
Hive Chapter 3:HQL Syntax(HQL 语法)
一、HQL Syntax(HQL 语法)
Hive 提供了一种机制,可以在 Hadoop 中的数据之上投射结构,并使用一种类似 SQL 的语言——HiveQL (HQL) 来查询这些数据。
之所以使用 Hive,是因为 Hive 中的表与关系型数据库中的表非常相似。如果你熟悉 SQL,那么使用 Hive 就会非常容易。
许多用户可以同时使用 Hive-QL 来查询数据。
在本章中,将使用以下 Hive 表为例:
| 员工编号 (emp_id) | 姓名 (name) | 性别 (gender) | 年龄 (age) | 入职季度 (Q_O_J) | 入职年份 (Y_O_J) | 在公司年限 (A_I_C) | 薪水 (salary) | 上次涨薪幅度 (L_H) | country | region |
|---|---|---|---|---|---|---|---|---|---|---|
| 100 | Bernard | M | 55.98 | Q3 | 2017 | 0.02 | 10000 | 13% | India | South |
| 101 | Cordia | F | 25.19 | Q1 | 2014 | 3.54 | 12000 | 15% | US | South |
| 102 | Burton | M | 41.43 | Q3 | 2004 | 12.85 | 13000 | 30% | England | South |
| 103 | Lauren | M | 38.32 | Q3 | 2001 | 15.94 | 15000 | 1% | US | North |
| 104 | Carter | M | 51.75 | Q2 | 2014 | 3.27 | 14000 | 5% | England | North |
| 105 | Isaiah | M | 57.98 | Q3 | 2004 | 12.93 | 11000 | 2% | India | North |
| 106 | Hugh | M | 37.65 | Q4 | 2014 | 2.69 | 9000 | 30% | India | West |
| 107 | Lucius | M | 45.21 | Q4 | 2003 | 13.69 | 8000 | 2% | US | South |
| 108 | Deane | F | 53.24 | Q1 | 1999 | 18.36 | 7000 | 9% | US | West |
| 109 | Joannie | F | 33.72 | Q2 | 2012 | 5.27 | 6000 | 8% | US | South |
| 110 | Christene | F | 26.32 | Q1 | 2013 | 4.37 | 15000 | 30% | England | South |
上述的 “emp” 表包含以下列及其数据类型:
| 列名 (Column) | 数据类型 (Data Type) |
|---|---|
| emp_id | int |
| name | string |
| gender | string |
| age | double |
| Q_O_J | string |
| Y_O_J | string |
| A_I_C | double |
| Salary | double |
| L_H | double |
| Country | string |
| Region | string |
SELECT 语句语法
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list [HAVING condition]]
[
CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY | ORDER BY col_list]
]
[LIMIT number]
-
ALL 与 DISTINCT:
用于区分查询结果中是否包含重复记录。默认是 ALL,表示查询所有记录;
DISTINCT 表示去除重复记录,只保留唯一值。
-
WHERE:
与传统 SQL 中的
WHERE条件语句类似,用于筛选符合条件的记录。 -
ORDER BY 与 SORT BY:
- ORDER BY:用于全局排序,整个结果集在一个 Reducer 中排序,因此只有一个 Reduce 任务。
- SORT BY:用于局部排序,每个 Reducer 内部都会进行排序,可使用多个 Reducer 并行处理,效率更高。
-
LIMIT:
用于限制查询返回的记录条数。
-
打印列名:
可以通过设置以下参数来打印查询结果的列名:
set hive.cli.print.header = true;
WHERE 子句
示例:
hive> SELECT name, age
FROM emp
WHERE gender = 'M' AND salary > 9000;
结果:
OK
Bernard 55.98
Burton 41.43
Lauren 38.32
Carter 51.75
Isaiah 57.98
Time taken: 4.455 seconds, Fetched: 5 row(s)
ALL 与 DISTINCT 子句
ALL 和 DISTINCT 用于指定查询结果中是否包含重复的行。
如果未明确指定,默认是 ALL(返回所有行);
DISTINCT 表示去除重复行,仅返回唯一结果。
**示例 1:**默认使用 ALL(查询全部记录):
hive> SELECT gender, country FROM emp;
结果:
OK
M India
F US
M England
M US
M England
M India
M India
M US
F US
F US
F England
Time taken: 0.15 seconds, Fetched: 11 row(s)
**示例 2:**使用 DISTINCT(去重):
hive> SELECT DISTINCT gender, country FROM emp;
结果:
OK
F England
F US
M England
M India
M US
Time taken: 75.705 seconds, Fetched: 5 row(s)
GROUP BY 子句
GROUP BY 用于配合聚合函数,对结果集按一个或多个列分组。
它可以对相同属性的记录进行聚合统计。
**示例 1:**按性别分组统计人数:
hive> SELECT gender, COUNT(*)
FROM emp
GROUP BY gender;
结果:
OK
F 4
M 7
Time taken: 59.711 seconds, Fetched: 2 row(s)
**示例 2:**按国家分组求工资总和:
hive> SELECT country, SUM(salary)
FROM emp
GROUP BY country;
结果:
OK
England 42000.0
India 30000.0
US 48000.0
Time taken: 63.935 seconds, Fetched: 3 row(s)
HAVING 子句
HAVING 类似于 WHERE,但它与 GROUP BY 搭配使用,用于筛选分组后的结果。
示例:
hive> SELECT gender, COUNT(*)
FROM emp
GROUP BY gender
HAVING gender = 'F';
结果:
OK
F 4
Time taken: 66.17 seconds, Fetched: 1 row(s)
LIMIT 子句
当查询结果返回大量记录时,可以使用 LIMIT 来限制返回的行数。
示例:
hive> SELECT name, age
FROM emp
LIMIT 3;
结果:
OK
Bernard 55.98
Cordia 25.19
Burton 41.43
Time taken: 0.128 seconds, Fetched: 3 row(s)
Column Alias 列别名
可以使用 AS 关键字为列定义别名,使查询结果更简洁。
示例:
hive> SELECT name, salary AS sal
FROM emp
LIMIT 2;
结果:
OK
Bernard 10000.0
Cordia 12000.0
Time taken: 0.11 seconds, Fetched: 2 row(s)
LIKE 与 RLIKE 运算符
LIKE(模糊匹配):
LIKE 是标准 SQL 运算符,用于模糊搜索字符串。
Hive 中的 LIKE 支持以下通配符:
'_':匹配单个字符'%':匹配零个或多个字符
示例:
hive> SELECT emp_id, name, salary
FROM emp
WHERE name LIKE '_u%';
结果:
OK
102 Burton 13000.0
106 Hugh 9000.0
107 Lucius 8000.0
Time taken: 0.188 seconds, Fetched: 3 row(s)
RLIKE(正则匹配):
RLIKE 是 Hive 的扩展函数,基于 Java 正则表达式。
它判断:如果 A 的任意子串能匹配 B,则返回 true。
与 LIKE 不同,RLIKE 不需要使用 % 通配符。
示例:
hive> SELECT emp_id, name, salary
FROM emp
WHERE name RLIKE '(Hugh|Deane)';
结果:
OK
106 Hugh 9000.0
108 Deane 7000.0
Time taken: 0.131 seconds, Fetched: 2 row(s)
1、Hive Set Operators(Hive 集合操作符)
Hadoop Hive 支持以下集合操作符。
UNION [DISTINCT] 或 UNION:
UNION 集合操作符用于合并两个查询结果,并去除重复的行。
UNION 与 UNION DISTINCT 等价,默认会对结果去重。
UNION ALL:
UNION ALL 用于合并两个查询结果,但不会去除重复的行。
相比 UNION,UNION ALL 执行更快,因为它省去了去重的计算过程。
Hive 中 UNION 与 UNION ALL 的语法
SELECT Statement
{ UNION [DISTINCT] | UNION [ALL] }
SELECT Statement;
Hive 子查询(Subqueries)
在 Hive 中,一个查询语句内部包含另一个查询语句的情况称为 子查询 (Subquery)。主查询(Main Query)依赖子查询返回的结果进行操作。
Hive 中的子查询主要分为两种类型:
FROM 子句中的子查询:
在 FROM 中使用子查询通常是为了生成一个临时结果集,再从中查询。
SELECT col1
FROM (SELECT a + b AS col1 FROM t1) t2;
此处,子查询 (SELECT a + b AS col1 FROM t1) 被命名为临时表 t2,外层查询再从中取数据。
WHERE 子句中的子查询:
在 WHERE 中使用子查询通常是为了根据另一张表的结果进行筛选。
SELECT name, age
FROM emp
WHERE emp.emp_id IN (SELECT id FROM dept);
此处,只有当 emp.emp_id 存在于 dept 表的 id 列中时,记录才会被选中。
使用场景:
- 获取来自不同表的两个列值组合而成的特定值
- 处理一个表中数据依赖于另一个表中值的情况
- 在多表之间进行列值的比较检查
分区查询(Partition-Based Query)
通常情况下,一个 SELECT 查询会扫描整个表(除非使用采样)。但如果表在创建时使用了 PARTITIONED BY 子句,则 Hive 会根据查询中指定的分区条件,仅扫描表的一部分数据。这称为 分区裁剪(Partition Pruning),能显著提高查询效率。
**示例 1:**在 WHERE 中指定分区范围:
假设 page_views 表按照 date 列分区:
SELECT page_views.*
FROM page_views
WHERE page_views.date >= '2008-03-01'
AND page_views.date <= '2008-03-31';
此查询只会扫描日期在 2008-03-01 到 2008-03-31 之间的分区,而不会读取整个表。
**示例 2:**在 JOIN 的 ON 子句中指定分区条件:
当 page_views 表与其他表(例如 dim_users)进行连接时,也可以在 ON 子句中直接加入分区条件:
SELECT page_views.*
FROM page_views
JOIN dim_users
ON (page_views.user_id = dim_users.id
AND page_views.date >= '2008-03-01'
AND page_views.date <= '2008-03-31');
这样 Hive 会在执行连接(JOIN)前就对 page_views 进行分区裁剪,从而提升查询效率。
2、Joins in Hive(Hive中的连接操作)
在 Hive 中,Join(连接) 的作用与传统关系型数据库(RDBMS)中的相同。
Join 用于根据一个公共字段或值,从两个或多个表中提取有意义的数据。
换句话说,Join 用于将多个表的数据组合在一起。
当在 FROM 子句中指定了多个表时,就会执行一次 Join 操作。
目前,Hive 只支持基于“等值条件(equality conditions)”的连接,它不支持任何基于非等值条件(non-equality conditions) 的连接操作。
Using Equality Joins to Combine Tables(使用等值连接来组合表)
Hive 支持表与表之间的等值连接(Equality Join),以便将两个表中的数据组合在一起。
Hive 的语法如下:
SELECT table_fields
FROM table_one
JOIN table_two
ON (table_one.key_one = table_two.key_one
AND table_one.key_two = table_two.key_two);
| SQL 语句 | 说明 |
|---|---|
SELECT table_fields |
关键字,用于从两个表中选择一系列字段。 |
FROM table_one & JOIN table_two |
列出要连接的两个表,用于获取 table_fields。 |
ON (table_one.key_one = table_two.key_one``AND table_one.key_two = table_two.key_two) |
列出连接两个表的等值条件规则。 |
Joining Tables in Hive(在 Hive 中连接表)
这段练习让你在 Hive 中创建两个表 census.personname 和 census.address 之间的连接(Join)。
示例使用脚本 Script_EqualJoin.txt。
完整脚本如下:
-- 切换到 census 数据库
USE census;
-- 创建 personname 表,存储人员信息
CREATE TABLE census.personname (
persid int, -- 人员ID(主键,用于连接)
firstname string, -- 名字
lastname string -- 姓氏
)
CLUSTERED BY (persid) INTO 1 BUCKETS -- 按 persid 分桶(这里仅 1 个桶)
STORED AS orc -- 使用 ORC 格式存储(高效压缩)
TBLPROPERTIES ('transactional' = 'true'); -- 设置表为可事务表(支持 ACID)
-- 向 personname 表中插入示例数据
INSERT INTO TABLE census.personname VALUES
(0, 'Albert', 'Ape'),
(1, 'Bob', 'Burger'),
(2, 'Charlie', 'Clown'),
(3, 'Danny', 'Drywer');
-- 创建 address 表,存储人员对应的邮政信息
CREATE TABLE census.address (
persid int, -- 人员ID(与 personname 表关联)
postname string -- 邮政编码
)
CLUSTERED BY (persid) INTO 1 BUCKETS -- 同样按 persid 分桶
STORED AS orc
TBLPROPERTIES ('transactional' = 'true');
-- 向 address 表中插入示例数据
INSERT INTO TABLE census.address VALUES
(1, 'KA13'),
(2, 'KA9'),
(10, 'SW1');
现在,你拥有两个表:
- census.personname
- census.address
接下来执行连接操作:
-- 执行连接查询
-- 目的:找出在两个表中都存在的人员(根据 persid 匹配)
SELECT
personname.firstname, -- 取出名字
personname.lastname, -- 取出姓氏
address.postname -- 取出邮政编码
FROM
census.personname
JOIN
census.address
ON (personname.persid = address.persid); -- 等值连接条件
连接结果如下:
OK
Bob Burger KA13
Charlie Clown KA9
Using Outer Joins(使用外连接)
Hive 支持在表之间使用 LEFT(左外连接)、RIGHT(右外连接) 和 FULL OUTER(全外连接) 等等值连接(Equality Join),用于处理连接键(key)没有匹配记录的情况。
Hive 的语法如下:
SELECT table_fields
FROM table_one [LEFT | RIGHT | FULL OUTER] JOIN table_two
ON (table_one.key_one = table_two.key_one
AND table_one.key_two = table_two.key_two);
| SQL 语句 | 说明 |
|---|---|
SELECT table_fields |
关键字,用于从两个表中选择一系列字段。 |
FROM table_one``LEFT JOIN table_two |
列出要连接的两个表。LEFT JOIN(左外连接)会返回左表中所有匹配的记录,以及右表中匹配和不匹配的记录。 |
FROM table_one``RIGHT JOIN table_two |
列出要连接的两个表。RIGHT JOIN(右外连接)会返回右表中所有匹配的记录,以及左表中匹配和不匹配的记录。 |
FROM table_one``FULL OUTER JOIN table_two |
列出要连接的两个表。FULL OUTER JOIN(全外连接)会返回两个表中所有匹配的记录,以及左右两边未匹配的记录。 |
ON (table_one.key_one = table_two.key_one``AND table_one.key_two = table_two.key_two) |
指定连接两个表的等值条件。 |
Joining Tables in Hive Using Left Join(在 Hive 中使用左连接连接表)
Hive 支持表之间的 等值连接(Equality Join),用于将两个表中的数据组合在一起。
本示例使用脚本 Script_OuterJoin.txt。
完整脚本如下:
USE census;
SELECT personname.firstname,
personname.lastname,
address.postname
FROM
census.personname
LEFT JOIN
census.address
ON (personname.persid = address.persid);
该查询的结果应包含 4 条记录:
OK
Albert Ape NULL
Bob Burger KA13
Charlie Clown KA9
Danny Drywer NULL
Joining Tables in Hive Using Right Join(在 Hive 中使用右连接连接表)
接下来执行一个 右连接(Right Join) 的示例:
SELECT personname.firstname,
personname.lastname,
address.postname
FROM
census.personname
RIGHT JOIN
census.address
ON (personname.persid = address.persid);
该查询的结果应包含 3 条记录:
OK
Bob Burger KA13
Charlie Clown KA9
NULL NULL SW1
Full Outer Join(在 Hive 中使用全外连接)
现在来看看 全外连接(Full Outer Join) 的示例:
SELECT personname.firstname,
personname.lastname,
address.postname
FROM
census.personname
FULL OUTER JOIN
census.address
ON (personname.persid = address.persid);
该查询的结果应包含 5 条记录:
OK
Albert Ape NULL
Bob Burger KA13
Charlie Clown KA9
Danny Drywer NULL
NULL NULL SW1
Joining Three Tables in One MapReduce(在一次 MapReduce 中连接三个表)
这个练习展示了如何在 一次 MapReduce 操作中连接三张表。
示例使用脚本 Script_MultiJoin.txt。
完整脚本如下:
-- 使用 census 数据库
USE census;
-- 创建账户表 account,用于存储人员账户余额信息
CREATE TABLE census.account (
persid int, -- 人员ID(用于与其他表连接)
bamount int -- 账户余额(balance amount)
)
CLUSTERED BY (persid) INTO 1 BUCKETS -- 按人员ID分桶(分桶字段必须与连接键一致)
STORED AS orc -- 使用 ORC 格式存储(支持事务和高效压缩)
TBLPROPERTIES('transactional' = 'true'); -- 启用事务支持,使表具有 ACID 特性
-- 向 account 表插入测试数据
-- 表示每个人员ID对应的账户余额
INSERT INTO TABLE census.account VALUES
(1, 12), -- persid = 1,对应账户余额 12
(2, 9); -- persid = 2,对应账户余额 9
-- 注意:这里只插入两个ID,与 personname 和 address 表的数据部分匹配
-- 执行三表连接查询
-- 在同一个 MapReduce 作业中完成多表 Join
SELECT
personname.firstname, -- 来自 personname 表的“名”
personname.lastname, -- 来自 personname 表的“姓”
address.postname, -- 来自 address 表的邮政编码
account.bamount -- 来自 account 表的账户余额
FROM
census.personname
JOIN
census.address
ON (personname.persid = address.persid) -- 第一层连接:人员表与地址表,通过 persid 匹配
JOIN
census.account
ON (personname.persid = account.persid); -- 第二层连接:人员表与账户表,通过 persid 匹配
-- 由于两个 JOIN 都基于同一个键(persid),Hive 会优化为单个 MapReduce 阶段执行
查询结果应包含 2 条记录:
OK
Bob Burger KA13 12
Charlie Clown KA9 9
Using Largest Table Last(最大表后使用)
Hive 在执行多表连接(Join)时,会先缓存前面的表,然后将最后一个表通过 Map 阶段与前面缓存的数据进行匹配。
Hive 的语法如下:
SELECT table_one.key_one,
table_two.key_one,
table_three.key_one
FROM
table_one
JOIN
table_two
ON (table_one.key_one = table_two.key_one)
JOIN
table_three
ON (table_three.key_one = table_two.key_one);
| SQL 语句 | 说明 |
|---|---|
table_one 和 table_two |
缓存在内存中(Buffered in memory) |
table_three |
直接从磁盘映射读取(Mapped directly from di |
Hive 的第二种语法如下:
SELECT table_one.key_one,
table_two.key_one,
table_three.key_one
FROM
table_one
JOIN
table_three
ON (table_one.key_one = table_three.key_one)
JOIN
table_two
ON (table_two.key_one = table_three.key_one);
| SQL 语句 | 说明 |
|---|---|
table_one 和 table_three |
缓存在内存中(Buffered in memory) |
table_two |
直接从磁盘映射读取(Mapped directly from disk) |
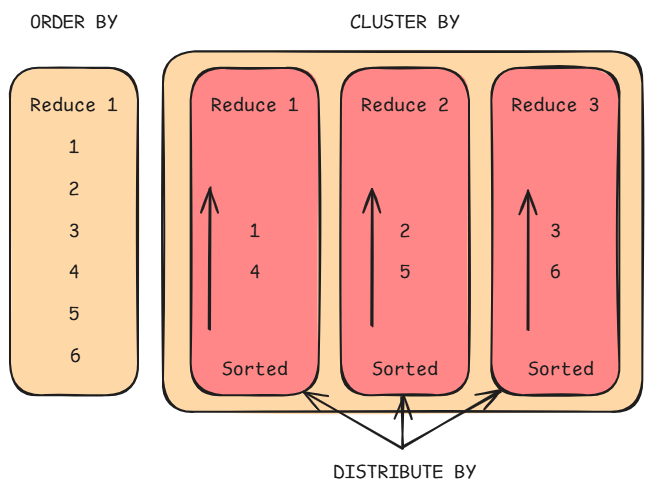
3、ORDER BY and SORT BY(ORDER BY 与 SORT BY)
在 Hive 中操作数据的另一个重要方面,是对数据或结果集进行正确的排序(order/sort),以便清晰地识别出关键信息,例如 前 N 个值(Top N)、最大值、最小值 等。
Hive 中用于对数据进行排序和排列的关键字如下:
ORDER BY(升序 ASC / 降序 DESC)
该语句与传统关系型数据库(RDBMS)中的 ORDER BY 功能相同。
Hive 在执行 ORDER BY 时,会对所有 Reducer 输出的数据进行全局排序,即在所有结果中保持完整的有序性。
由于 ORDER BY 只使用一个 Reducer 来执行全局排序,因此在数据量较大的情况下,执行时间会较长。
建议在使用 ORDER BY 时,最好结合 LIMIT 一起使用,以限制返回的数据量,从而提高性能。
SELECT name
FROM emp
ORDER BY name DESC;
SORT BY(升序 ASC / 降序 DESC)
SORT BY 用于指定在将数据发送给 Reducer 之前,Mapper 端应该根据哪些列进行排序。也就是说,排序在发送数据到 Reducer 之前完成。
SORT BY 不会进行全局排序(Global Sort),它只保证每个 Reducer 内部的数据是局部有序(Locally Sorted)。除非设置参数 mapred.reduce.tasks=1,否则结果不会像 ORDER BY 那样在全局范围内有序。
如果将 mapred.reduce.tasks 设置为 1,那么 SORT BY 的结果将与 ORDER BY 完全相同。
- 使用多个 Reducer:
SET mapred.reduce.tasks = n; -- n 可以是 2, 3 等多个 Reducer
SELECT name FROM emp SORT BY name;
- 使用单个 Reducer:
SET mapred.reduce.tasks = 1;
SELECT name FROM emp SORT BY name;
DISTRIBUTE BY
DISTRIBUTE BY 用于指定具有相同列值的行应被分配到同一个 Reducer 中。当单独使用 DISTRIBUTE BY 时,并不能保证 Reducer 输入的数据是有序的。
在功能上,它类似于关系型数据库(RDBMS)中的 GROUP BY,即决定了 Mapper 的输出将被发送到哪个 Reducer。
当与 SORT BY 一起使用时,DISTRIBUTE BY 必须出现在 SORT BY 之前。同时,用于分发的列必须出现在 SELECT 的列列表中。
- 单独使用:
SELECT name, emp_id
FROM emp
DISTRIBUTE BY emp_id;
- 与
SORT BY一起使用:
SELECT name, emp_id
FROM emp
DISTRIBUTE BY emp_id
SORT BY name;
CLUSTER BY
CLUSTER BY 是一种简写操作符,相当于同时执行 DISTRIBUTE BY 和 SORT BY,并且基于同一组列完成分发与排序。
CLUSTER BY 在每个 Reducer 内部进行局部排序,但目前不支持 ASC 或 DESC(即只能默认升序)。
与 ORDER BY 的区别是:
ORDER BY进行全局排序(Global Sort);CLUSTER BY只在每个 Reducer 内部排序(Local Sort)。
在需要全局排序但又想充分利用多个 Reducer 时,可以先使用 CLUSTER BY 再执行 ORDER BY。
SELECT name, emp_id
FROM emp
CLUSTER BY name;
4、HQL common examples(HQL 常用示例)
-
创建表
create table emp( emp_id string, name string, gender string, age double, Q_O_J string, Y_O_J string, A_I_C double, salary double, L_H double, country string, region string ) row format delimited fields terminated by ',' lines terminated by '\n' stored as textfile; -
查询薪资最高的员工姓名
select name from (select * from emp order by salary desc limit 1) a; -
输出每个国家(country)中的区域(region)数量
select country, count(*) from emp group by country; -
输出拥有区域数最多的两个国家
select country from ( select * from ( select country, count(*) as cnt from emp group by country ) a order by cnt desc limit 2 ) b; -
输出薪资第二高的员工姓名
select name from ( select * from ( select * from emp order by salary desc limit 2 ) a order by salary limit 1 ) b; -
将查询结果导出到本地
INSERT OVERWRITE LOCAL DIRECTORY '/opt/datafiles' select name from ( select * from ( select * from emp order by salary desc limit 2 ) a order by salary limit 1 ) b; -
查询销售记录最大的 5 个销售代表
SET mapred.reduce.tasks = 1; SELECT * FROM test SORT BY amount DESC LIMIT 5; -
从同一张表向不同的表和路径插入数据
FROM src INSERT OVERWRITE TABLE dest1 SELECT src.* WHERE src.key < 100 INSERT OVERWRITE TABLE dest2 SELECT src.key, src.value WHERE src.key >= 100 and src.key < 200 INSERT OVERWRITE TABLE dest3 PARTITION(ds='2008-04-08', hr='12') SELECT src.key WHERE src.key >= 200 and src.key < 300 INSERT OVERWRITE LOCAL DIRECTORY '/tmp/dest4.out' SELECT src.value WHERE src.key >= 300; -
输出总薪资(salary)最低的两个国家
select * from ( select country, sum(salary) as sal from emp group by country ) a order by sal limit 2;
二、Hive Views(Hive 视图)
基本上,Apache Hive 的视图与 Hive 表类似,它们都是根据需求生成的。

1、Apache Hive View on External Table(基于外部表的 Apache Hive 视图)
- 作为 Hive 视图,我们可以保存任何结果集数据。
- 从用途上来说,它的使用方式与 SQL 中的视图相同。
- 此外,我们可以对 Hive 视图执行所有类型的 DML 操作。
换句话说,Apache Hive 的视图是数据库中的一个可查询对象,它是由查询语句定义的。然而,我们不能在视图中存储数据。视图通常被称为 “虚拟表”。因此,我们可以像查询表一样查询视图。另外,通过使用 joins,可以将多个表中的数据组合起来。视图也可以只包含部分数据(数据子集)。
Apache Hive 视图语法
CREATE VIEW <VIEWNAME> AS SELECT ...
创建 Hive 视图
在执行 SELECT 语句的同时,我们可以创建视图。因此,创建 Hive 视图的语法如下:
CREATE VIEW [IF NOT EXISTS] view_name
[(column_name [COMMENT column_comment], …)]
[COMMENT table_comment]
AS SELECT …
Apache Hive 视图示例
假设有一张员工表(employee),包含字段:Id、Name、Salary、Designation 和 Dept。
现在,我们要查询工资高于 RMB 35000 的员工,并将结果存储在名为 emp_35000 的视图中。
示例数据如下:
| ID | Name | Salary | Designation | Dept |
|---|---|---|---|---|
| 1201 | Michel | 45000 | Technical manager | TP |
| 1202 | Chandler | 45000 | Proofreader | PR |
| 1203 | Ross | 40000 | Technical writer | TP |
| 1204 | Joey | 40000 | Hr Admin | HR |
| 1205 | Monika | 35000 | Op Admin | Admin |
根据以上数据,创建视图的 Hive 查询如下:
hive> CREATE VIEW emp_35000 AS
SELECT * FROM employee
WHERE salary > 35000;
删除 Hive 视图
要删除 Hive 视图,可以使用以下语法:
DROP VIEW view_name;
例如,删除名为 emp_35000 的视图:
hive> DROP VIEW emp_35000;
三、Advanced Table Properties(高级表属性)
在加载表数据时跳过表头(Header)和表尾(Footer)记录。
在许多源文件中,我们经常会看到文件顶部的一些行(header)和底部的一些行(footer)。这些行并不是实际数据,而是包含一些关于数据或文件本身的信息。
因此,我们有两种处理方式:
- 手动去文件中删除这些表头和表尾行,然后再基于清理后的文件创建表(不推荐)。
- 使用表属性(table properties)在创建表时自动跳过这些表头和表尾行(推荐)。
请看下面的源文件示例:
- 文件的 前两行 是表头(header),提供文件的创建日期和文件名等信息。
- 文件的 最后两行 是表尾(footer),提供文件总行数、最后修改日期等信息。
File Creation Date : 2024-01-10
File Name : employee_data.txt
101,Michael,45000,TP
102,Ross,40000,TP
103,Joey,40000,HR
104,Monika,35000,Admin
105,Chandler,45000,PR
Total Rows : 5
Last Modified : 2024-01-12
我们在创建表时使用了属性 "skip.header.line.count"="2",因为我们想要跳过文件顶部的 2 行;同时使用 "skip.footer.line.count"="2",因为我们也想跳过文件底部的 2 行。
create table if not exists Tb_Employee (
id int,
EMP_NAME string,
Department_ID int,
Manager_ID int,
Designation string,
Location string,
Years_of_Experience double
)
row format delimited
fields terminated by ','
lines terminated by '\n'
stored as textfile
tblproperties (
"skip.header.line.count"="2",
"skip.footer.line.count"="2"
);
现在,当我们向这个表中加载数据时,Hive 会自动跳过前两行的表头和后两行的表尾内容。
1、Hive Immutable Table property(Hive 不可变表属性)
不可变对象是指一旦创建就不能被修改的对象。Hive 提供了表的不可变属性,用于阻止 insert into 命令对表进行追加操作。insert into 命令用于向表或分区追加数据,同时保留已有数据。
在正常情况下,当表不是不可变(即表是可变的 mutable)时,insert into 的行为是:如果一张表中已经存在数据,现在希望在保留旧数据的前提下插入新数据,就会使用 insert into。
Mutable Table(可变表):所有表默认都是可变的。当表中已存在数据时,可变表允许继续追加数据。
Immutable Table(不可变表):可以通过将表属性设置为 true 来创建不可变表。默认情况下该属性为 false。
创建不可变表示例:
create table if not exists EMP1 (
emp_id int,
emp_name string,
dept_id int
)
row format delimited
fields terminated by ','
lines terminated by '\n'
stored as textfile
tblproperties ("immutable"="true");
不可变属性允许首次加载数据,但在第一次插入之后,再执行后续的 insert into 会失败,因此不可变表只能拥有一份数据集。
对非空的不可变表执行 insert into:如果尝试这样做,Hive 会报错,表示不允许向非空的不可变表插入数据。
对非空的不可变表执行 insert overwrite:不可变表中所有旧数据会被删除,并插入新数据。
因此可以得出结论:insert overwrite 不受不可变属性的影响。
2、Hive Null Format property(Hive 空值格式属性)
这个属性允许将传入的指定值视为 NULL。下面来看一个示例。
下面的源文件包含 3 列,但其中有 3 行(第 2、3、5 行)第二列的值缺失。例如在第 2 行,20 后面的第二列值缺失:
20,20-April-2021,Shanghai
30,,Guiyang
40,,Tongran
50,21-May-2021,Delhi
60,22-June-2021,Mumbai
如果我们尝试将这个文件加载到一张具有 3 列的 Hive 表中,Hive 会成功加载文件。但是,如果我们尝试从表中查询第二列为 NULL 的数据,将会返回零行记录。
这是因为在默认情况下,分隔符之间没有任何内容时,Hive 并不会将其视为 NULL。在 Hive 看来,只要是在分隔符之间的内容,不管是否为空,它都会当作普通数据,而不会当成 NULL。
示例表:
create table if not exists DEPT_DET (
Department_ID int,
Started_on string,
Location string
)
row format delimited
fields terminated by ','
lines terminated by '\n'
stored as textfile;
未使用 Null Format 属性的表中显示的数据:
hive> select * from dept_det;
OK
20 20-April-2021 Shanghai
30 Guiyang
40 Tongran
50 21-May-2021 Delhi
60 22-June-2021 Mumbai
如上所示,Hive 没有将空字段填成 NULL。
使用 Null Format 属性的表中显示的数据:
让我们创建另一张表。这里使用表属性 "serialization.null.format"=""(空字符串),表示我们希望将空字段替换为 NULL。
如果我们想让空格也变成 NULL,只需要在设置属性时把等号后面的值改成一个空格即可。
示例:
create table if not exists DEPT_DET1 (
Department_ID int,
Started_on string,
Location string
)
row format delimited
fields terminated by ','
lines terminated by '\n'
stored as textfile
tblproperties("serialization.null.format"="");
查询结果:
hive> select * from dept_det1;
OK
20 20-April-2021 Shanghai
30 NULL Guiyang
40 NULL Tongran
50 21-May-2021 Delhi
60 22-June-2021 Mumbai
如上所示,Hive 现在会将空字段替换为 NULL。设置此属性后,Hive 会将所有空值都视为 NULL。