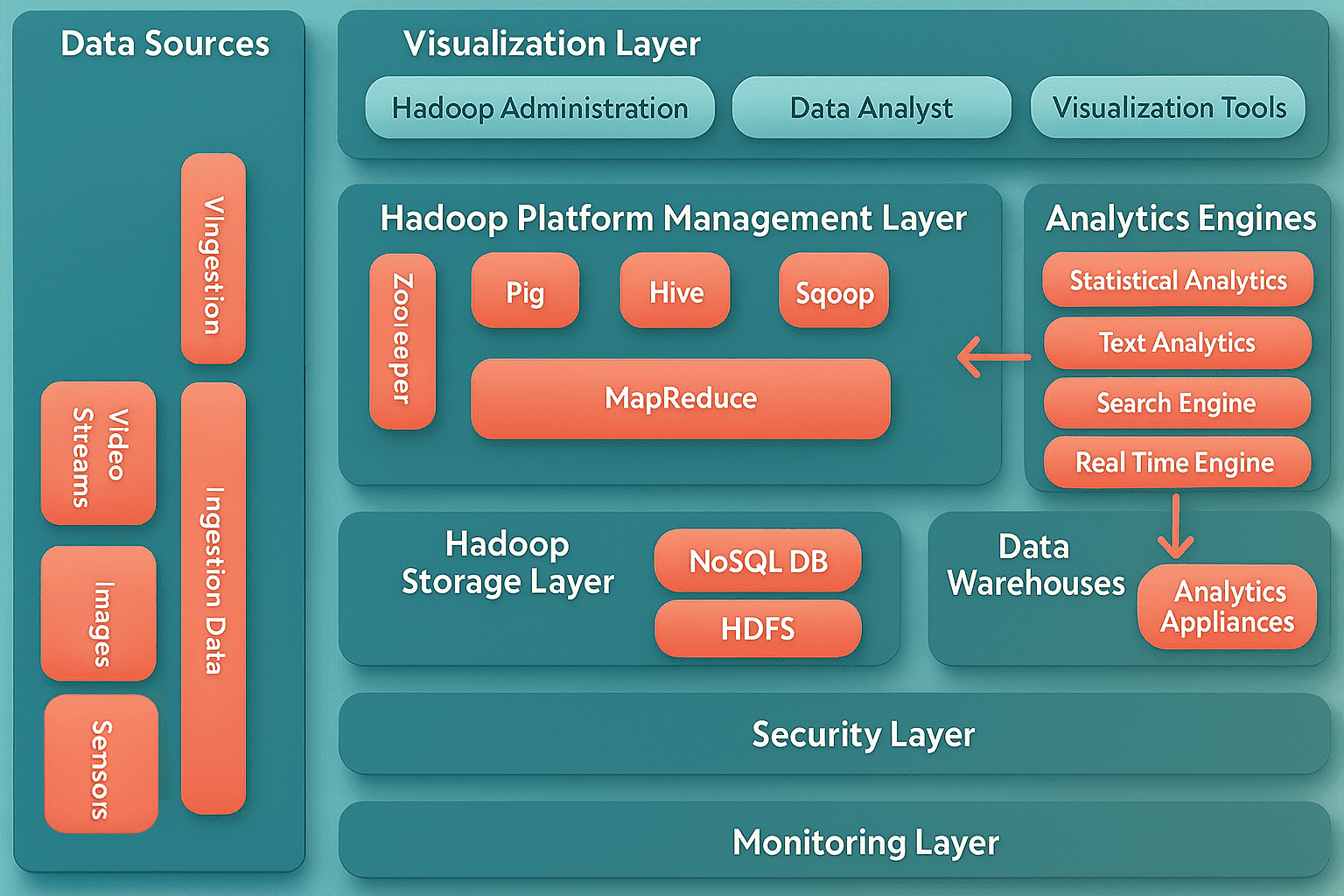
二、Hadoop and Big Data Architecture(Hadoop 与大数据架构)
Hadoop 生态系统既不是一种编程语言,也不是一个服务,它是一个平台或框架,用于解决大数据问题。你可以把它看作是一个包含多个服务(包括数据的采集、存储、分析和管理)的完整套件。
Hadoop 生态系统中的大多数服务,都是为了补充 Hadoop 的四个核心组件,这四个核心组件包括:
- HDFS(Hadoop 分布式文件系统)
- YARN(资源管理器)
- MapReduce(分布式计算框架)
- Common(通用工具和库)
下图展示了 Hadoop 生态系统的组成组件,这些组件可以相互组合,用于构建不同的大数据架构。
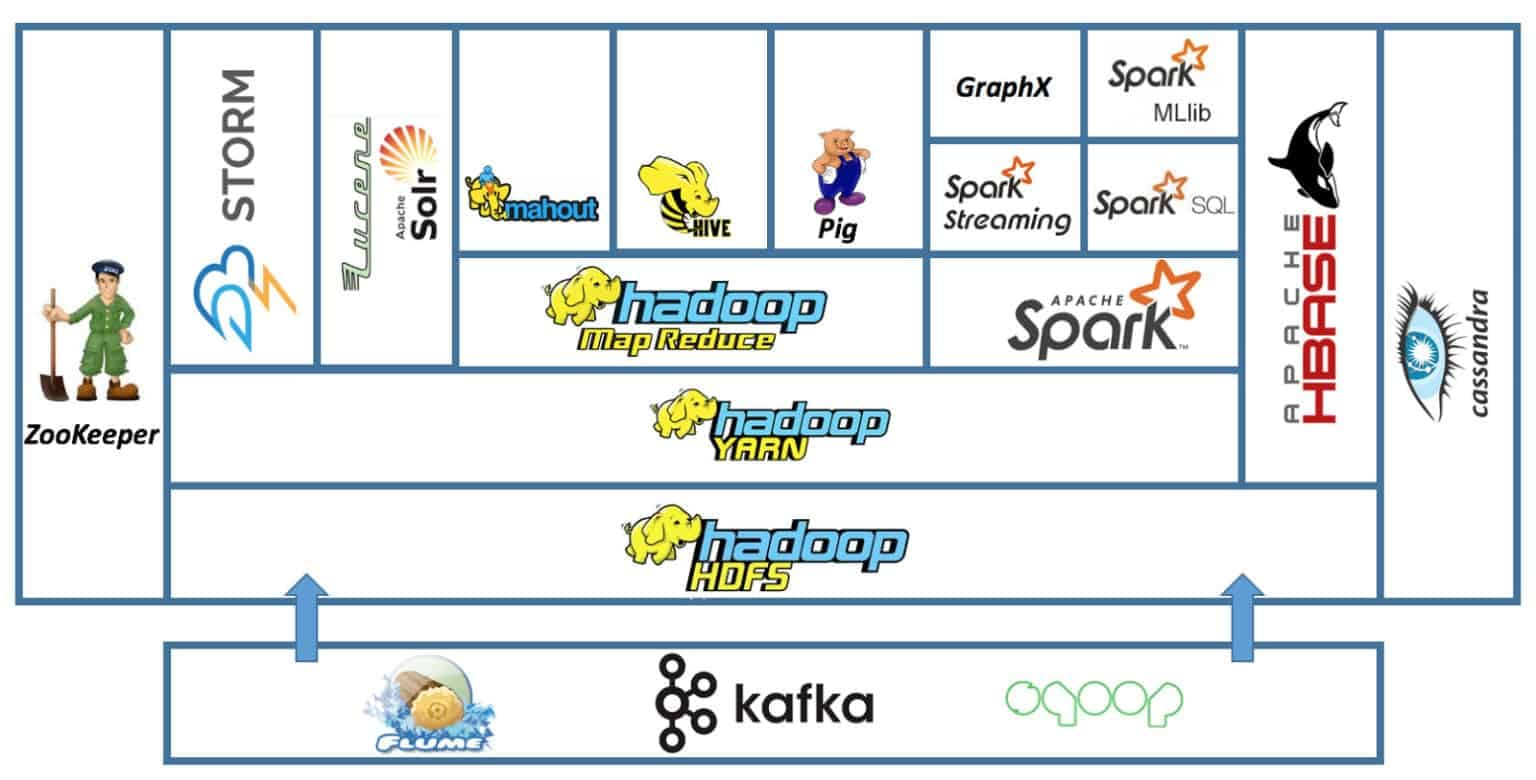
大数据技术架构
大数据的“V”特征包括:体量(Volume)、多样性(Variety)、速度(Velocity)和 真实性(Veracity),每一项特征都会影响数据的采集、监控、存储、分析与报告。下图展示了企业级应用系统中常见的大数据架构。
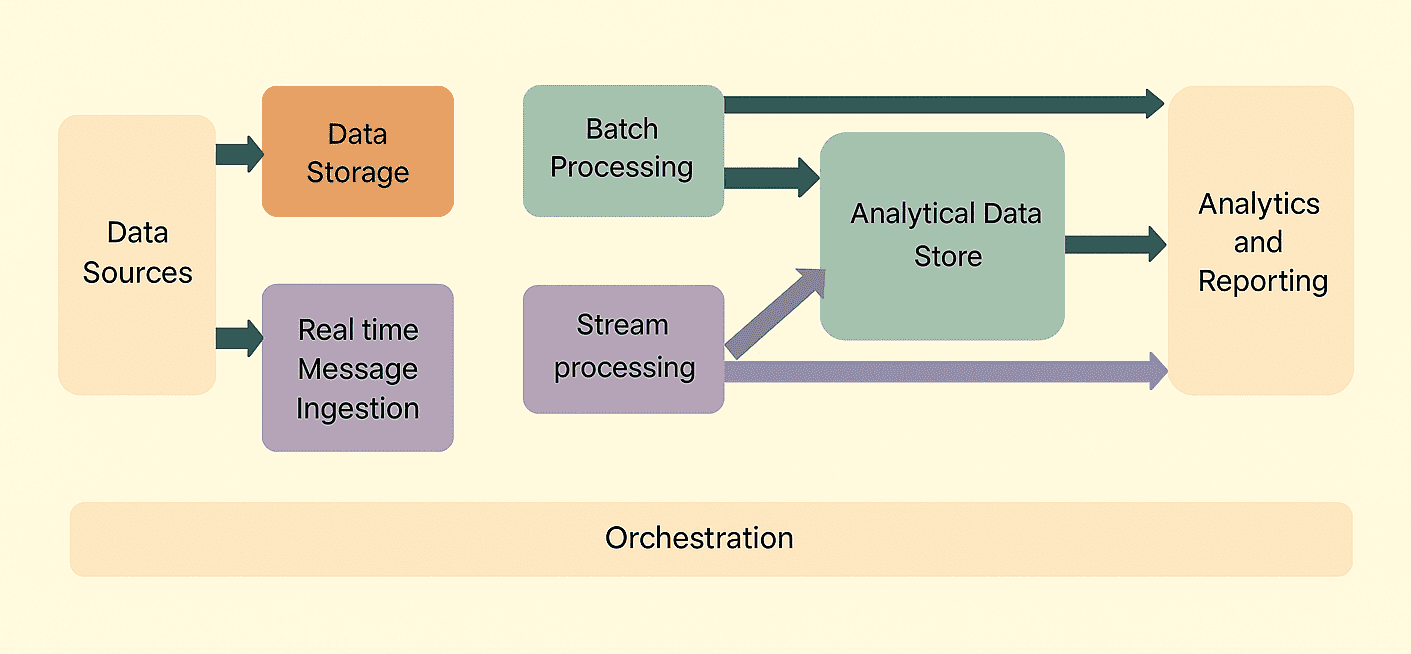
1、Hadoop Real-time Computing Architecture(Hadoop 实时计算架构)
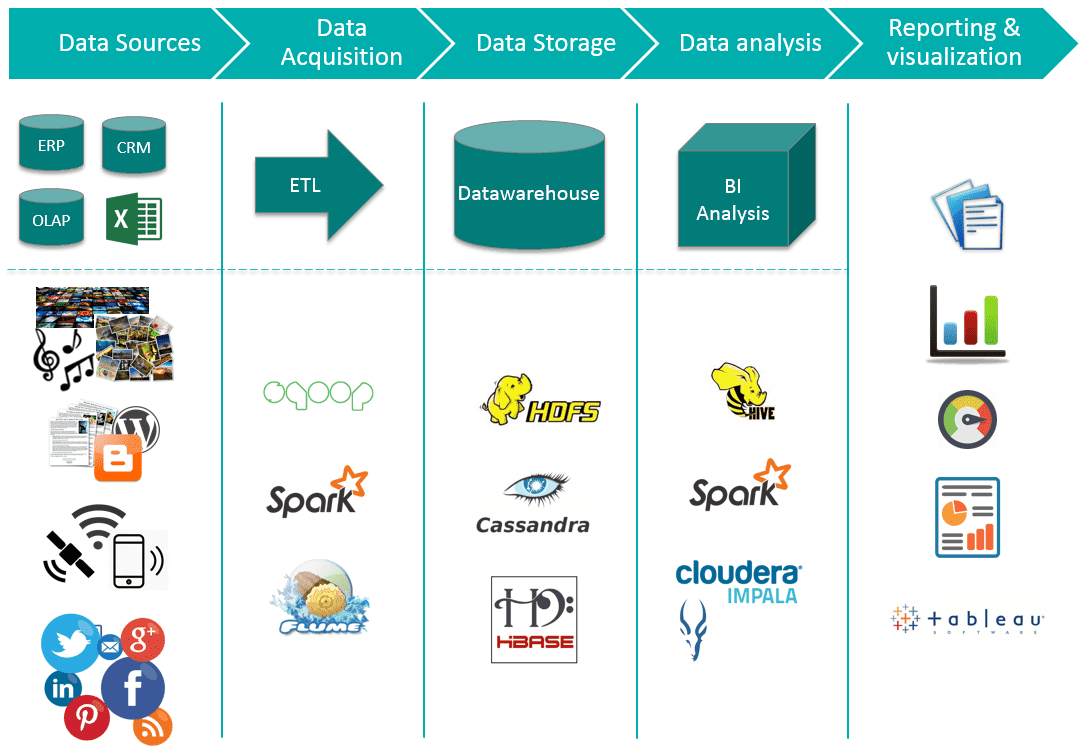
概述
Hadoop 的实时计算能力并非源自其本身,而是依赖第三方组件 Apache Storm。Storm 有多种应用场景,例如:实时分析、在线机器学习、持续计算、分布式 RPC(远程过程调用)、ETL(抽取、转换、加载) 等。
实时计算技术架构
基于 Hadoop 生态系统 和 Apache Storm 的流式计算技术架构如图所示,其中 Storm 负责执行实时计算任务。整个 Hadoop 跨越了 数据存储层 和 资源管理层。