
一、Kafka Core Concepts(Kafka 核心概念)
Apache Kafka 的核心是一个基于 **分区(Partition)**和 **多副本(Replication)**的分布式消息引擎,由 Zookeeper 协调管理。
在 Kafka 中,每条消息也被称为一条 记录(Record) 或 事件(Event),不同类别的消息存储在不同的 主题(Topic) 中。
生产者(Producer) 和 消费者(Consumer) 分别是消息的发送端与接收端,而 消费者组(Consumer Group) 提供了一种机制,使多个消费者能够协同工作,从而提升系统的吞吐量和可用性。
以下将详细介绍 Kafka 的核心概念。
1、Kafka cluster composition(Kafka 集群组成)
Zookeeper:ZooKeeper 在 Kafka 集群中发挥着至关重要的作用,主要用于集群的协调与管理。例如,它负责维护 Kafka 集群的元数据信息,确保集群操作的可靠性与一致性,并为动态集群管理提供支持。
但值得注意的是,从 Kafka 2.8.0 版本开始,Kafka 引入了 KRaft 模式(Kafka Raft Metadata mode),这是一种全新的控制器选举与集群管理机制,不再依赖 ZooKeeper。随着 KRaft 模式的引入,Kafka 社区也正逐步减少对 ZooKeeper 的依赖。
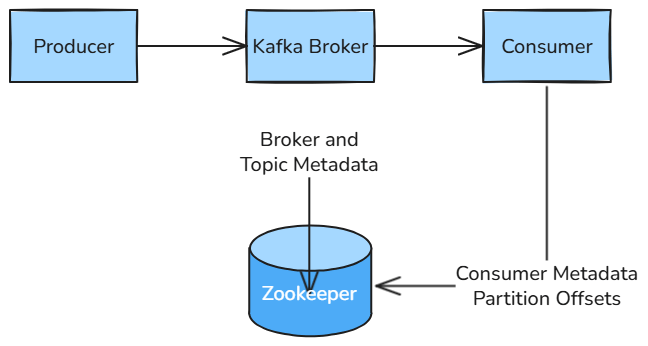
**服务器节点(Broker):**Kafka 集群由一个或多个服务器节点组成,每个独立的服务器节点称为 Broker(代理节点)。Broker 负责 数据的存储与管理,以及处理 生产者的数据写入(push) 和 消费者的数据读取(pull)。
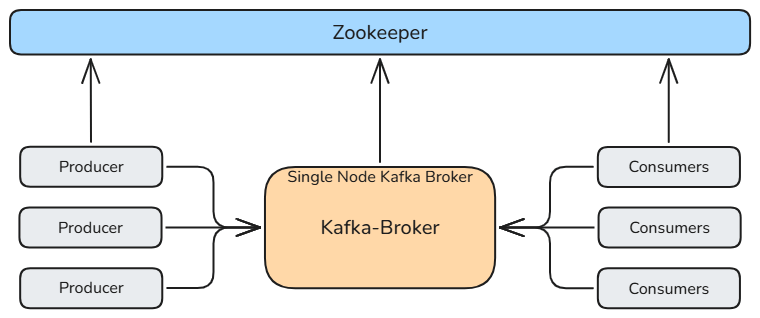
**分布式架构:**Kafka 通过多个 Broker 节点构建集群,每个 Broker 保存部分消息数据,从而实现了 高可用性、可扩展性和负载均衡 的分布式系统架构。
2、Kafka message storage mechanism(Kafka 消息存储机制)
Kafka 通过 Topic(主题) 对消息进行分类。一个 Topic 可以被划分为多个 Partition(分区),每个 Partition 可以存储在不同的Broker(代理节点) 上。换句话说,一个 Topic 可以跨越多个服务器进行存储。
Topic 分区的优势在于:它允许主题消息的总大小 突破单台服务器的最大文件限制。由于一个 Topic 可以拥有多个 Partition,并且这些 Partition 可以分布在不同的服务器上,当某个分区文件的大小超过服务器的最大文件容量时,可以动态地增加分区数量,从而实现对 无限数据量的处理与存储。

Message
Kafka 传输的最小数据单元称为 Message(消息),有时也被称为 Record(记录) 或 Event(事件)。
你可以将消息类比为数据库中的一行数据或一条记录。为了提高传输效率,Kafka 支持将多条消息 批量传输。每组消息构成一个 批次(Batch),批量传输可以显著减少网络开销。同样地,为了提高写入性能,Kafka 也会 批量写入消息。
与逐条发送消息相比,批处理可以显著降低网络消耗并提高吞吐量。通常,批处理会与 压缩格式(Compression) 结合使用,以实现更高效的数据传输与存储,但这需要一定的 CPU 计算资源。
Schemas
在 Kafka 中,Schemas 指的是消息的 结构定义(Schema Definition),它是一种用于描述消息结构并验证消息格式的规范。
在发送和接收消息时,需要将数据 序列化(Serialization) 为可传输的格式,并在接收时 反序列化(Deserialization) 为原始格式。
Schemas 定义了数据序列化与反序列化的规则。通过 Schemas,可以定义数据的 版本(Version),以保证新旧系统之间的兼容性。作为一种消息规范,Schemas 为开发者提供了 清晰的接口文档,有助于团队协作与系统维护。
在 Kafka 生态系统中,有许多工具与库支持 Schemas,例如 Confluent Schema Registry —— 一种用于 存储与管理 Schemas 的服务,可以与 Kafka 集群集成使用。
Schemas 支持 前向兼容(Forward Compatibility) 与 后向兼容(Backward Compatibility) 的数据演进机制,从而使数据结构能够 逐步更新和扩展,而不会影响现有的消息消费者。
Retention
Kafka 将消息存储在服务器所在的磁盘中,以支持 数据持久化(Persistence) 和 高吞吐读写(High Throughput I/O)。
Kafka 使用参数 log.retention.hours 来配置消息的保留时间。默认值为 168 小时(即一周),超过保留时间的消息将根据策略被自动删除或清理。
Topic
每条发布到 Kafka 集群的消息都属于某个 Topic(主题)。
在物理上,不同主题的消息是 分开存储 的;在逻辑上,尽管同一主题的消息可能分布在一个或多个 Broker 上,但用户只需 通过指定 Topic 名称 来生产或消费消息,而无需关心消息的具体存储位置。
Partition
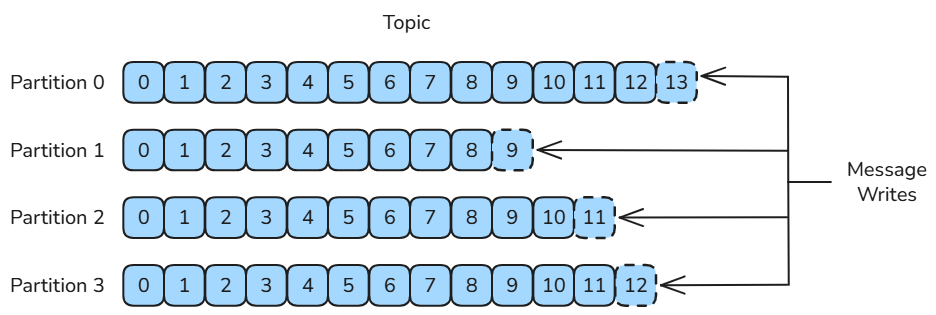
为了实现 水平扩展(Horizontal Scalability) 与 并行处理(Parallel Processing),Kafka 会将每个 Topic 物理划分为多个 Partition(分区),并分布到不同的服务器上。这使得 Kafka 能支持更大的数据量与更高的并发处理能力。
在创建 Topic 时,可以指定 Partition 的数量。Kafka 为每个 Topic 维护一个 分区日志(Partition Log),用于记录消息在各分区中的存储情况。消息会以 追加写入(Append-only) 的方式写入到分区末尾,并以 先进先出(FIFO) 的顺序读取。
由于一个 Topic 包含多个 Partition,Kafka 只能 保证分区内消息的有序性,而 无法保证整个 Topic 范围内的全局顺序。
当消息发送到 Broker 时,会根据 分区规则(Partitioning Rule) 分配到具体的分区中。如果分区策略设计合理,消息会 均匀分布 到不同分区,从而实现 负载均衡与水平扩展。若一个 Topic 的所有消息都存储在单一文件中,则该 Broker 的磁盘 I/O 将成为系统性能瓶颈,而 Partition 的存在正是为了解决这一问题。
Replication Factor
为了实现 高数据可用性(High Data Availability),Kafka 集群中可以将同一条消息的多个副本分配到不同的 Broker(代理节点) 上。
这种机制类似于 HDFS 的副本机制。当某个 Broker 宕机时,其他 Broker 可以接管其工作,从而确保服务的连续性。但在这种情况下,生产者(Producer) 和 消费者(Consumer) 需要重新连接到新的 Broker。
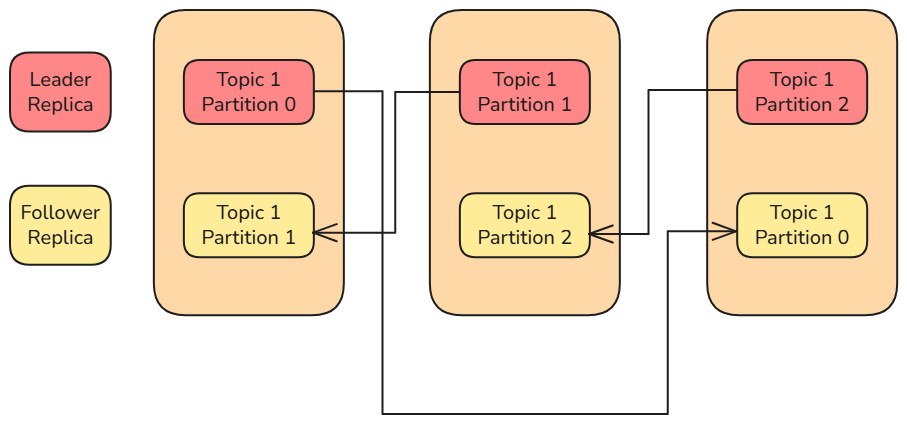
Kafka 中每个 分区(Partition) 的副本分为两种类型:
- Leader 副本(Leader Replica)
- Follower 副本(Follower Replica)
每个分区中 只有一个 Leader 副本,其余的都是 Follower 副本。所有生产者和消费者的 读写请求都由 Leader 副本处理。Follower 副本不直接处理客户端请求,它的唯一任务是 从 Leader 副本中复制数据,以保持与 Leader 副本的数据和状态一致。
当 Leader 副本所在的 Broker 发生故障 时,系统会从剩余的 Follower 副本中 选举出一个新的 Leader 副本,以确保服务持续可用。
在创建 Topic(主题) 时,可以同时指定 副本因子(Replication Factor) 的数量,从而控制每个分区在集群中保存的副本数量,以实现 更高的容错性与可靠性。
3、Kafka client(Kafka 客户端)
Kafka Producer Client(Kafka 生产者客户端)
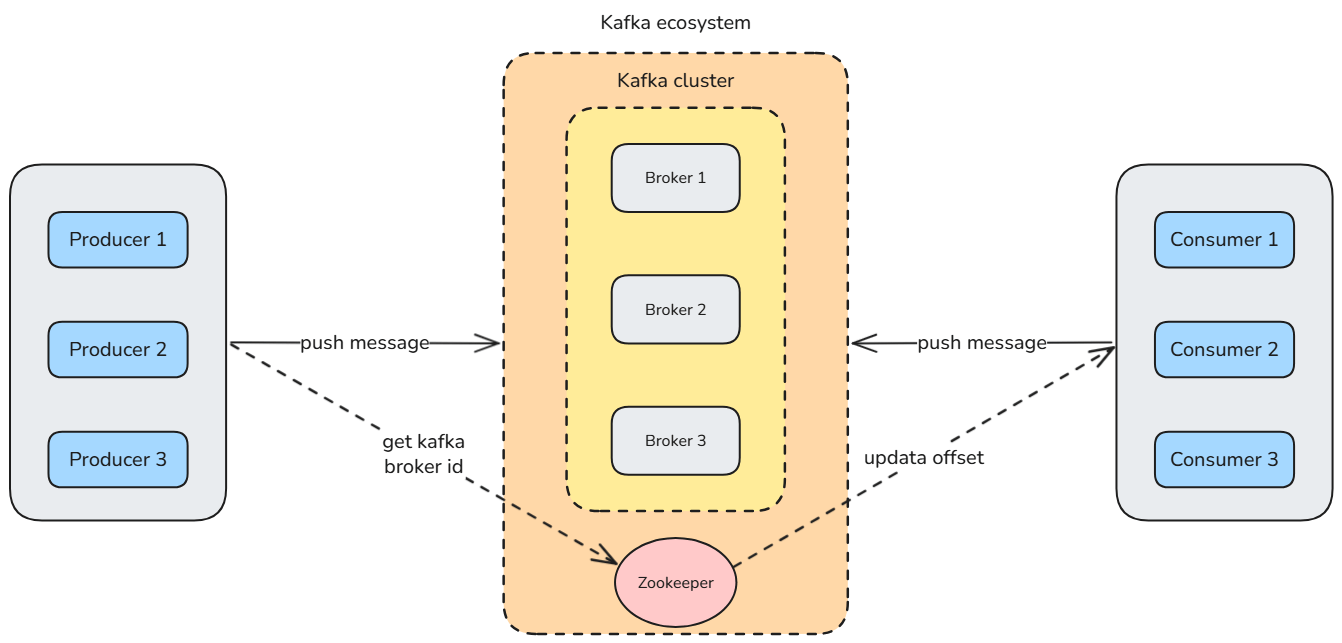
Producer(生产者) 是一种客户端应用程序,用于向 Kafka 集群发送消息。
生产者负责 创建消息 并将其 发布到 Kafka 的特定 Topic(主题) 中。
生产者可以指定消息的 Key(键) 和 Value(值)。
默认情况下,生产者会将消息 均匀分布 到某个 Topic 的所有 Partition(分区) 中。但在某些情况下,生产者也可以直接将消息写入指定的分区。例如,可以使用 消息键的哈希值(Hash) 来确定消息在分区中的存储位置,而 Value 则是实际传输的数据载荷。
Kafka 生产者支持 批量发送消息(Batch Sending) 以提高网络传输效率,并可配置不同的 序列化方法(Serialization Methods) 来处理键和值的数据格式。
Kafka Consumer Client(Kafka 消费者客户端)
Consumer(消费者) 是一种客户端应用程序,用于从 Kafka 集群中 读取消息。
消费者可以 订阅(Subscribe) 一个或多个 Topic,并通过 轮询(Polling) 的方式从这些 Topic 中拉取消息。在读取消息时,消费者需要指定要读取的 Topic。
通常情况下,消费者会订阅一个或多个 Topic,并按照消息生成的顺序读取数据。
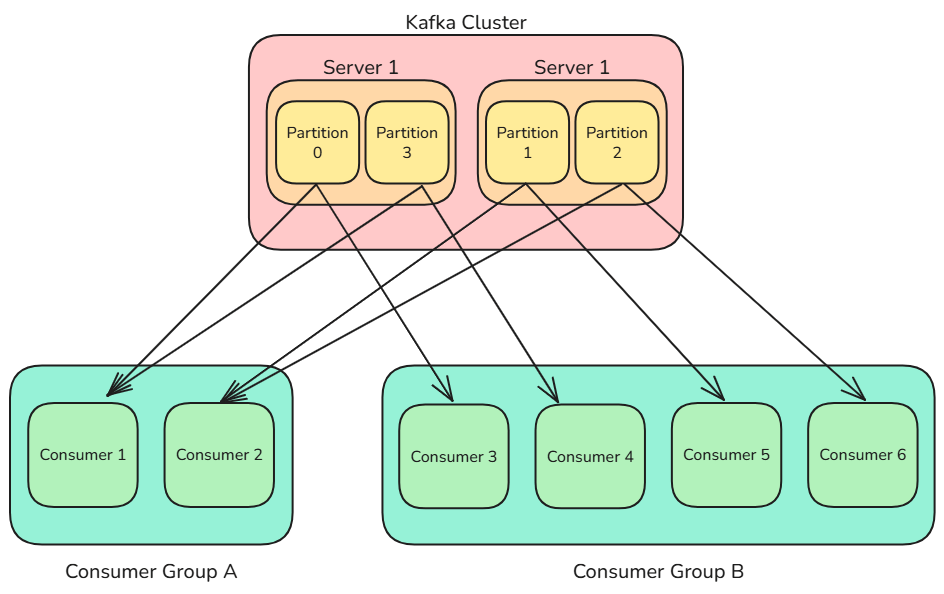
Consumer Group(消费者组)
消费者组 是 Kafka 的核心概念之一。
每个消费者都属于某个特定的消费者组(可以通过 Group Name(组名) 来指定)。如果未显式指定组名,Kafka 会自动为该消费者分配一个唯一的组名。从逻辑上讲,一个消费者组可以被看作一个整体的消费者。
消费者组的主要优势在于 负载均衡(Load Balancing) 与 容错(Fault Tolerance)。同一组内的所有消费者共同分担订阅 Topic 的消息消费任务;如果组内某个消费者实例发生故障,其他实例会继续接管其消息消费。
Kafka 规定:
- 同一消费者组内的多个消费者 不能同时消费同一分区 的消息;
- 但不同消费者组之间 可以同时消费同一分区 的消息。
换句话说,分区(Partition)与消费者(Consumer)之间的对应关系 在同一消费者组内是 多对一,而不是 一对多。
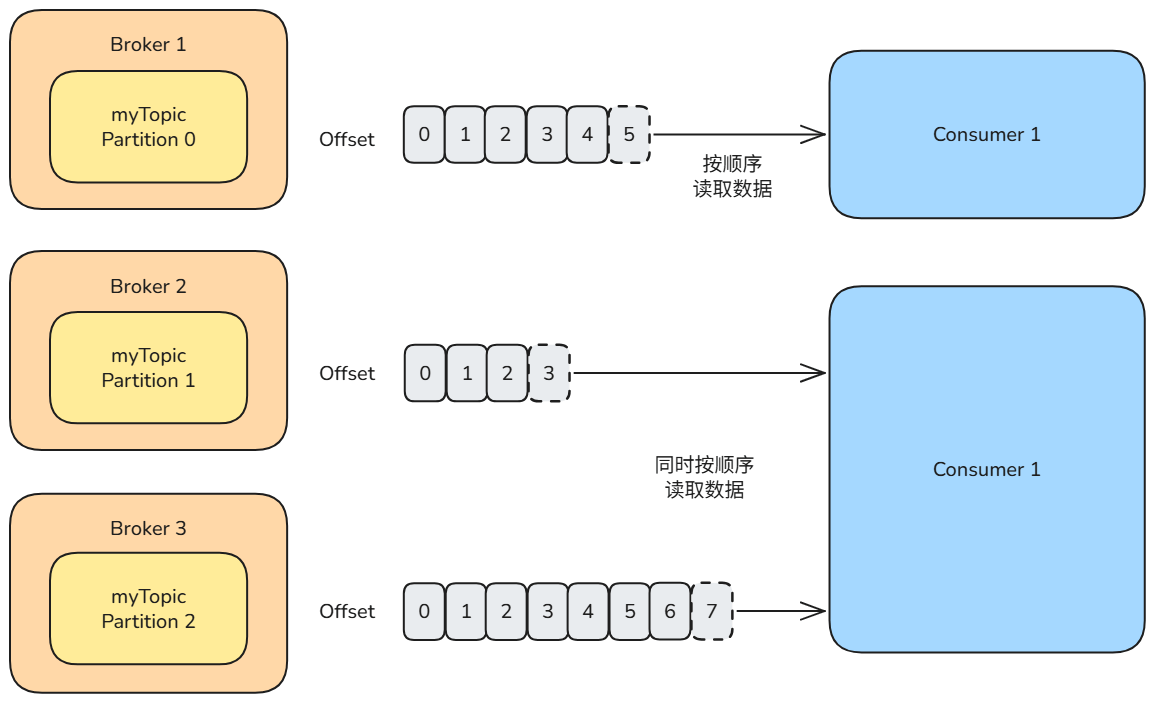
Offset(位移)
每条消息在分区中都会被分配一个唯一的 Offset(偏移量),这是一个 递增的整数值,用于唯一标识消息在分区中的位置。
Offset 是 Kafka 用于 跟踪消费者读取进度 的机制。每个消费者在分区中都有自己的 Offset,用于记录当前读取到的位置。当消费者读取一条消息后,Offset 会线性递增。
消费者可以将 Offset 提交(Commit) 到 Kafka 中,以便在发生故障后,能够从上次提交的位置继续读取消息。当然,消费者也可以选择手动重置 Offset,以便 重新消费历史消息。
此外,消费者还可以设置一次从分区中 最多返回的消息数量,以避免一次性读取过多数据导致客户端内存压力过大。
在早期版本的 Kafka(0.8.x 及更早)中,Offset 存储在 ZooKeeper 中。由于 ZooKeeper 不适合频繁更新操作,这种方式已被弃用。现在,Offset 被存储在 Kafka 内置的 主题(Topic) 中,以提高性能并简化管理。
Rebalance Mechanism of Partition(分区重平衡机制)
当消费者组的成员发生变化(例如新增消费者或某个实例故障)时,Kafka 会触发 分区重平衡(Rebalance) 过程,重新将分区分配给组内所有消费者实例。
Rebalance 的作用是:
- 确保消费者之间的负载均衡;
- 使消费者组能动态适应消费者数量的变化。
为了便于理解,可以将不同的 Topic(主题) 比作不同类型的 高速公路,Partition(分区) 就像高速公路的 车道(车道数),Message(消息) 就是行驶在车道上的 车辆,Consumer(消费者) 则好比 收费站。
由于单条车道的流量有限,当消息流量(即车辆数量)过大时,可以 增加车道数(分区数);反之,为节省资源,也可以减少车道。
同时,开放更多收费站(消费者实例)也能让车辆(消息)更快通过系统。
二、Kafka Architecture(Kafka 架构)
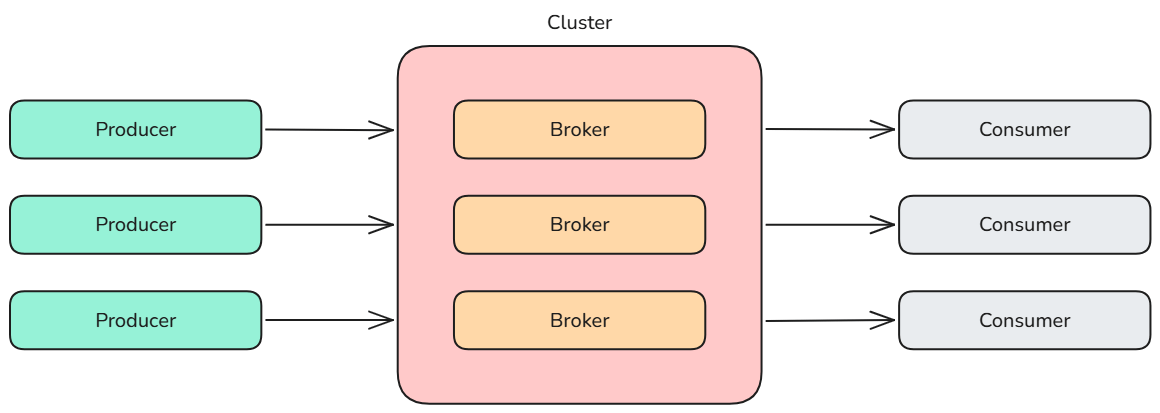
一个典型的 Kafka 集群 包括多个 生产者(Producer)(数据可以是网页内容或 Web 前端生成的服务器日志)、多个 代理节点(Broker)、多个 消费者(Consumer)(如 Hadoop 集群、实时监控程序、数据仓库或其他服务),以及一个 ZooKeeper 集群。
ZooKeeper 用于 管理和协调各个 Broker。当新的 Broker 加入 Kafka 系统或某个 Broker 出现故障时,ZooKeeper 会通知生产者和消费者,使它们与其他 Broker 重新建立协调关系。生产者采用 推送模式(Push) 将消息发送到 Broker,而消费者采用 拉取模式(Pull) 从 Broker 订阅并消费消息。
传统的消息处理有两种模式:队列模式(Queue Mode) 和 发布/订阅模式(Publish-Subscribe Mode)。
- 队列模式下,多个消费者可以从同一服务器读取消息,但 每条消息只能被其中一个消费者读取;
- 发布/订阅模式下,消息会 广播给所有消费者,每个消费者都能接收到同一条消息。
Kafka 的消费者组模式(Consumer Group Mode) 结合了两者的优点:同一组内的消费者共享消息负载,每条消息只被一个消费者处理;而不同的消费者组可以同时消费相同的主题,实现类似发布/订阅的效果。
发布–订阅模型(Publish–Subscribe,简称 Pub-Sub)是一种消息通信模式,在这种模式中,消息的发送者(发布者)与接收者(订阅者)之间不存在直接耦合关系。发布者并不关心谁会接收消息,而订阅者也不需要知道消息是从哪里发来的。
在这种模型中:
- 发布者(Producer) 将消息发送到某个 主题(Topic)
- 订阅者(Consumer) 通过订阅这些主题来接收自己感兴趣的消息
- 对于不关心的消息,订阅者会自动忽略
这样做使得消息的发送和接收过程完全解耦,从而提升系统的可扩展性。新的订阅者可以随时加入并订阅某个主题,而不会对发布者或已有订阅者造成影响。
发布–订阅模型通常支持 异步消息通信:
- 发布者发送消息后无需等待订阅者的回应即可继续执行
- 订阅者也可以在准备好时再处理接收到的消息
这种模型让系统更加灵活,特别适合分布式、大规模、高并发的应用场景。