
LocalBites 是一家初创公司,他的目标是提供关于附近餐厅的实时信息、优化配送路线,并生成有关用户偏好和餐厅人气的有价值分析。关键内容包括索引的实现、地理空间索引以及聚合管道的使用。
LocalBites 所处的是一个竞争激烈的市场,在这里,快速的响应时间和准确的基于位置的数据对于用户满意度至关重要。该应用程序的后端基于 MongoDB 构建。随着用户数量的增长,团队在高效处理大量数据集和复杂查询方面面临性能挑战。
为了提升查询性能,开发团队首先在常用查询字段上创建索引。例如,他们在 restaurants(餐厅)集合中的 cuisine(菜系)和 rating(评分)字段上创建了一个复合索引,从而优化了按菜系和评分筛选餐厅的查询,大大减少了查询执行时间。
一、Understanding the index and geospatial index(理解索引与地理空间索引)
1、Introduction to index(索引简介)
数据库中的索引类似于一本书的目录。与其翻阅整本书查找内容,不如直接查看有序的目录列表,这使得 MongoDB 能以数量级的速度提升查询效率。
如果一个查询不使用索引,就会执行 集合扫描(collection scan),意味着服务器要“从头看到尾”来找到结果。就像你在没有目录的书中查信息一样,从第一页开始,一页页翻阅。对于大集合而言,集合扫描效率非常低,应尽量避免。
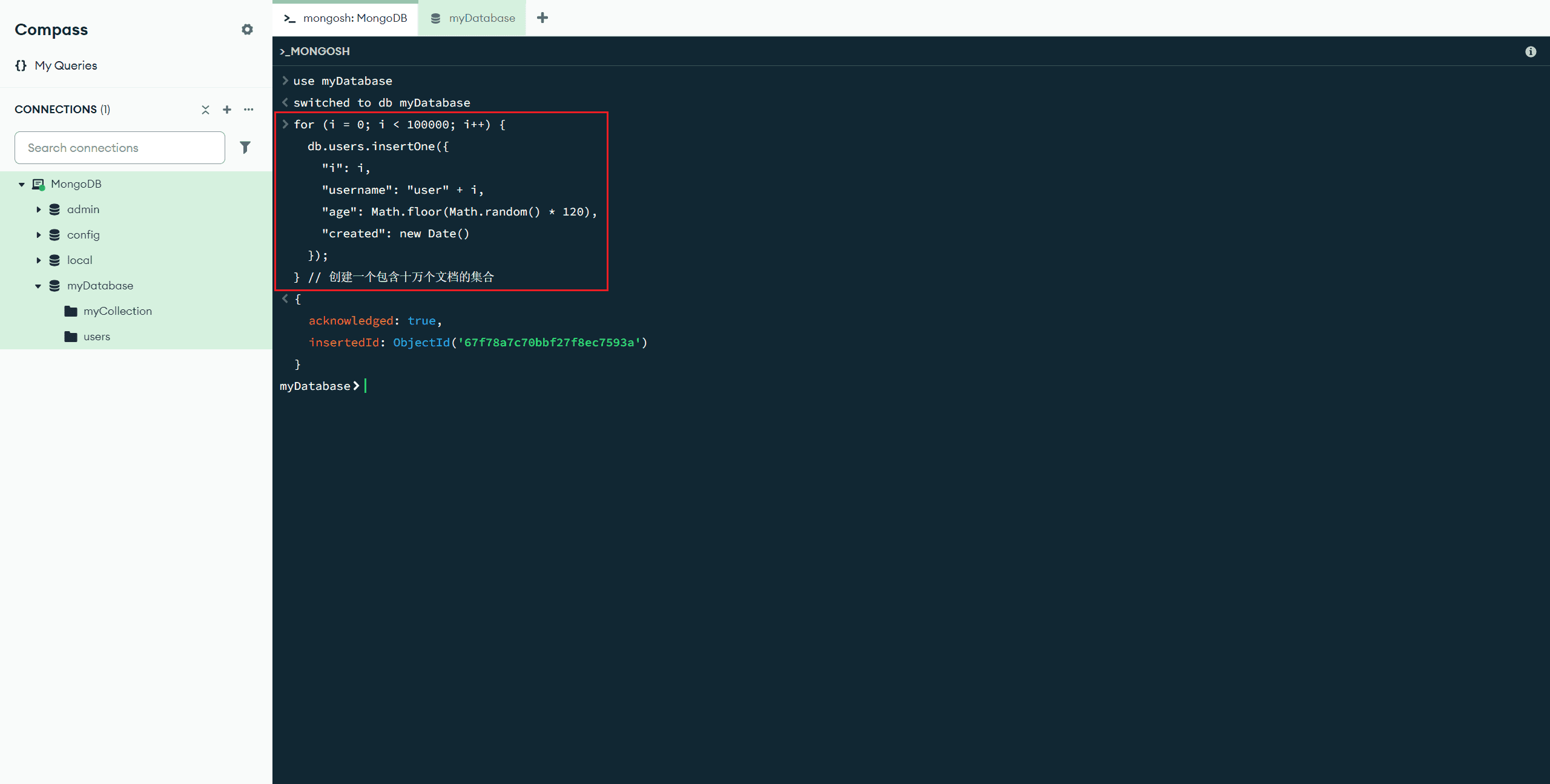
创建一个包含十万个文档的集合示例:
for (i = 0; i < 100000; i++) {
db.users.insertOne({
"i": i,
"username": "user" + i,
"age": Math.floor(Math.random() * 120),
"created": new Date()
});
} // 创建一个包含十万个文档的集合
当我们在集合中进行查询时,可以使用 explain 命令 来查看 MongoDB 执行查询的方式。cursor 的 explain 方法,它可以分析多种 CRUD 操作的执行过程。我们将使用 executionStats 模式,因为它能帮助我们理解使用索引前后的执行效率差异(了解就好)。
db.users.find({"username": "user101"}).explain("executionStats")
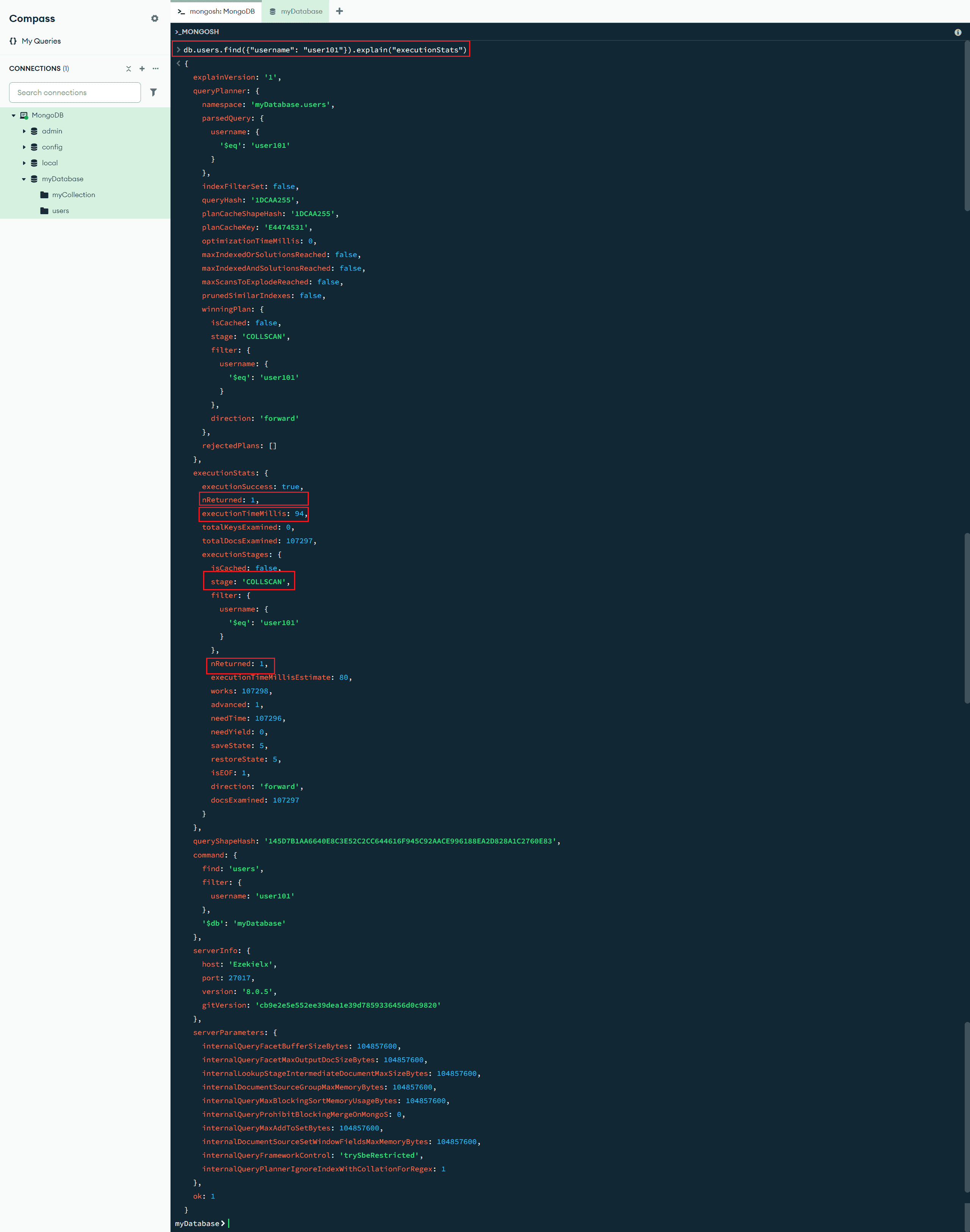
这条命令的返回结果中,关注以下几点:
"stage": "COLLSCAN"表示执行的是集合扫描。"totalDocsExamined": 100000表示 MongoDB 检查了所有的 10 万条文档。"executionTimeMillis": 94表示查询耗时约 94 毫秒。"nReturned": 1表示最终返回了 1 条匹配的记录。
也就是说,MongoDB 不知道 username 是唯一的,因此只能一条条扫描所有文档,效率很低。
为了提升查询效率,应该为你的应用中所有常用的查询模式创建索引。“查询模式”是指你应用中会向数据库提出的各种查询方式。在本例中,就是通过 username 查询用户,这是一个典型的查询模式。
在很多应用中,一个索引可以支持多个查询模式。关于如何为查询模式定制索引,会在后面说明。
一个未使用索引的查询称为集合扫描(Collection Scan),如果使用了索引,则称为索引扫描(Index Scan)。
2、 Creating an Index(创建索引)
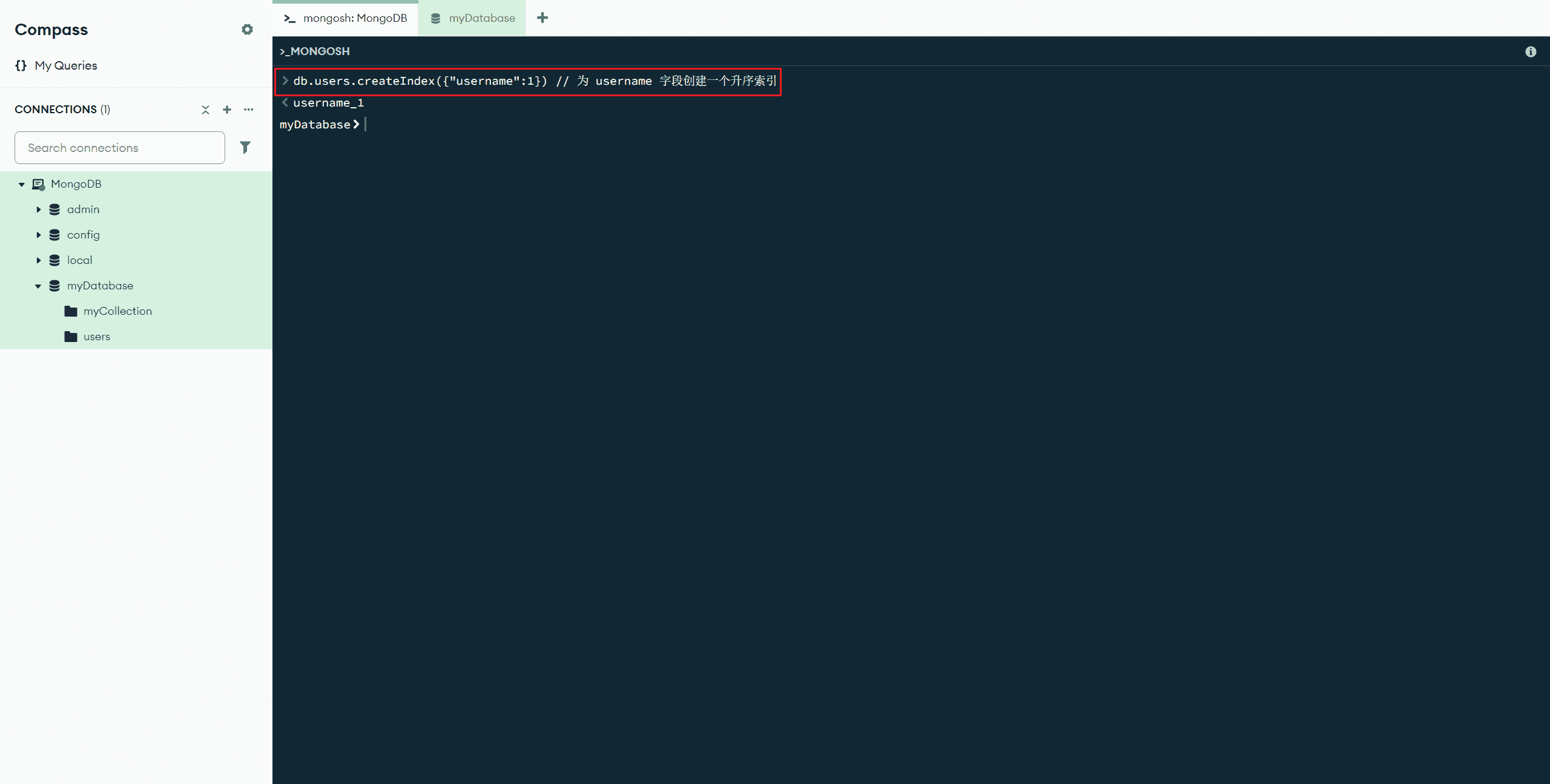
createIndex(<关键字>,<选项>,<行为>) :创建索引(更多信息详见官方文档:db.collection.createIndex() - Database Manual v8.0 - MongoDB Docs)
db.users.createIndex({"username":1}) // 为文档创建一个 username 字段的升序索引
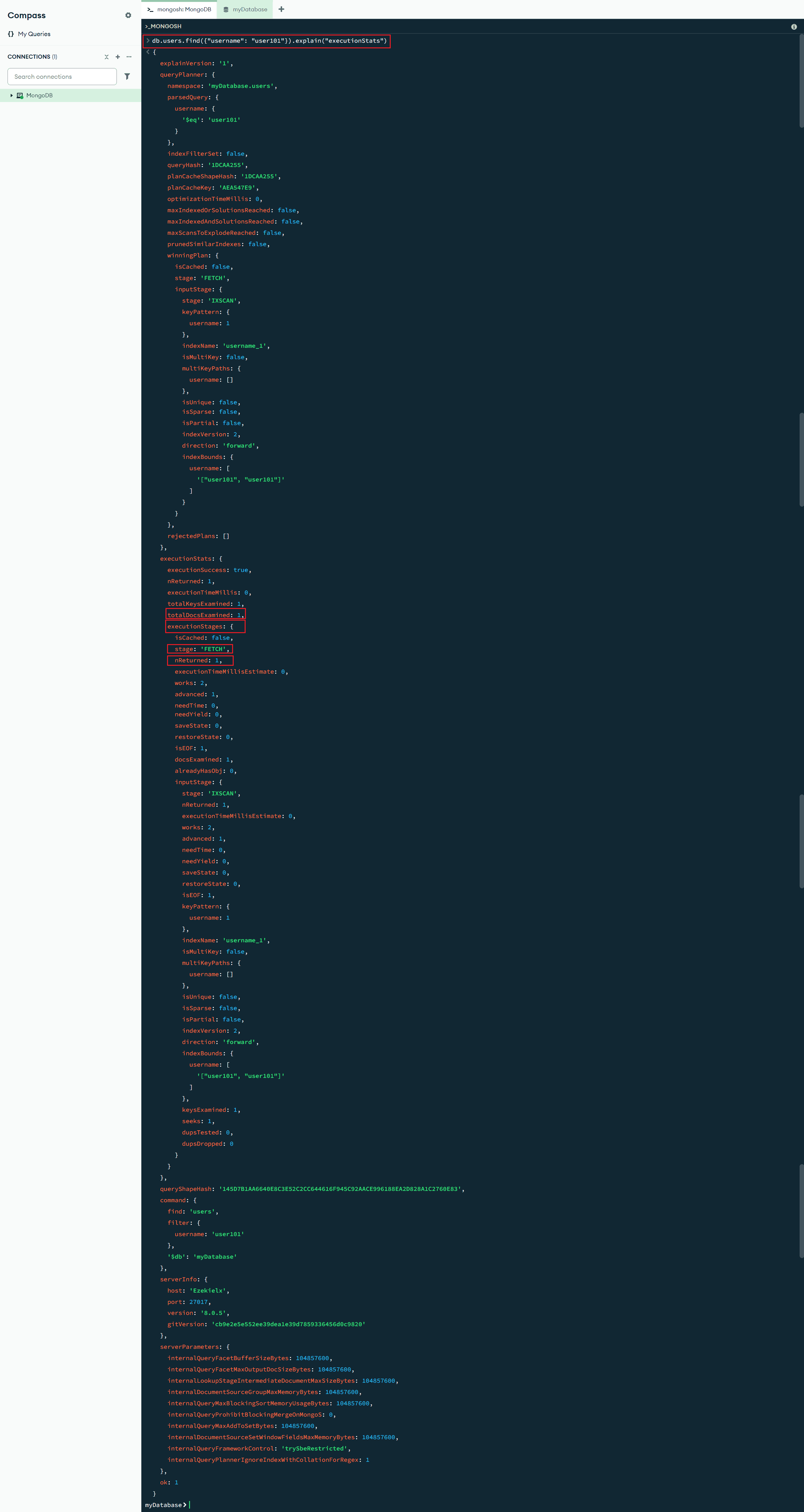
创建索引后,再次执行查询命令 db.users.find({"username": "user101"}).explain("executionStats"),这条命令的返回结果中,关注以下几点:
"stage": "FETCH"表示执行的是从索引中获取数据。"totalDocsExamined": 1表示 MongoDB 只检查了 1 条文档。executionTimeMillis": 0表示查询几乎是瞬间完成的。"nReturned": 1表示最终返回了 1 条匹配的记录。
3、The complex Index(复合索引)
索引的目的是尽可能让你的查询效率更高。 对于很多查询模式,通常需要基于两个或多个字段来建立索引。
例如,索引会将所有的值按照顺序排序,因此在根据被索引的字段进行排序时,速度会更快。 不过,只有当排序字段是索引的前缀时,索引才能对排序起作用。
假设索引是:{"age": 1, "username": 1, "created": -1}
能用索引排序的情况(前缀):
sort({"age": 1})✅sort({"age": 1, "username": 1})✅sort({"age": 1, "username": 1, "created": -1})✅因为这几个排序字段正好是索引最左边连续的一部分
不能用索引排序的情况(不是前缀):
sort({"username": 1})❌sort({"created": -1})❌sort({"username": 1, "created": -1})❌因为这些都跳过了最左边的
age,不连续,不是前缀,MongoDB就没法用索引来排。
db.users.createIndex({"age":1,"username":1}) // 为文档创建一个包含 age 和 username 字段复合索引
这个就是一个复合索引(compound index),当你的查询条件涉及多个字段或者多种排序方式时,复合索引就能发挥很大的作用。复合索引是指基于多个字段建立的索引。
4、GeoSpatial Index(地理索引)
MongoDB 有两种地理空间索引类型:2dsphere 和 2d。
- 2dsphere 索引:适用于基于 WGS84 基准的球面几何体,WGS84 模型把地球视为一个略扁的椭球体,因此 2dsphere 索引在计算距离时会考虑地球的形状,比 2d 索引计算两城市等位置间的距离更准确。(更多有关 2dsphere 索引的信息,请参见:2dsphere Indexes - Database Manual v8.0 - MongoDB Docs )
- 2d 索引:适用于存储在二维平面上的点。(更多有关 2d 索引的信息,请参见:2d Indexes - Database Manual v8.0 - MongoDB Docs)
2dsphere 索引允许你用 GeoJSON 格式来表示点、线和多边形的几何图形。
一个点(Point)用一个包含两个元素的数组表示,格式是 [经度, 纬度]。
例如,一个点的 GeoJSON 格式是:
"name": "New York City",
"loc": {
"type": "Point",
"coordinates": [50, 2]
}
一条线(LineString)由一组点坐标组成,格式如下:
"name": "Hudson River",
"loc": {
"type": "LineString",
"coordinates": [[0,1], [0,2], [1,2]]
}
一个多边形(Polygon)由一组坐标点组成,表示多边形的顶点顺序,格式如下:
"name": "New England",
"loc": {
"type": "Polygon",
"coordinates": [[0,1], [0,2], [1,2]]
}
注意,GeoJSON 中嵌套对象的字段名称是固定的,不能更改。
5、 Types of GeoSpatial Queries(地理空间查询的类型)
MongoDB 中可以执行三种类型的地理空间查询:相交(intersection)、包含(within) 和 临近(nearness)。
下面定义了一个 GeoJSON 对象:
var eastVillage = {
"type": "Polygon",
"coordinates": [[
[-73.9732566, 40.7187272],
[-73.9724573, 40.7217745],
[-73.9717144, 40.7250025],
[-73.9714435, 40.7266002],
[-73.975735, 40.7284702],
[-73.9803565, 40.7304255],
[-73.9825505, 40.7313605],
[-73.9887732, 40.7339641],
[-73.9907554, 40.7348137],
[-73.9914581, 40.7317345],
[-73.9919248, 40.7311674],
[-73.9904979, 40.7305556],
[-73.9907017, 40.7298849],
[-73.9908171, 40.7297751],
[-73.9911416, 40.7286592],
[-73.9911943, 40.728492],
[-73.9914313, 40.7277405],
[-73.9914635, 40.7275759],
[-73.9916003, 40.7271124],
[-73.9915386, 40.727088],
[-73.991788, 40.7263908],
[-73.9920616, 40.7256489],
[-73.9923298, 40.7248907],
[-73.9925954, 40.7241427],
[-73.9863029, 40.7222237],
[-73.9787659, 40.719947],
[-73.9772317, 40.7193229],
[-73.9750886, 40.7188838],
[-73.9732566, 40.7187272]
]]
}
$geometry:{type:"<GeoJSON对象>",coordinates:[<经纬度数组>]} :$geometry 操作符用于指定与下列地理空间查询操作符一起使用的 GeoJSON 几何图形: $geoWithin 、 $geoIntersects 、 $near 和 $nearSphere
查询地址坐标前需要先为存储 GeoJSON 对象的字段创建地理索引,如 db.openStreetMap.createIndex( { "loc" : "2dsphere" } )
查找与查询区域相交的文档,可以使用 $geoIntersects:
db.openStreetMap.find({
"loc": {
"$geoIntersects": {
"$geometry": eastVillage
}
}
})
如果要查找完全位于某个区域内的内容(例如“East Village 区域内有哪些餐厅?”),可以使用 $geoWithin:
db.openStreetMap.find({
"loc": {
"$geoWithin": {
"$geometry": eastVillage
}
}
})
查询附近的位置可以使用 $near :
db.openStreetMap.find({
"loc": {
"$near": {
"$geometry": eastVillage
}
}
})
$near是唯一一个带有排序功能的地理空间操作符,查询的结果总是按照距离由近到远的顺序返回。
6、Using GeoSpatial Indexes(使用地理空间索引)
2dsphere 索引:
2dsphere 索引支持在地球类球体上计算几何图形的查询。要创建一个 2dsphere 索引,可以使用 db.collection.createIndex() 方法,并将字符串字面量 "2dsphere" 作为索引类型:
db.collection.createIndex({ <location field> : "2dsphere" })
其中,<location field> 是一个字段,它的值可以是一个 GeoJSON 对象或一个传统的坐标对。
2d 索引:
2d 索引支持在二维平面上计算几何图形的查询。尽管该索引可以支持 $nearSphere 查询(在球体上计算),但如果可能,应该使用 2dsphere 索引来进行球形查询。
要创建一个 2d 索引,可以使用 db.collection.createIndex() 方法,并将位置字段作为键,字符串字面量 "2d" 作为索引类型:
db.collection.createIndex({ <location field> : "2d" })
其中,<location field> 是一个字段,它的值是传统的坐标对。
7、Indexing for text search(文本检索索引)
建立文本索引(text index)。以下的 createIndex 调用将在 "title"(标题)和 "body"(正文)字段中建立基于词项的文本索引:
db.articles.createIndex({"title":"text","body":"text"})
使用 "$text" 查询操作符 可以在包含文本索引的集合上执行文本搜索。"$text" 会将搜索字符串按空格和大多数标点符号分词(tokenize),并对所有这些词项执行逻辑“或(OR)”运算。
例如,下面这个查询将找到所有包含词项 "impact"(撞击)、"crater"(陨石坑)或 "lunar"(月球)的文章。
注意,由于我们建立的索引是基于标题和正文中的词项,所以这个查询会匹配这些词项出现在任意字段(标题或正文)中的文档。
我们可以通过在查询中使用短语(phrase)来更准确地指定搜索内容。你可以通过双引号括住短语,来搜索精确短语。
例如,下面这个查询将查找所有包含短语 "impact crater"(撞击坑)的文档:
db.articles.find({$text: {$search: "\"impact crater\" lunar"}}, {title: 1}).limit(10)
MongoDB 会将这个查询解释为:"impact crater" AND "lunar"
即返回的文档需要同时包含短语 "impact crater" 和词项 "lunar"。
以下是可能的返回结果({title: 1} 表示只显示标题字段):
{ "_id" : "2621724", "title" : "Schjellerup (crater)" }
{ "_id" : "2622075", "title" : "Steno (lunar crater)" }
{ "_id" : "168118", "title" : "South –PoleAitken basin" }
{ "_id" : "1509118", "title" : "Jackson (crater)" }
{ "_id" : "10096822", "title" : "Victoria Island structure" }
{ "_id" : "968071", "title" : "Buldhana district" }
{ "_id" : "780422", "title" : "Puchezh−Katunki crater" }
{ "_id" : "28088964", "title" : "Svedberg (crater)" }
{ "_id" : "780628", "title" : "Zeleny Gai crater" }
{ "_id" : "926711", "title" : "Fracastorius (crater)" }
8、Time Series(时间序列)
时间序列数据是一系列按时间顺序记录的数据点,通过分析这些数据随时间的变化可以获得有价值的洞察。时间序列数据通常由以下几个部分组成:
- 时间字段(Time):数据点记录的时间。
- 元数据(Metadata)(有时也称为来源 source):是一个标识某一数据序列的标签或标记,通常不发生变化。元数据存储在
metaField字段中。注意:一旦创建时间序列文档,不能再添加新的metaField字段。 - 测量值(Measurements)(也称为指标 metrics 或数值 values):是按时间间隔追踪的实际数据点,通常是随时间变化的键值对。
创建和查询时间序列集合(Create and Query a Time Series Collection):
-
使用
db.createCollection()或create命令创建集合,例如:db.createCollection( "weather", { timeseries: { timeField: "timestamp", metaField: "metadata" } } ) -
设置
timeField和metaField:timeseries: { timeField: "timestamp", // 表示时间戳字段 metaField: "metadata" // 表示元数据字段 } -
设定时间间隔粒度(可选):
你可以使用以下两种方式中的任意一种定义每个数据桶(bucket)的时间跨度。
方式一:指定粒度 granularity(比如秒)
timeseries: { timeField: "timestamp", metaField: "metadata", granularity: "seconds" }方式二:手动定义数据桶的最大跨度和舍入时间(单位为秒)
timeseries: { timeField: "timestamp", metaField: "metadata", bucketMaxSpanSeconds: "300", // 每个数据桶最多跨度 300 秒 bucketRoundingSeconds: "300" // 每 300 秒舍入一次 }
列出数据库中的时间序列集合:
你可以列出数据库中的所有集合,并通过各种属性(例如集合类型)来进行过滤,从而仅获取时间序列类型的集合。
操作:
使用 listCollections 命令并添加筛选条件 type: "timeseries",如下所示:
db.runCommand({
listCollections: 1,
filter: { type: "timeseries" }
})
输出结果:
对于时间序列集合,输出将包含以下信息:
type: 'timeseries'options: 包含timeseries的相关配置项
示例输出:
{
cursor: {
id: Long("0"),
ns: 'test.$cmd.listCollections',
firstBatch: [
{
name: 'weather',
type: 'timeseries',
options: {
timeseries: {
timeField: 'timestamp',
metaField: 'metadata',
granularity: 'hours',
bucketMaxSpanSeconds: 2592000
}
},
info: { readOnly: false }
}
]
},
ok: 1
}