
一、Log collection and data transmission in big data ecology(大数据生态中的日志采集与数据传输)
随着大数据技术的快速发展,一个完整而多样化的大数据生态系统已经形成。这个生态系统通常可描述为由数据采集层、数据计算层和数据应用层组成的三层架构。每一层在支撑整个大数据系统中都发挥着不同的作用。
数据采集层(Data Collection Layer)
目前,许多公司的业务平台每天都会产生海量的日志数据。日志采集系统的任务就是将这些日志数据收集起来,供离线和在线分析系统使用。
数据采集层是整个大数据生态系统的起点,主要负责从各种数据源中收集数据。除了日志数据外,大数据系统的常见数据源还包括业务数据库中的结构化数据,以及视频、图片等非结构化数据。
数据计算层(Data Computing Layer)
仅仅将大数据收集到存储系统中是不够的,只有通过整合和计算数据中潜在的价值,才能真正发挥其作用。
数据计算层可分为离线数据计算和实时数据计算两种。
- 离线数据计算主要指传统的数据仓库概念,可以按小时、天、周或月对数据进行汇总。通常采用 T+1 模式,即每天早上处理前一天的数据。
- 然而,随着业务的发展,对实时计算的需求不断增长,实时计算开始占据越来越大的比重。其实时应用场景不断扩展,例如:
- 电商交易数据的实时更新;
- 设备运行状态的实时监控;
- 活跃用户数据分布的动态变化。
在日常生活中,我们常见的应用包括:
- 地图与定位服务:可实时分析道路拥堵情况;
- 天气应用:可实时预测天气趋势。
面对庞大的数据处理需求,YARN 等资源管理系统发挥着关键作用。它通过共享集群资源来提高资源利用率、降低运维成本。
在大数据计算领域中,任务之间往往存在依赖关系,一个计算任务的执行可能依赖于另一个任务的结果。因此,使用**任务调度系统(Task Scheduling System)**来合理管理这些依赖关系并实现任务的自动化执行就显得尤为重要。
然而,所有这些计算的前提是建立在标准化、合理化的数据管理基础之上。构建标准化、统一的数据仓库系统,是解决数据冗余和重复计算问题的关键,有助于最大化数据价值。
数据应用层(Data Application Layer)
当数据经过整合与计算后,就需要将其提供给用户使用。针对不同的数据平台及其具体需求,会有有针对性的数据应用层设计与规划。
数据的最终计算结果可以存储在多种数据库中,如 MySQL、HBase、Redis、Elasticsearch 等,方便用户访问这些结果数据。
由于用户群体多样、访问量不同、所面临的业务挑战也各异,因此,确保数据服务接口的高可用性、满足不同用户复杂的数据业务需求,是数据应用层必须重点考虑的问题。
二、Common log collection and data transmission technologies and industry cases(常见的日志采集与数据传输技术及行业案例)
随着大数据的重要性不断提升,构建一个合理的大数据采集系统显得尤为关键。
在大数据采集过程中,面临的挑战越来越多,主要包括:数据源的多样性、数据量巨大且变化迅速、如何确保数据的可靠性、避免数据重复以及保证数据质量。
为应对这些挑战,日志采集系统必须具备高可用性、高可靠性以及良好的可扩展性。
1、Common log collection and data transmission technology(常见的日志采集与数据传输技术)
常见的日志采集与数据传输技术
目前,主流的数据传输层工具包括 Flume、Logstash、Sqoop、DataX、Canal、Maxwell 等。
通过这些工具的协同工作,可以满足不同数据源的采集需求。
-
Apache Flume
Flume 是一个分布式、可靠且高可用的服务,用于高效地收集、聚合和传输大量日志数据。
它主要用于将来自各种来源(如日志文件、网络套接字等)的日志数据传输到集中式的数据存储系统中,如 Hadoop。
Flume 通常与 Elasticsearch 和 Kibana 结合使用,构建强大的日志分析与可视化平台——ELK Stack。
-
Apache Sqoop
Sqoop 是一种用于在关系型数据库(如 MySQL、PostgreSQL)与 Hadoop 之间传输大量数据的工具。它支持:
- 将关系型数据库中的数据导入到 Hadoop 的 HDFS 或 Hive 中;
- 或将 Hadoop 中的数据导出到关系型数据库中。
Sqoop 适用于批量数据导入导出场景,常用于数据仓库的离线数据同步。
-
DataX
DataX 是阿里巴巴开源的数据同步工具,用于在不同存储系统之间进行数据迁移。它支持在 关系型数据库(MySQL、Oracle 等)、Hadoop、HBase 等系统之间进行数据传输。特点包括:
支持全量抽取与增量抽取;具有良好的可扩展性与插件化架构;可灵活适配多种数据源与目标端。
-
Canal
Canal 是基于 MySQL Binlog 的增量数据订阅与消费组件,主要用于实现数据的实时增量同步。它可以实时捕获 MySQL 数据变更(如插入、更新、删除)并同步到其他系统中,例如 Elasticsearch、HBase 等。Canal 通常用于构建实时数据总线或数据库变更监听系统(CDC, Change Data Capture)。
-
Maxwell
Maxwell 是一个将 MySQL Binlog 数据实时同步到 Kafka 的工具。它可以实时捕获 MySQL 的变更日志,并以多种数据格式(如 JSON)推送到不同的 Kafka Topic。
Maxwell 简单轻量,部署方便,常用于构建实时数据流管道。
消息队列中间件
为了缓解数据存储系统的压力,日志采集系统通常会使用**消息队列中间件(Message Queue)**作为数据缓冲层。
常见的消息队列包括 Kafka、RabbitMQ、ActiveMQ、RocketMQ 等。
-
Apache Kafka
Kafka 是一个高性能分布式流处理平台,以其高吞吐量、低延迟著称。
它非常适合大规模数据流处理和实时分析场景,如日志聚合、实时监控、用户行为分析等。
-
RabbitMQ
RabbitMQ 是一个灵活且可靠的消息代理系统,支持多种消息协议和复杂的路由机制。
它适用于需要强大消息路由与任务调度能力的分布式系统,常用于业务系统间异步通信。 -
Apache ActiveMQ
ActiveMQ 是一个完全支持 JMS(Java Message Service)规范的消息服务器,提供企业级的消息功能,包括事务处理与消息持久化。
它适合那些对消息投递可靠性要求较高的企业应用。
-
Apache RocketMQ
RocketMQ 是一个高性能、高吞吐量的分布式消息队列系统,支持自动负载均衡和消息持久化。
它特别适用于金融支付、电商交易等需要高并发和高可靠性的场景。
2、Introduction to relevant industry cases(相关行业案例介绍)
大数据的浪潮席卷了社会的每一个角落,从金融到汽车,从互联网到电信,再到物流、影视娱乐等行业,其影响无处不在。
金融行业:
在金融领域,大数据的应用已经深入到用户管理、风险控制、产品设计、决策支持等多个方面。通过大数据分析,金融机构可以向客户推荐合适的金融产品,并预测未来金融产品的流行趋势。金融行业的数据多为结构化数据,通常存储在传统的关系型数据库中。通过数据挖掘,这些数据能够揭示隐藏在交易数据中的商业价值。
汽车行业:
大数据在汽车行业中释放了巨大的价值,受到越来越多的关注。利用大数据分析消费者行为,可以帮助企业确定汽车营销的方向。同时,通过对用户保养行为的分析,有助于评估二手车的价值。智能导航系统借助大数据为智能交通提供了更多可能性。未来,融合大数据与物联网技术的无人驾驶汽车将走进我们的日常生活。
互联网行业:
大数据在互联网行业的应用已经渗透到各个方面。几乎所有客户行为都会在互联网平台上留下痕迹,使互联网企业能够轻松获取大量用户行为信息。通过对这些行为的分析,企业可以制定更有针对性的服务策略。以阿里巴巴等企业为代表,不仅强化了个性化推荐,还开发了面向消费者的大数据应用,并尝试利用大数据进行智能客服。此外,互联网行业还开始推动数据的商业化,挖掘新的商业价值。
电信行业:
电信行业的大数据应用仍处于探索阶段。国内运营商正利用大数据优化网络设施建设、网络运营管理以及精准营销。
物流行业:
物流行业通过挖掘海量的物流数据,发现新的价值层次。具体而言,大数据可以帮助优化车辆与货物的匹配、库存预测以及供应链协同管理,从而提高物流效率并降低物流成本。
影视娱乐行业:
在影视娱乐领域,大数据在精准营销中发挥着重要作用。通过挖掘不同类型影片背后的受众,企业可以更准确地锁定目标观众。大数据还可以帮助内容策划,甚至在演员选择上提供数据支持。
大数据的价值远不止于此。它对各行各业的渗透促进了社会生产与生活的发展,并将在未来产生深远的影响。
三、Introduction and application scenarios of Apache Kafka, Flume and Sqoop(Apache Kafka、Flume 和 Sqoop 的简介及应用场景)
大数据日志采集与数据传输工具的选择取决于具体的应用需求、性能要求、成本预算以及与其他系统的集成能力。
本系列选取了大数据应用中三种传统且常用的技术进行讲解,即 Kafka、Flume 和 Sqoop。
1、Kafka Introduction and Application Scenarios(Kafka 简介与应用场景)
Kafka 于 2010 年底首次在 GitHub 上以开源项目的形式发布。随着其在开源社区中逐渐受到关注,该项目于 2011 年 7 月被正式提交给 Apache 软件基金会,并成功成为其孵化项目。2012 年 10 月,Kafka 顺利毕业于孵化器,开始独立发展。
自那以后,Kafka 不仅在 LinkedIn 内部得到应用,还吸引了众多贡献者和提交者,形成了一个强大的社区。如今,Kafka 已成为全球众多大型数据管道系统的核心组件。
2014 年秋,Jay Kreps 离开 LinkedIn,创立了 Confluent 公司,专注于为 Apache Kafka 提供专业的开发、企业级支持及培训服务。在 Confluent 及其他开源社区公司的共同努力下,Kafka 的发展与维护得到了持续推进,进一步巩固了其在大数据管道领域的领先地位。
Jay Kreps 对 “Kafka” 这一名称的看法是:由于 Kafka 是一个针对写入操作进行优化的系统,用一位作家的名字来命名它具有特殊的意义。
他在大学期间修过许多文学课程,并且非常喜欢作家 弗朗茨·卡夫卡(Franz Kafka)。此外,他还认为这个名字对于一个开源项目来说听起来很酷。
在深入了解 Apache Kafka 之前,首先需要理解发布/订阅(Publish/Subscribe,简称 Pub/Sub)消息机制的概念及其重要性。
发布/订阅是一种消息传递模式,其中数据(或消息)的发送者(即发布者)并不会直接将消息发送给特定的接收者。相反,发布者会根据一定的规则对消息进行分类,而接收者(即订阅者)则根据自身的兴趣订阅相应类别的消息。
在这种模式下,Pub/Sub 系统通常包含一个或多个 Broker(代理服务器),它们作为消息发布与分发的中心节点。发布者将消息发送到 Broker,由 Broker 根据订阅者的订阅偏好,将消息分发给相应的订阅者。
这种机制不仅提高了消息传递的灵活性,还允许消息接收方根据自身需求选择接收的消息类型。
如下图所示:
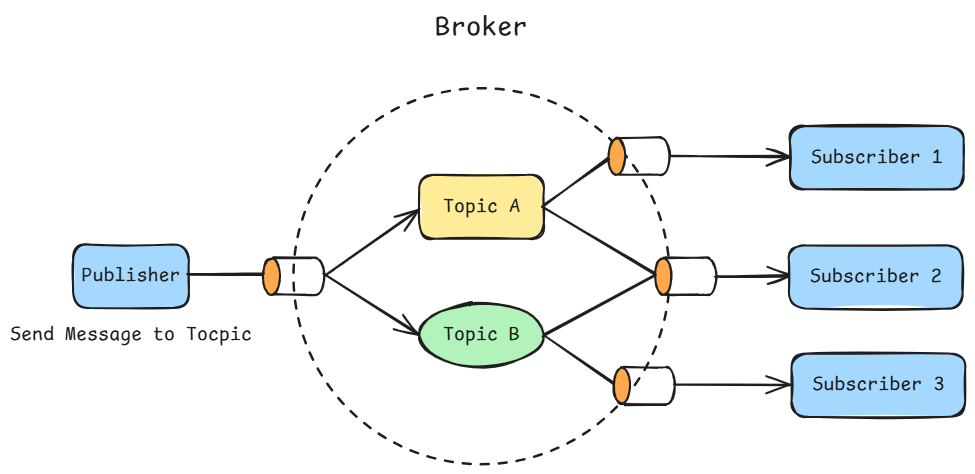
将这些数据实时传输到目标系统。Kafka 主要由 Scala 和 Java 编写,被广泛应用于大数据的实时事件流处理。
Apache Kafka 提供了一种强大的解决方案,能够处理大规模实时数据流,并快速地将信息分发给多个用户。它不仅适用于实时数据处理,也能应对批量数据处理的挑战。
作为一个开源的分布式系统,Kafka 通过分区(Partition)和副本(Replication)机制,确保了数据的高可用性与可靠性。基于提交日志(Commit Log)架构,它为发布/订阅消息系统提供了实时解决方案。此外,Kafka 还支持与 Hadoop 系统的集成,从而在 Hadoop 环境中实现高效的并行数据加载与处理。
Apache Kafka 是一个理想的分布式事件流处理平台,用于构建高吞吐量、低延迟的消息系统,特别适合需要处理大量实时数据的应用场景。
以下是 Kafka 的主要特性:
-
统一的数据流(Unified Data Stream)
Kafka 允许在多个微服务之间实现数据流的统一视图,这对于需要将来自不同数据源的数据汇聚成单一数据流的应用非常有利。
这种机制简化了数据处理管道,降低了同时处理多条数据通道的复杂性。
-
支持多消费者(Support Multiple Consumers)
Kafka 专为多消费者设计,允许多个消费者独立读取消息流而互不干扰。
与传统消息队列系统不同,Kafka 允许消息被多个消费者独立处理,而不是在被单个客户端消费后即失效。
消费者可以作为**消费者组(Consumer Group)**的一部分,共享消息流,并确保整个消费者组对每条消息仅处理一次。
-
基于磁盘的数据保留策略(Disk-Based Data Retention Policy)
Kafka 会将消息持久化存储在磁盘上,并根据可配置的保留规则进行管理。
这种策略使消费者无需实时工作,消息会在磁盘上保留,直到被消费者处理完毕。
这为消费者提供了极大的灵活性,即使处理速度较慢或在高峰期间,也不会丢失数据。
此外,消费者在维护或临时离线期间,也能依靠 Kafka 保留的消息继续处理数据,而无需担心数据丢失。
-
可扩展性(Scalability)
Kafka 的设计使其在处理海量数据时具有极高的可扩展性。
用户可以从单个代理(Broker)开始,逐步扩展为由多个代理组成的集群,以满足不断增长的数据需求。
集群的扩展可以在不中断服务的情况下进行,从而保证系统的高可用性。
对于需要更高容错性的集群,可以通过配置更高的副本因子来实现。
-
高性能(High Performance)
综合以上特性,Apache Kafka 在高负载环境下表现出色。
无论是生产者、消费者还是代理服务器,Kafka 都可以扩展以处理庞大的消息流,并在从消息生成到消费者可用的整个过程中保持亚秒级延迟。
这使得 Kafka 成为对高性能与高可靠性有严格要求的消息系统的理想选择。
Apache Kafka 拥有广泛的应用场景,其主要应用领域如下:
-
构建消息系统(Build a Message System)
Kafka 可以作为一个高效的消息代理系统,用于实现数据处理与数据生产者之间的解耦。
与传统的消息中间件相比,Kafka 提供了更高的吞吐量、内置的分区机制、数据副本以及容错能力,因此成为构建复杂消息系统的首选工具。
-
网站用户行为追踪(Website User Behavior Tracking)
网站上的用户活动,如浏览页面、搜索或其他操作,都可以实时发布到相应的消息主题(Topic)中。
这样,不同需求的场景可以通过订阅这些主题来实现数据的实时处理、监控,或将数据导入 Hadoop 进行批量处理,用于构建报表分析的离线数据仓库。
网站用户行为追踪是现代网站运营中非常重要的一部分。
当用户浏览网页时,服务器上会生成相应的行为日志。
网站通常会频繁地对用户行为进行跟踪和分析,以此来优化网站性能、提升用户体验、增强营销效果、支持数据驱动的决策制定,以及实现安全监控等多种目的。
-
指标监控(Indicator Monitoring)
Kafka 在监控系统中也发挥着重要作用。多个应用程序可以定期生成并发布同类指标数据到 Kafka 的主题中。
这些指标不仅可用于实时监控与告警系统,还可以提供给 Hadoop 等离线分析系统,用于进行长期趋势分析和增长预测。
-
日志收集(Log Collection)
Kafka 可用于从服务器收集物理日志文件,并将其存储到文件服务器或 HDFS 中进行处理。
通过将日志或事件数据抽象为消息流,Kafka 消除了对文件格式的依赖,提供了低延迟的数据处理能力,并支持多数据源输入和分布式数据消费。
-
流式处理(Stream Processing)
Kafka Streams 提供了强大的流式数据处理功能,使开发者能够实时地处理数据流。
这意味着数据可以被动态地捕获、处理和分析,而无需先存储为静态数据集。
这种实时能力对于需要快速响应的应用场景至关重要,例如金融交易监控、实时推荐系统等。
2、Flume Introduction and Application Scenarios(Flume 简介与应用场景)
Apache Flume 最初是由 Cloudera 提供的日志采集系统,如今已成为 Apache 软件基金会(ASF)的顶级项目。
Flume 是一个分布式的、高可靠性、高可用性的服务,用于高效地收集、聚合并传输海量日志数据,广泛应用于大数据生态系统中。
Flume 能够将来自各种数据源的数据传输到集中式存储平台,例如 Hadoop 的 HDFS 或 HBase。
其设计使 Flume 成为一个高吞吐量的数据传输系统,尤其适合处理大规模日志数据的采集与传输。
Flume 系统的核心组件是 Flume Agent,它负责接收、处理和传输数据。
每个 Agent 是一个独立的 JVM 进程,包含 Source(数据源)、Channel(通道)、Sink(数据接收器) 等组件。
Flume 可以自定义数据源(Source)和数据接收器(Sink)的实现,并通过 拦截器(Interceptor) 对数据进行简单的 ETL 处理(抽取、转换、加载)。
通过连接多个 Flume Agent,可以实现多种数据流模型,如多级代理(multi-level agents)、扇入(fan in) 和 扇出(fan out) 等模式,以应对更复杂的使用场景和业务需求。
Flume 在大数据生态中得到了广泛应用,与 Hadoop、HBase 等大数据技术紧密集成,支持高效的数据采集与传输。
其主要特性包括:
-
分布式(Distributed):
Flume 是一个分布式服务,可从多个数据源收集数据并传输到集中式数据存储系统,如 Hadoop HDFS 或 HBase。
-
高可靠与高可用(Reliable and Available):
Flume 专为高可靠性和高可用性而设计,确保数据在传输过程中不会丢失,适用于大规模日志数据的采集与传输。
-
高吞吐量(High Throughput):
Flume 能够处理大规模数据流,具有高吞吐率的数据传输能力,非常适合处理海量日志数据。
-
灵活性(Flexibility):
Flume 支持多种数据源和数据存储目标,可通过配置不同类型的 Source、Channel 和 Sink 来满足不同的数据传输需求。
-
可扩展性(Scalability):
Flume 可以通过增加 Agent 数量实现水平扩展,以应对数据量的增长。
-
数据源与接收器的可定制化(Customization of Source and Sink):
Flume 允许用户自定义数据源和数据接收器,以满足不同场景下的数据采集与传输需求。
-
ETL 处理能力(ETL Processing):
Flume 可通过拦截器对数据进行简单的 ETL 操作,如过滤、转换等。
-
支持多种数据流模型(Multiple Data Flow Models):
通过连接多个 Flume Agent,可以实现多级代理、扇入(fan in)和扇出(fan out)等数据流模型,以应对复杂的业务场景。
Flume 的易用性与高可靠性,使其成为大数据领域中数据采集与传输的重要工具,主要应用场景包括:
-
日志收集(Log Collection):
Flume 常用于收集和传输分布式系统的日志数据。
由 Web 服务器、应用服务器、数据库等生成的日志数据,可以通过 Flume 传输到集中式存储系统(如 HDFS、HBase 或 Elasticsearch)进行统一存储与分析。
-
数据集成(Data Integration):
Flume 可作为数据集成工具,将来自不同数据源的数据汇聚到统一的存储平台。
数据可从数据库、文件系统、消息队列等多个来源采集,并传输至目标系统,如 HDFS、Kafka 或 HBase。
-
实时分析(Real-Time Analysis):
Flume 可与实时分析系统集成,实现实时数据的采集与分析。
数据可通过 Flume 传输至实时分析引擎,如 Apache Storm、Apache Spark 或 Apache Flink,以实现实时数据处理与分析。
-
系统监控与性能分析(System Monitoring & Performance Metrics):
系统指标与应用性能数据可以通过 Flume 传输至监控系统,如 Prometheus、Grafana 或 Nagios,以实现实时监控与告警功能。
3、Introduction and application scenarios of Sqoop(Sqoop 简介与应用场景)
各类应用的关系型数据库中存储的数据,是大数据的重要来源之一。
Apache Sqoop(SQL to Hadoop) 是一款开源工具,于 2012 年 3 月作为 Apache 顶级项目孵化成功,主要用于在关系型数据库(如 MySQL、Oracle、PostgreSQL 等)与 Hadoop 之间传输数据。
Sqoop 的设计目标是简化数据导入与导出的过程,使开发人员能够轻松地将关系型数据库中的结构化数据导入到 Hadoop 分布式文件系统(HDFS) 或 HBase 中,反之,也可以将 Hadoop(HDFS 或 HBase)中的数据导出到关系型数据库中。
由于该项目已足够成熟稳定,Sqoop 于 2021 年 6 月 从 Apache 基金会“退休”,并迁移至 Apache Attic 项目中作为其子项目。
Sqoop 的主要特性包括:
-
批量数据传输(Batch Data Transmission)
Sqoop 支持批量数据传输,能够高效地将大量数据从一个系统迁移到另一个系统。
-
数据一致性(Data Consistency)
通过事务性导入(Transactional Import),Sqoop 能够在数据传输过程中确保数据的一致性和完整性。
-
多数据格式支持(Multiple Data Formats)
Sqoop 支持多种数据格式,包括文本文件(Text File)、二进制序列化文件、Avro、Parquet 等。
-
增量数据导入(Incremental Data Import)
Sqoop 支持增量数据导入,用户可以仅导入自上次导入以来发生变化的数据,从而提高效率。
-
数据导出(Data Export)
Sqoop 不仅可以导入数据,还可以将 Hadoop 系统中的数据导出到关系型数据库中。
-
灵活性与可扩展性(Flexibility and Extensibility)
Sqoop 提供了丰富的配置选项与扩展机制,用户可以根据具体需求自定义数据传输过程。
Sqoop 已成为连接关系型数据库与 Hadoop 生态系统的重要工具,大大简化了数据传输与处理的复杂性,其主要应用场景包括:
-
大数据分析(Big Data Analysis)
在进行大数据分析时,Sqoop 可将关系型数据库中的数据导入 HDFS 或 HBase,再通过 Hadoop 生态中的工具(如 Hive、Pig、Spark 等)进行分析。
-
数据迁移与同步(Data Migration and Synchronization)
除作为数据迁移工具外,Sqoop 还可实现关系型数据库与 Hadoop 之间的数据同步,确保两者间的数据一致性。
-
ETL 过程(ETL Process)
在 ETL(抽取、转换、加载)流程中,Sqoop 可作为数据抽取工具,将数据从源系统抽取到 Hadoop 系统;
同时,也可在数据加载阶段,将 Hadoop 系统中的数据导出至关系型数据库。
-
数据仓库建设(Data Warehouse Construction)
Sqoop 常用于将关系型数据库中的数据导入 Hadoop 生态系统,以支持数据仓库建设,实现更深入的数据分析与处理。
-
为数据应用层提供数据(Providing Data for the Application Layer)
Sqoop 还可将 Hadoop 文件系统中的分析结果导出到关系型数据库(如 MySQL),为数据应用层提供支持,进一步实现大数据可视化等功能。