
Chapter 1:Introduction to NoSQL
一、Introduction to NoSQL(NoSQL 简介)
数据库是一个用于存储数据的平台,其设计目标是确保数据的安全性、可靠性和易于访问性。通常,数据库分为两种类型:关系型数据库和非关系型数据库。非关系型数据库通常被称为 NoSQL 数据库。
NoSQL数据库用于存储大量复杂且多样化的数据,例如产品目录、日志、用户交互数据、分析数据等。MongoDB 是最成熟的 NoSQL 数据库之一,具有数据聚合、ACID(Atomicity 原子性、Consistency 一致性、 Isolation 隔离性、Durability 持久性)事务、水平扩展和图表等功能。我们将在接下来的章节中详细探讨这些特性。
数据对业务至关重要——特别是存储、分析和可视化数据,同时基于数据做出决策。正因如此,MongoDB 受到许多公司的信任和使用,例如Google、Facebook、Adobe、Cisco、eBay、SAP、Electronic Arts 等。
二、 Features of NoSQL(NoSQL 的特性)
1、Schema Flexibility(模式灵活性)
与传统的关系型数据库不同,NoSQL 数据库不需要预定义模式。这使得它可以存储各种类型和结构的数据,更容易应对不断变化的数据需求和非结构化数据。
2、Horizontal Scalability(水平扩展性)
NoSQL 数据库设计为通过将数据分布到多个服务器上来扩展。这种水平扩展能力使其能够通过简单地增加更多服务器到数据库集群中,来处理大量数据和高流量。
3、High Availability and Fault Tolerance(高可用性和容错性)
NoSQL 数据库内置的复制和分片功能确保了数据的可用性和弹性。数据在多个节点之间复制,提供了冗余,即使某些节点发生故障,系统也能继续运行。
4、 Performance(性能)
NoSQL 数据库针对特定用例进行了优化,通常比传统的关系型数据库提供更快的读写操作。这种性能提升对于需要实时数据访问和处理的应用程序尤为重要。
5、Diverse Data Models(多样化的数据模型)
NoSQL 数据库支持多种数据模型,包括键值对、文档、列族和图数据库。这种多样性使开发人员能够为其应用程序选择最合适的数据模型,从而提高效率和灵活性。
6、Cost-Effectiveness(成本效益)
能够使用廉价硬件进行水平扩展,使 NoSQL 数据库成为一种经济高效的解决方案。组织无需投资昂贵的高端服务器,而是可以使用价格合理的硬件来实现所需的扩展性和性能。
三、Relational Database Vs NoSQL(关系型数据库对比 NoSQL)
| Feature | Relationa | Database |
|---|---|---|
| Schema(模式) | 遵循严格的模式。数据库表需要预先定义所有列及其类型。任何偏离模式的数据操作都会导致错误。 | 不强制使用严格的模式,允许存储具有动态结构的非结构化数据。这使得数据库结构可以灵活演变。 |
| Datamodel/StorageStructure(数据模型/存储结构) | 数据存储在表中,每条记录作为一行,包含所有列的信息。修改表结构可能会影响其他表和相关应用程序。 | 数据根据不同的数据库类型以多种格式存储,常见的存储结构包括文档(Documents)、图(Graphs)、键值对(Key-Values)和宽列(Wide Columns)。数据库能够适应数据的动态变化,应用程序无需修改即可无缝运行。 |
| Normalization(规范化) | 规范化是用于消除重复数据并避免数据异常的过程。关系型数据库通过规范化防止数据异常,要求将数据存储在不同的表中并建立它们之间的关系。 | 更注重快速数据检索,数据可以是规范化的,但通常不强制要求。 |
| Scaling(扩展性) | 扩展性较差,通常采用垂直扩展(Vertical Scaling),即通过增加机器的计算能力和存储容量来实现扩展。 | 支持垂直扩展和水平扩展(Horizontal Scaling),数据可以分布在不同的机器和集群上,扩展性更强。 |
四、Types of NoSQL(NoSQL 的类型)
1、Key-Value Store(键值存储)
一种简单的数据存储系统,通过键(Key)来访问值(Value)。
2、Column Family Store(列族存储)
一种稀疏矩阵系统,使用行(Row)和列(Column)作为键。
3、Graph Store(图存储)
适用于关系密集型问题的存储系统。
4、Document Store(文档存储)
直接在数据库中存储分层数据结构。
五、Introduction to MongoDB(MongoDB 简介)
MongoDB 是一个功能强大、灵活且可扩展的通用数据库。它结合了横向扩展的能力,并提供了诸如二级索引、范围查询、排序、聚合和地理空间索引等特性。
MongoDB 是一个面向文档的数据库,而不是关系型数据库。放弃关系模型的主要原因是为了更容易进行横向扩展,同时它还有其他优势。
易于使用
面向文档的数据库用更灵活的 文档 模型取代了 行 的概念。通过支持嵌套文档和数组,这种文档导向的方法可以用单个记录表示复杂的层次结构关系。这种方式与现代面向对象编程语言中开发人员处理数据的方式天然契合。
在 MongoDB 中,一条记录就是一个文档,它是一种由字段和值对组成的数据结构。MongoDB 文档类似于 JSON 对象。字段的值可以包括其他文档、数组以及文档数组。

设计可扩展
应用程序的数据集规模正以惊人的速度增长。带宽的增加和廉价存储的普及,使得即使是小规模的应用程序也需要存储比许多传统数据库设计时所能处理的更多数据。曾经难以想象的 1TB 数据量,如今已变得司空见惯。
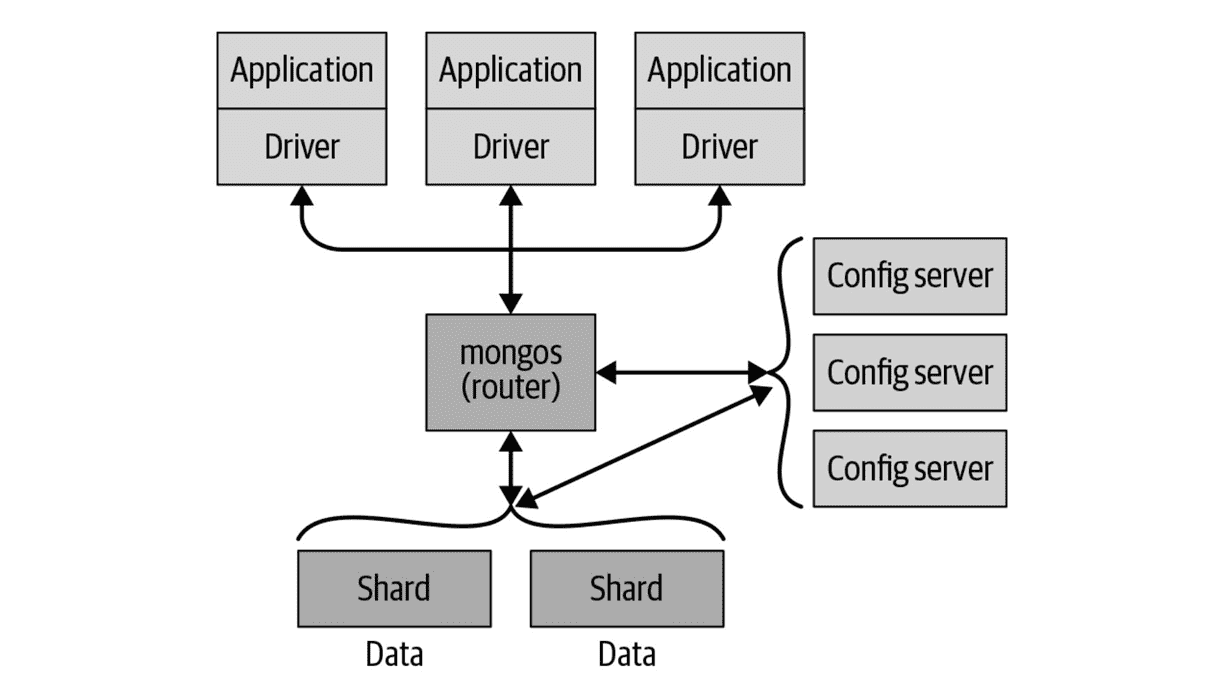
数据库的扩展方式主要有两种选择:纵向扩展(scale up),即升级到更强大的机器,或横向扩展(scale out),即将数据分片存储在多台机器上。MongoDB 旨在实现横向扩展。其面向文档的数据模型使得数据拆分到多个服务器变得更加容易。
MongoDB 能够自动管理集群中的数据和负载均衡,自动重新分配文档,并将读写请求正确地路由到相应的服务器。
六、Introduction to Redis(Redis 简介)
Redis 是一个开源(BSD 许可)、灵活的内存数据结构存储,可用作数据库、缓存和消息代理。类似于 Cassandra、CouchDB 和 MongoDB 等其他 NoSQL 数据库,Redis 允许用户存储海量数据,而不会受到关系型数据库的限制。
Redis 是一个非常快速的非关系型数据库,采用 键值对(key-value)存储,支持五种不同类型的值。Redis 还支持持久化存储(将数据写入磁盘)、复制(replication) 以扩展读性能,以及 客户端分片(sharding) 以扩展写性能。
Chapter 2:Working with MongoDB
一、Need for Schemas(模式需求)
**模式(Schema)**在数据库管理系统中起着至关重要的作用,它为数据的组织和存储提供了蓝图。
虽然 MongoDB 是一个无模式(schema-less)的 NoSQL 数据库,但合理使用模式(Schema)可以显著提升数据库的结构性、一致性和性能。
理解 MongoDB 中的 Schema:
Schema 是一种逻辑结构,定义了数据库中数据的组织方式。在传统的关系型数据库中,Schema 是固定的,强制规定数据类型以及表与表之间的关系。而 MongoDB 作为一个 NoSQL 数据库,提供了灵活性,允许你在同一个集合(collection)里,存储不需要预先定义结构的文档。
这种无模式的特性,虽然带来了很大的灵活性和易用性,但如果管理不当,也可能引发一些问题。
MongoDB 中 Schema 的重要性:
-
保证数据一致性和完整性
在 MongoDB 中使用 Schema,最重要的目的之一就是保证数据的一致性和完整性。如果不使用 Schema,可能导致同一个集合中不同的文档结构不一致,增加数据查询和操作的复杂度。
比如一个电商应用,产品(product)文档必须包含
name、price和category这些字段。如果没有 Schema 约束,某些文档可能会遗漏这些字段,或者字段类型不一致,导致无法可靠查询和聚合。 -
提升查询性能
Schema 还能优化查询性能。当 MongoDB 知道集合中文档的结构时,可以更有效地优化查询,索引的建立也会更加高效,从而加快数据的检索速度。例如,为订单(order)集合定义
orderId、customerId和orderDate字段的 Schema,MongoDB 就能针对这些字段创建更优的索引,尤其在数据量较大的情况下,查询速度提升非常明显。 -
提高开发效率
Schema 还能显著提升开发效率。当文档结构是预定义好的,开发人员在写查询和操作代码时就更有信心,不用担心数据结构异常,减少运行时错误。此外,现代开发工具和 IDE 也对有 Schema 的数据提供了更好的支持,例如自动补全、数据验证等功能,让开发过程更流畅,调试和排查错误的时间也会更少。
-
简化维护和升级
有 Schema 的数据库,维护和更新更加方便。因为数据结构清晰明确,添加新字段或修改字段更容易统一管理。Schema 验证工具还能帮助检查并统一数据结构,确保所有文档符合新的规范。而在无模式的环境下,更新操作会复杂得多,尤其是大数据量、结构多样化的数据库,升级改动极易出错。
-
改善团队协作
在团队协作时,预定义的 Schema 能让所有成员对数据结构有统一认知,协作更顺畅,沟通更清晰,降低因理解偏差导致的错误,提高工作效率。
同时,Schema 也便于文档化,方便新成员上手,降低学习门槛,加快熟悉数据库结构和业务逻辑的速度。
1、Data Modeling in MongoDB(MongoDB 中的数据建模)
在 MongoDB 中进行数据建模(Data modeling) 是一个比较细致的过程,它与传统的关系型数据库有很大的不同。
一方面,你需要考虑应用程序的需求以及用户与应用的交互方式,另一方面,还要兼顾数据库性能的高效性,以及访问数据时采用的具体访问模式。
在这两者之间取得平衡,会直接影响到数据本身的结构。而在 MongoDB 中,数据是以**文档(documents)**的形式来表示和存储的。
Structuring the document(构建文档):
MongoDB 特点之一是其灵活的文档结构。它可以管理嵌套的 BSON(Binary JSON)文档和数组,支持最多 100 层的嵌套。这种灵活性让数据结构可以完全贴合应用需求。
Benefit of MongoDB Document Structure(MongoDB 文档结构的优势):
-
减少联接的需求
在传统的关系型数据库中,通常需要使用**联接(Joins)**来将多个表的数据合并。这一过程既复杂又费时。然而,利用 MongoDB 的嵌套文档,你可以将相关数据保存在一个文档中,从而减少联接操作,简化数据检索,提升性能。
-
简化数据检索
MongoDB 支持嵌套文档,意味着你可以将所有相关数据存储在一起。例如,假设你有一个用户文档,可以在该文档中嵌入用户的所有地址、订单和偏好。当你需要检索用户的数据时,可以一次性获取所有信息,而不需要查询多个表或集合。这种简化的检索过程使 MongoDB 在处理复杂数据结构时表现出色。
-
简化查询
通过嵌套文档,查询变得更加直接。你不再需要编写复杂的 SQL 查询和多个联接,而是可以使用 MongoDB 的查询语言轻松访问所需的数据。例如,你可以直接查询嵌入的文档和数组,无需额外步骤,从而简化代码并减少潜在的错误。
Document Structure in Practice(实际中的文档结构):
假设你正在构建一个电子商务应用程序。在关系型数据库中,你可能会为用户、订单、产品和评论等创建单独的表。为了获取一个用户的最近购买信息,你需要将这些表连接在一起。
在 MongoDB 中,你可以将所有相关数据存储在用户文档中。这意味着每个用户文档可以包含其订单的数组,而每个订单又可以包含产品和评论的嵌套文档。以下是一个简化的示例,展示一个 MongoDB 中的用户文档可能是什么样子:
{
"_id": ObjectId("user123"),
"name": "John Doe",
"email": "john.doe@example.com",
"orders": [
{
"order_id": ObjectId("order001"),
"date": "2025-03-01",
"total_amount": 150.00,
"products": [
{
"product_id": ObjectId("product001"),
"name": "Laptop",
"price": 1000.00,
"quantity": 1
},
{
"product_id": ObjectId("product002"),
"name": "Mouse",
"price": 20.00,
"quantity": 1
}
],
"reviews": [
{
"product_id": ObjectId("product001"),
"rating": 4,
"comment": "Great laptop!"
}
]
}
]
}
在此文档中,John 的所有订单、产品和评论都嵌套在他的用户文档中。这种结构不仅使数据井然有序,而且使查询和更新变得异常简单。
2、Data Types in MongoDB(MongoDB 数据类型)
MongoDB 是一种 NoSQL 数据库,它提供多种数据类型以满足各种需求,并确保灵活高效的数据存储和检索。
BSON: The Binary Representation(BSON:二进制表示):
BSON(Binary JSON),MongoDB 用来存储数据的格式(储存的是文件,文件的格式是 BSON)。BSON 扩展了 JSON 模型,提供了包括日期和二进制数据等 JSON 中没有的数据类型。BSON 的设计目标是提高空间效率和处理速度,从而确保快速的数据处理和较小的存储开销。
Basic Data Type(基本数据类型):
-
字符串(String)
- 描述:字符串是 MongoDB 中最常用的类型,用于存储文本数据。它们是 UTF-8 编码的,因此可以支持包括特殊字符和国际字符在内的广泛字符。
- 示例:{ "name": "John Doe" }
-
整数 (Integer)
- 描述:MongoDB 支持 32 位和 64 位整数,用于存储没有小数部分的数值数据。
- 示例:{ "age": 30, "score": 123456789 }
-
浮点数 (Double)
- 描述:浮点数用于存储小数点数字。
- 示例:{ "price": 19.99, "rating": 4.5 }
-
布尔值 (Boolean)
- 描述:布尔值用于表示二进制值:真或假。
- 示例:{ "isActive": true, "isAdmin": false }
Complex Data Type(复杂数据类型):
-
数组 (Arrays)
- 描述:数组用于存储一个字段中的多个值,这些值可以是任何数据类型,包括其他数组或文档。
- 示例:{ "tags": ["mongodb", "database", "NoSQL"] }
-
嵌套文档 (Embedded Documents)
-
描述:MongoDB 允许文档嵌套在其他文档内,用于在层次结构中存储相关数据。
-
示例:
{ "name": "John Doe", "address": { "street": "123 Main St", "city": "New York", "state": "NY", "zip": "10001" } }
-
Special Data Type(特殊数据类型):
-
ObjectId(对象Id)
- 描述:ObjectId 是 MongoDB 用于文档的唯一标识符,它是一个由时间戳、机器标识符、进程标识符和计数器组成的 12 字节值。
- 示例:{ "_id": ObjectId("507f1f77bcf86cd799439011") }
-
日期 (Date)
- 描述:日期数据类型用于存储当前的日期和时间,存储为自 Unix 纪元以来的毫秒数(1970 年 1 月 1 日)。
- 示例:{ "created_at": ISODate("2023-07-24T00:00:00Z") }
-
空值 (Null)
- 描述:Null 数据类型用于表示空值或缺失的值。
- 示例:{ "middle_name": null }
-
正则表达式 (Regular Expression)
- 描述:正则表达式用于在字符串中进行模式匹配。MongoDB 支持 Perl 兼容正则表达式(PCRE)语法。
- 示例:{ "pattern": /abc/i }
-
二进制数据 (Binary Data)
- 描述:二进制数据类型用于存储二进制数据,如图像、音频文件或其他多媒体内容。
- 示例:{ "profile_picture": BinData(0, "base64encodedstring") }
3、Understanding Relations(理解关系)
在 MongoDB 中,数据之间的关系可以通过多种方式表示。不同于传统的关系型数据库,MongoDB 没有固定的严格表结构,允许更灵活的数据建模方式,这在处理复杂关系型数据时非常有用。
MongoDB 中常见的三种关系类型:一对一、一对多、多对多。
一对一关系:
一对一关系指一个集合中的一条文档对应另一个集合中的一条文档,类似于关系型数据库中的主键和外键。
示例:用户与个人资料
- 嵌入式文档:把资料信息直接嵌入用户文档中。适用于资料较小、且经常和用户数据一起访问的情况。
{
"_id": ObjectId("507f191e810c19729de860ea"),
"username": "johndoe",
"email": "john.doe@example.com",
"profile": {
"age": 30,
"gender": "male",
"address": "123 Main St"
}
}
- 引用文档:将资料存储在单独的集合中,通过
ObjectId引用。
// 用户文档
{
"_id": ObjectId("507f191e810c19729de860ea"),
"username": "johndoe",
"email": "john.doe@example.com",
"profile_id": ObjectId("507f191e810c19729de860eb")
}
// 资料文档
{
"_id": ObjectId("507f191e810c19729de860eb"),
"age": 30,
"gender": "male",
"address": "123 Main St",
"user_id": ObjectId("507f191e810c19729de860ea")
}
使用场景:
- 使用嵌入式:当资料较小、且常随用户数据一起访问。
- 使用引用:当资料较大或独立更新。
一对多关系:
一对多关系是指一个集合中的一条文档对应另一个集合中的多条文档,常见于例如博客系统,一个作者有多篇文章。
示例:作者与文章
- 嵌入式文档:
{
"_id": ObjectId("507f191e810c19729de860ea"),
"name": "John Doe",
"posts": [
{"title": "First Post", "content": "This is my first post."},
{"title": "Second Post", "content": "This is my second post."}
]
}
- 引用文档:
// 作者文档
{
"_id": ObjectId("507f191e810c19729de860ea"),
"name": "John Doe"
}
// 文章文档
{
"_id": ObjectId("507f191e810c19729de860eb"),
"author_id": ObjectId("507f191e810c19729de860ea"),
"title": "First Post",
"content": "This is my first post."
}
使用场景:
- 使用嵌入式:当文章数量少、常与作者数据一起读取。
- 使用引用:当文章数量多或需独立管理。
多对多关系:
多对多关系是指多个集合中的文档彼此对应,例如课程选修系统,一个学生可以选多门课,一门课也可以有多个学生。
示例:学生与课程
- 嵌入式数组
// 学生文档
{
"_id": ObjectId("507f191e810c19729de860ea"),
"name": "Alice",
"enrolled_courses": [
ObjectId("507f191e810c19729de860eb"),
ObjectId("507f191e810c19729de860ec")
]
}
// 课程文档
{
"_id": ObjectId("507f191e810c19729de860eb"),
"title": "Math 101",
"students": [
ObjectId("507f191e810c19729de860ea"),
ObjectId("507f191e810c19729de860ed")
]
}
- 中间集合(关联表)
// 学生文档
{
"_id": ObjectId("507f191e810c19729de860ea"),
"name": "Alice"
}
// 课程文档
{
"_id": ObjectId("507f191e810c19729de860eb"),
"title": "Math 101"
}
// 选课关联文档
{
"student_id": ObjectId("507f191e810c19729de860ea"),
"course_id": ObjectId("507f191e810c19729de860eb")
}
使用场景:
- 使用嵌入式数组:当关系数量少,数据量小。
- 使用中间集合:当关系数量多、或需要独立查询、管理。
在 MongoDB 中,理解并正确实现数据关系,对于设计高效且可扩展的数据库至关重要。以下是针对每种关系类型的使用场景总结:
- 一对一关系:
当相关数据较小且经常一起访问时,使用嵌入式存储;当数据较大或需要独立更新时,使用引用方式。 - 一对多关系:
当相关文档数量有限且经常与主文档一起读取时,使用嵌入式存储;当相关文档数量较多或需要独立管理时,使用引用方式。 - 多对多关系:
当关系数量较少且易于管理时,使用嵌入式数组;当关系复杂、数量庞大或需要独立查询时,使用中间集合(关联集合)。
通过为不同类型的关系选择合适的建模方式,可以优化 MongoDB 数据库的性能和可维护性。
二、CRUD Operations(CRUD 操作)
CRUD 代表 创建(Create)、读取(Read)、更新(Update)和删除(Delete)——这是数据库中对数据执行的四种基本操作。MongoDB 作为一种流行的 NoSQL 数据库,提供了灵活而强大的方式来执行这些操作。
1、Inserting Documents(插入文档)
插入(Insert)是向 MongoDB 添加数据的基本方法。
插入单个文档:
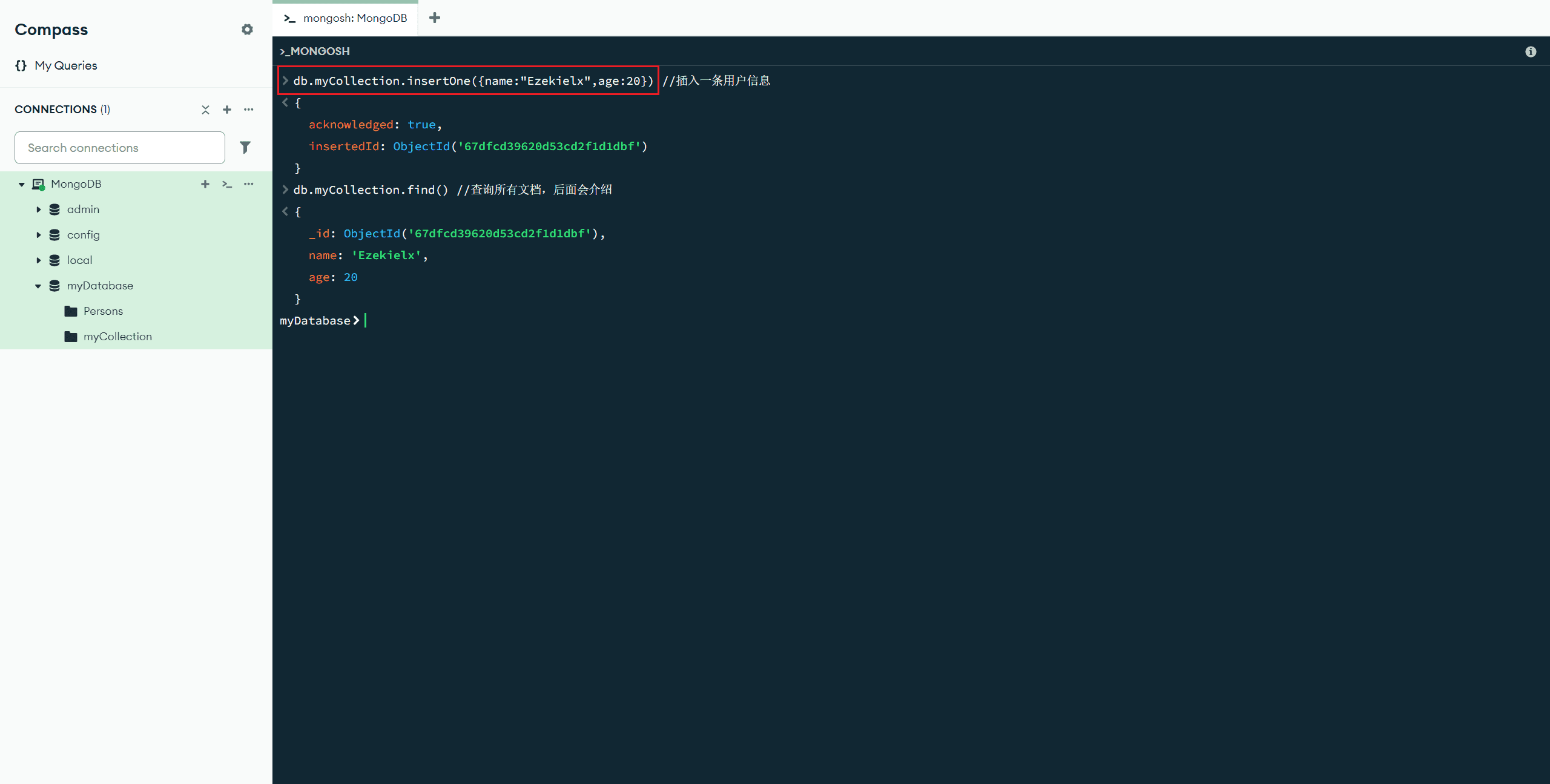
insertOne(<文档>) :插入单个文档,如果未提供 _id,MongoDB 会自动生成并添加 _id 字段。
db.myCollection.insertOne({name:"Ezekielx",age:20}) //插入一条用户信息
插入多个文档:
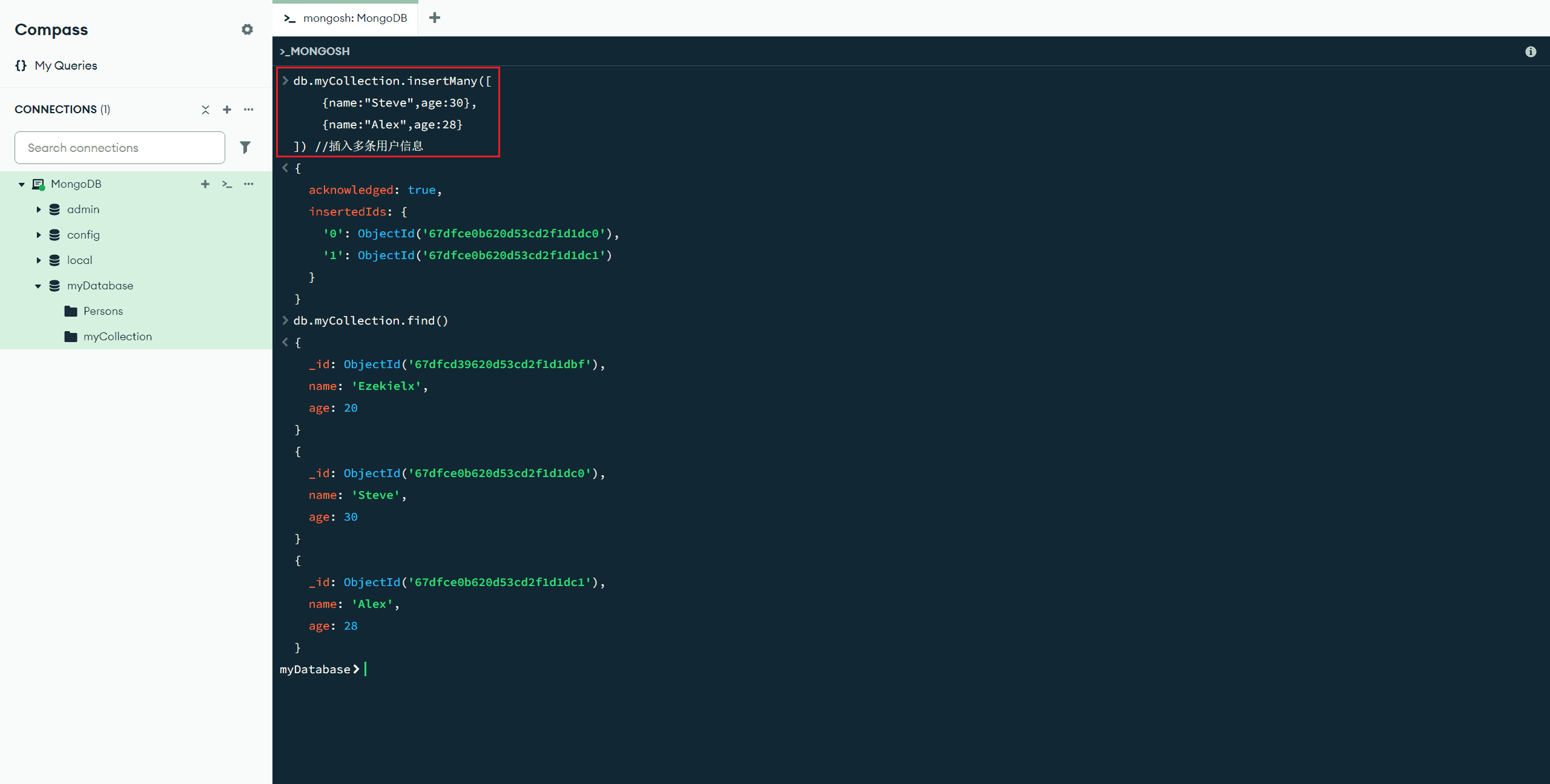
insertMany([<文档1>,<文档2>, ...]) :插入多个文档
db.myCollection.insertMany([
{name:"Steve",age:30},
{name:"Alex",age:28}
]) //插入多条用户信息
2、Removing Document(移除文档)
删除数据库中已有数据,CRUD API 提供了 deleteOne 和 deleteMany 方法来执行删除操作。
这两个方法的第一个参数都是一个过滤文档,该文档指定了一组用于匹配要删除文档的条件。
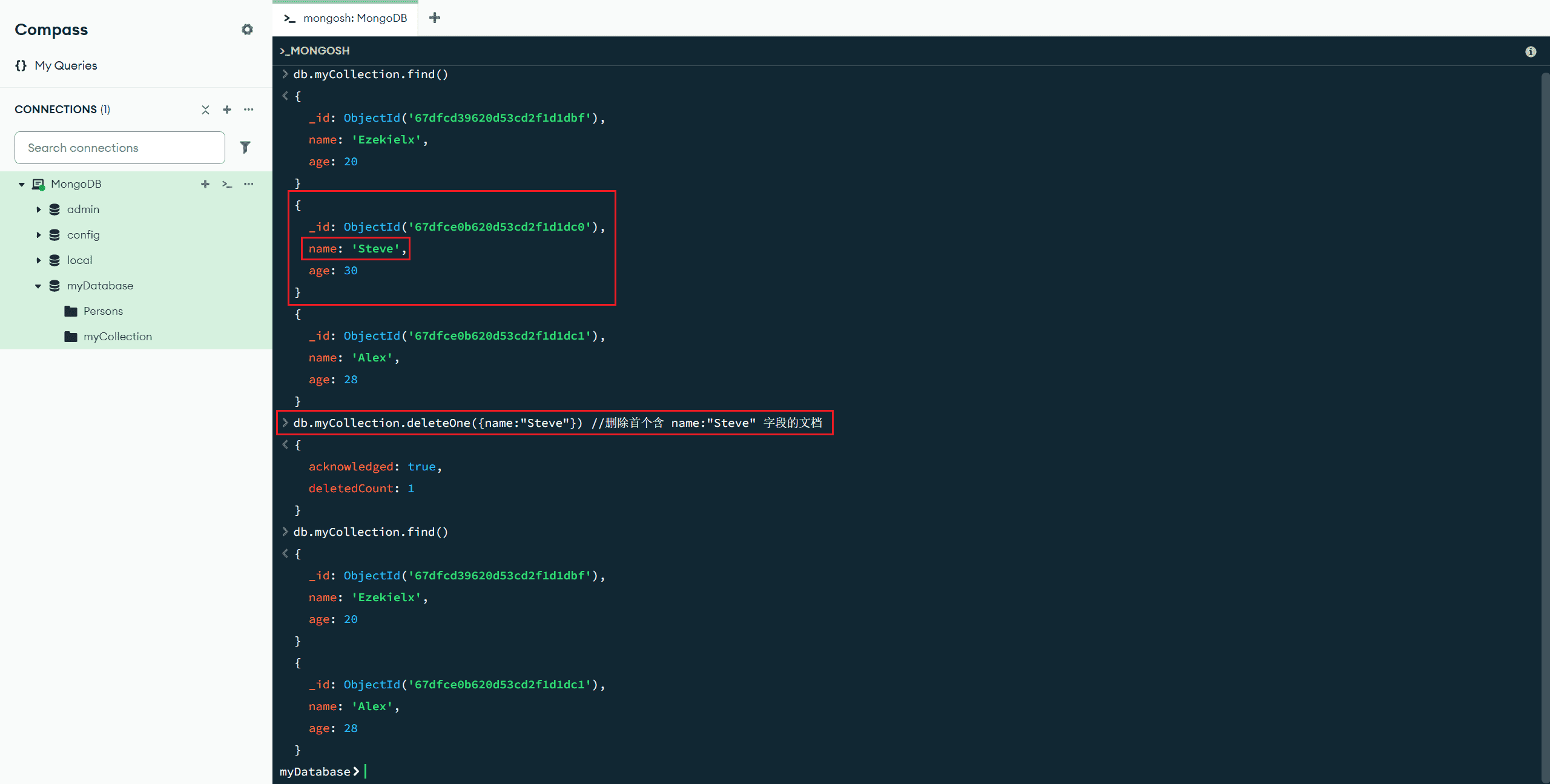
deleteOne(<过滤文档>) :删除匹配的单个文档(如果有多个文档匹配过滤文档,则只会删除第一个)
db.myCollection.deleteOne({name:"Steve"}) //删除首个含 name:"Steve" 字段的文档
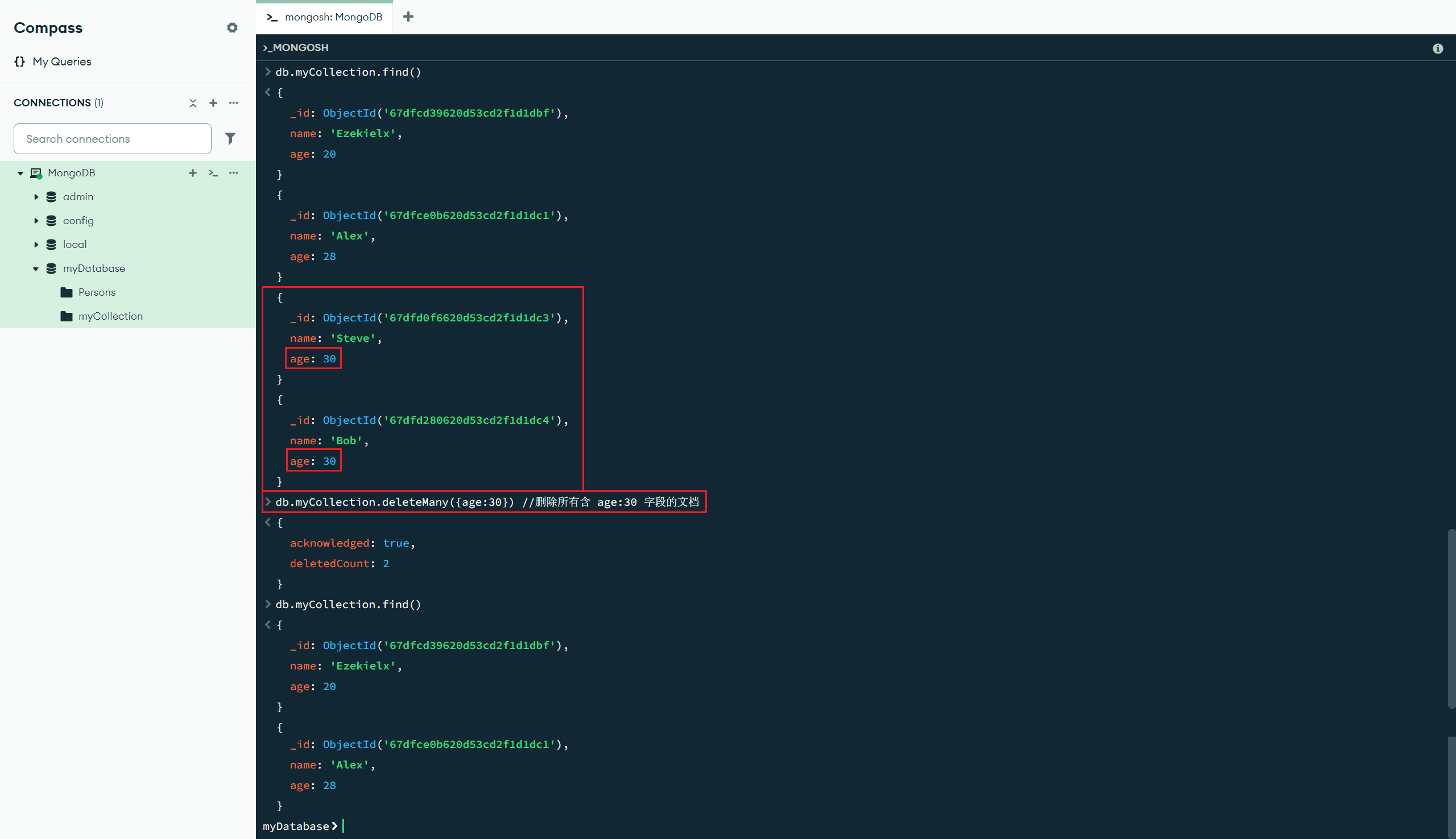
deleteMany(<过滤文档>) :删除匹配的所有文档
db.myCollection.deleteMany({age:30}) //删除所有含 age:30 字段的文档
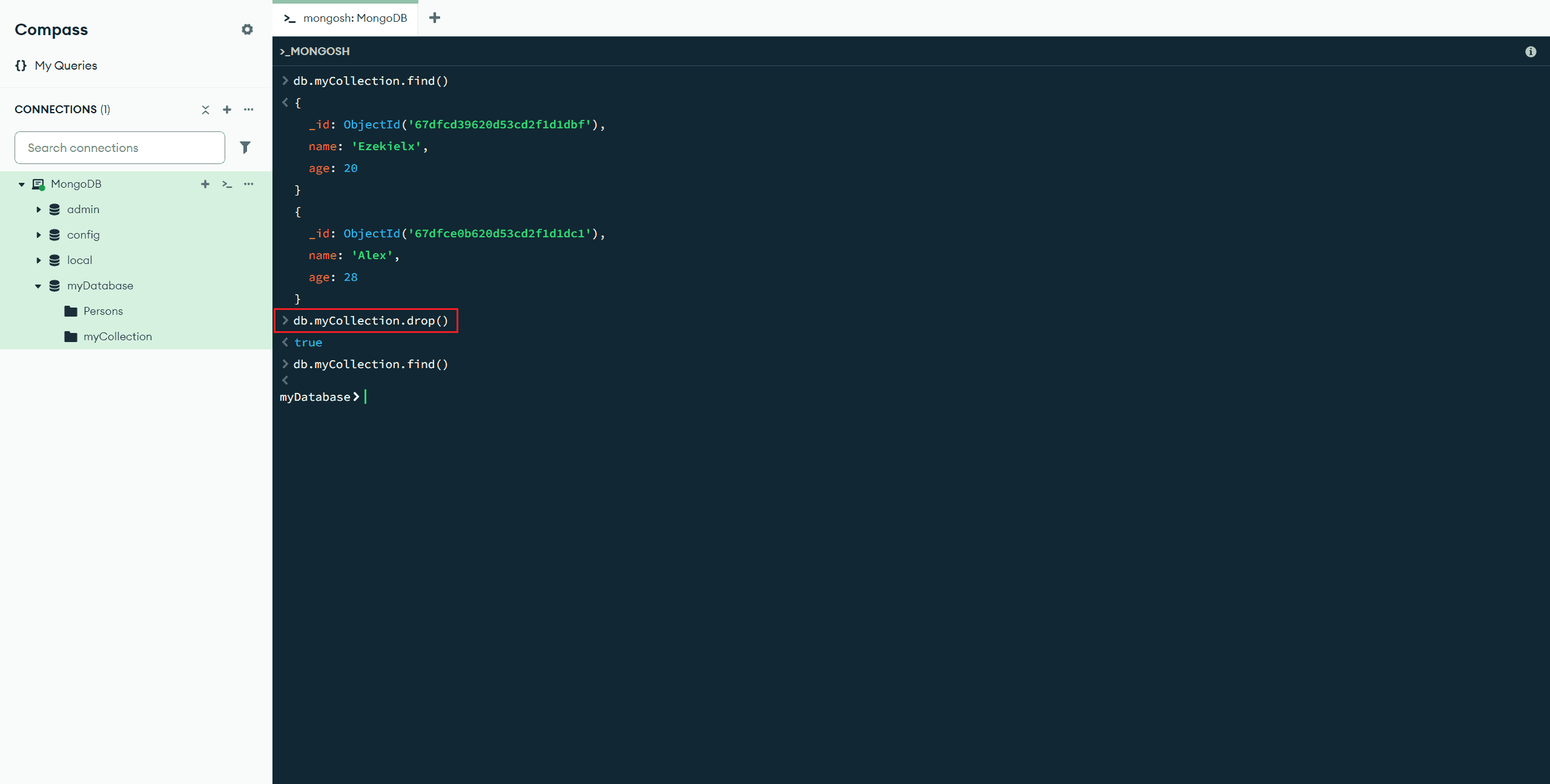
drop() :删除所有文档
db.myCollection.drop() //删除所有文档
3、Updating Documents(更新文档)
一旦文档存储到数据库中,它可以使用以下几种更新方法进行修改:updateOne、updateMany 和 replaceOne。
updateOne 和 updateMany 的第一个参数是筛选文档,用于指定要更新的目标,第二个参数是修改文档,定义具体的更改内容。
replaceOne 也使用筛选文档作为第一个参数,但第二个参数是一个完整的新文档,它会完全替换匹配的旧文档。
更新操作是原子的:如果两个更新同时发生,先到达服务器的更新会先被应用,然后再应用下一个。因此,可以安全地发送多个冲突的更新,而不会导致数据损坏,最终的更新会覆盖之前的内容。(就像原子是不可分割的)
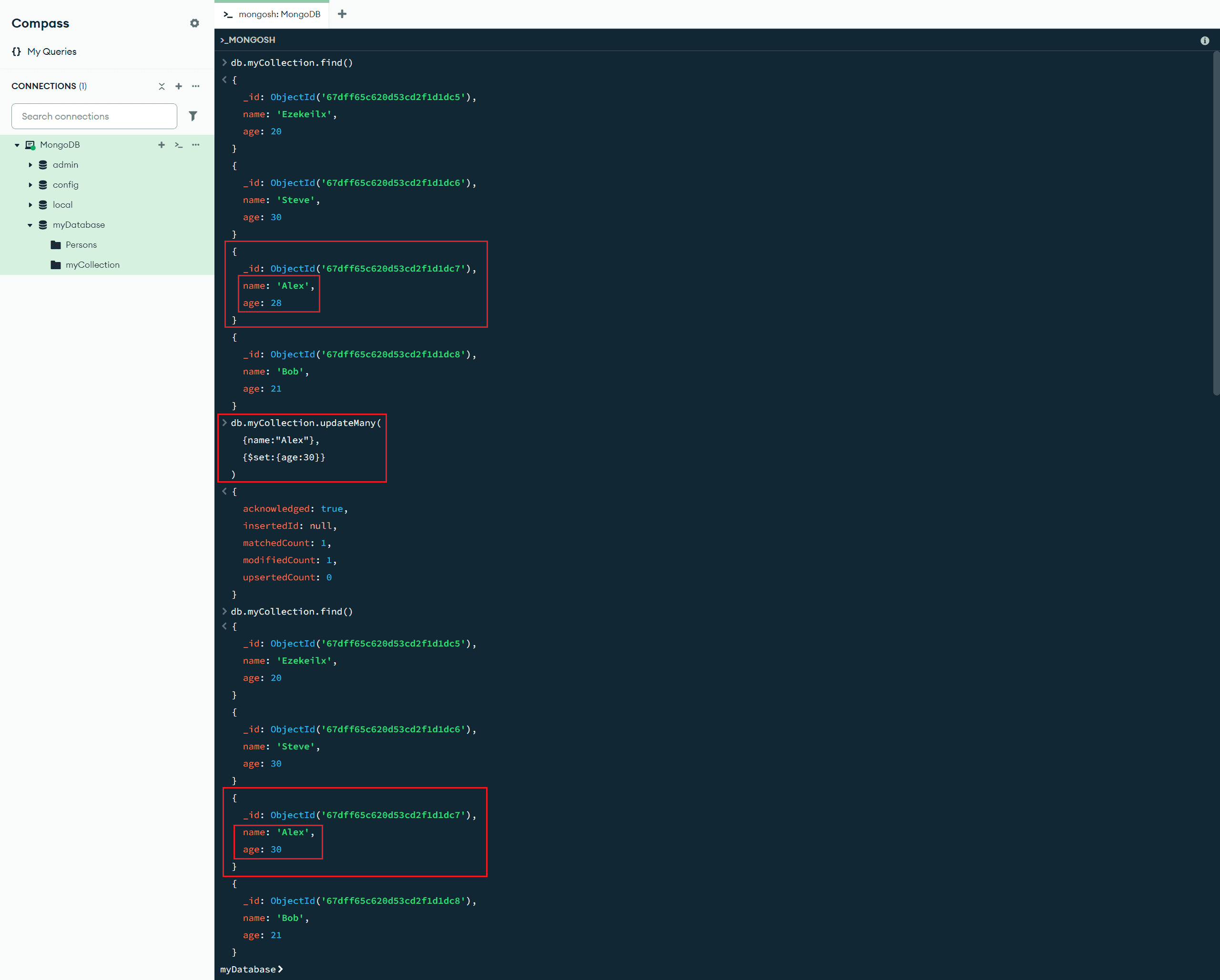
updateOne(<查询条件>,<更新操作>) :更新匹配的单个文档(如果有多个文档匹配,则只会更新第一个)
$set:{<更新字段1>:<更新值1>,<更新字段2>:<更新值2>, ...} :字段更新操作符,会用指定值替换某个字段的值(更多字段更新操作符见:字段更新操作符 - MongoDB手册 v8.0 - MongoDB Docs)
db.myCollection.updateOne(
{name:"Alex"}, // 查询条件
{$set:{age:30}} // 更新操作
)
updateMany(<查询条件>,<更新操作>,<可选操作>) :更新匹配的多个文档
$gte:{<比较字段1>:<比较值1>} :比较表达式操作符,当第一个值大于或等于第二个值时返回 true,否则返回 false(更多比较表达式操作符见:比较表达式操作符 - MongoDB手册 v8.0 - MongoDB Docs)
db.myCollection.updateMany(
{age:{$gte:30}}, // 查询条件
{$set:{salary:4000}} // 更新操作
)

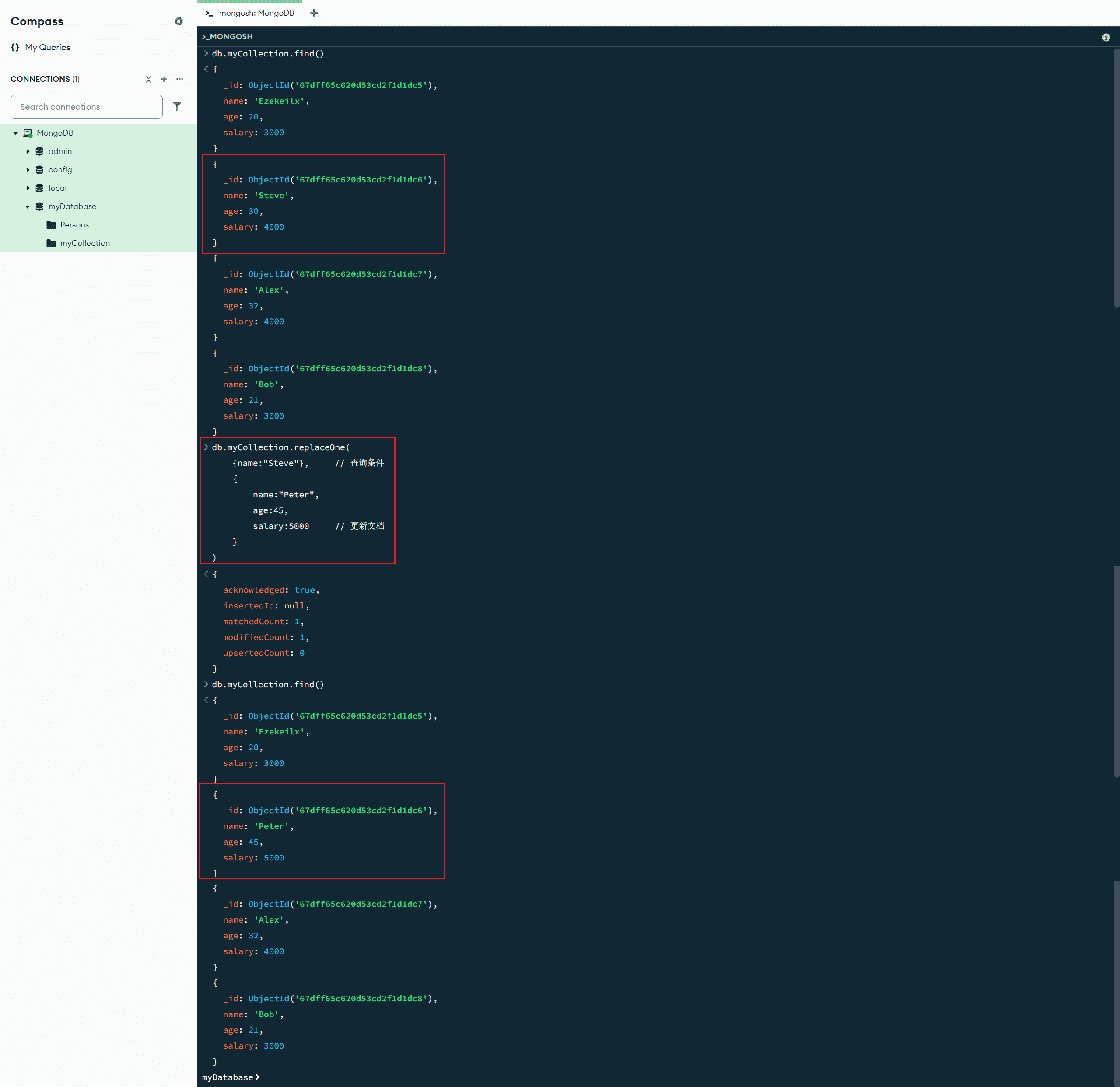
replaceOne(<查询条件>,<更新文档>) :完全替换匹配的文档,适用于大规模模式迁移
db.myCollection.replaceOne(
{name:"Steve"}, // 查询条件
{
name:"Peter",
age:45,
salary:5000 // 更新文档
}
)
4、 Array Operator(数组操作)
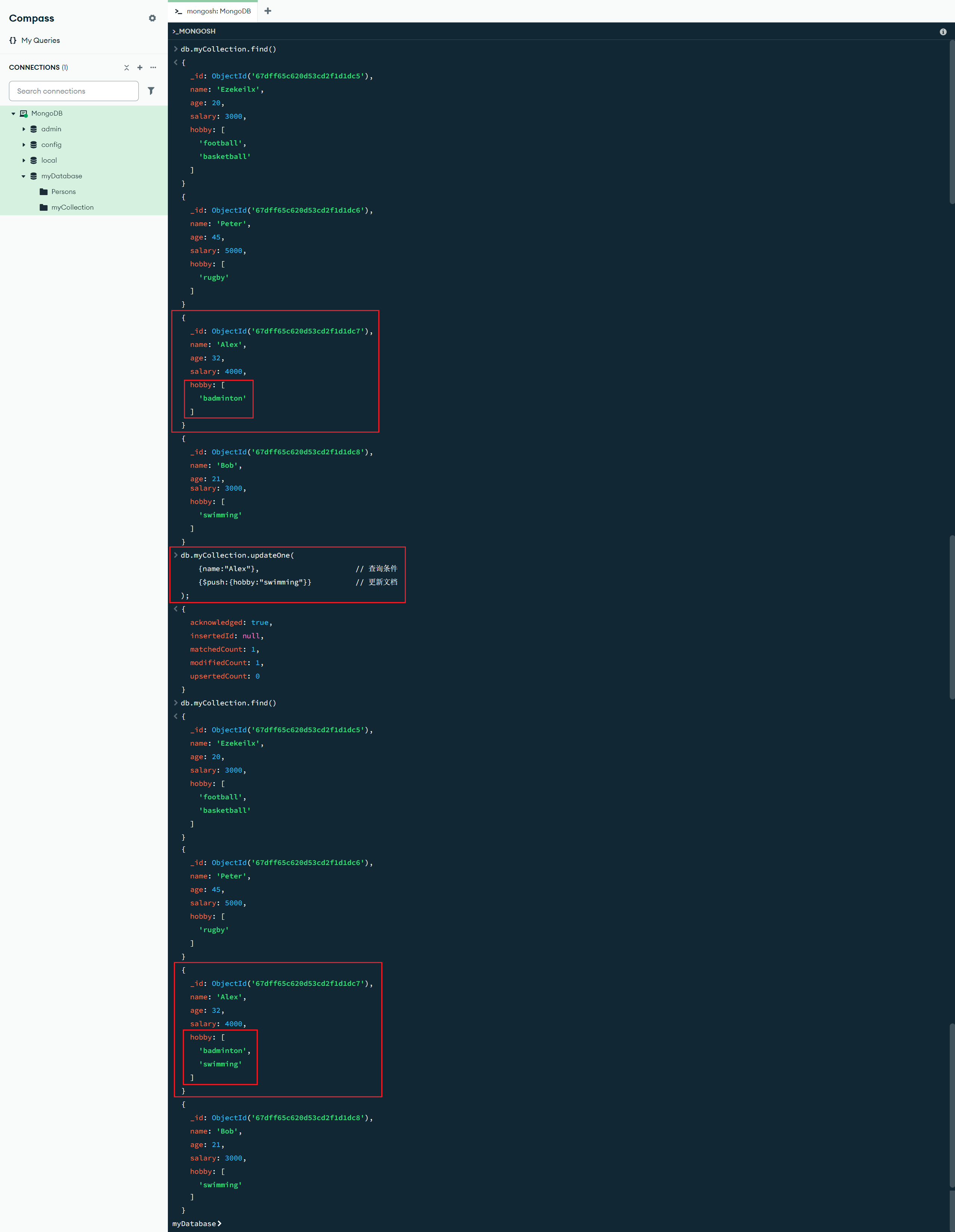
添加元素:
$push:{<更新字段1>:<更新值1>,<更新字段2>:<更新值2>, ...} :数组更新操作符,用于向数组追加元素,如果数组不存在,则会创建新的数组(更多数组更新操作符见:更新操作符 - MongoDB手册 v8.0 - MongoDB Docs)
db.myCollection.updateOne(
{name:"Alex"}, // 查询条件
{$push:{hobby:"swimming"}} // 更新文档
);
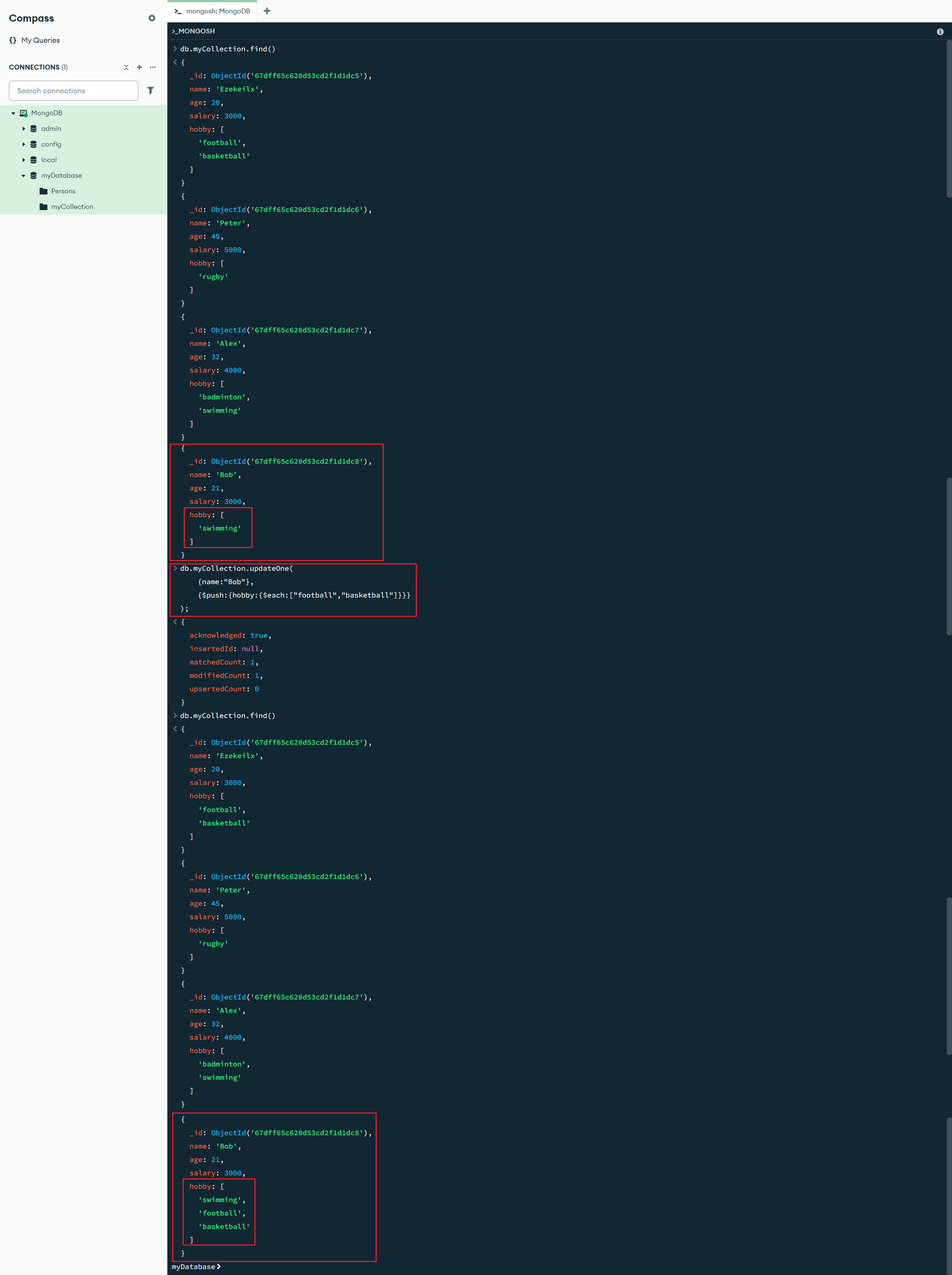
$each:[<更新值1>,<更新值2>, ...] :数组更新操作符修改器,与 $push、$addToSet 操作符一起使用,将多个值附加到数组(更多数组更新操作符修改器见:更新操作符修改器 - MongoDB手册 v8.0 - MongoDB Docs)
db.myCollection.updateOne(
{name:"Bob"},
{$push:{hobby:{$each:["football","basketball"]}}}
);
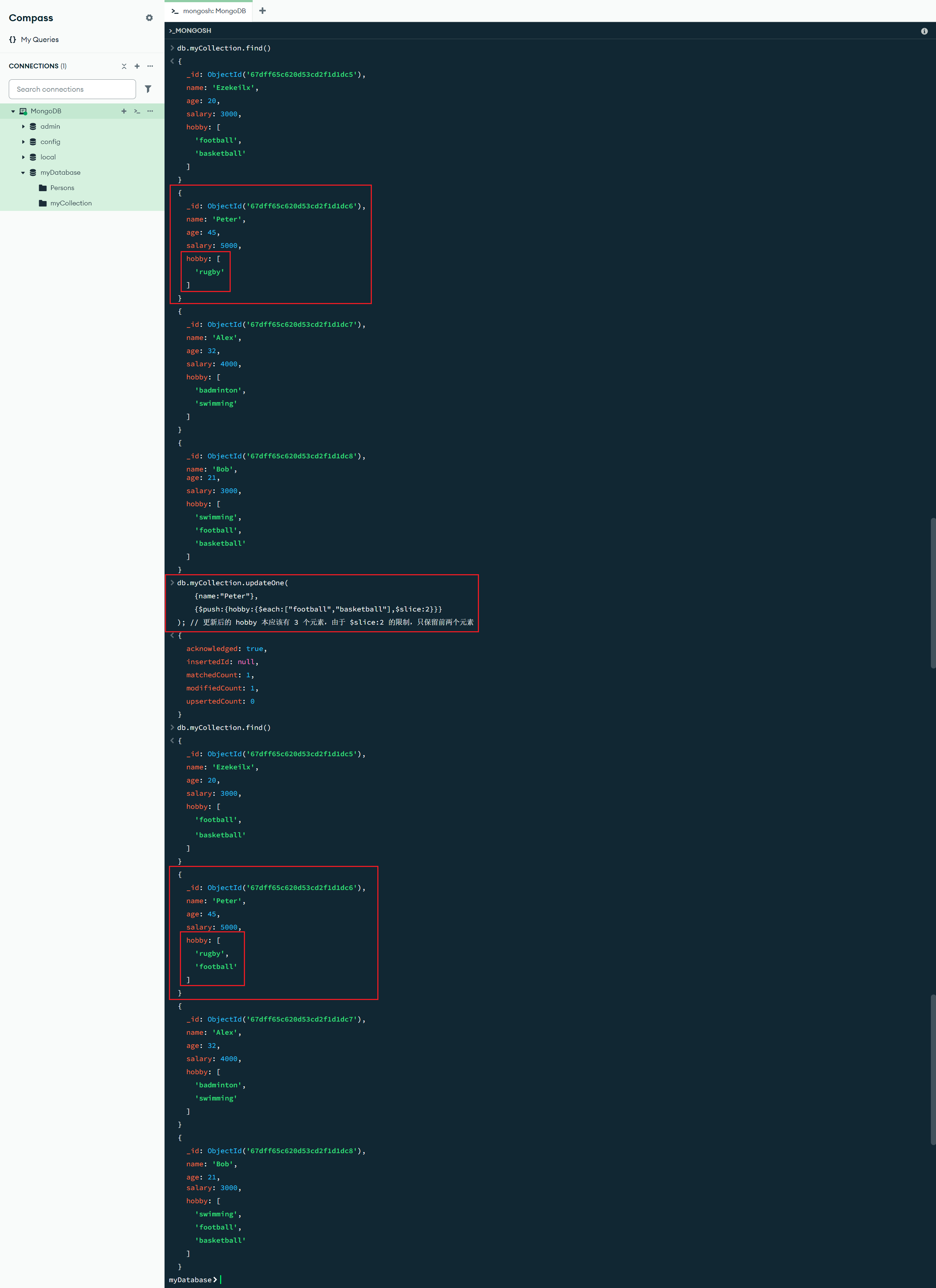
$slice:<参数> :更新操作符修改器,$slice 修饰符限制 $push 操作元素的数量。限制数组的长度:当 <参数> 为 0 时,更新字段返回一个空数组;当 <参数> 大于 0 时,更新字段返回前 <参数> 个元素;当 <参数> 小于 0 时,更新字段返回后 <参数> 个元素
db.myCollection.updateOne(
{name:"Peter"},
{$push:{hobby:{$each:["football","basketball"],$slice:2}}}
); // 更新后的 hobby 本应该有 3 个元素,由于 $slice:2 的限制,只保留前两个元素
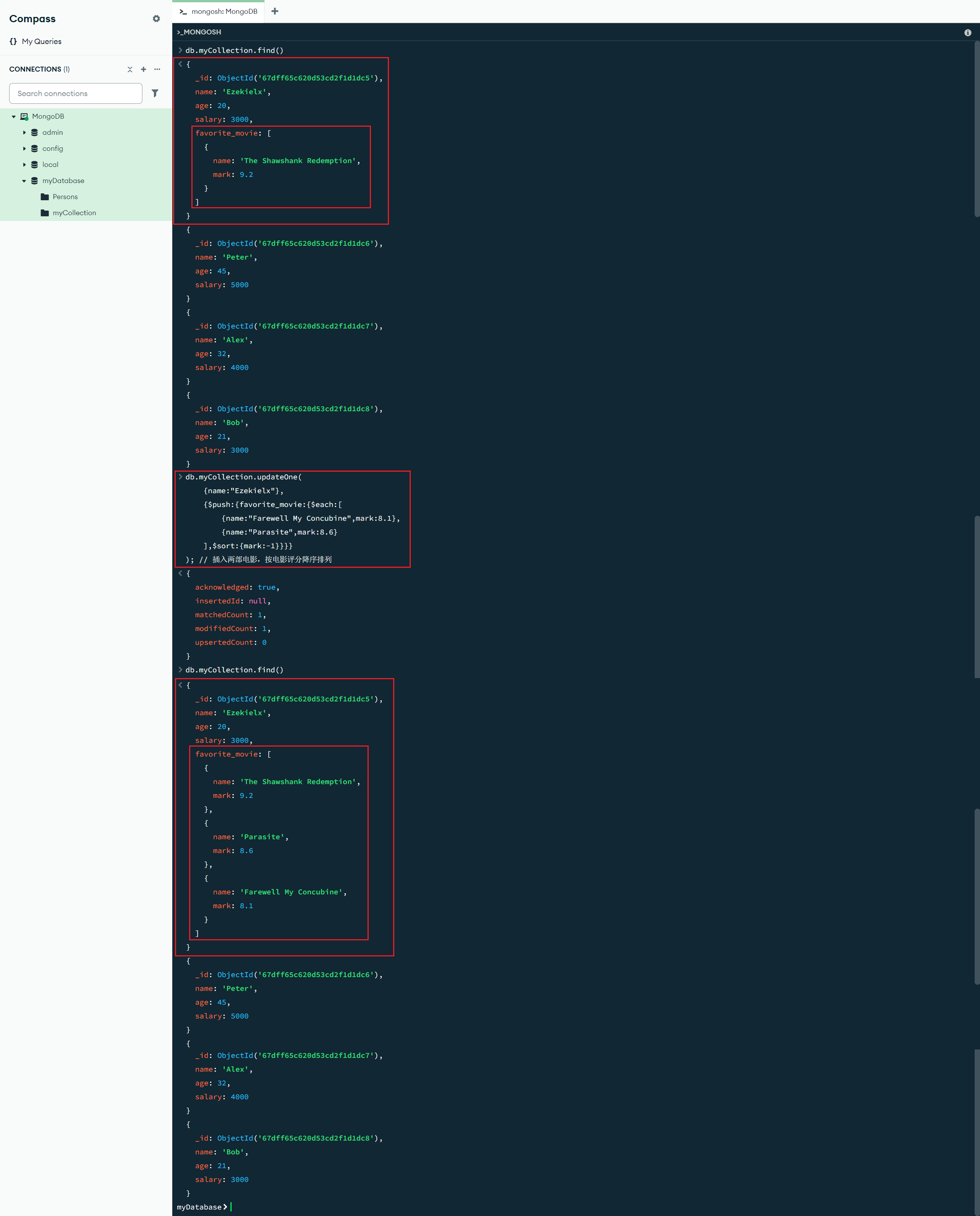
$sort:{<排序字段>:<参数>} :更新操作符修改器,$sort 修饰符在 $push 操作期间对数组的元素进行排序,<参数> 为 1 时升序;为 -1 时降序
db.myCollection.updateOne(
{name:"Ezekielx"},
{$push:{favorite_movie:{$each:[
{name:"Farewell My Concubine",mark:8.1},
{name:"Parasite",mark:8.6}
],$sort:{mark:-1}}}}
); // 插入两部电影,按电影评分降序排列
数组去重:
$addToSet:{<更新字段1>:<更新值1>,<更新字段2>:<更新值2>, ...} :数组更新操作符,$addToSet 操作符会将值添加到数组中,除非该值已经存在
db.myCollection.updateOne(
{name:"Ezekielx"},
{$addToSet:{favorite_movie:{$each:[
{name:"Farewell My Concubine",mark:8.1},
{name:"Inception",mark:8.8}
]}}}
); // 插入两部电影,由于使用 $addToSet,重复的 {name:"Farewell My Concubine",mark:8.1} 不会被加入
删除数组元素:
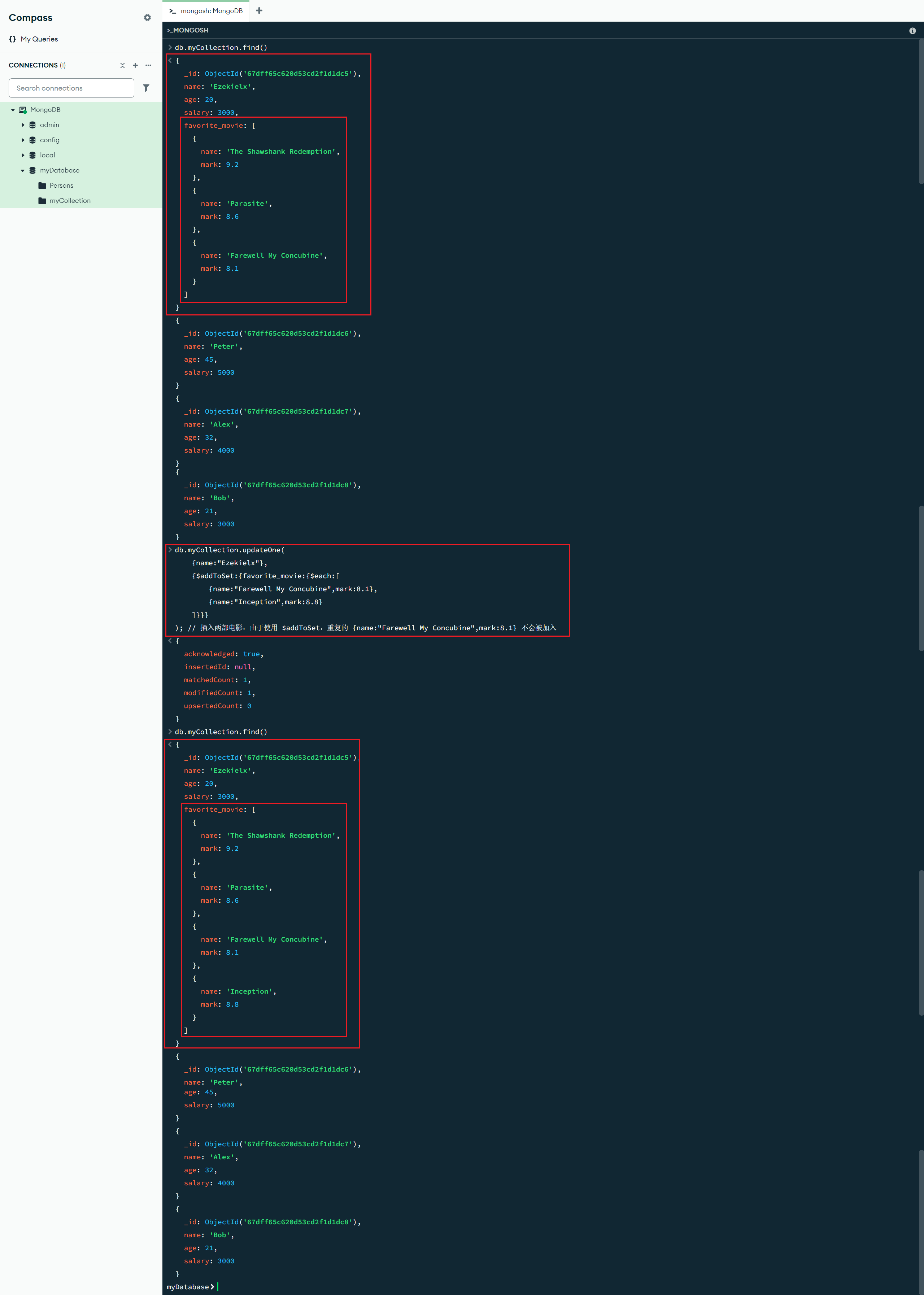
$pop:{<更新字段>:<-1/1>} :数组更新操作符,$pop 操作符删除数组的第一个元素或最后一个元素。为 $pop 传入 -1 的值,可以删除数组中的第一个元素,传入 1 的值则可以删除数组中的最后一个元素
db.myCollection.updateOne({name:"Ezekielx"},{$pop:{favorite_movie:-1}}); // 删除 favorite_movie 中的第一个元素
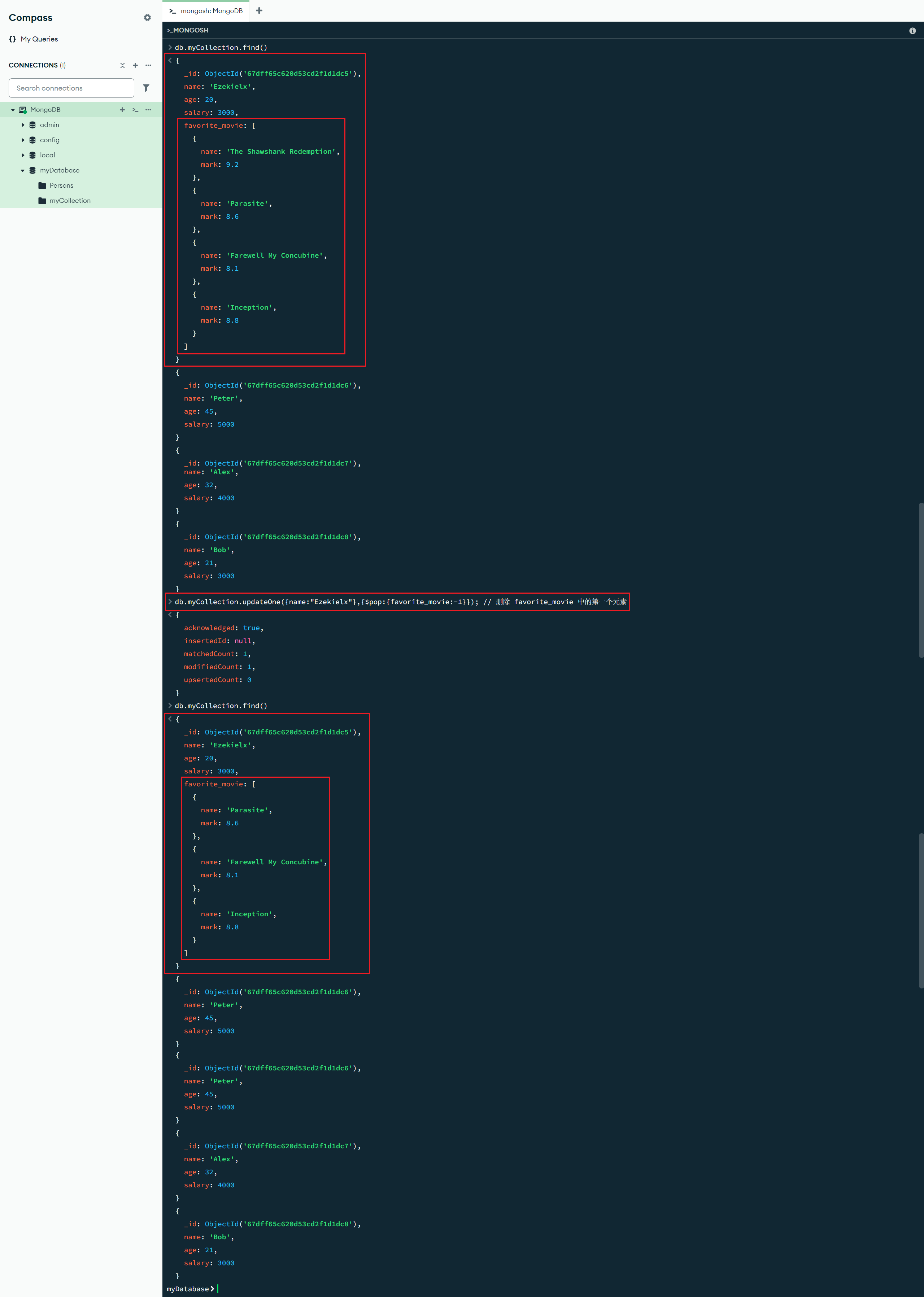
$pull:{<更新字段1>:<删除值1>,<更新字段2>:<删除值2>, ...} :数组更新操作符,$pull 操作符会从现有数组中删除符合指定条件的一个或多个值的所有实例
db.myCollection.updateOne({name:"Alex"},{$pull:{schedule:"play"}}); // 删除 schedule 中所有的 "play" 元素
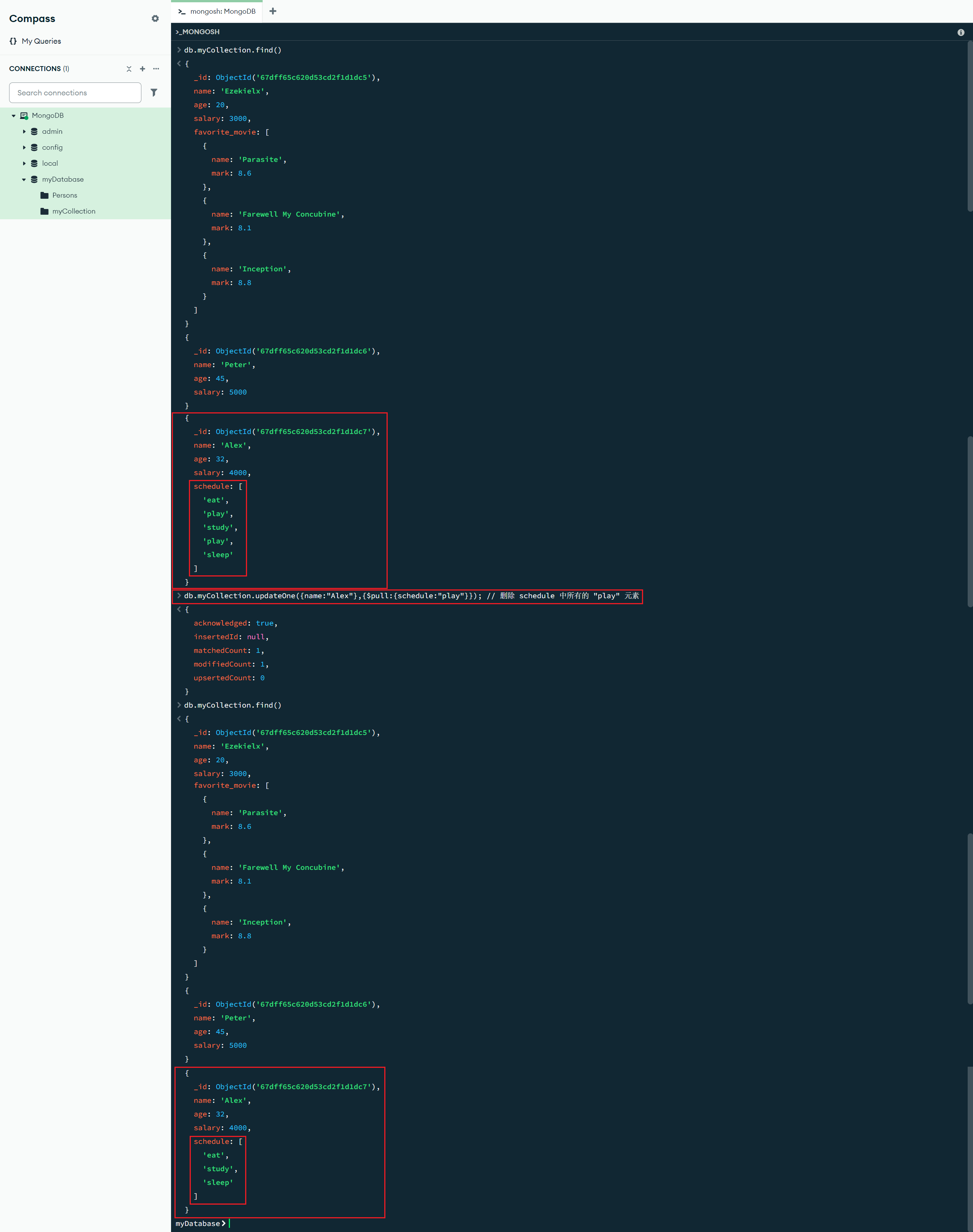
修改数组内的某个元素:
按索引修改
$inc:{<更新字段1>:<递增值1>,<更新字段2>:<递增值2>, ...} :更新操作符,将指定字段但特定值递增
db.myCollection.updateOne(
{name:"Ezekielx"},
{$inc:{"favorite_movie.0.mark":1}}
) // 将 favorite_movie 数组中索引为 0 的元素的 mark 字段的值加 1(由于 "favorite_movie.0.mark" 是一个完整的字段所以需要加引号,而 name 字段不加是因为 Mongodb 会自动解析简单的字段)
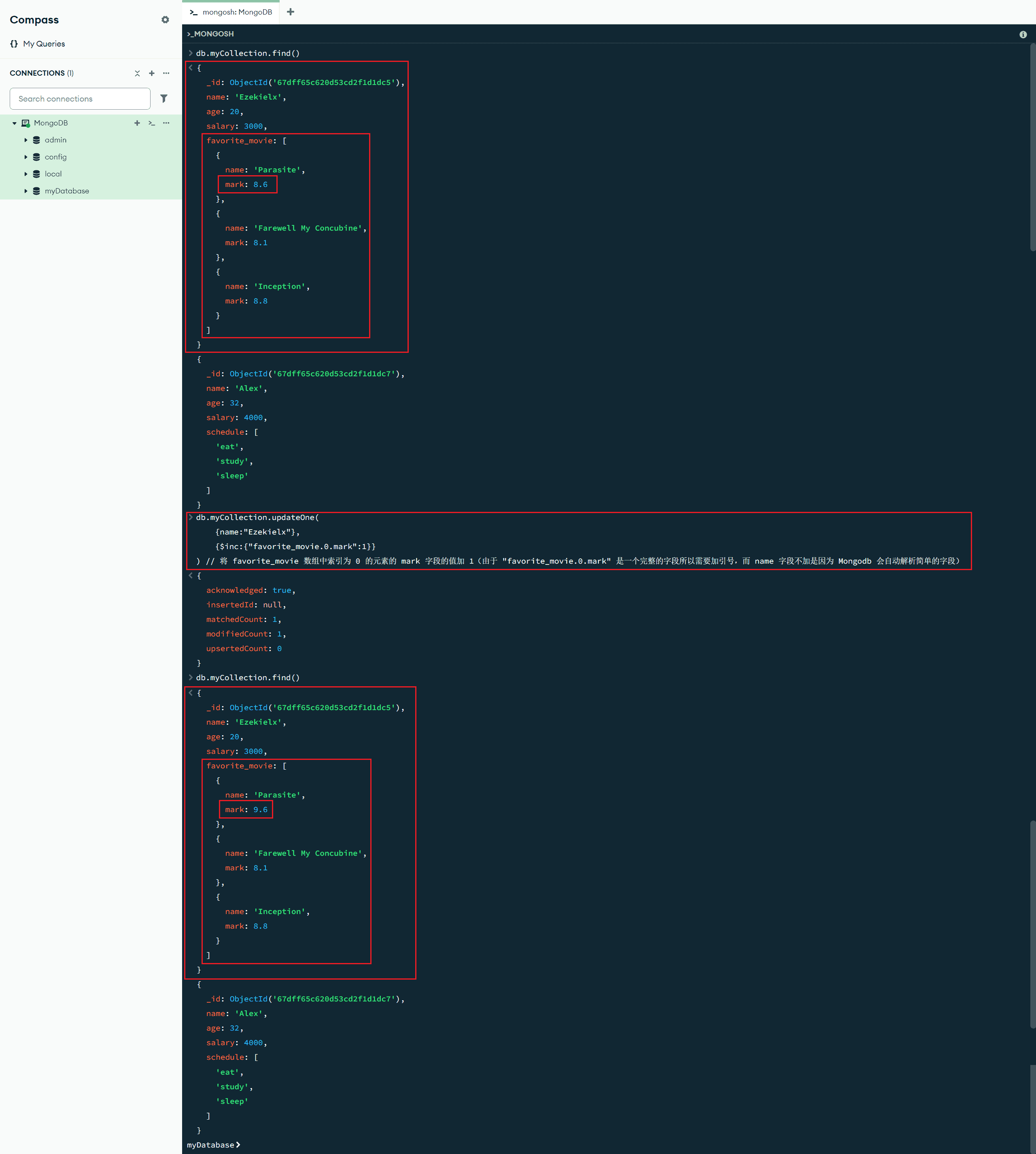
按位置运算符修改
$ :数组更新操作符,充当占位符,用于更新与查询条件匹配的第一个元素
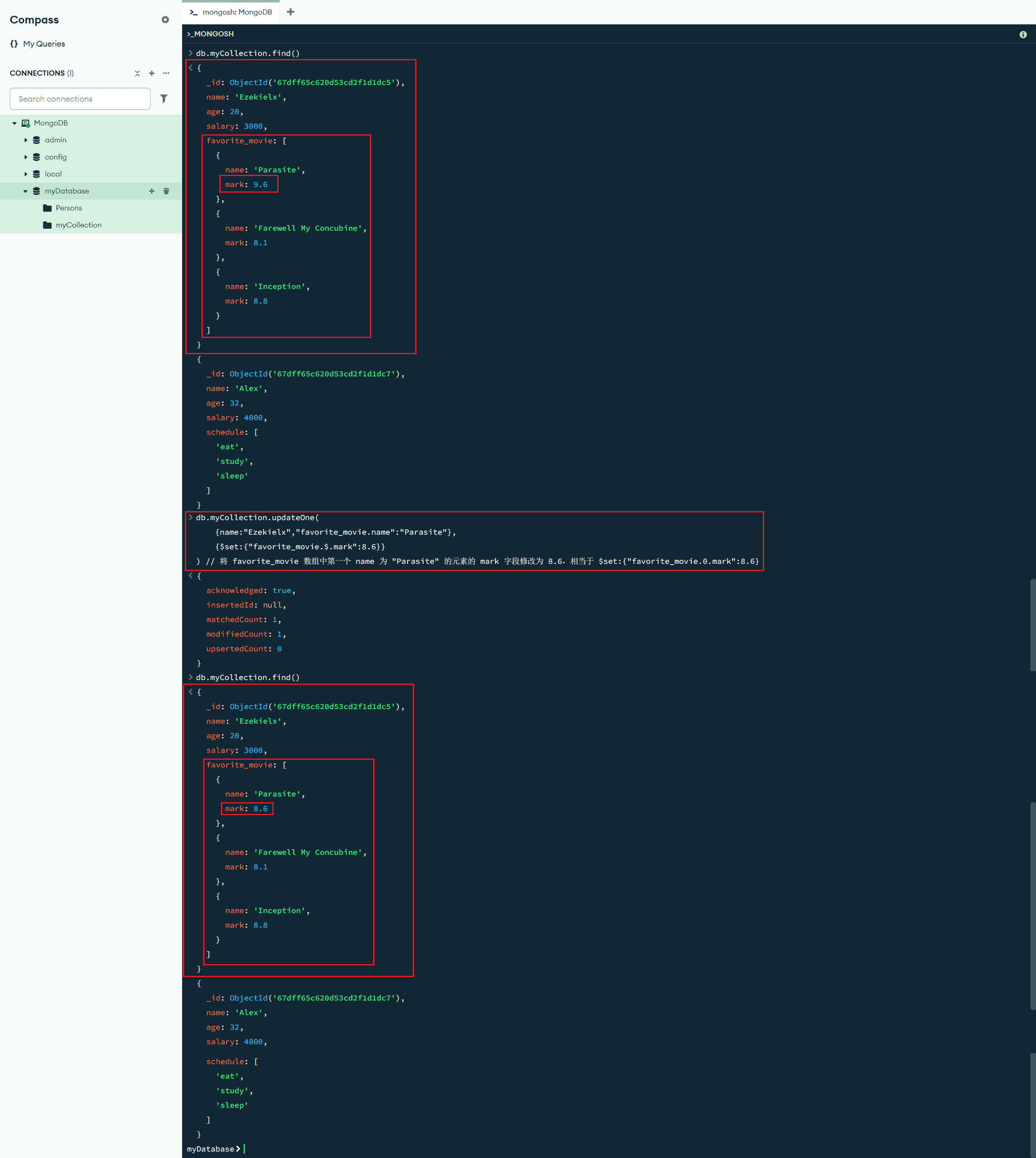
db.myCollection.updateOne(
{name:"Ezekielx","favorite_movie.name":"Parasite"},
{$set:{"favorite_movie.$.mark":8.6}}
) // 将 favorite_movie 数组中第一个 name 为 "Parasite" 的元素的 mark 字段修改为 8.6,相当于 $set:{"favorite_movie.0.mark":8.6}
5、Upserts(插入或更新)
Upsert 是一种特殊类型的更新操作。如果查询不到匹配的文档,则会创建一个新文档;如果匹配到,则正常更新。
Upsert 可以简化代码,不必先查询再决定是否插入新文档。
updateOne、updateMany、replaceOne 等更新操作都将 upsert 设为可选项,默认为 false。(比如官方文档中的 updateOne 方法参数)
upsert:true/false :如果查询不到匹配的文档,则会创建一个新文档;如果匹配到,则正常更新
db.myCollection.updateOne(
{name:"Alice"},
{$set:{age:25,city:"Shanghai"}},
{upsert:true}
) // 查询 myCollection 是否含 name:"Alice" 的文档。如果有则正常更新;没有则创建含 name:"Alice" 的文档,并更新内容

$setOnInsert:{<更新字段1>:<更新值1>,<更新字段2>:<更新值2>, ...}:更新操作符,它仅在插入(Insert)新文档时设置指定的字段,而在**更新(Update)**时不会修改这些字段
db.myCollection.updateOne(
{name:"Alice"},
{$setOnInsert:{age:18,salary:3000}},
{"upsert":true}
) // 查询 myCollection 是否有含 name:"Alice" 的文档。如果含 name:"Alice",则不更新;如果不含,则插入含 name:"Alice" 的新文档且更新内容

Chapter 3:Working with MongoDB index,geospatial data and timeseries
LocalBites 是一家初创公司,他的目标是提供关于附近餐厅的实时信息、优化配送路线,并生成有关用户偏好和餐厅人气的有价值分析。关键内容包括索引的实现、地理空间索引以及聚合管道的使用。
LocalBites 所处的是一个竞争激烈的市场,在这里,快速的响应时间和准确的基于位置的数据对于用户满意度至关重要。该应用程序的后端基于 MongoDB 构建。随着用户数量的增长,团队在高效处理大量数据集和复杂查询方面面临性能挑战。
为了提升查询性能,开发团队首先在常用查询字段上创建索引。例如,他们在 restaurants(餐厅)集合中的 cuisine(菜系)和 rating(评分)字段上创建了一个复合索引,从而优化了按菜系和评分筛选餐厅的查询,大大减少了查询执行时间。
一、Understanding the index(理解索引)
1、Introduction to index(索引简介)
数据库中的索引类似于一本书的目录。与其翻阅整本书查找内容,不如直接查看有序的目录列表,这使得 MongoDB 能以数量级的速度提升查询效率。
如果一个查询不使用索引,就会执行 集合扫描(collection scan),意味着服务器要“从头看到尾”来找到结果。就像你在没有目录的书中查信息一样,从第一页开始,一页页翻阅。对于大集合而言,集合扫描效率非常低,应尽量避免。
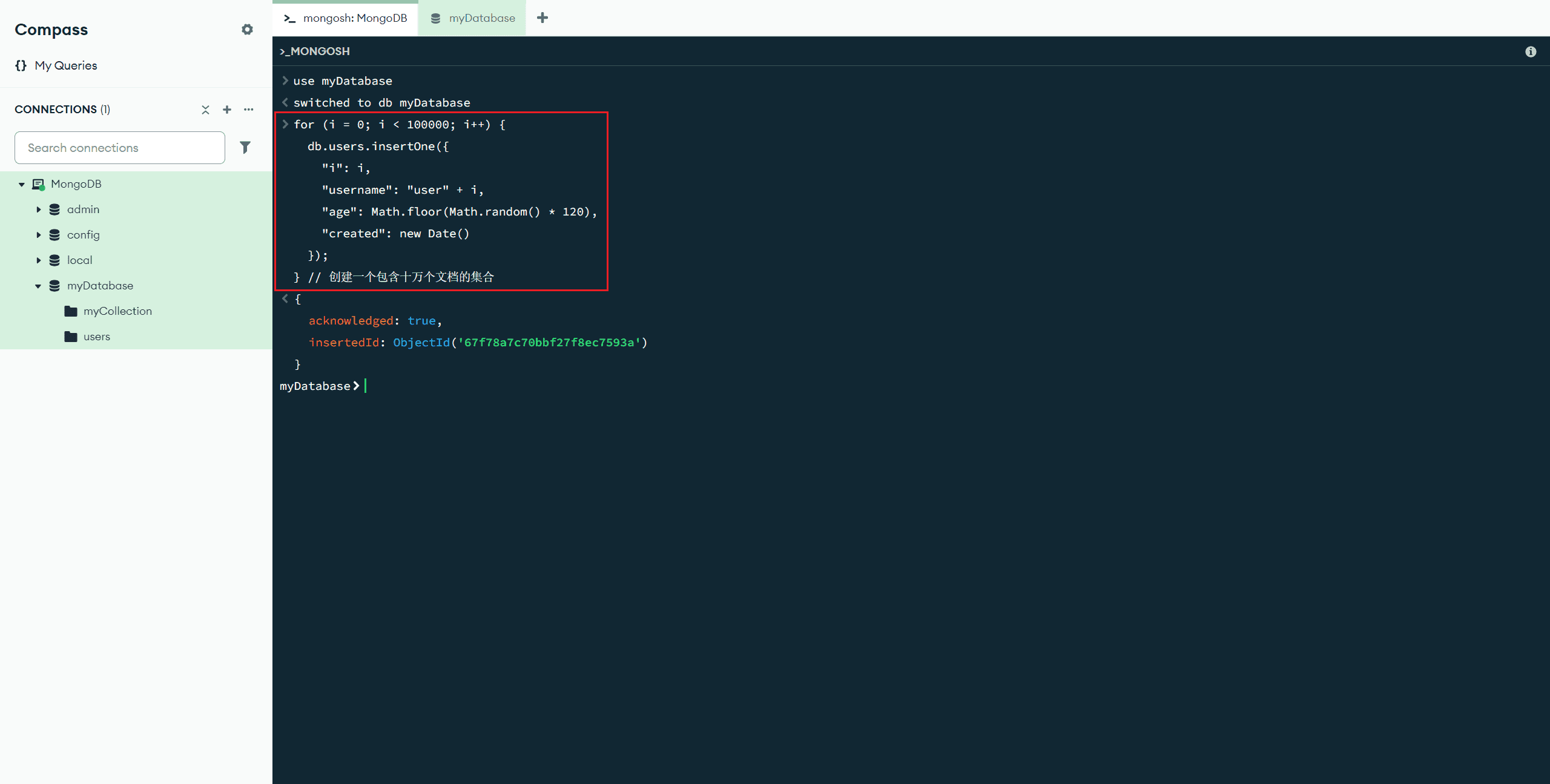
创建一个包含十万个文档的集合示例:
for (i = 0; i < 100000; i++) {
db.users.insertOne({
"i": i,
"username": "user" + i,
"age": Math.floor(Math.random() * 120),
"created": new Date()
});
} // 创建一个包含十万个文档的集合
当我们在集合中进行查询时,可以使用 explain 命令 来查看 MongoDB 执行查询的方式。cursor 的 explain 方法,它可以分析多种 CRUD 操作的执行过程。我们将使用 executionStats 模式,因为它能帮助我们理解使用索引前后的执行效率差异(了解就好)。
db.users.find({"username": "user101"}).explain("executionStats")

这条命令的返回结果中,关注以下几点:
"stage": "COLLSCAN"表示执行的是集合扫描。"totalDocsExamined": 100000表示 MongoDB 检查了所有的 10 万条文档。"executionTimeMillis": 94表示查询耗时约 94 毫秒。"nReturned": 1表示最终返回了 1 条匹配的记录。
也就是说,MongoDB 不知道 username 是唯一的,因此只能一条条扫描所有文档,效率很低。
为了提升查询效率,应该为你的应用中所有常用的查询模式创建索引。“查询模式”是指你应用中会向数据库提出的各种查询方式。在本例中,就是通过 username 查询用户,这是一个典型的查询模式。
在很多应用中,一个索引可以支持多个查询模式。关于如何为查询模式定制索引,会在后面说明。
一个未使用索引的查询称为集合扫描(Collection Scan),如果使用了索引,则称为索引扫描(Index Scan)。
2、 Creating an Index(创建索引)
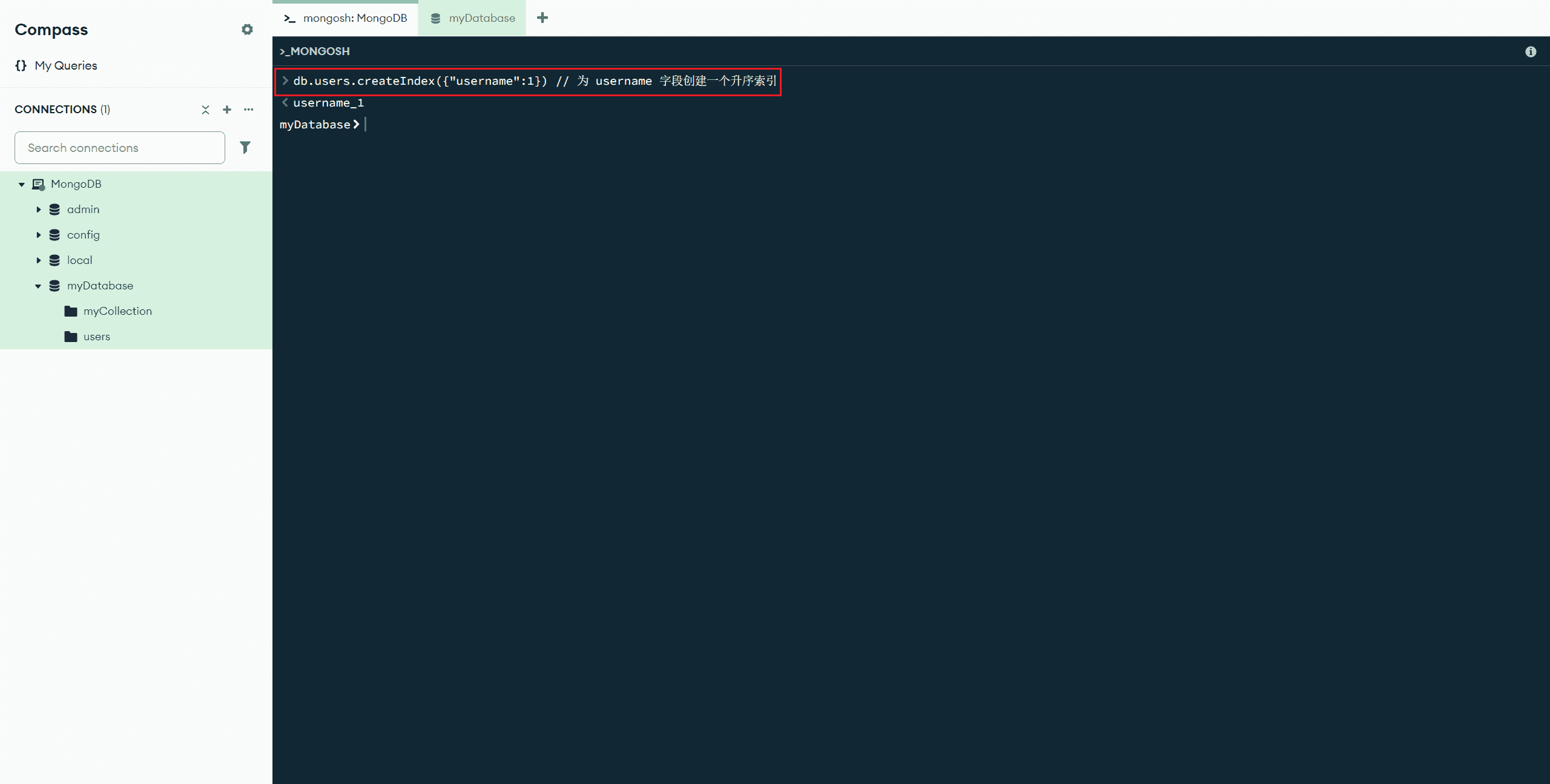
createIndex(<关键字>,<选项>,<行为>) :创建索引(更多信息详见官方文档:db.collection.createIndex() - Database Manual v8.0 - MongoDB Docs)
db.users.createIndex({"username":1}) // 为文档创建一个 username 字段的升序索引
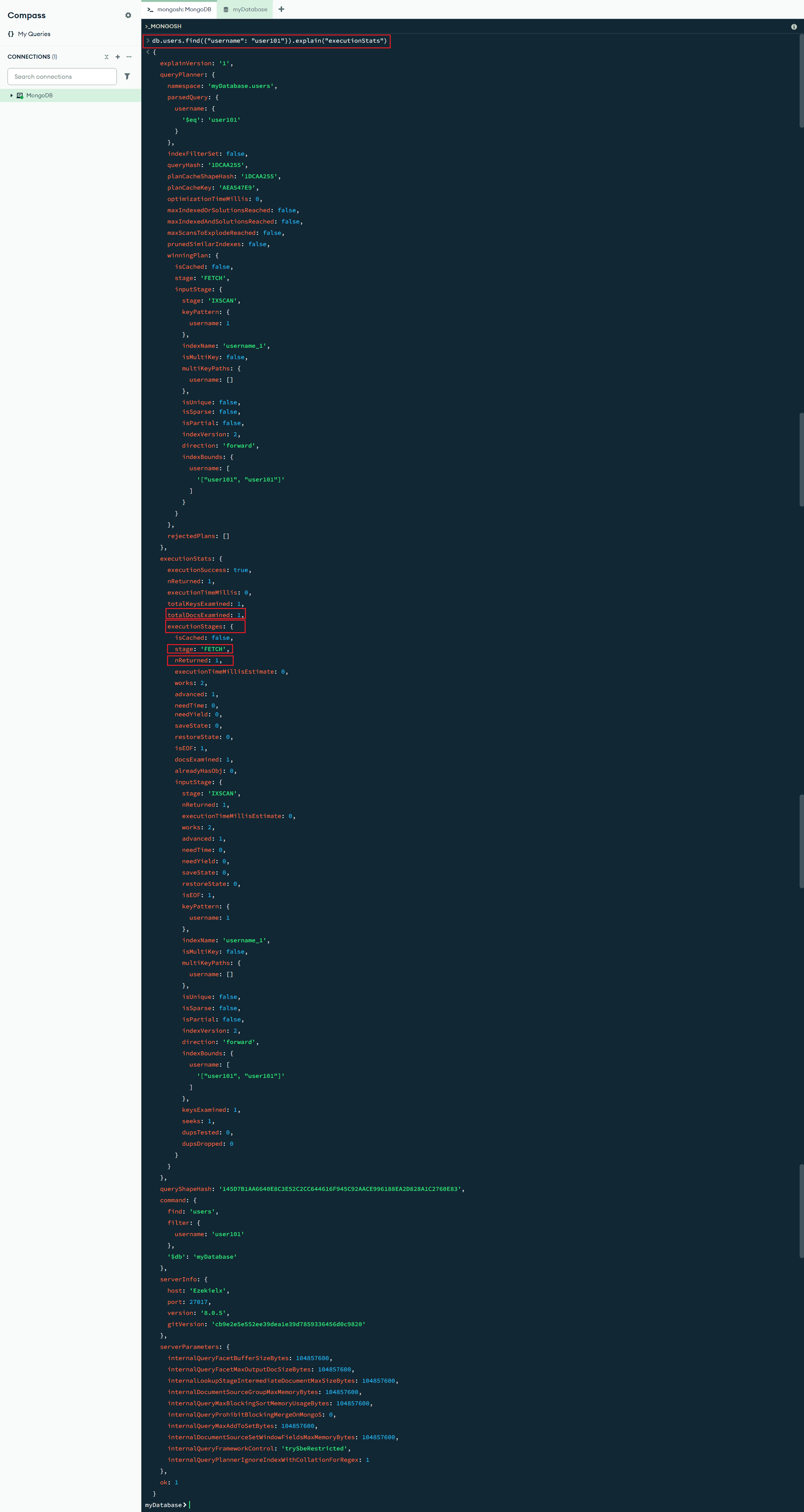
创建索引后,再次执行查询命令 db.users.find({"username": "user101"}).explain("executionStats"),这条命令的返回结果中,关注以下几点:
"stage": "FETCH"表示执行的是从索引中获取数据。"totalDocsExamined": 1表示 MongoDB 只检查了 1 条文档。executionTimeMillis": 0表示查询几乎是瞬间完成的。"nReturned": 1表示最终返回了 1 条匹配的记录。
3、The complex Index(复合索引)
索引的目的是尽可能让你的查询效率更高。 对于很多查询模式,通常需要基于两个或多个字段来建立索引。
例如,索引会将所有的值按照顺序排序,因此在根据被索引的字段进行排序时,速度会更快。 不过,只有当排序字段是索引的前缀时,索引才能对排序起作用。
假设索引是:{"age": 1, "username": 1, "created": -1}
能用索引排序的情况(前缀):
sort({"age": 1})✅sort({"age": 1, "username": 1})✅sort({"age": 1, "username": 1, "created": -1})✅因为这几个排序字段正好是索引最左边连续的一部分
不能用索引排序的情况(不是前缀):
sort({"username": 1})❌sort({"created": -1})❌sort({"username": 1, "created": -1})❌因为这些都跳过了最左边的
age,不连续,不是前缀,MongoDB就没法用索引来排。
db.users.createIndex({"age":1,"username":1}) // 为文档创建一个包含 age 和 username 字段复合索引
这个就是一个复合索引(compound index),当你的查询条件涉及多个字段或者多种排序方式时,复合索引就能发挥很大的作用。复合索引是指基于多个字段建立的索引。
4、文本搜索的索引
假设我们有一个包含维基百科文章的集合,并且我们希望对其进行索引。为了在文本上进行搜索,我们首先需要创建一个文本索引。以下命令将基于 "title" 和 "body" 字段中的术语创建索引:
db.articles.createIndex({"title": "text", "body": "text"})
使用 $text 查询操作符,可以在具有文本索引的集合上执行文本搜索。$text 会使用空格和大多数标点符号作为分隔符对搜索字符串进行分词,并对所有分词执行逻辑 OR 操作。
例如,你可以使用以下查询来查找包含 "impact"、"crater" 或 "lunar" 任意一个术语的所有文章。由于我们的索引是基于文章的 "title" 和 "body" 字段中的术语,因此该查询会匹配那些在任一字段中出现这些术语的文档。
我们还可以通过在查询中使用短语来进一步解决查询的问题。可以通过将短语放入双引号中来搜索精确短语。例如,以下查询将查找包含短语 "impact crater"的所有文档。MongoDB 会将此查询转换为 "impact crater" AND "lunar":
db.articles.find({$text: {$search: "\"impact crater\" lunar"}},{title: 1}).limit(10)
查询结果如下:
{ "_id" : "2621724", "title" : "Schjellerup (crater)" }
{ "_id" : "2622075", "title" : "Steno (lunar crater)" }
{ "_id" : "168118", "title" : "South–PoleAitken basin" }
{ "_id" : "1509118", "title" : "Jackson (crater)" }
{ "_id" : "10096822", "title" : "Victoria Island structure" }
{ "_id" : "968071", "title" : "Buldhana district" }
{ "_id" : "780422", "title" : "Puchezh−Katunki crater" }
{ "_id" : "28088964", "title" : "Svedberg (crater)" }
{ "_id" : "780628", "title" : "Zeleny Gai crater" }
{ "_id" : "926711", "title" : "Fracastorius (crater)" }
二、Understanding the geospatial index(理解地理索引)
1、GeoSpatial Index(地理索引)
MongoDB 有两种地理空间索引类型:2dsphere 和 2d。
- 2dsphere 索引:适用于基于 WGS84 基准的球面几何体,WGS84 模型把地球视为一个略扁的椭球体,因此 2dsphere 索引在计算距离时会考虑地球的形状,比 2d 索引计算两城市等位置间的距离更准确。
- 2d 索引:适用于存储在二维平面上的点。
2dsphere 索引允许你用 GeoJSON 格式来表示点、线和多边形的几何图形。
一个点(Point)用一个包含两个元素的数组表示,格式是 [经度, 纬度]。
例如,一个点的 GeoJSON 格式是:
"name": "New York City",
"loc": {
"type": "Point",
"coordinates": [50, 2]
}
一条线(LineString)由一组点坐标组成,格式如下:
"name": "Hudson River",
"loc": {
"type": "LineString",
"coordinates": [[0,1], [0,2], [1,2]]
}
一个多边形(Polygon)由一组坐标点组成,表示多边形的顶点顺序,格式如下:
"name": "New England",
"loc": {
"type": "Polygon",
"coordinates": [[0,1], [0,2], [1,2]]
}
注意,GeoJSON 中嵌套对象的字段名称是固定的,不能更改。
2、 Types of GeoSpatial Queries(地理空间查询的类型)
MongoDB 中可以执行三种类型的地理空间查询:相交(intersection)、包含(within) 和 临近(nearness)。
下面定义了一个 GeoJSON 对象:
var eastVillage = {
"type": "Polygon",
"coordinates": [[
[-73.9732566, 40.7187272],
[-73.9724573, 40.7217745],
[-73.9717144, 40.7250025],
[-73.9714435, 40.7266002],
[-73.975735, 40.7284702],
[-73.9803565, 40.7304255],
[-73.9825505, 40.7313605],
[-73.9887732, 40.7339641],
[-73.9907554, 40.7348137],
[-73.9914581, 40.7317345],
[-73.9919248, 40.7311674],
[-73.9904979, 40.7305556],
[-73.9907017, 40.7298849],
[-73.9908171, 40.7297751],
[-73.9911416, 40.7286592],
[-73.9911943, 40.728492],
[-73.9914313, 40.7277405],
[-73.9914635, 40.7275759],
[-73.9916003, 40.7271124],
[-73.9915386, 40.727088],
[-73.991788, 40.7263908],
[-73.9920616, 40.7256489],
[-73.9923298, 40.7248907],
[-73.9925954, 40.7241427],
[-73.9863029, 40.7222237],
[-73.9787659, 40.719947],
[-73.9772317, 40.7193229],
[-73.9750886, 40.7188838],
[-73.9732566, 40.7187272]
]]
}
查找与查询区域相交的文档,可以使用 $geoIntersects:
db.openStreetMap.find({
"loc": {
"$geoIntersects": {
"$geometry": eastVillage
}
}
})
如果要查找完全位于某个区域内的内容(例如“East Village 区域内有哪些餐厅?”),可以使用 $geoWithin:
db.openStreetMap.find({
"loc": {
"$geoWithin": {
"$geometry": eastVillage
}
}
})
查询附近的位置可以使用 $near :
db.openStreetMap.find({
"loc": {
"$near": {
"$geometry": eastVillage
}
}
})
$near是唯一一个带有排序功能的地理空间操作符,查询的结果总是按照距离由近到远的顺序返回。
3、Using GeoSpatial Indexes(使用地理空间索引)
2dsphere 索引:
2dsphere 索引支持在地球类球体上计算几何图形的查询。要创建一个 2dsphere 索引,可以使用 db.collection.createIndex() 方法,并将字符串字面量 "2dsphere" 作为索引类型:
db.collection.createIndex({ <location field> : "2dsphere" })
其中,<location field> 是一个字段,它的值可以是一个 GeoJSON 对象或一个传统的坐标对。更多有关 2dsphere 索引的信息,请参见:2dsphere Indexes - Database Manual v8.0 - MongoDB Docs
2d 索引:
2d 索引支持在二维平面上计算几何图形的查询。尽管该索引可以支持 $nearSphere 查询(在球体上计算),但如果可能,应该使用 2dsphere 索引来进行球形查询。
要创建一个 2d 索引,可以使用 db.collection.createIndex() 方法,并将位置字段作为键,字符串字面量 "2d" 作为索引类型:
db.collection.createIndex({ <location field> : "2d" })
其中,<location field> 是一个字段,它的值是传统的坐标对。更多有关 2d 索引的信息,请参见:2d Indexes - Database Manual v8.0 - MongoDB Docs