Chapter 1:Big Data Concept(大数据概念)
一、Type of Big Data
1、Structured(结构化)
以固定格式存储、访问和处理的数据都称为结构化数据,但灵活性差。比如 MySQL 中储存的数据表。
2、Unstructred(非结构化数据)
任何形式或结构未知的数据都属于非结构化数据。这类数据通常包含大量文本、图像、音频、视频等信息,格式多样且复杂。比如你在搜索引擎中搜索关键词后返回的结果。
3、Semi-structred(半结构化)
半结构化数据是介于结构化数据和非结构化数据之间的一种数据类型。它虽然没有严格的数据模式(Schema),但包含一定的结构信息,通常通过标签、标记或格式来组织数据。比如 XML 文件中表示的数据。
二、Characteristics of Big Data
1、Volume(数据量)
指数据的规模巨大。随着互联网、物联网等技术的发展,数据量呈指数级增长,传统的数据处理工具难以应对。
2、Variety(多样性)
指数据的类型多样。包括结构化数据(如数据库)、半结构化数据(如XML、JSON)和非结构化数据(如文本、图像、视频等)。
3、Velocity (速度)
指数据生成和处理的速度快。数据实时或近实时地产生,要求系统能够快速处理和分析,以支持实时决策。
4、Veracity(真实性)
指数据的准确性和可信度。大数据中可能存在噪声、不一致或错误,确保数据的质量是分析结果可靠的关键。
三、Hadoop Ecosystem tools
1、HBASE
HBase 是一个开源的、非关系型的分布式数据库。换句话说,它是一种 NoSQL 数据库。它支持所有类型的数据,因此能够处理 Hadoop 生态系统中的任何内容。
2、HIVE
Apache Hive 数据仓库软件构建在 Apache Hadoop 之上,用于查询和管理大规模分布式数据集。它提供以下功能:HIVE 提供了一系列工具来实现 ETL(extract提取/transform转换/load加载)。HIVE 可以存储、查询和分析存储在 HDFS(或 HBase)中的大规模数据。SQL 被转换为 MapReduce 作业并在 Hadoop 上运行,以执行统计分析和处理海量数据。
Hive 定义了一种类似于 SQL 的查询语言,称为 HQL。熟悉 SQL 的用户可以直接使用 Hive 查询数据。
3、HADOOP
在传统方式中,所有数据都存储在单一的中央数据库中。随着大数据的兴起,单一的数据库已不足以处理这些任务。解决方案是使用分布式方法来存储海量信息。数据被分割并分配到许多独立的数据库中。HDFS 是一个专门为在商用硬件上存储大规模数据集而设计的文件系统,它将信息以不同的格式存储在多台机器上。
4、STORM
Apache Storm 是一个免费、开源的分布式实时计算系统,它简化了流数据的可靠处理。
Storm 使用 Hadoop Zookeeper 进行集群协调,可以充分确保大型集群的良好运行。每条信息的处理都可以得到保证。
5、Zookeeper
Apache Zookeeper 是任何 Hadoop 作业的协调者,在 Zookeeper 之前,Hadoop 生态系统中不同服务之间的协调非常困难且耗时。早期的服务在交互时存在许多问题,例如同步数据时的常见配置。即使服务配置好了,服务配置的变化也会使其变得复杂且难以处理。分组和命名也是一个耗时的因素。
由于上述问题,Zookeeper 被引入。它通过执行同步、配置维护、分组和命名节省了大量时间。尽管它是一个简单的服务,但它可以用于构建强大的解决方案。
6、SQOOP
Sqoop 是 Apache 的顶级项目,它允许用户将数据从关系数据库提取到 Hadoop 中进行进一步处理。在获得分析结果后,Sqoop 还可以将分析结果导回数据库,供其他客户端使用。
Chapter 2:Hadoop and Big Data Architecture(Hadoop 与大数据架构)
一、 Hadoop Operating Modes
1、Local runtime mode(本地运行模式)
默认情况下,Hadoop 会以非分布式模式运行,作为一个单独的 Java 进程,这种模式称为 本地模式(Local/Standalone Mode)。在这种模式下,不需要运行任何守护进程,所有的程序都在单个 JVM 上执行。由于在本地模式下更容易测试和调试 MapReduce 程序,因此这种模式适合在开发阶段使用。
2、Pseudo-distributed operating mode(伪分布式运行模式)
Hadoop 可以在单个节点上运行,每个 Hadoop 守护进程以单独的 Java 进程运行,这种模式称为 伪分布式模式(Pseudo-Distributed Mode)。在这种模式下,所有的 Hadoop 进程都运行在单个服务器节点上,以模拟一个完全分布式的环境,通常用于实验学习阶段。Hadoop 伪分布式集群启动后,也会像完全分布式集群一样有五个进程。这些进程的名称如下:
- NameNode
- DataNode
- SecondaryNameNode
- ResourceManager
- NodeManager
HDFS 守护进程
HDFS(分布式文件系统)用于解决海量数据存储的问题。HDFS 的正常运行需要以下三个进程:
- NameNode
- DataNode
- SecondaryNameNode
也就是说,运行 start-dfs.sh 命令可以启动 HDFS 守护进程,以对外提供服务。
YARN 守护进程
YARN 是 Hadoop 3.x 中的资源管理系统。YARN 的正常运行需要以下两个进程:
- ResourceManager
- NodeManager
运行 start-yarn.sh 命令可以启动 YARN 守护进程,以对外提供服务。
3、Fully distributed operating mode(完全分布式运行模式)
Hadoop 可以在集群上运行,每个 Hadoop 守护进程以 Java 进程的形式运行在集群中的每个服务器节点上,这种模式称为 完全分布式模式(Full-Distributed Mode)。这种模式通常用于实验验证和企业部署阶段。集群中的进程总数与伪分布式模式相同,即以下五个进程:
- NameNode
- DataNode
- SecondaryNameNode
- ResourceManager
- NodeManager
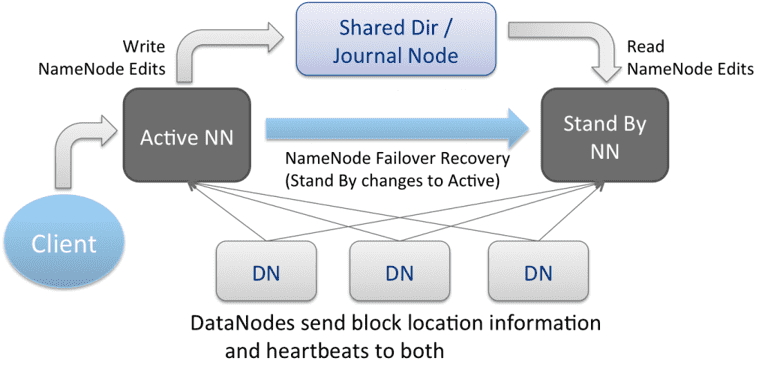
4、High availability (HA) operating mode(高可用运行模式)
高可用性集群(High Availability Cluster) 的概念是在 Hadoop 2.x 中引入的,目的是解决 Hadoop 1.x 中存在的单点故障问题。众所周知,HDFS 架构遵循 主从拓扑(Master/Slave Topology),其中 NameNode 作为主守护进程,负责管理其他称为 DataNode 的从节点。这种单一的主守护进程(NameNode)成为了系统的瓶颈。尽管 SecondaryNameNode 的引入确实防止了数据丢失,并减轻了 NameNode 的部分负担,但它并没有解决 NameNode 的可用性问题。
而 HDFS 的高可用性(HA)架构通过引入 Active/Standby NameNode 配置,解决了 NameNode 的单点故障问题。在高可用性集群中,同时运行两个 NameNode:
- Active NameNode:负责处理所有客户端请求和管理 DataNode。
- Standby/Passive NameNode:作为备份 NameNode,实时同步 Active NameNode 的状态,准备在故障时接管工作。
如果一个 NameNode 宕机,另一个 NameNode 可以接管责任,从而减少集群的停机时间,为 Hadoop 集群提供了故障转移能力。
在 HDFS HA 架构中,保持一致性有两个问题:
- 主动和备用 NameNode 应始终保持同步,即它们应具有相同的元数据。这将使我们能够将 Hadoop 集群恢复到崩溃时的相同命名空间状态,从而提供快速的故障转移。
- 应始终只有一个主动 NameNode,因为两个主动 NameNode 会导致数据损坏。即集群被分成多个较小的集群,每个集群都认为自己是唯一的主动集群,这种情况称为 "脑裂"(split-brain)。为了避免这种情况,需要进行隔离。隔离是确保在特定时间只有一个 NameNode 保持活动的过程。
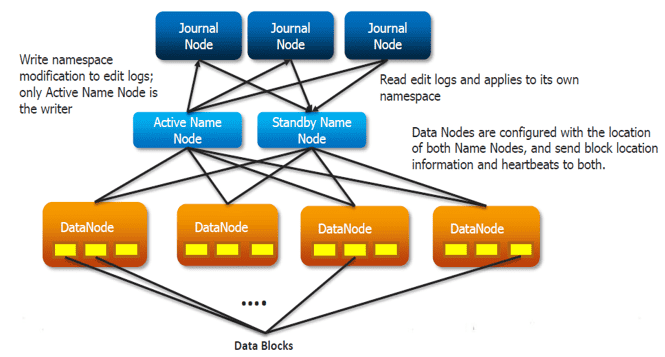
HDFS HA 架构使用两种方法解决 Active 和 Standby NameNode 同步的配置:
使用法定日记节点( Quorum Journal Nodes):
- 备用 NameNode 和活动 NameNode 通过一组独立的节点或守护进程(称为 JournalNodes)保持同步。这些节点处理请求并将信息复制到网络中的其他节点,从而在 JournalNode 发生故障时提供容错能力。
- 活动 NameNode 负责更新 JournalNodes 中的 EditLogs(编辑日志)。
- 备用 NameNode 持续读取 JournalNodes 中的 EditLogs 变化,并将其应用到自身。
- 在故障转移期间,备用 NameNode 确保在成为新的活动 NameNode 之前,已从 JournalNodes 更新其元数据信息,与 活动 NameNode 保持同步。
- 所有 DataNodes 都可以访问两个 NameNode 的 IP 地址,并向其发送数据块位置信息。这种机制使备用 NameNode 能够快速接管,减少系统停机时间。
使用共享存储(Shared Storage):
- 备用 NameNode 和活动 NameNode 通过共享存储设备保持同步。活动 NameNode 会记录对其的任何修改,并将其写入共享存储中的 EditLog。
- 备用 NameNode 读取共享存储中的 EditLogs 并写入自身。
- 在发生故障转移时,备用 NameNode 会优先从 EditLogs 更新元数据,然后接管活动 NameNode 的职责,从而保证状态与故障转移前保持一致。
- 管理员必须配置至少一种隔离方法(fencing method)以避免 "脑裂"(split-brain)情况。
- 可能使用的隔离机制包括:终止 NameNode 进程、撤销其对共享存储目录的访问权限等。
Chapter 3:Hadoop Composition and Structure(Hadoop 的组成与结构)
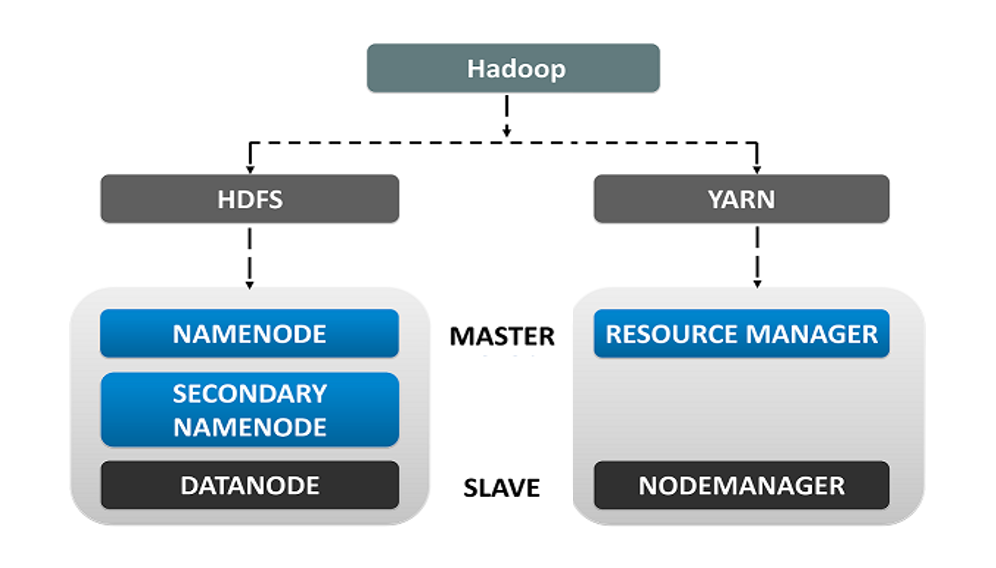
一、Hadoop Architecture and Components(Hadoop 架构和组件)
Hadoop 采用主从拓扑结构。在这种拓扑结构中,我们有一个主节点(Master Node)和多个从节点(Slave Nodes)。主节点的功能是向各个从节点分配任务并管理资源,而从节点执行实际的计算。从节点存储真实数据,而主节点存储元数据(即关于数据的数据,即记录数据存放位置)。
1、Hadoop Core Components(Hadoop 核心组件)
Hadoop 是一个框架,允许在多个节点系统上存储大规模数据。Hadoop 架构通过多个组件实现数据的并行处理:
- Hadoop HDFS:在多个从节点上存储数据。
- Hadoop YARN:用于Hadoop集群的资源管理。
- Hadoop MapReduce:用于分布式数据处理。
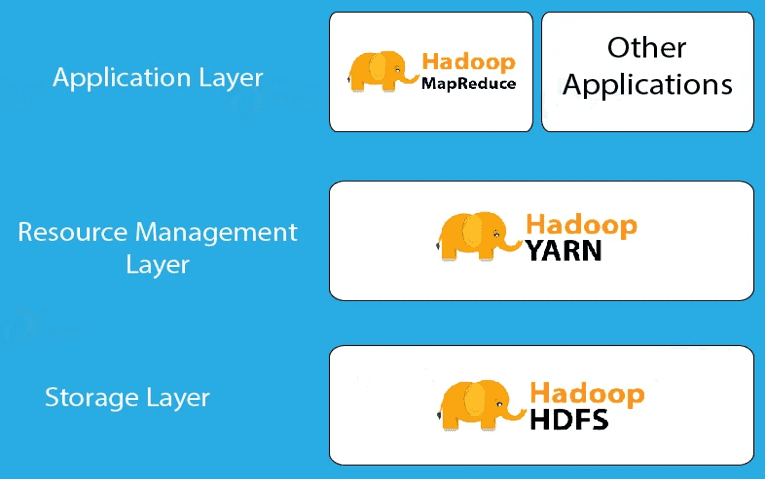
2、Hadoop Architecture(Hadoop 架构)
- HDFS(Hadoop 分布式文件系统):Hadoop生态系统中的主要存储单元。HDFS 使 Hadoop 能够快速访问数据,并具备良好的扩展性。
- YARN(Yet Another Resource Negotiator):是 Hadoop 2.0 版本后引入的更新,负责资源管理和作业调度。
- MapReduce:是一种基于 Java 编程语言的软件数据处理模型,由 Map(映射)和 Reduce(归约)两部分组成。 MapReduce 处理流程可以执行各种大数据操作,如数据过滤和排序等。
二、Hadoop HDFS Architecture(Hadoop HDFS架构)
HDFS(Hadoop Distributed File System,Hadoop 分布式文件系统)是 Hadoop 的数据存储系统。HDFS 将数据单元拆分为更小的单元,称为数据块(Blocks),并以分布式方式存储。HDFS 运行两个守护进程:主节点(NameNode)和从节点(DataNode)。
1、HDFS Core Components(HDFS 核心组件)
HDFS 由以下 3 个组件组成:
- NameNode:在内存(RAM)和磁盘上存储元数据。
- Secondary NameNode:在磁盘上存储 NameNode 的元数据副本。
- DataNode:以数据块的形式存储实际数据。
Client(客户端):客户端是一个充当服务提供者的客户端(如命令行或程序),它请求资源并向 Hadoop 集群发送请求。具体职责如下
- 文件共享:当文件上传到 HDFS 时,客户端会将文件拆分为多个数据块并存储到 DataNode 中。
- 与 NameNode 交互:获取文件位置信息。
- 与 DataNode交互:执行数据的读取或写入操作。
- 提供 HDFS 管理命令:如启动或关闭 HDFS,以及使用
start-all.sh命令启动集群。
NameNode 和 DataNode:
- NameNode(主节点):HDFS 的核心组件,负责存储元数据、监控从节点的运行状态,并向 DataNode 分配任务。
- DataNode(从节点):存储实际数据,并通过 心跳机制 向 NameNode 报告其运行状态和任务状态。如果 DataNode 未能响应NameNode,则该节点被视为失效,并由 NameNode 将任务重新分配给其他可用的 DataNode。
- Secondary NameNode(辅助NameNode):并不是 NameNode 的备份,而是充当缓存(Buffer),定期将 NameNode 的 **Edit-log(日志)**合并到 **FS-image(文件系统快照)**中,以减少 NameNode 的存储负担。

2、Block in HDFS(HDFS 数据块)
HDFS 是 Hadoop 的存储层,数据分布在多个服务器上。**数据块(Block)**是计算机系统中最小的存储单元。在 Hadoop 中,默认的数据块大小为 128MB。这些数据块会被随机分配并存储在不同的从节点(DataNode)上。HDFS 会将大规模数据拆分成多个 128MB 的数据块,并分布存储在多个机器上。

3、Replication Management(HDFS 复制管理)
HDFS 具有很高的容错能力,它采用**副本机制(Replication)**来处理故障,即同一份数据会在不同的 DataNode 上存储多个副本,以确保即使某个 DataNode 失效,数据仍然可以从其他节点读取。
为了提供容错能力,HDFS 使用复制技术,将数据块(Blocks)复制多份,并存储在不同的 DataNode 上。**副本因子(Replication Factor)**决定了每个数据块的副本数量,默认值为 3,但可以根据需求进行配置。
复制管理规则
- 同一个 DataNode 上不能存放相同的数据块。
- 在启用机架感知(Rack Awareness)模式时,同一数据块的所有副本不能存放在同一个机架(Rack)上。
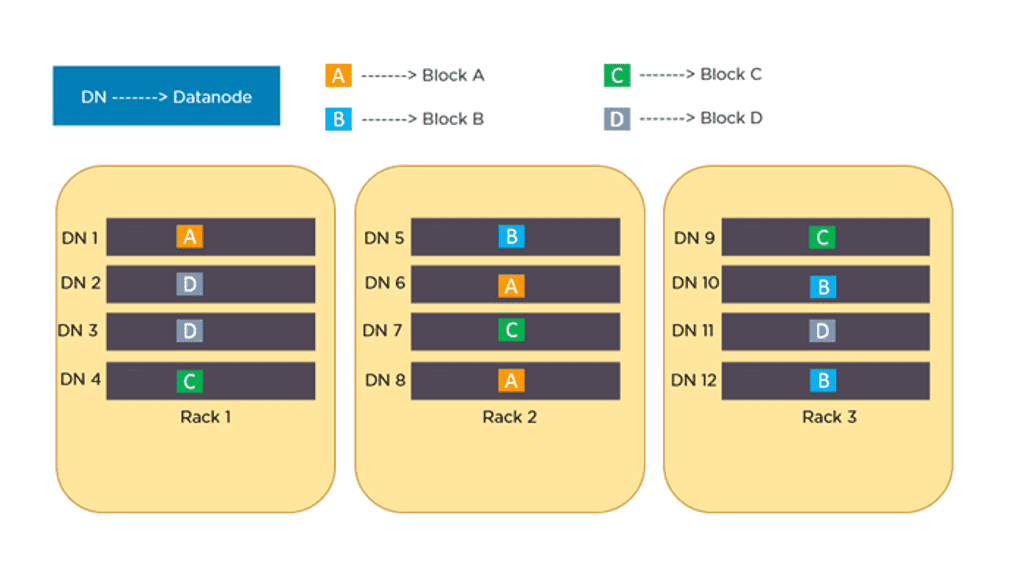
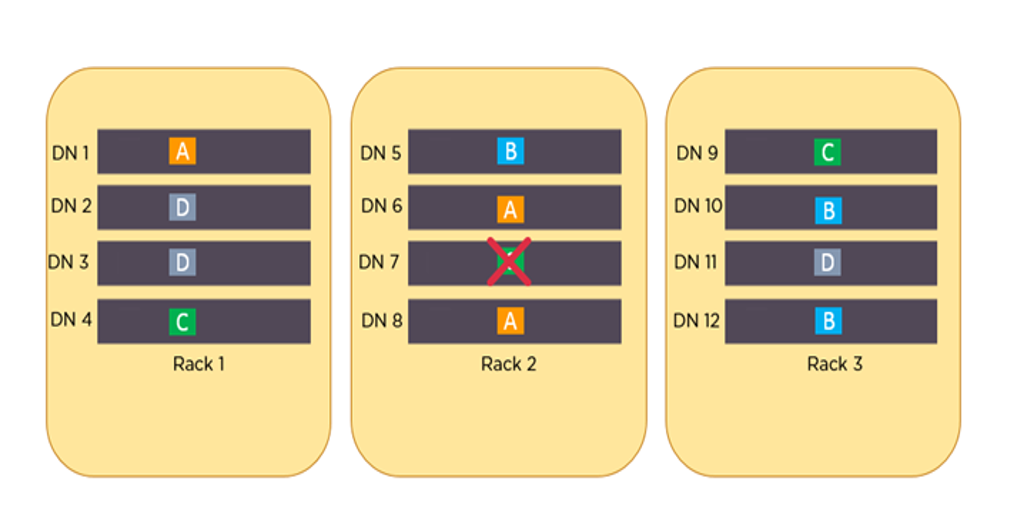
例如,假设数据块 A、B、C 和 D 被复制 3 次,并分布在不同的机架上。如果 DataNode 7 宕机,仍然可以从 Rack 1 的 DataNode 4 和 Rack 3 的 DataNode 9 访问数据块 C,从而确保数据的高可用性。
4、Advantages and Disadvantages of HDFS Architecture(HDFS 架构的优缺点)
优点
✔ 高容错性:数据会自动存储多个副本,丢失后可自动恢复,提高系统可靠性。
✔ 适合大数据处理:可处理 PB 级别数据,支持存储超过百万个文件。
✔ 支持流式数据读取:确保数据一致性,适用于大规模数据处理。
✔ 可部署在低成本硬件上:通过**多播机制(Multicast Mechanism)**提高可靠性,降低硬件成本。
缺点
✘ 不适用于低延迟数据访问:例如毫秒级存储需求的应用场景。
✘ 不适合存储大量小文件:小文件会占用大量 NameNode 内存,导致存储效率低下。小文件的查找时间可能超过读取时间,不符合 HDFS 的设计目标。
✘ 不支持并发写入和随机修改:
- 文件只能由一个线程写入,不支持多线程同时写入。
- 仅支持追加写入(Append),不支持随机修改文件内容。
三、Hadoop's YARN Architecture(Hadoop YARN 架构)
Hadoop YARN(Yet Another Resource Negotiator)是 Hadoop 的集群资源管理层,负责资源分配和作业调度。YARN 作为 Hadoop 2.0 版本引入的组件,是 Hadoop 体系结构中HDFS 和 MapReduce 之间的中间层。
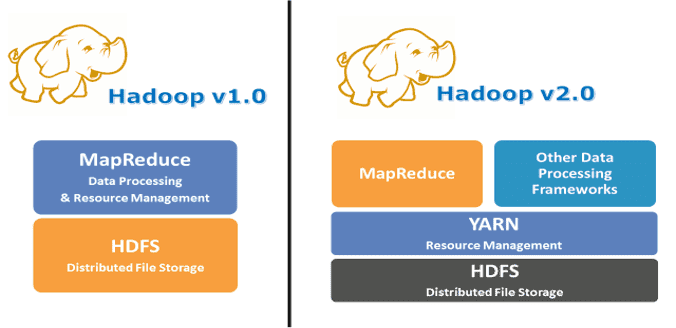
1、Why YARN?(为什么需要 YARN?)
在 Hadoop 1.0(MRV1,MapReduce Version 1)中,MapReduce 同时执行数据处理和资源管理的功能。
MRV1 架构的问题:
- Job Tracker 负责资源分配、调度和任务监控。它将 map 和 reduce 任务分派给多个下级进程,称为 Task Trackers。Task Trackers 会定期向 Job Tracker 报告进度。
- 这种设计由于只有一个 Job Tracker,因此在扩展性方面存在瓶颈。实际上,在拥有 5000 个节点、4 万个并发任务的集群上,这种架构就已经达到极限。
- 除了扩展性的问题外,MRV1 在计算资源的利用率方面也不高。同时,Hadoop 框架也被限制在只能运行 MapReduce 类型的任务。
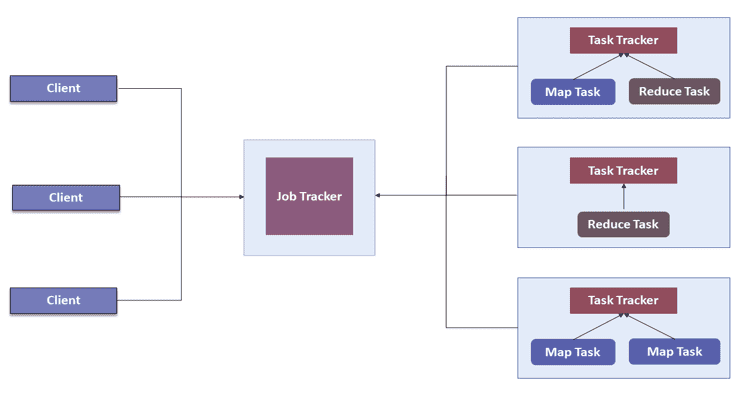
为了解决上述问题,在 Hadoop 2.0 中引入了 YARN。
YARN 的基本思想是将资源管理和作业调度的职责从 MapReduce 中分离出来。YARN 开始让 Hadoop 能够运行非 MapReduce 类型的作业。
2、YARN Core Components (YARN 核心组件)
YARN 包含以下几个关键组件:
- ResourceManager(资源管理器):每个集群一个
- ApplicationMaster(应用主控):每个应用一个
- NodeManagers(节点管理器):每个节点一个
- Container(容器)
YARN 的基本原理是将资源管理和作业调度/监控功能分离到不同的守护进程中:
NodeManager(NM):监控容器的资源使用情况(如 CPU、内存、磁盘、网络等),并定期向 ResourceManager 发送信号(前面提到过的心跳机制)。
ApplicationMaster(AM):管理单个应用的资源需求,与调度器交互以获取所需资源,并与 NodeManager 协作来执行和监控任务。
Container(容器):容器封装了一组资源(如内存、CPU 和网络带宽),YARN 根据资源情况进行分配。容器为应用分配使用特定资源的权限。
ResourceManager(RM):集群资源的总管,负责跟踪集群中所有可用资源及各个 NodeManager 的资源贡献情况。包含两个主要子组件:
- Scheduler(调度器):根据应用需求,为不同的运行中应用分配资源。这是一个“纯调度器”,不会监控应用状态,也不会重新调度因软硬件错误失败的任务。
- Application Manager(应用管理器):接收客户端提交的作业,并在 ApplicationMaster 失败时进行重启。
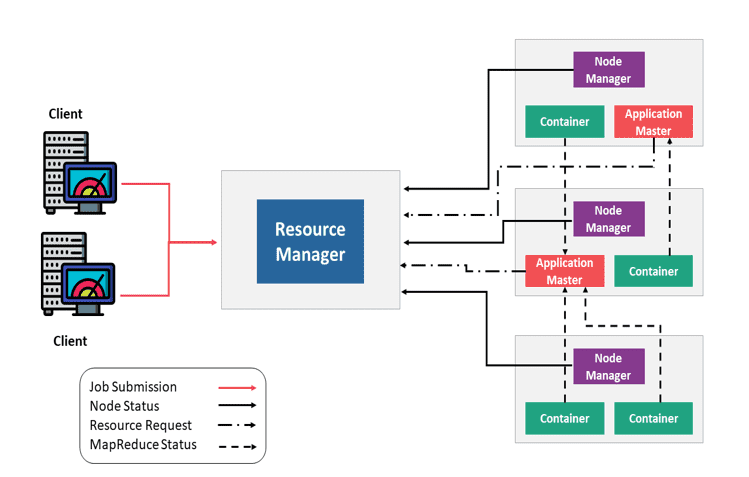
Hadoop YARN 的应用提交过程:
- 提交作业
- 获取 Application ID
- 创建 Application Submission Context(应用提交上下文)
- 启动容器启动流程
- 4a. 启动容器
- 4b. 启动 ApplicationMaster
- 分配资源
- 启动容器执行
- 6a. 创建容器
- 6b. 启动任务
- 执行应用
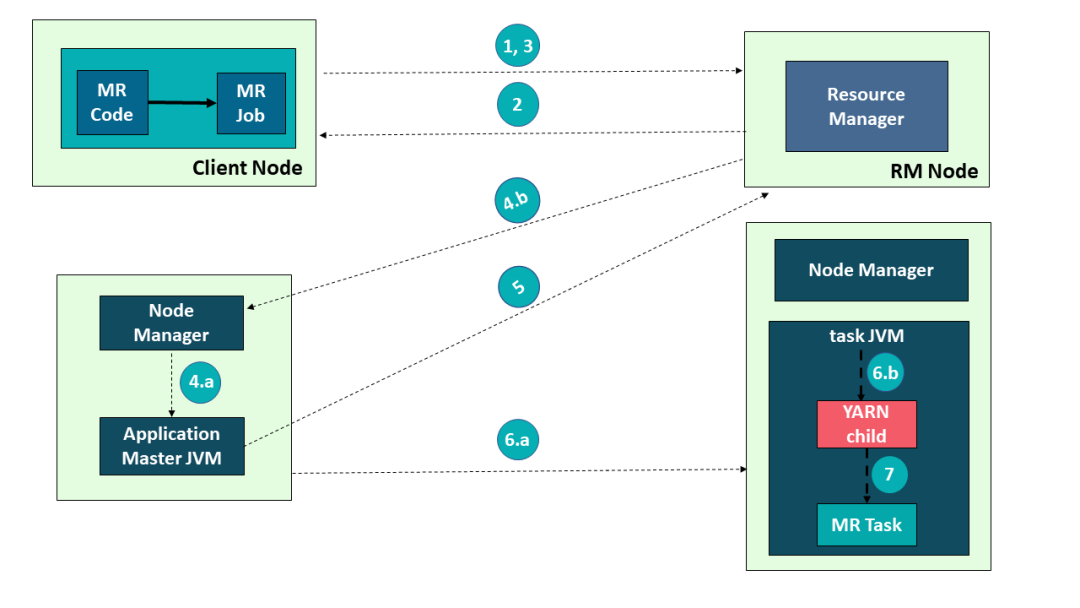
Hadoop YARN 中的应用执行流程
Apache Hadoop YARN 的应用执行涉及以下步骤:
- 客户端提交一个应用程序
- ResourceManager 分配一个容器来启动 ApplicationMaster
- ApplicationMaster 向 ResourceManager 注册
- ApplicationMaster 向 ResourceManager 请求更多容器资源
- ApplicationMaster 通知 NodeManager 启动容器
- 应用程序代码在容器中执行
- 客户端通过 ResourceManager 或 ApplicationMaster 来监控应用程序状态
- 应用程序完成后,ApplicationMaster 向 ResourceManager 注销
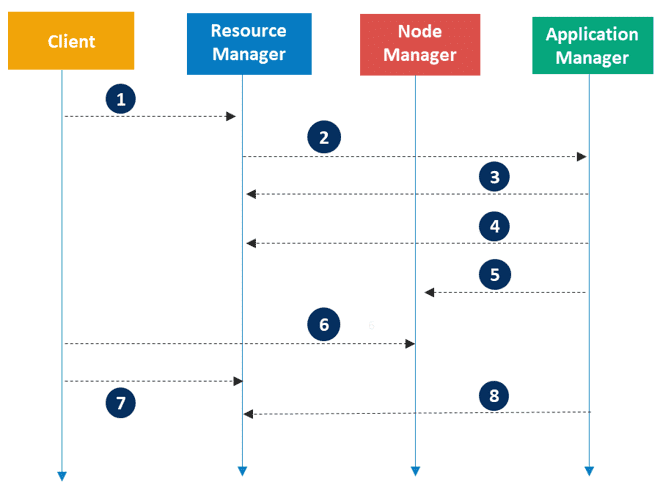
四、Hadoop's MapReduce Architecture(Hadoop 的 MapReduce 架构)
MapReduce 是 Hadoop 的处理层,它是一种编程模型,设计用于通过将工作划分为一组独立任务来并行处理海量数据。
你只需将业务逻辑嵌入 MapReduce 的工作方式中,其他的事务由框架自动完成。用户将一个完整的作业提交给主节点,主节点再将其分解为若干小任务并分发给从属节点执行。
1、Traditional Way for parallel and distributed processing(传统的并行和分布式处理方式)
我们来了解一下在没有 MapReduce 框架之前,传统方式是如何进行并行和分布式处理的。
举个例子:假设我们有一个天气日志,记录了从 2000 年到 2015 年每天的平均气温。现在我们想要计算出每一年中气温最高的一天。
我们会将数据拆分成更小的部分或数据块,并将它们存储在不同的机器上。然后,我们会在各自的机器上找出其对应部分中气温最高的一天。最后,我们将每台机器返回的结果汇总,得出最终的输出。
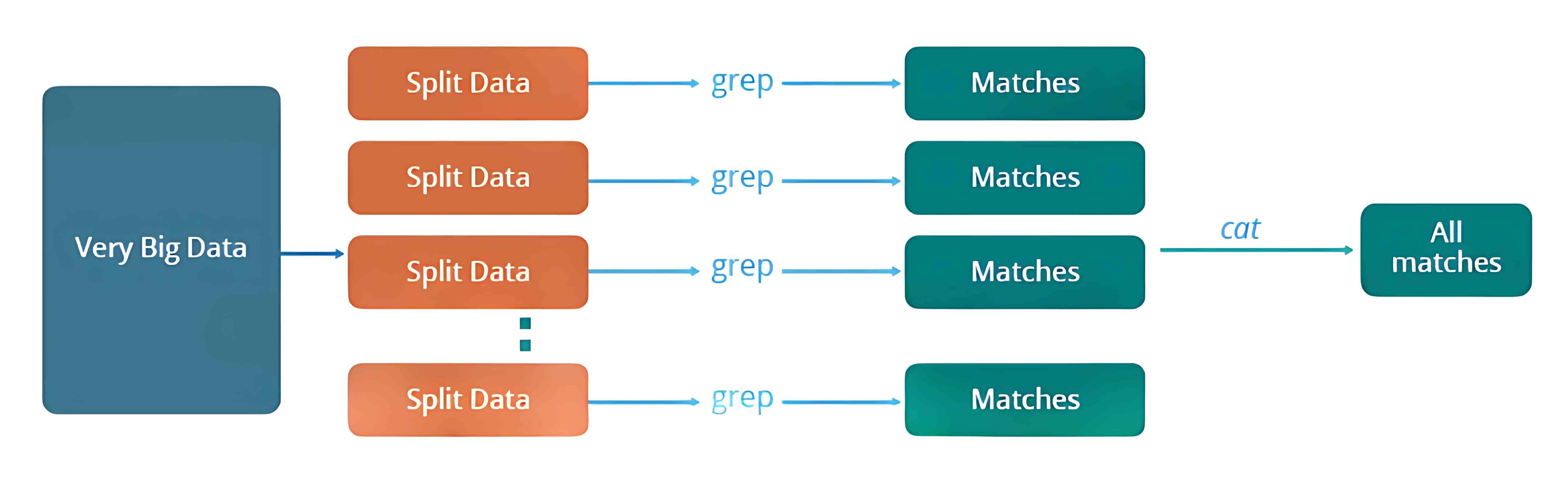
下面是这种传统方法所面临的一些问题:
- 关键路径问题:如果某台机器处理任务出现延迟,整个处理流程都会被拖延。
- 可靠性问题:如果某台正在处理部分数据的机器发生故障怎么办?
- 数据平均划分问题:如何将数据合理地拆分,使每台机器分到的任务量大致相等?
- 分块失败问题:如果某个数据块所在的机器未能返回结果,那就无法计算出最终结果。
- 结果汇总问题:需要有一种机制来将每台机器产生的中间结果进行汇总,得到最终结果。
为了解决这些问题,我们有了 MapReduce 框架。它允许我们执行这样的并行计算,而无需担心诸如可靠性、容错等系统设计问题。因此,MapReduce 为开发者提供了灵活性,可以只关注代码逻辑,而不必考虑底层系统的复杂性。
MapReduce 是一种编程框架,允许我们在分布式环境中对大规模数据集进行分布式和并行处理。MapReduce 由两个核心任务组成:Map 和 Reduce。
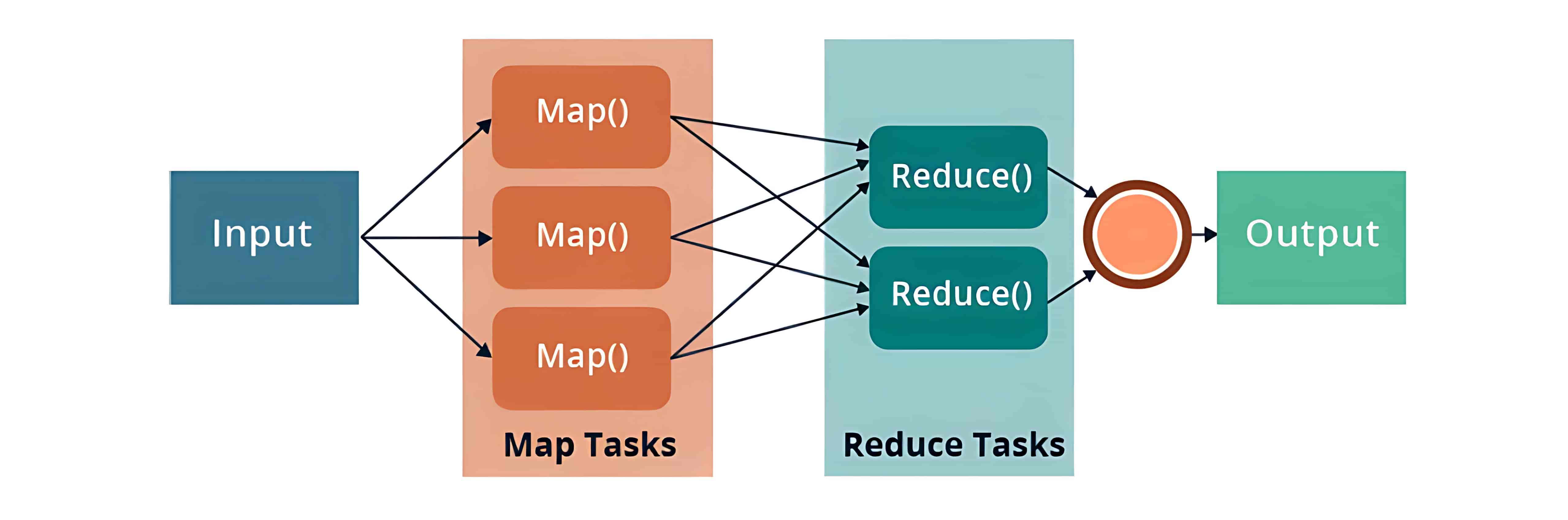
MapReduce 的优点:
- 把计算任务放到数据所在的地方执行,减少数据传输。
- 多个任务同时处理数据,提高处理速度。
2、MapReduce Components(MapReduce 组件)
MapReduce 模型包括三个主要阶段:
- Mapper(映射器):首先是 Map 任务,即将分布在多个数据节点上的多个数据块进行读取和处理。Mapper 函数接受的输入是键值对形式 (k, v),其中键 k 表示每条记录的偏移地址,值 v 表示整个记录的内容。Mapper 阶段的输出同样是键值对形式,记作 (k’, v’)。
- Shuffle 和 Sort(洗牌与排序):各个 Mapper 的输出 (k’, v’) 会进入 Shuffle 和 Sort 阶段。在这个阶段,会去除重复的值,并根据相同的键对不同的值进行分组。该阶段的输出仍然是键值对形式,表现为键与值数组的组合 (k, v[])。
- Reducer(归约器):Reducer 接收来自多个 Map 任务的键值对。然后,它将这些中间数据元组(即中间键值对)进行聚合,最终生成一组更小的键值对作为最终结果,并写入 HDFS 的输出目录中的一个文件中。
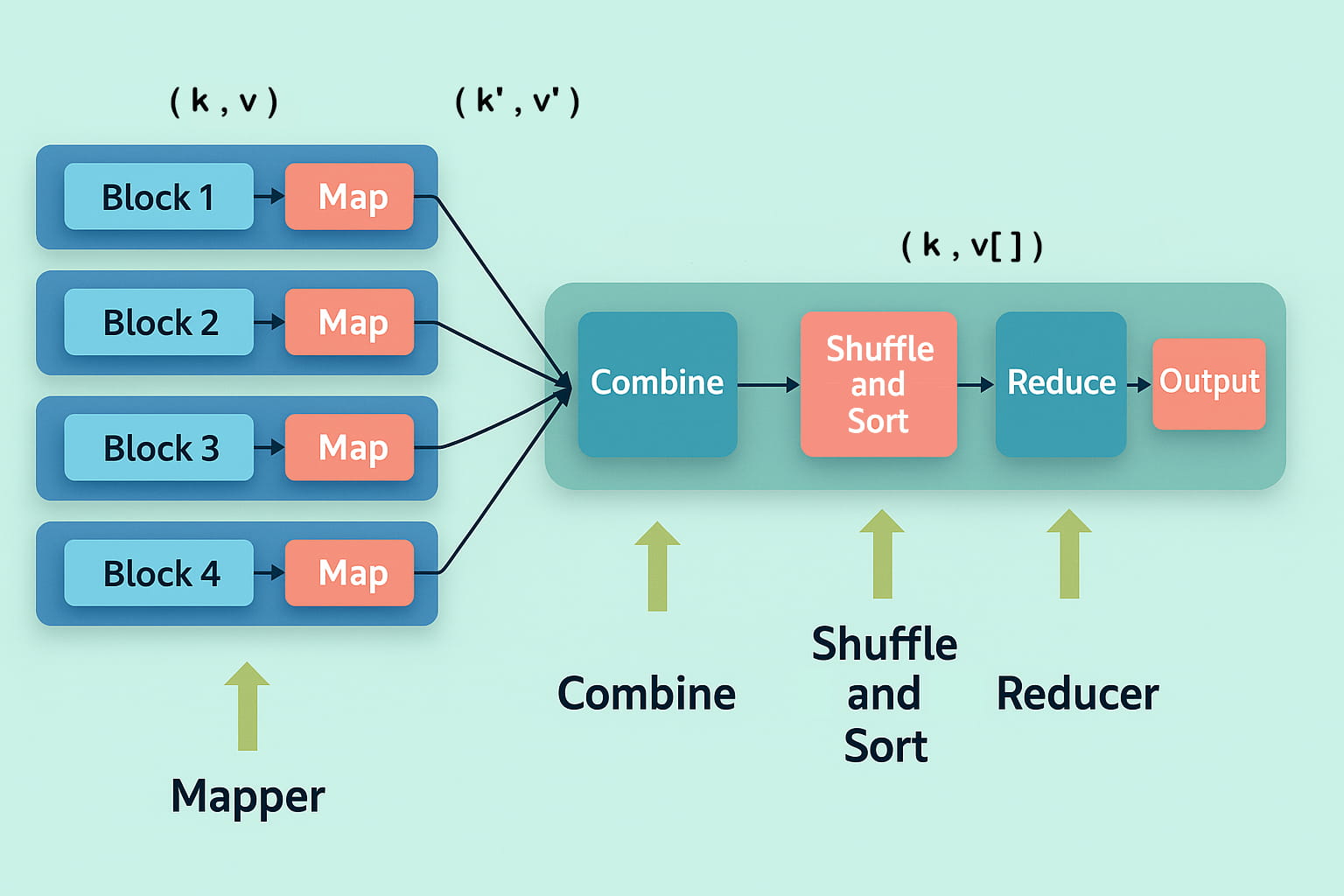
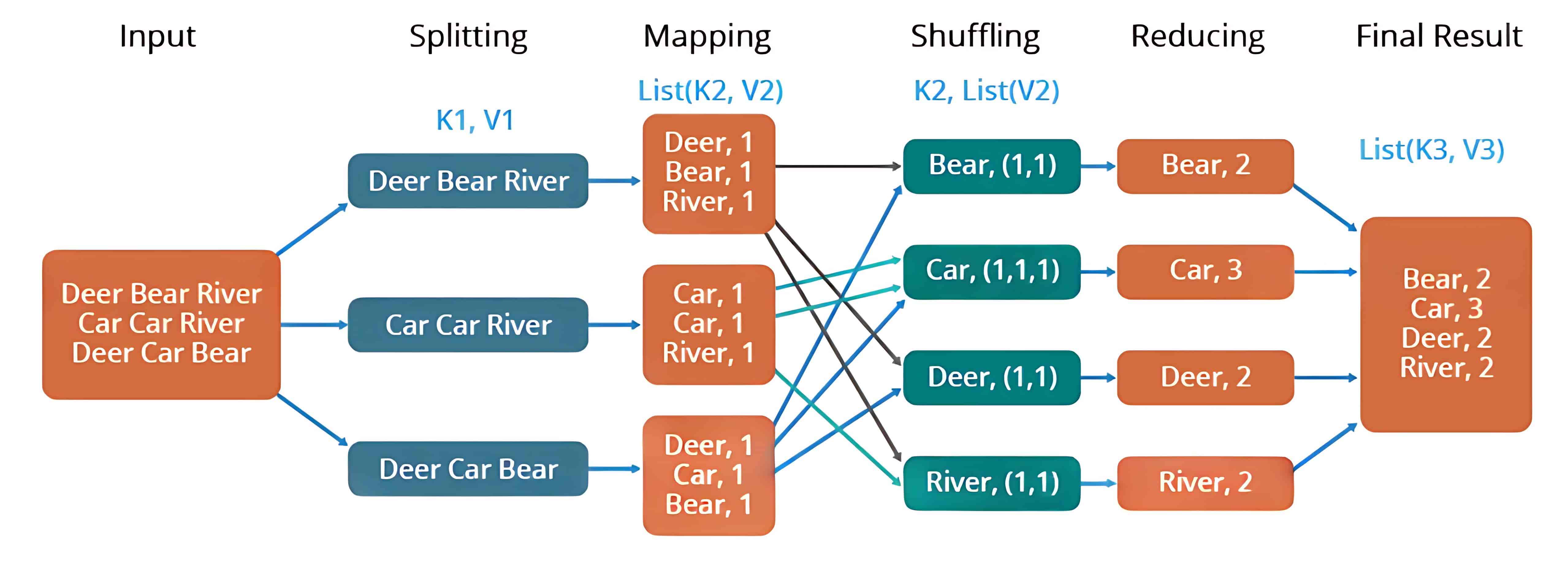
示例:比如统计一组文本文件中每个单词出现的次数,整个过程可以理解为如下所示:
Chapter 4:HDFS Distributed File System(HDFS 分布式文件系统)
一、Introduction of Hadoop Shell Commands(Hadoop Shell 命令简介)
Hadoop 分布式文件系统(HDFS)是一种分布式文件系统,基于“一次写入,多次读取”的理念,具有高容错性和高吞吐量。DataNode 负责处理来自文件系统客户端的读写请求。
HDFS 拥有自己的 shell 命令来管理 HDFS 上的文件。且文件的内容无法通过 Linux 命令识别。
1、Top Hadoop Shell Commands(常用的 Hadoop Shell 命令)
HDFS 是通过一组 Shell 命令来访问的,借助这些命令,我们可以执行 HDFS 文件操作,例如移动文件、删除文件、更改文件权限、设置副本因子、更改文件所有权等。

Hadoop 基本命令:查看和创建文件及目录:
| 命令语法 | 示例 | 功能说明 |
|---|---|---|
| hdfs dfs -ls | hdfs dfs -ls / | 列出指定路径下的所有文件和目录。使用 -lsr 进行递归列出,适用于查看目录层级结构。 |
| hdfs dfs -mkdir | hdfs dfs -mkdir /Ezekielx | 创建一个新目录。Hadoop 默认没有用户主目录,因此需要手动创建。 |
| hdfs dfs -touchz | hdfs dfs -touchz /Ezekielx/file.txt | 创建一个空文件(zero-length)。如果文件不存在,则创建;存在则更新访问和修改时间戳。 |
| hdfs dfs -touch | hdfs dfs -touch /Ezekielx/file.txt | 同上,与 touchz 类似,也用于创建空文件并更新时间戳。 |
| hdfs dfs -cat | hdfs dfs -cat /Ezekielx/file.txt | 打印文件内容到标准输出,相当于“读取”文件。 |
| hdfs fs -tail [-f] | hdfs fs -tail /Ezekielx | 输出文件最后 1KB 内容,-f 可用于持续追踪文件更新(类似 Linux 的 tail -f)。 |
| hdfs fs -test -[ezd] | hdfs fs -test -e /Ezekielx/file.txt | 测试文件或目录状态: - -e:判断是否存在; - -z:是否为空文件; - -d:是否为目录。返回 0 表示真,1 表示假。 |
| hdfs fs -text | hdfs fs -text /Ezekielx/file.txt | 将文件内容以文本形式输出,仅支持某些压缩格式(如 zip、TextRecordInputStream)。 |
计数和大小命令:查看目录或文件的总数及其大小。
| 命令语法 | 示例 | 功能说明 |
|---|---|---|
| hdfs dfs -count | hdfs dfs -count /Ezekielx | 统计 HDFS 上目录数量、文件数量及文件大小。 |
| hdfs dfs -du | hdfs dfs -du /Ezekielx | 显示目录中每个文件的大小。 |
| hdfs dfs -dus | hdfs dfs -dus /Ezekielx | 显示目录或文件的总大小。 |
| hadoop fs -du hdfs://master:54310/hbase | hadoop fs -du hdfs://master:54310/hbase | 查看指定路径下所有 hbase 文件的大小。 |
复制和移动命令
| 命令语法 | 示例 | 功能说明 |
|---|---|---|
| hdfs dfs -put | hdfs dfs -put /tools/file.txt /Ezekielx | 从本地磁盘复制文件/文件夹到 HDFS。指定本地路径和 HDFS 目标路径。 |
| hdfs dfs -copyFromLocal | hdfs dfs -copyFromLocal /tools/file.txt /Ezekielx | 同 put 命令,从本地文件系统复制文件/文件夹到 HDFS。 |
| hdfs dfs -copyToLocal | hdfs dfs -copyToLocal /Ezekielx /tools/hero | 从 HDFS 复制文件/文件夹到本地文件系统。 |
| hdfs dfs -moveFromLocal | hdfs dfs -moveFromLocal /tools/file.txt /Ezekielx | 将本地文件移动到 HDFS,移动后本地文件删除。 |
| hdfs dfs -cp | hdfs dfs -cp /Ezekielx /Ezekielx_copied | 在 HDFS 内部复制文件。 |
| hadoop fs -getmerge [addnl] | — | 将源目录内所有文件合并成一个文件并复制到本地。可选参数 addnl 表示每个文件末尾添加换行符。 |
删除命令
| 命令语法 | 示例 | 功能说明 |
|---|---|---|
| hdfs dfs -rmr | hdfs dfs -rmr /Ezekielx_copied | 递归删除 HDFS 中的文件或目录,适用于删除非空目录,会先删除目录内所有内容,然后删除目录本身。 |
| hdfs dfs -rm | hdfs dfs -rm /Ezekielx/file.txt | 删除 HDFS 中的文件或目录。 |
| hdfs dfs -rmdir | hdfs dfs -rmdir /Ezekielx | 删除空目录,仅当目录为空时才能删除。 |
| hdfs fs -expunge | — | 清空回收站,永久删除已删除文件。 |
二、HDFS Read and Write Architecture(HDFS 读写架构)
HDFS 遵循“只写一次,多次读取”的理念。我们来看一下在 HDFS 上是如何执行数据的读写操作的。因此,HDFS 中已存储的文件无法被编辑,但可以通过重新打开文件来追加新数据。
1、HDFS Write Architecture(HDFS 写入架构)
要向 HDFS 写入数据,客户端首先会与 NameNode 交互,以获取写入数据的权限,并获得用于写入数据的 DataNode 的 IP 地址。
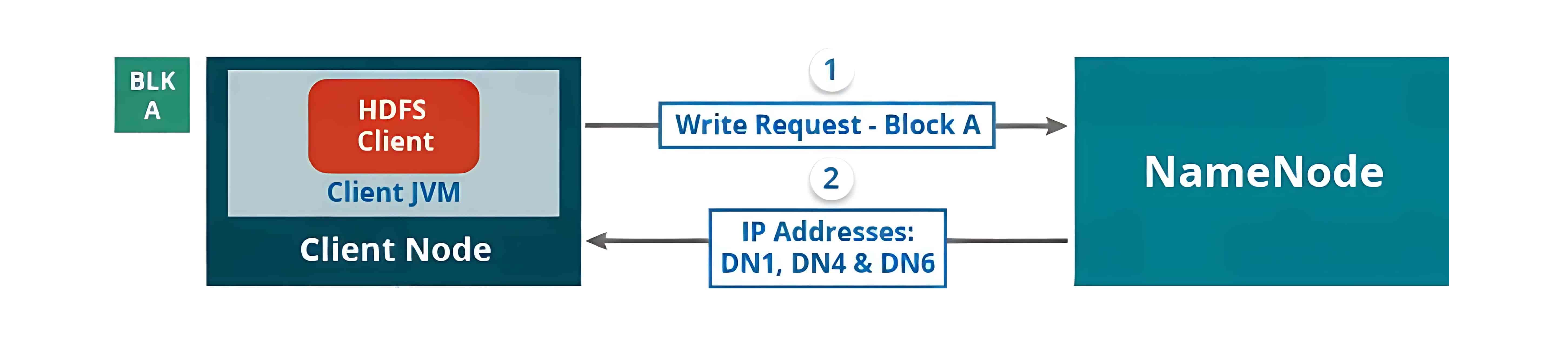
随后,客户端会直接与 DataNode 交互以写入数据。DataNode 根据副本因子(replication factor),将数据块复制到管道中的其他 DataNode。如果副本因子为 3,那么在不同的 DataNode 上至少会创建 3 个数据块副本。
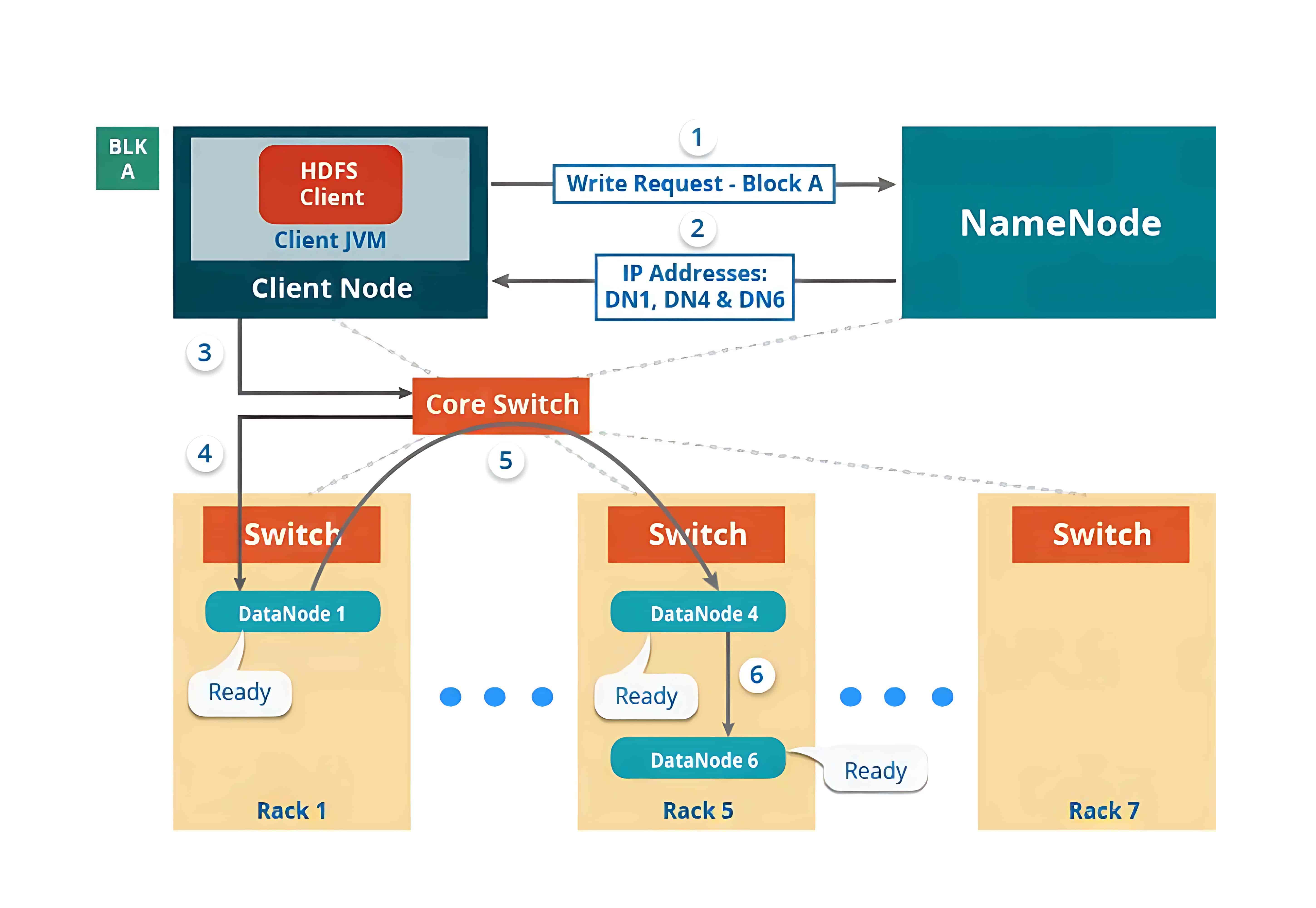
在创建完所需的副本之后,系统会向客户端发送确认信息。这样就在集群中形成了一个数据写入的管道,并将数据复制到设定的副本数量。
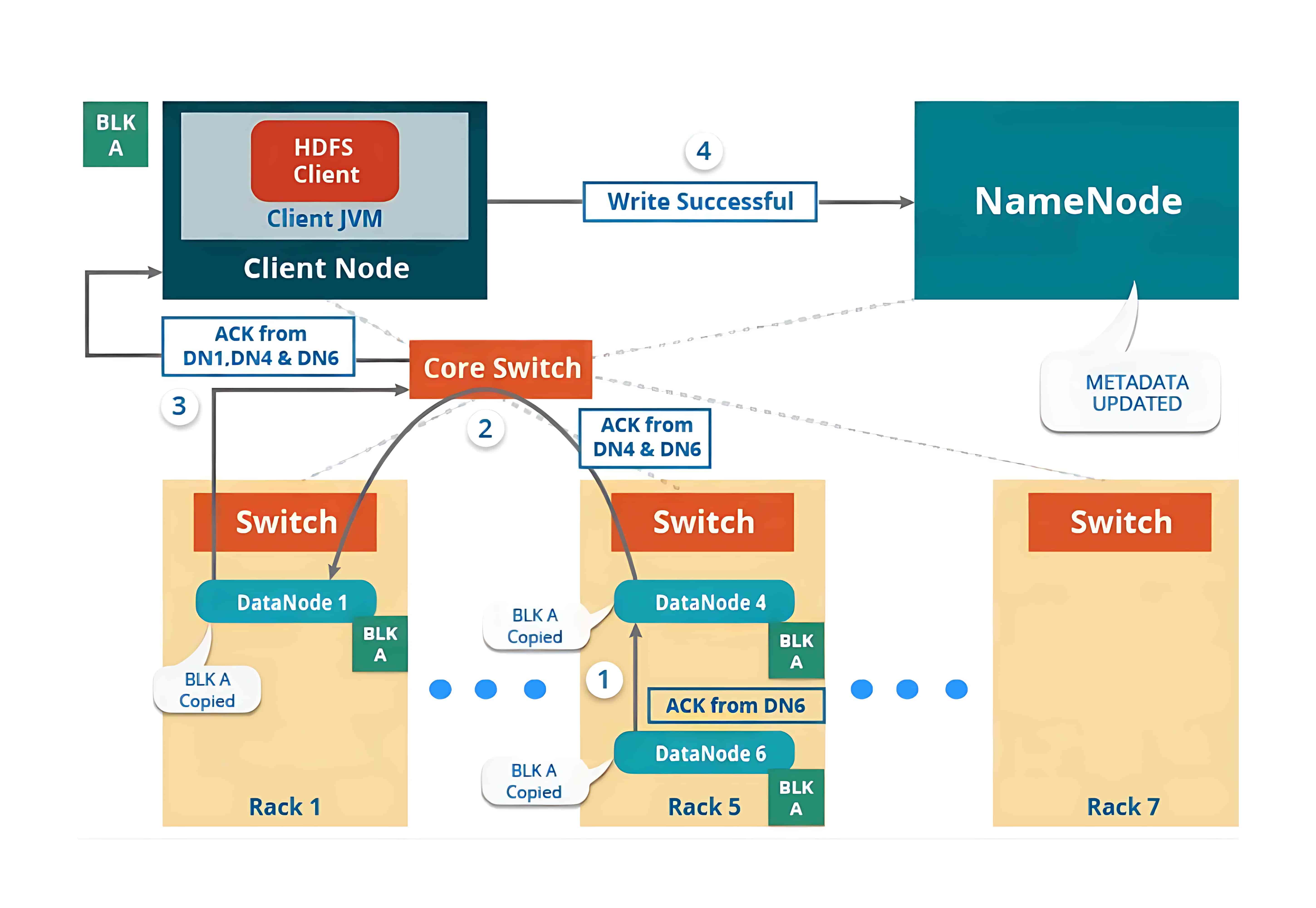
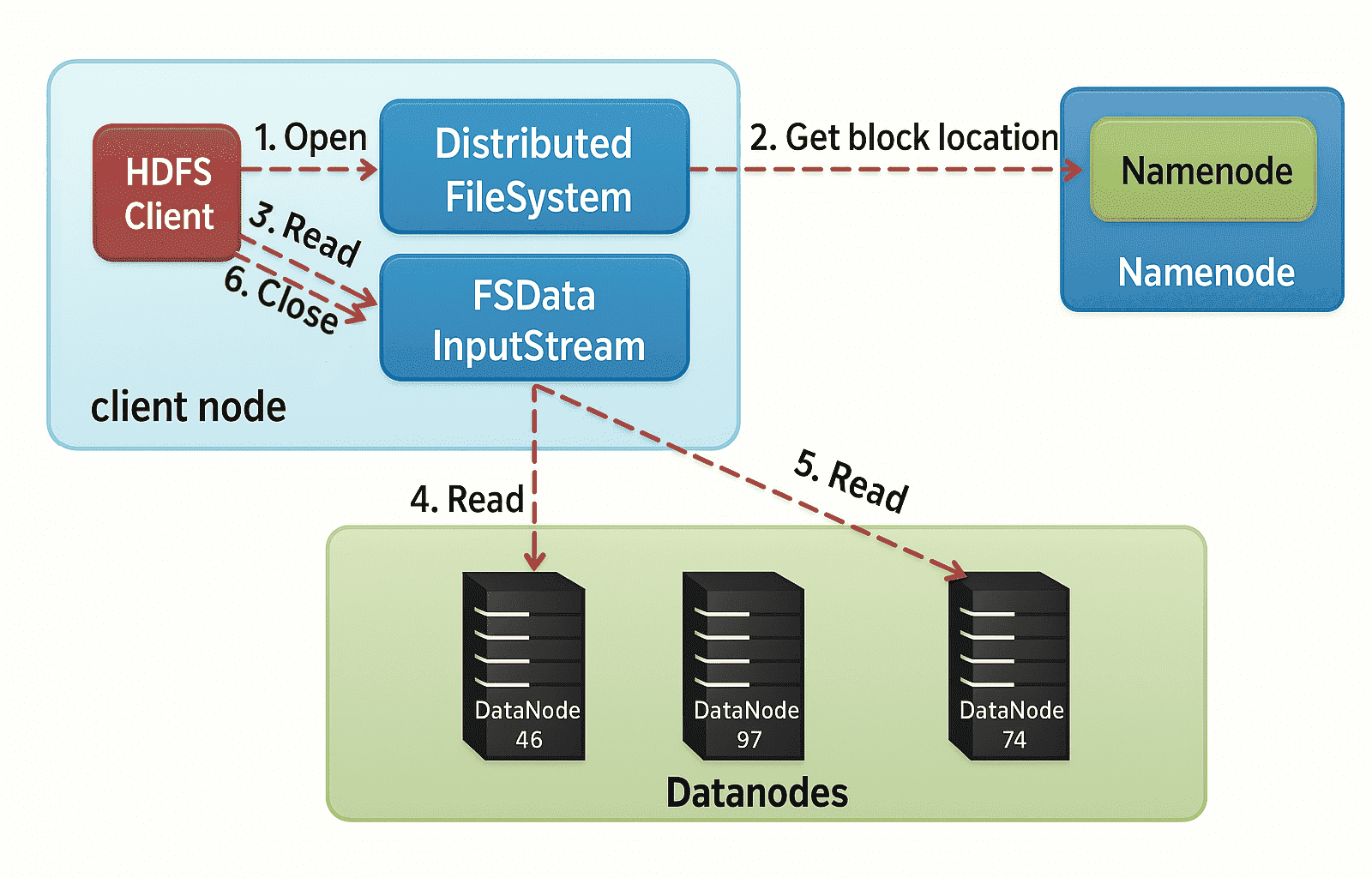
2、HDFS Read Architecture(HDFS 读取架构)
HDFS 的读取架构相对来说比较容易理解。我们继续以上面的例子,即 HDFS 客户端想要读取一个文件的情况。读取文件时将会发生以下几个步骤:
- 客户端会向 NameNode 请求该文件的块(Block)元数据信息;
- NameNode 会返回存储该文件各个数据块(如 Block A 和 Block B)所在的 DataNode 列表;
- 然后客户端会连接到这些存储块的 DataNode;
- 客户端会并行地从这些 DataNode 中读取数据(比如从 DataNode1 读取 Block A,从 DataNode3 读取 Block B);
- 当客户端获取到所有所需的数据块后,会将这些块组合起来还原成完整的文件。
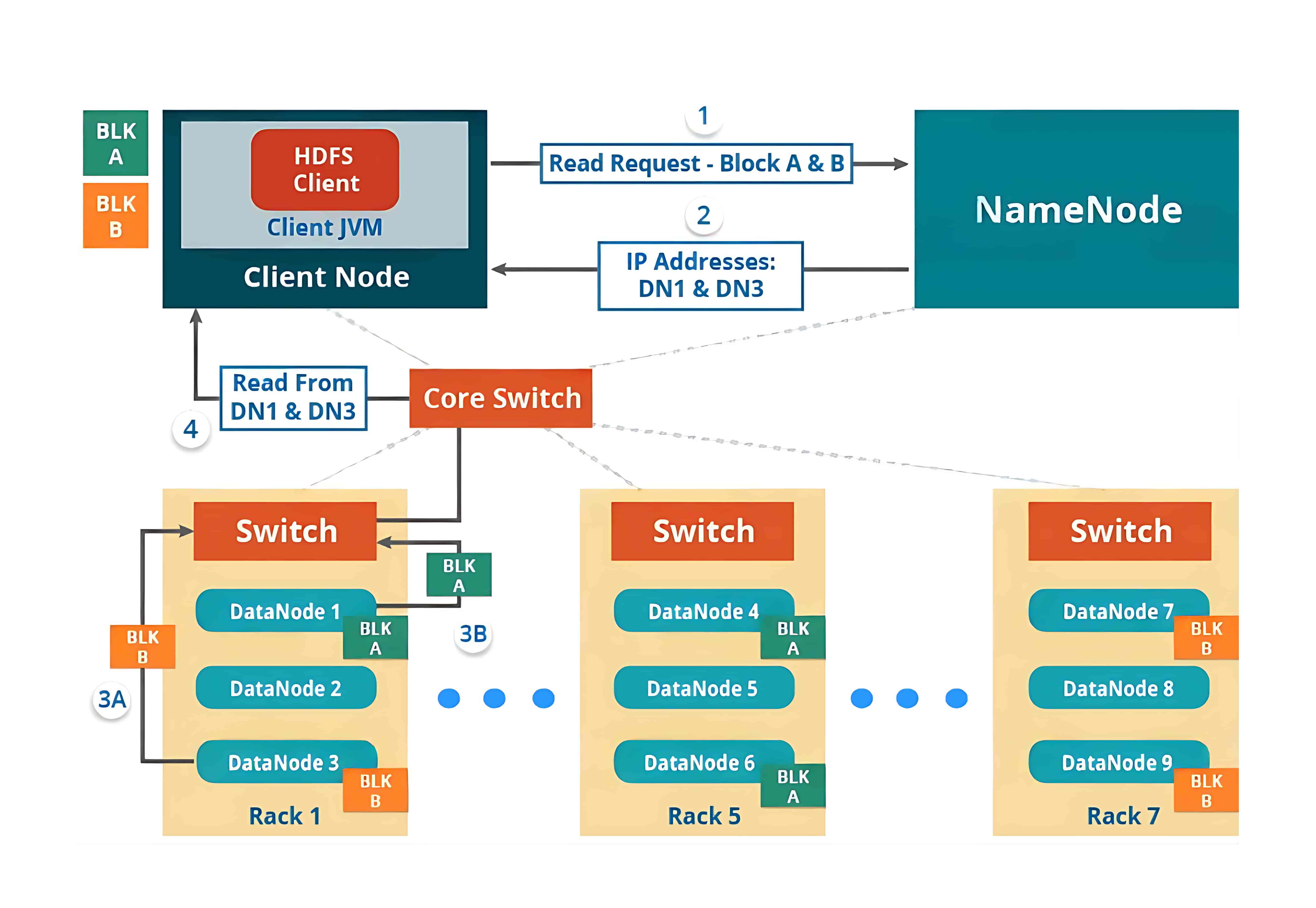
在处理客户端的读取请求时,HDFS 会选择距离客户端最近的副本。这样可以减少读取延迟和带宽消耗。
三、JAVA Application Interface HDFS Operations(Java 应用程序接口的 HDFS 操作)
1、添加依赖
打开 IDEA,选择构建一个 Maven 项目。
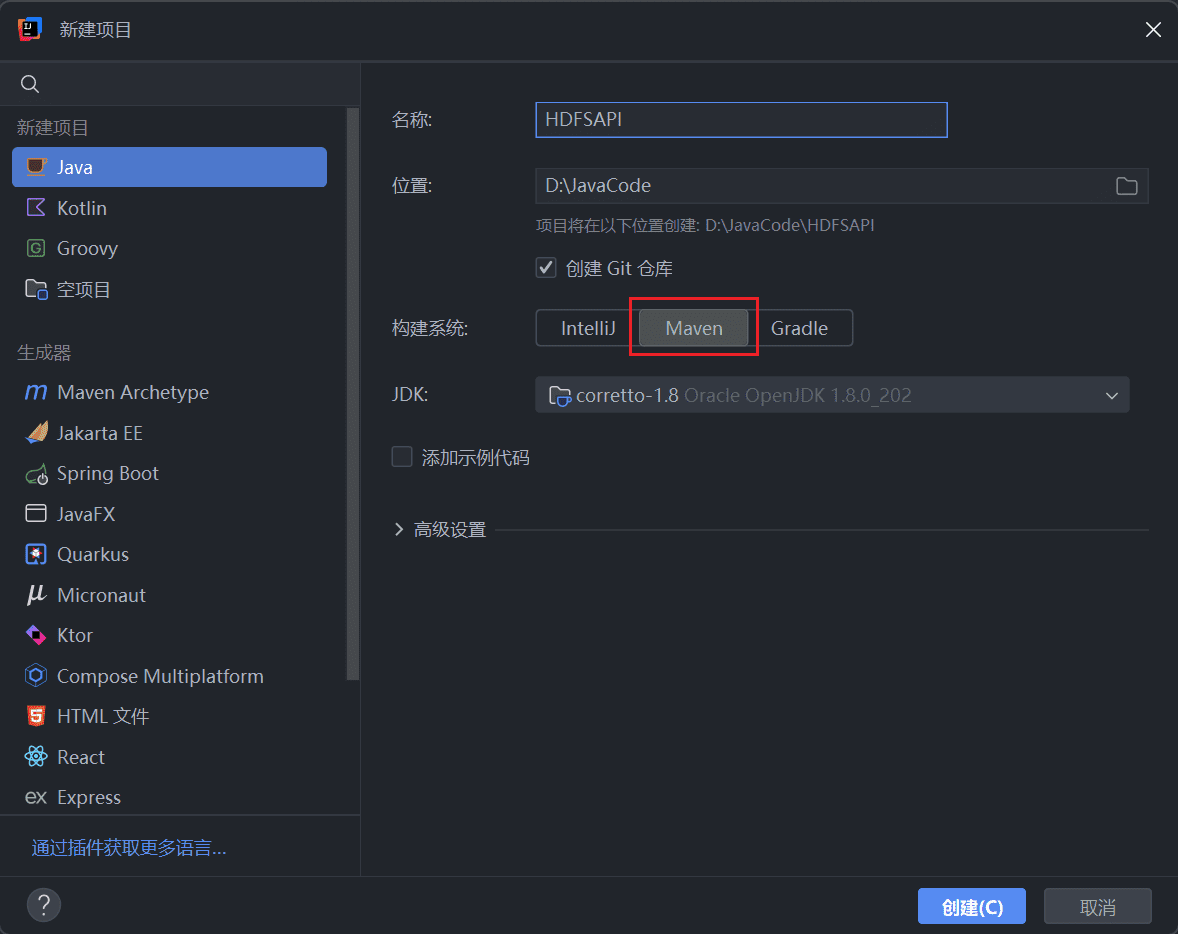
进入 maven 官方官网,分别搜索 hadoop-common、hadoop-hdfs,选择对应的 Hbase 版本,将依赖配置复制下来。
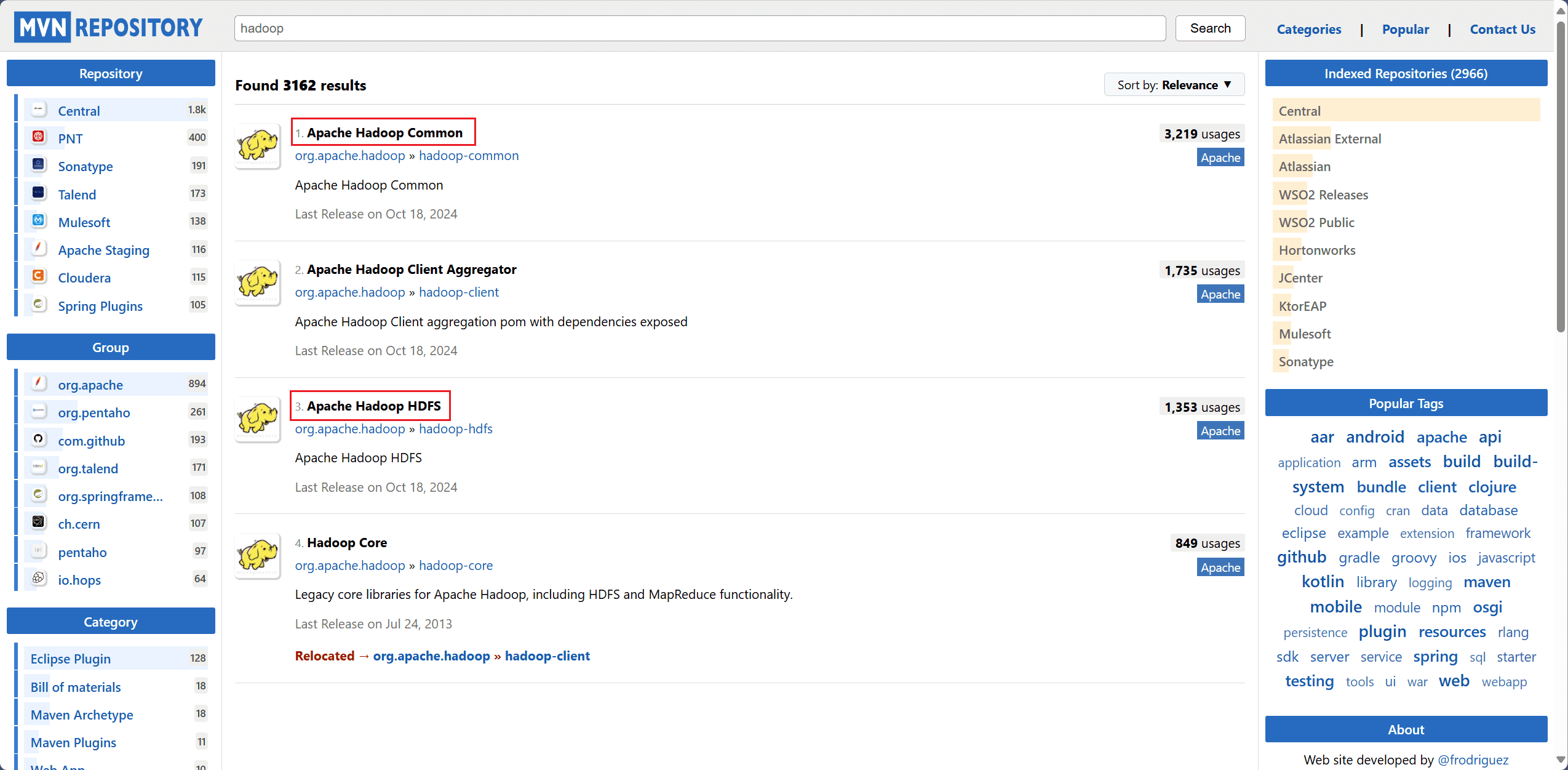
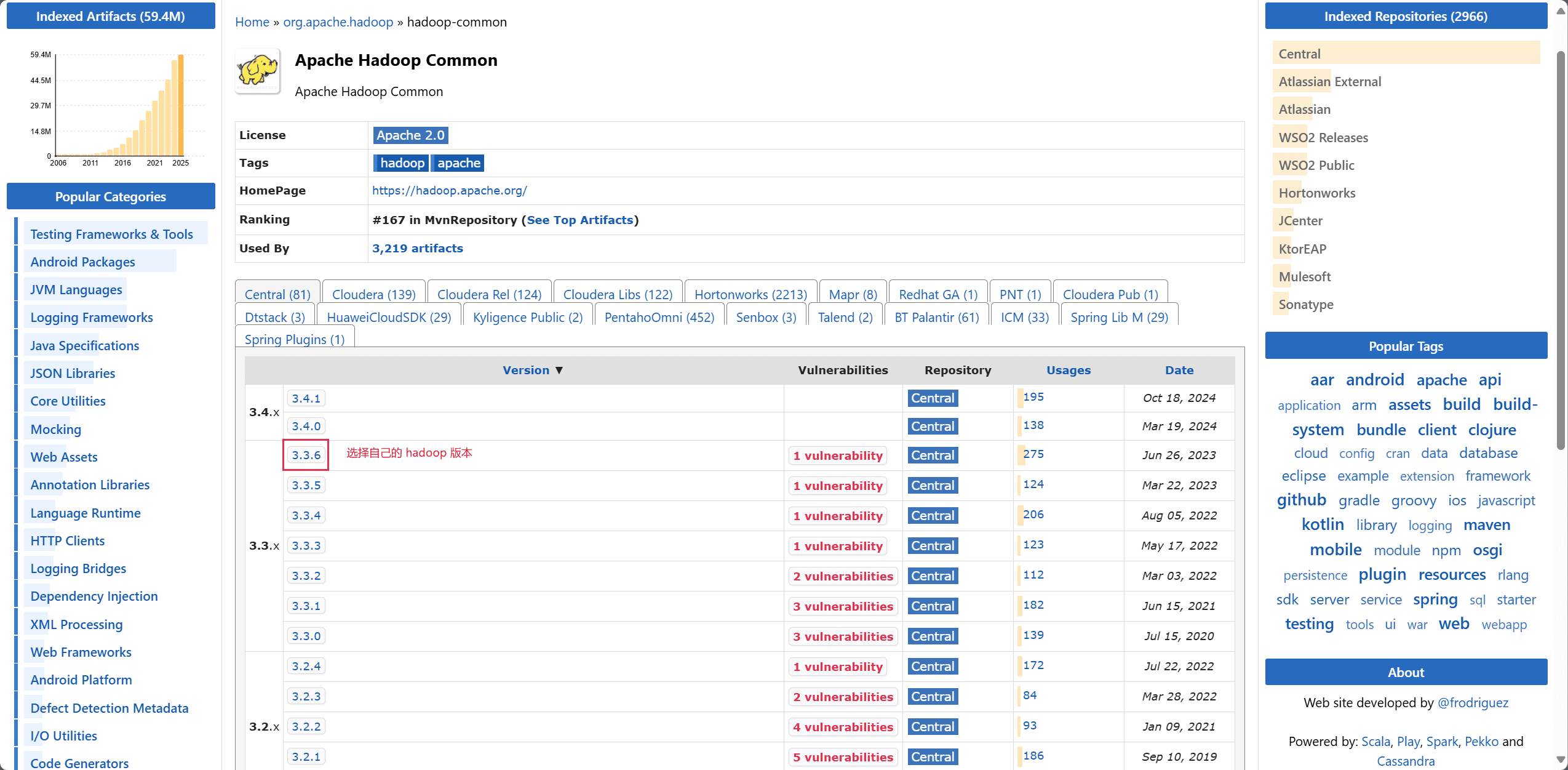
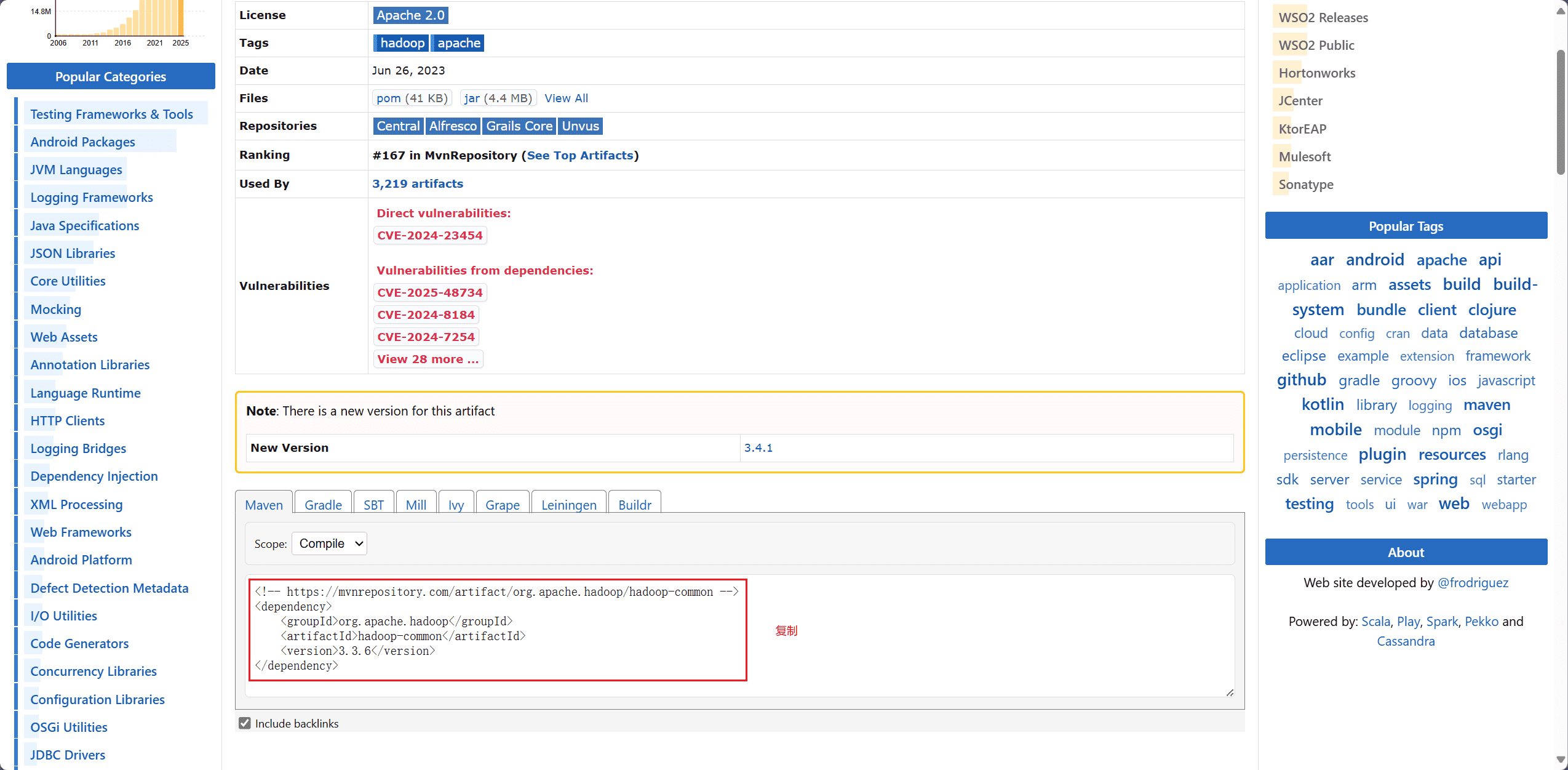
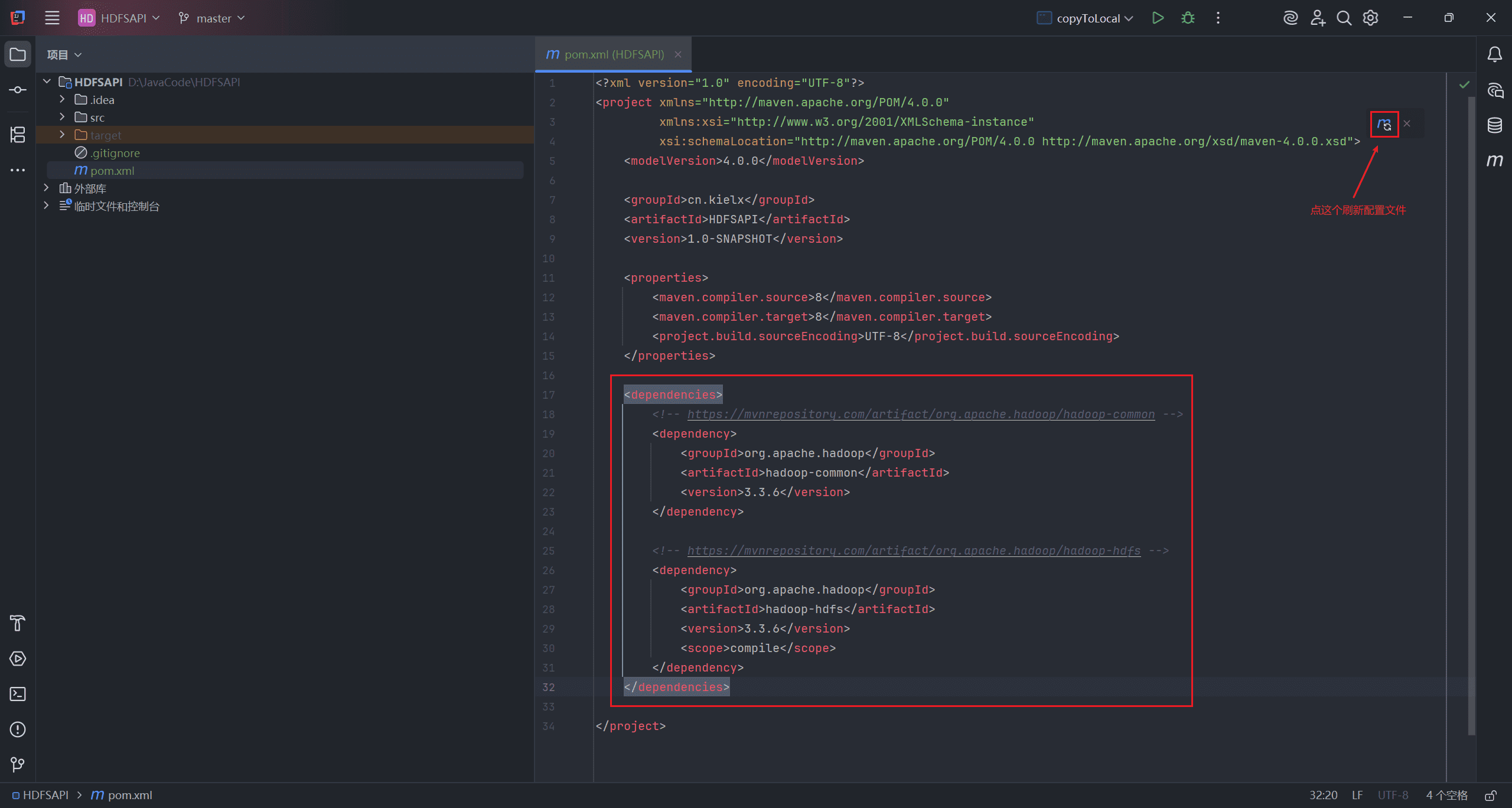
创建 <dependencies> 标签,将复制的配置粘贴进去,刷新配置文件。
Hadoop 中的文件操作类基本上都位于 org.apache.hadoop.fs 包中。这些 API 支持的操作包括:打开文件、读写文件、删除文件等。
Hadoop 类库中面向用户的接口类是 FileSystem,它是一个抽象类,不能直接实例化。只能通过调用它的静态 get 方法并传入相关参数来获取具体的实现类实例。比如 DistributedFileSystem 就是 FileSystem 用于操作 HDFS 的实现类。
例如:FileSystem.get(new URI uri, Configuration conf)。
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.hdfs.DistributedFileSystem;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
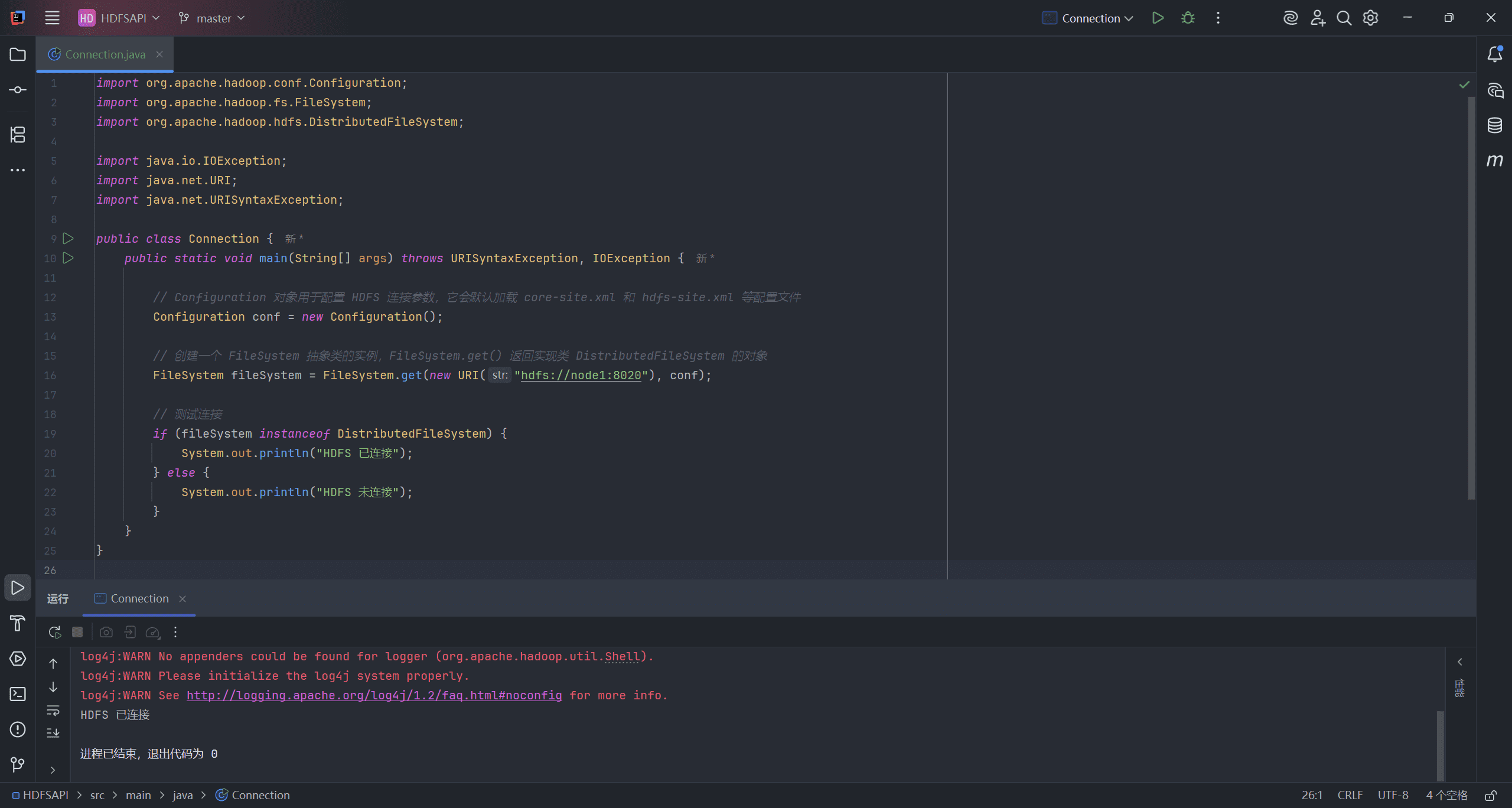
public class Connection {
public static void main(String[] args) throws URISyntaxException, IOException {
// Configuration 对象用于配置 HDFS 连接参数,它会默认加载 core-site.xml 和 hdfs-site.xml 等配置文件
Configuration conf = new Configuration();
// 创建一个 FileSystem 抽象类的实例,FileSystem.get() 返回实现类 DistributedFileSystem 的对象
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:8020"), conf);
// 测试连接
if (fileSystem instanceof DistributedFileSystem) {
System.out.println("HDFS 已连接");
} else {
System.out.println("HDFS 未连接");
}
}
}
2、Client File Writing Operation(客户端文件写入操作)
客户端写入文件的过程:
-
HDFS 客户端通过 DistributedFileSystem APIs 发送创建请求。
-
DistributedFileSystem 会通过远程过程调用向 NameNode 发送请求,在文件系统的命名空间中创建一个新文件。
例如:
public FSDataOutputStream create(Path f, Progressable progress)。 -
DistributedFileSystem 会返回一个
FSDataOutputStream对象,供客户端开始写入数据。当客户端写入数据时,DFSOutputStream会将数据分割成若干数据包,并将它们写入一个内部队列,该队列称为数据队列。
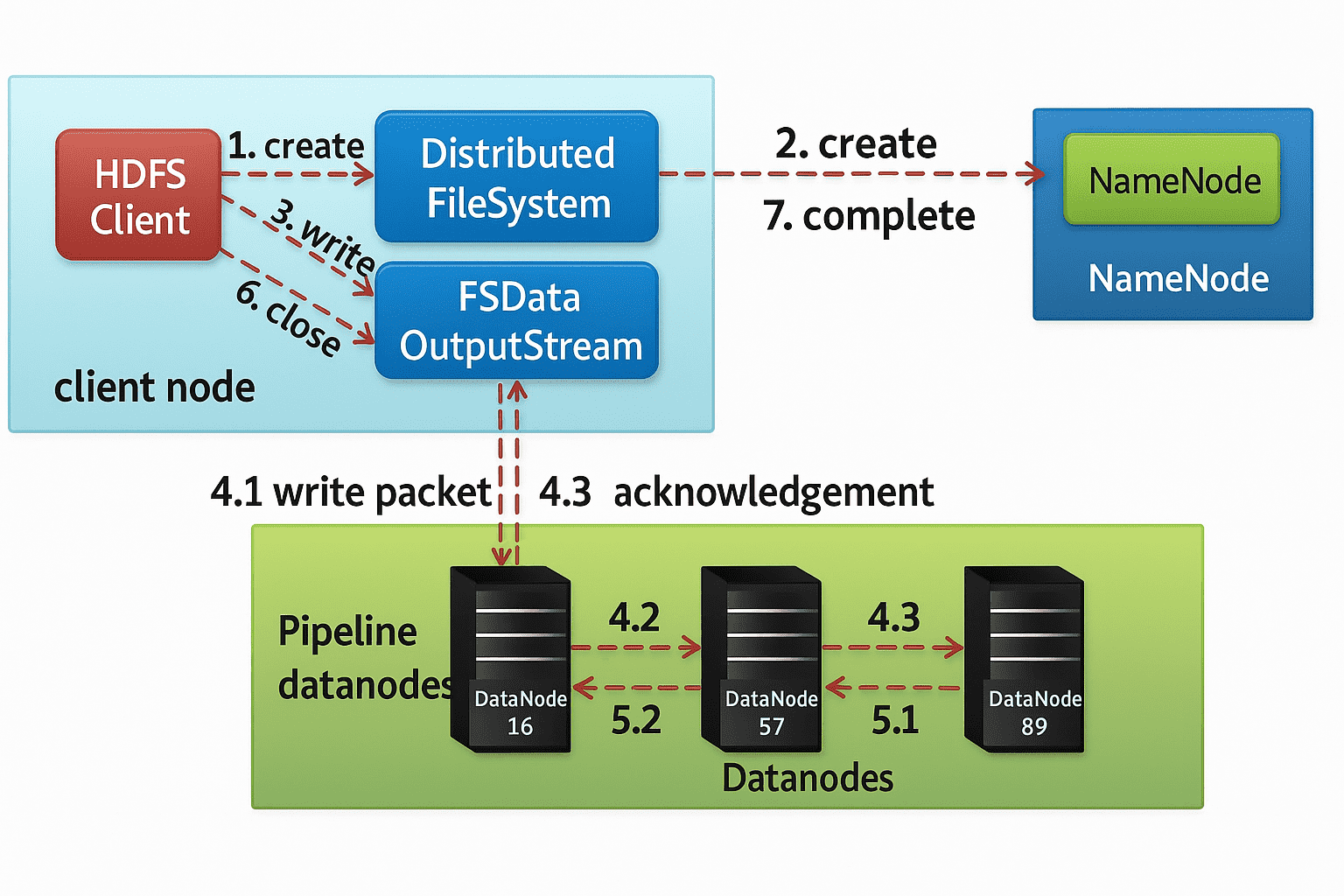
- DataNode 列表组成一个数据传输的流水线(pipeline),这里我们假设副本因子(replication level)为 3,因此流水线中会有三个节点。DataStreamer 会将数据包(packet)传输到流水线中的第一个 DataNode,该节点在存储数据包的同时,会将其转发给流水线中的第二个 DataNode。同样地,第二个 DataNode 也会存储数据包,并将其转发给流水线中的第三个(也是最后一个)DataNode。
- DFSOutputStream 还维护了一个内部队列,用于保存那些正在等待各个 DataNode 确认(acknowledge)的数据包,该队列被称为 ack 队列(ack queue)。
- 当客户端完成数据写入后,会调用流的 close() 方法。
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import java.io.*;
import java.net.URI;
import java.net.URISyntaxException;
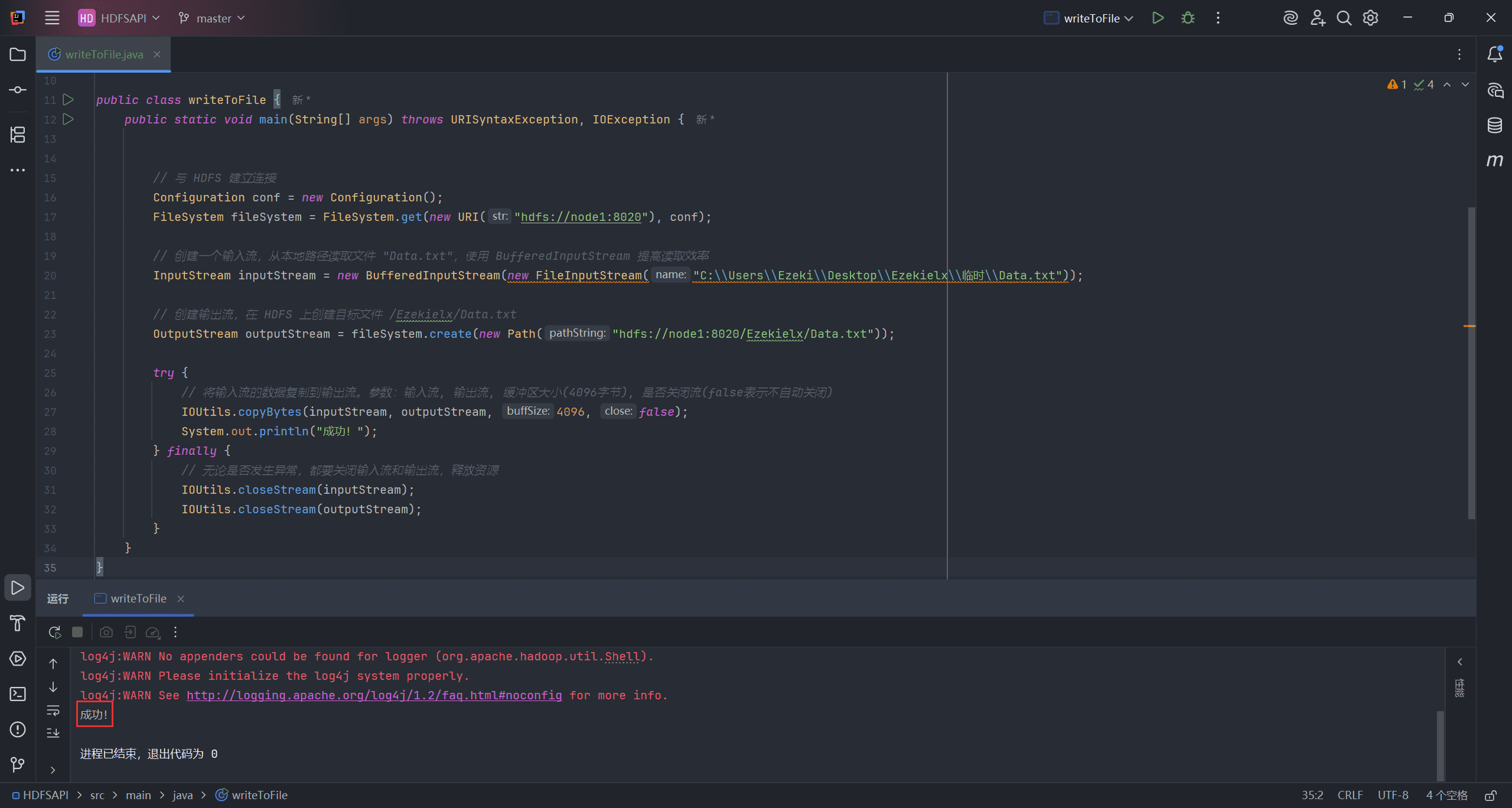
public class writeToFile {
public static void main(String[] args) throws URISyntaxException, IOException {
// 与 HDFS 建立连接
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:8020"), conf);
// 创建一个输入流,从本地路径读取文件 "Data.txt",使用 BufferedInputStream 提高读取效率
InputStream inputStream = new BufferedInputStream(new FileInputStream("hdfs://node1:8020/Ezekielx/Data.txt"));
// 创建输出流,在 HDFS 上创建目标文件/MyData/dependencies.txt
OutputStream outputStream = fileSystem.create(new Path("hdfs://node1:8020/Ezekielx/Data.txt"));
try {
// 将输入流的数据复制到输出流。参数:输入流, 输出流, 缓冲区大小(4096字节), 是否关闭流(false表示不自动关闭)
IOUtils.copyBytes(inputStream, outputStream, 4096, false);
} finally {
// 无论是否发生异常,都要关闭输入流和输出流,释放资源
IOUtils.closeStream(inputStream);
IOUtils.closeStream(outputStream);
}
}
}
3、Client File Read Operation(客户端文件读取操作)
客户端读取文件的过程:
- 客户端通过 FileSystem 的 open() 函数打开文件。
- 分布式文件系统通过 RPC 调用元数据节点,以获取文件的数据块信息。对于每个数据块,元数据节点返回持有该数据块的数据节点的地址。
- 分布式文件系统将 FSDataInputStream 返回给客户端,用于读取数据。
- 客户端调用流的 read() 函数开始读取数据。
- DFSInputStream 连接到存储该文件第一个数据块的最近数据节点,从该数据节点读取数据到客户端。
- 当一个数据块读取完成后,DFSInputStream 会关闭与该数据节点的连接,然后连接文件中下一个数据块的最近数据节点。客户端读取完数据后,会调用 FSDataInputStream 的 close() 函数。
- 在读取数据的过程中,如果客户端无法与某个数据节点通信,它会尝试连接包含该数据块的下一个数据节点。
- 失败的数据节点会被记录,后续将不再尝试连接这些节点。
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import java.io.*;
import java.net.URI;
import java.net.URISyntaxException;
public class readFromFile {
public static void main(String[] args) throws URISyntaxException, IOException {
// 与 HDFS 建立连接
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:8020"), conf);
// 创建一个输入流,从 HDFS 目标文件 /Ezekielx/Data.txt
InputStream inputStream = fileSystem.open(new Path("hdfs://node1:8020/Ezekielx/Data.txt"));
try {
// 将输入流的数据复制到标准输出。参数:输入流, 输出流, 缓冲区大小(4096字节), 是否关闭流(false表示不自动关闭)
IOUtils.copyBytes(inputStream, System.out, 4096, false);
System.out.println("\n成功!");
} finally {
// 无论是否发生异常,都要关闭输入流,释放资源
IOUtils.closeStream(inputStream);
}
}
}
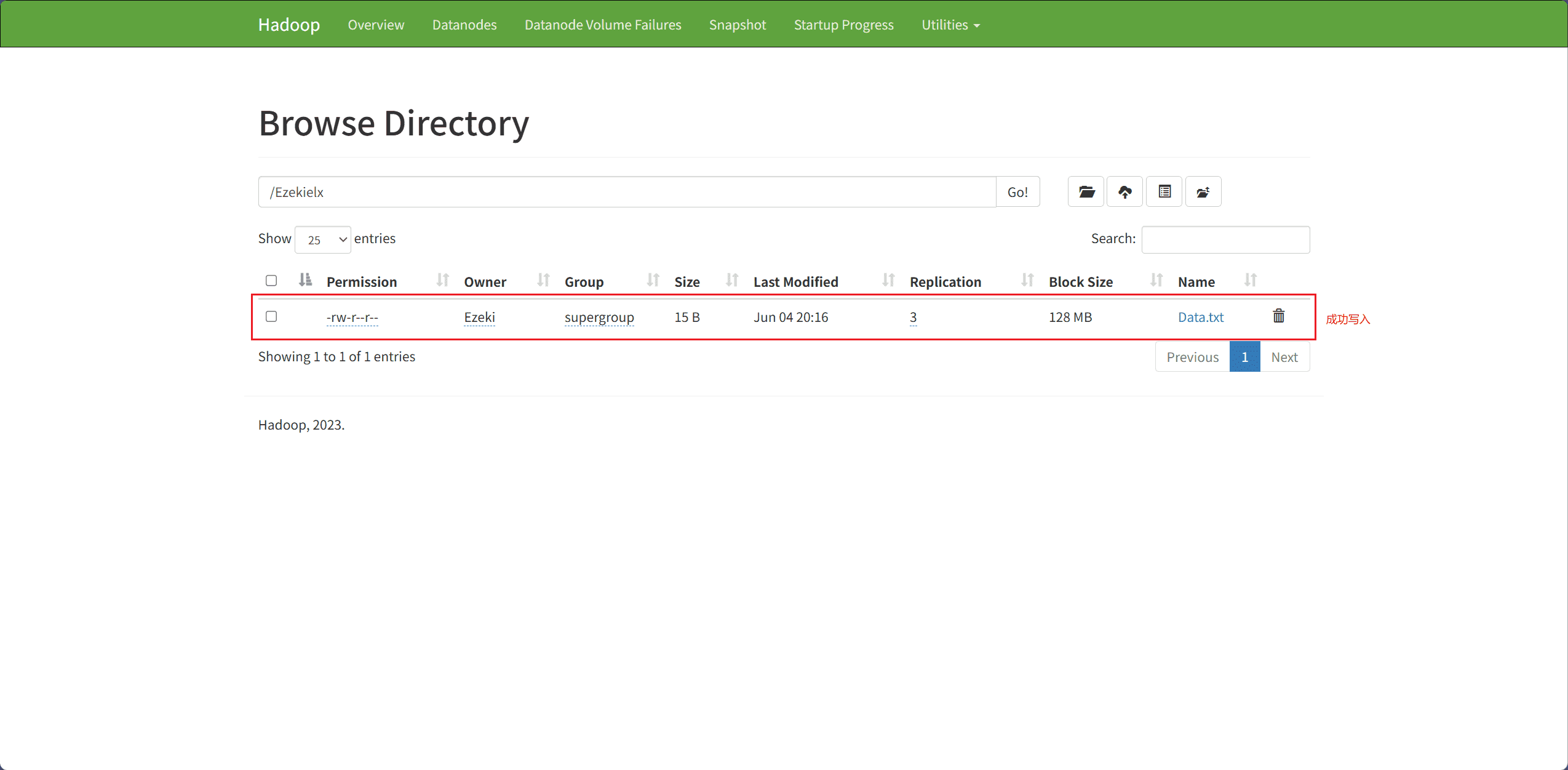
4、Upload Files locally to HDFS(将本地文件上传到 HDFS)
文件上传主要通过 copyFromLocalFile 接口完成。
src表示本地文件路径dest表示目标路径(HDFS 上的路径)
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class copyFromLocal {
public static void main(String[] args) throws URISyntaxException, IOException {
// 与 HDFS 建立连接
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:8020"), conf);
// 本地文件路径
Path source = new Path("C:\\Users\\Ezeki\\Desktop\\Ezekielx\\临时\\copyFromLocal.txt");
// HDFS 路径
Path dest = new Path("hdfs://node1:8020/Ezekielx/copyFromLocal.txt");
// 将本地文件复制到 HDFS
fileSystem.copyFromLocalFile(source, dest);
System.out.println("成功!");
}
}
5、Download Files from HDFS to Local(从 HDFS 下载文件到本地)
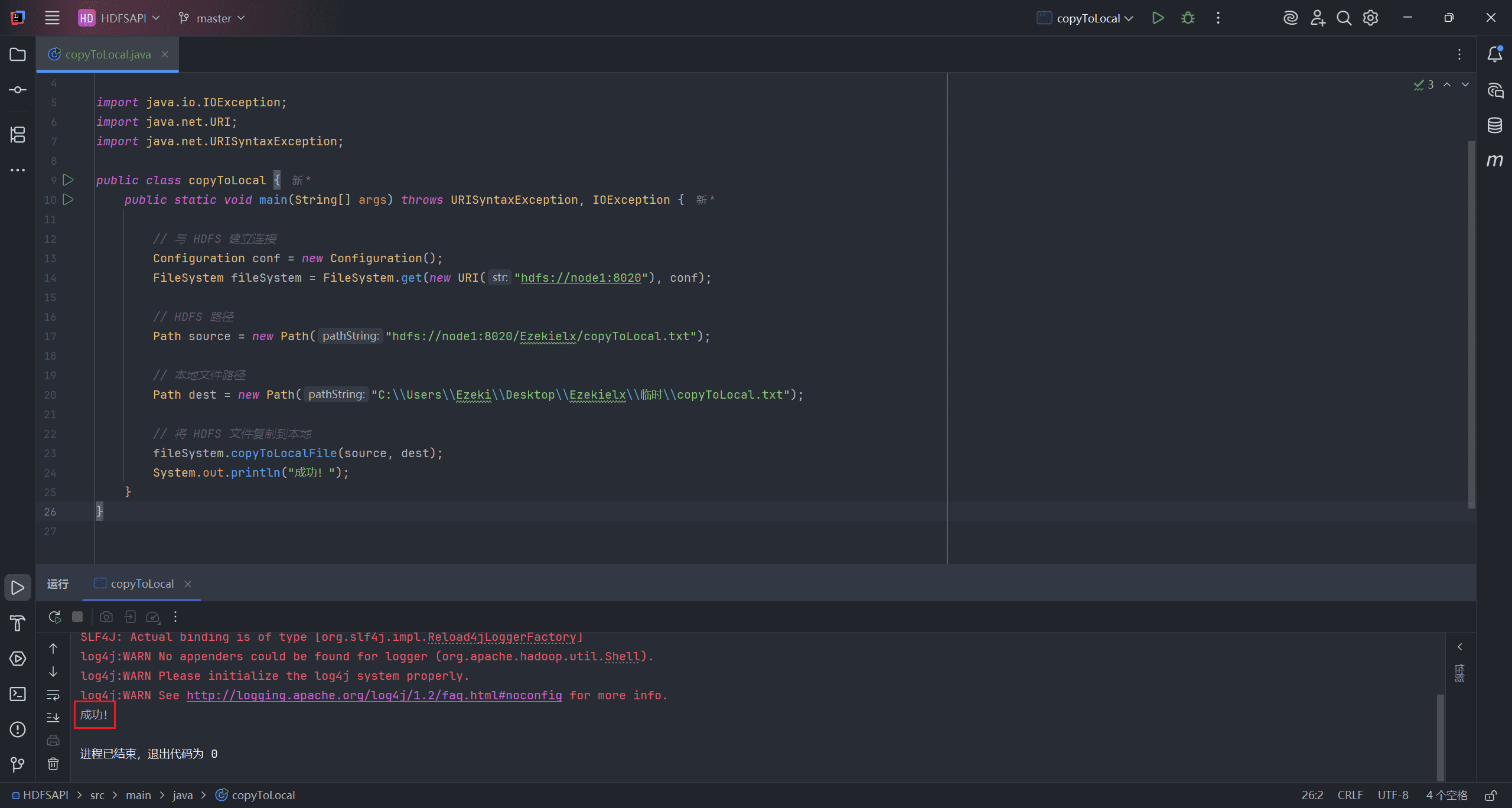
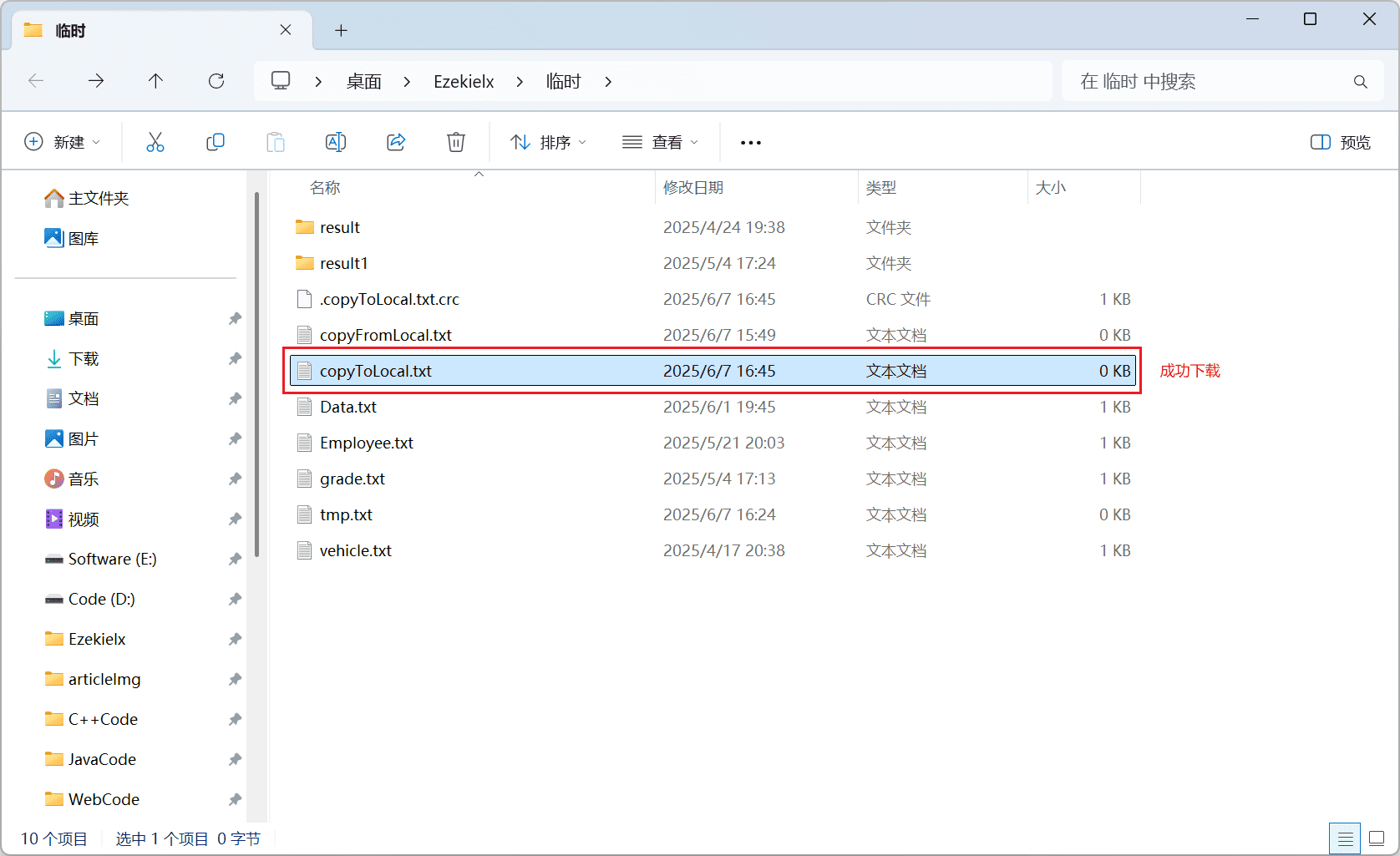
文件下载主要通过 copyToLocalFile 接口完成。
src表示源路径(HDFS 上的文件路径)dest表示本地路径
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class copyToLocal {
public static void main(String[] args) throws URISyntaxException, IOException {
// 与 HDFS 建立连接
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:8020"), conf);
// HDFS 路径
Path source = new Path("hdfs://node1:8020/Ezekielx/copyToLocal.txt");
// 本地文件路径
Path dest = new Path("C:\\Users\\Ezeki\\Desktop\\Ezekielx\\临时\\copyToLocal.txt");
// 将 HDFS 文件复制到本地
fileSystem.copyToLocalFile(source, dest);
System.out.println("成功!");
}
}
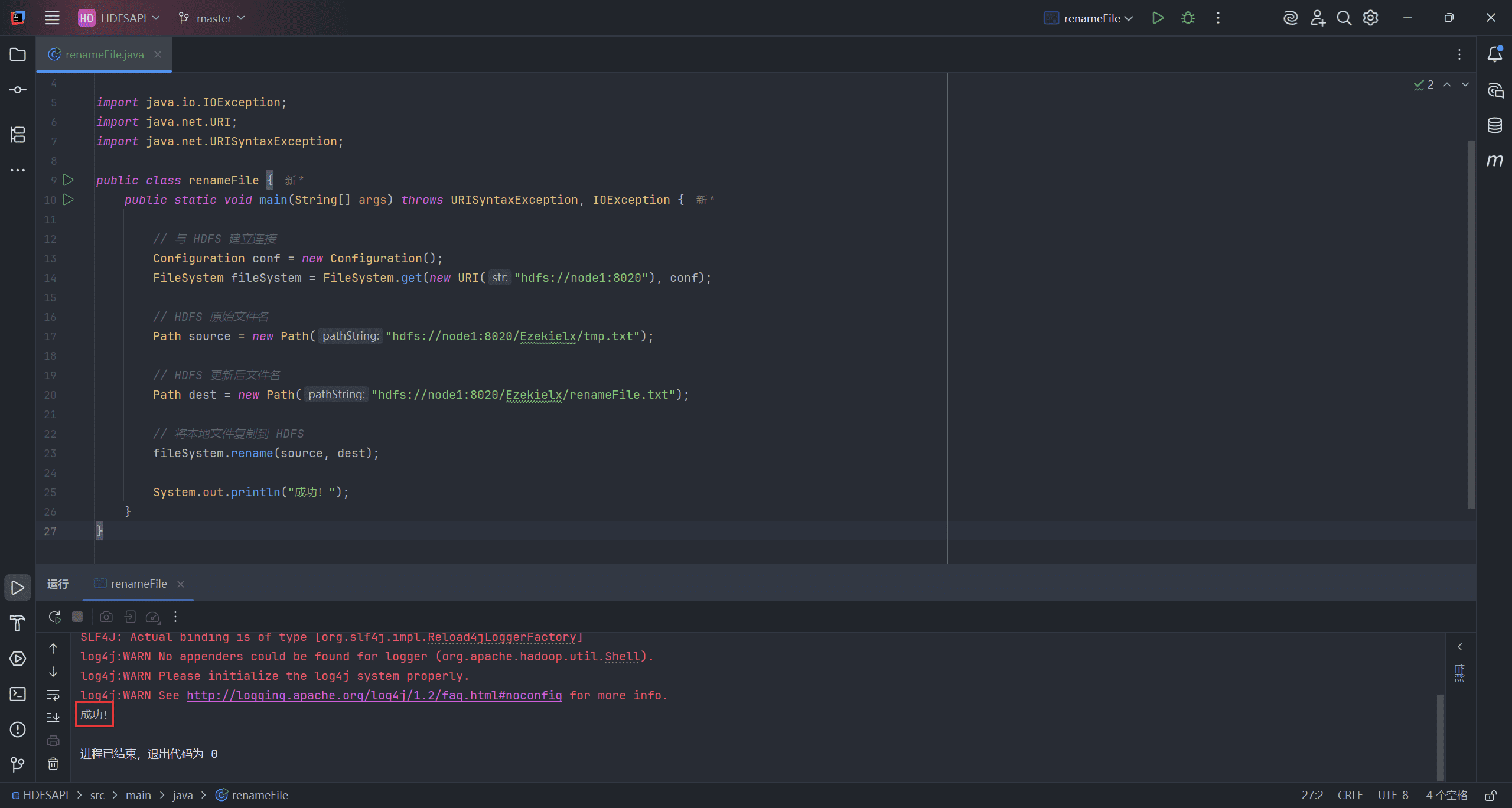
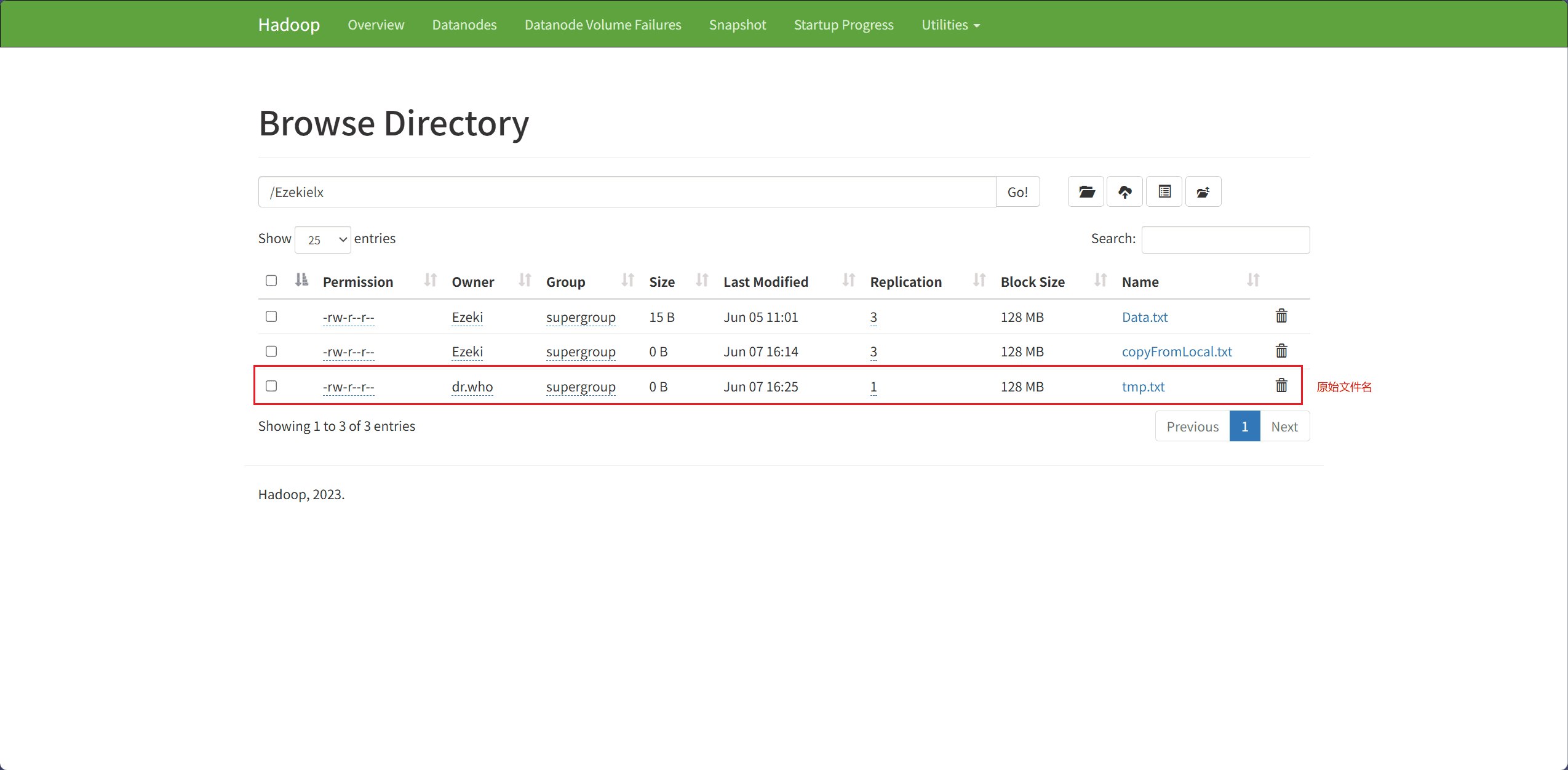
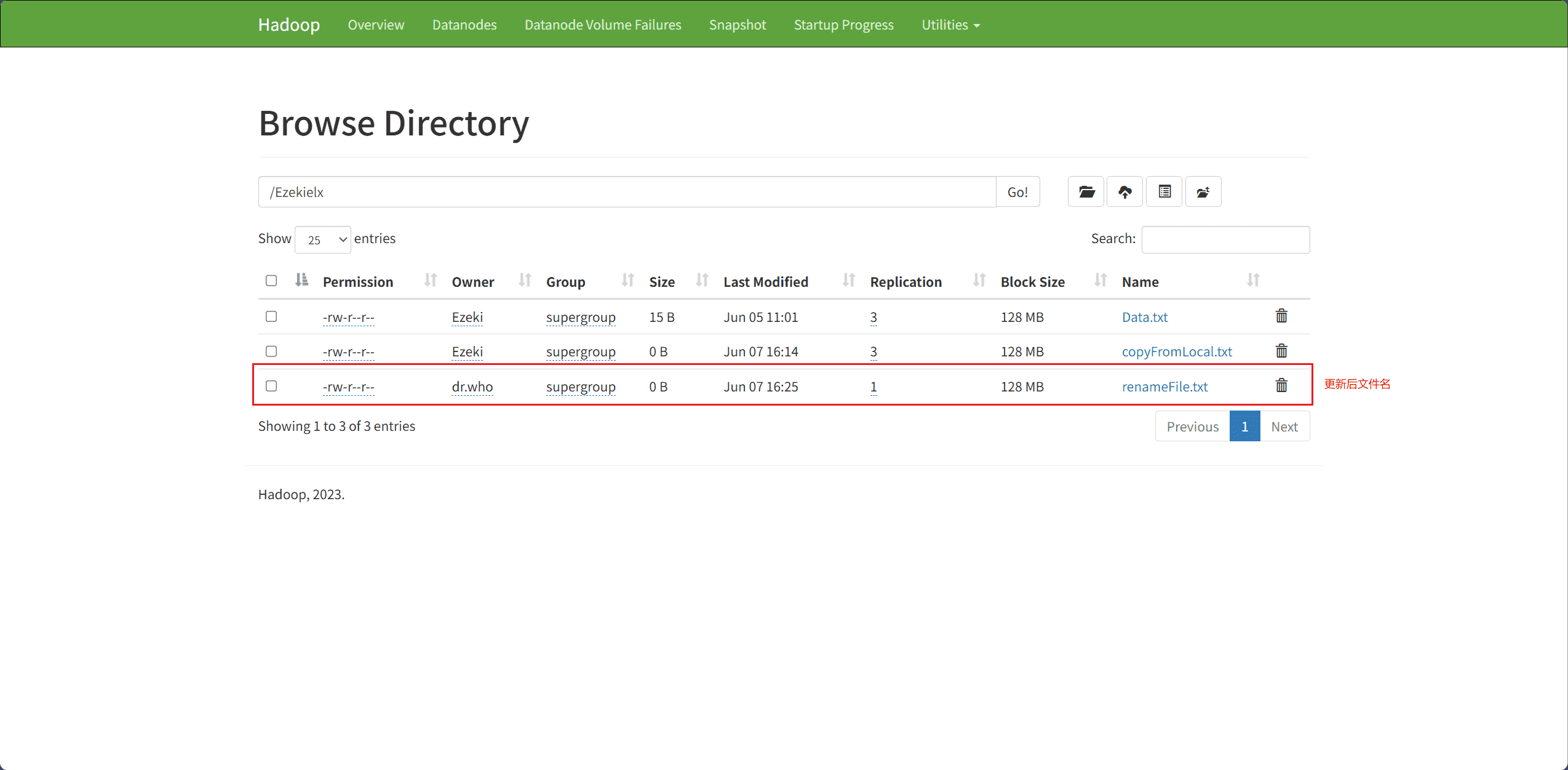
6、Rename File(重命名文件)
文件重命名主要通过 rename 接口完成。
src表示原始文件名,即要被重命名的文件dest表示重命名后的文件名
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class renameFile {
public static void main(String[] args) throws URISyntaxException, IOException {
// 与 HDFS 建立连接
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:8020"), conf);
// HDFS 原始文件名
Path source = new Path("hdfs://node1:8020/Ezekielx/tmp.txt");
// HDFS 更新后文件名
Path dest = new Path("hdfs://node1:8020/Ezekielx/renameFile.txt");
// 将本地文件复制到 HDFS
fileSystem.rename(source, dest);
System.out.println("成功!");
}
}
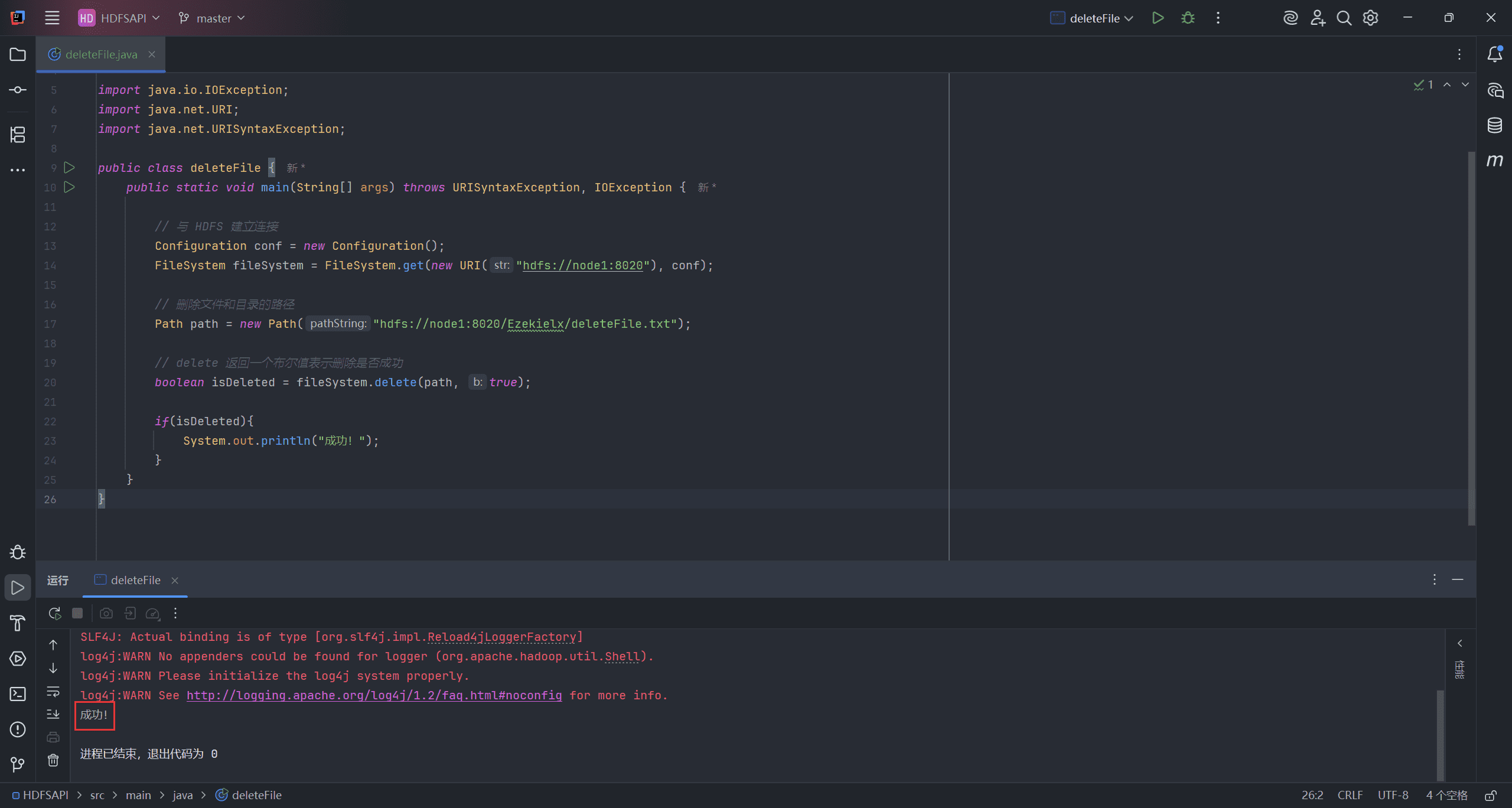
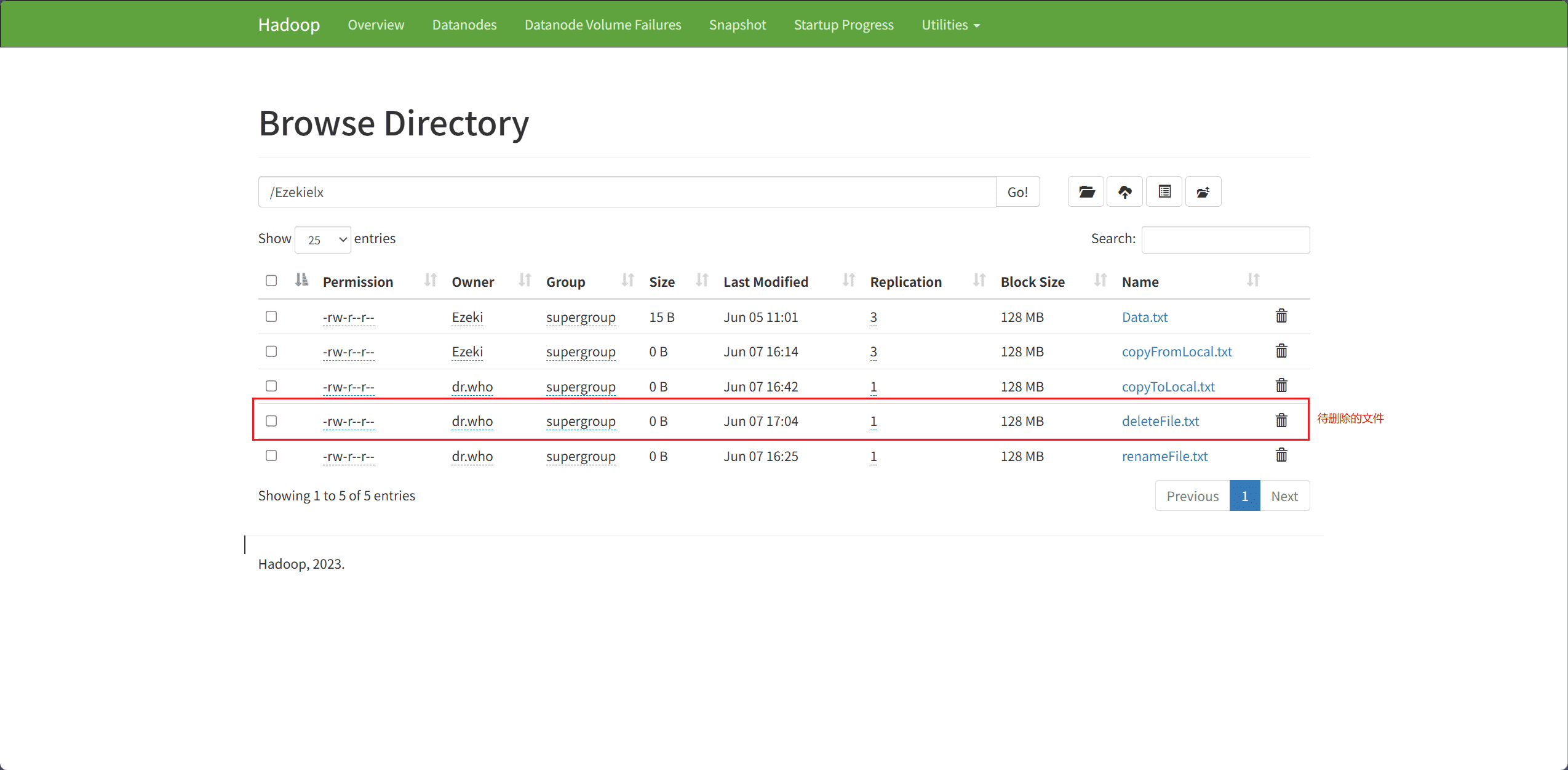
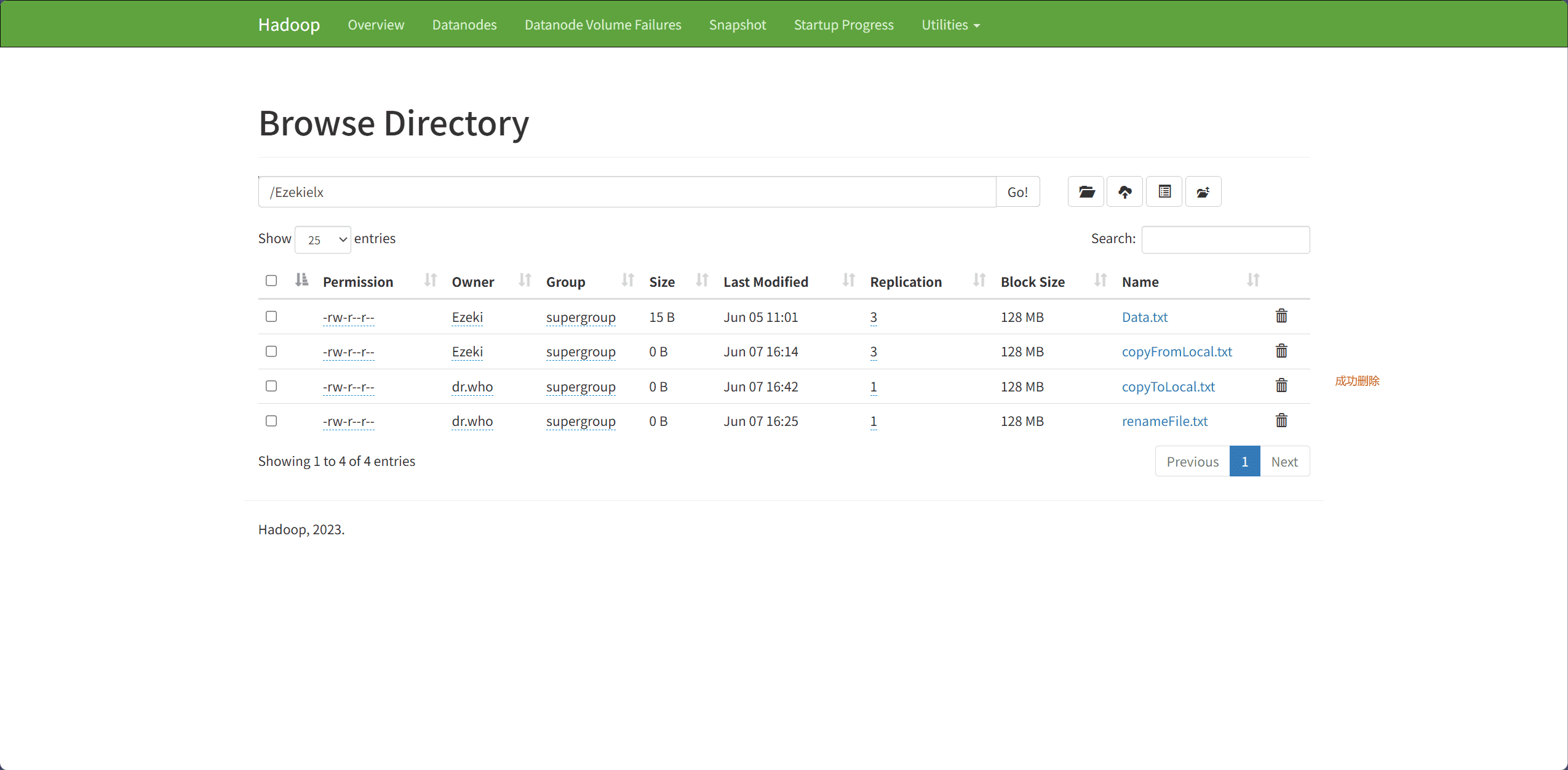
7、Delete Files & Directory(删除文件和目录)
文件和目录的删除主要通过 delete 接口完成。
path表示删除文件和目录的路径
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class deleteFile {
public static void main(String[] args) throws URISyntaxException, IOException {
// 与 HDFS 建立连接
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:8020"), conf);
// 删除文件和目录的路径
Path path = new Path("hdfs://node1:8020/Ezekielx/deleteFile.txt");
// delete 返回一个布尔值表示删除是否成功
boolean isDeleted = fileSystem.delete(path, true);
if(isDeleted){
System.out.println("成功!");
}
}
}
8、Create directories(创建目录)
目录的创建主要通过 mkdirs 接口完成。
path表示创建目录的路径
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
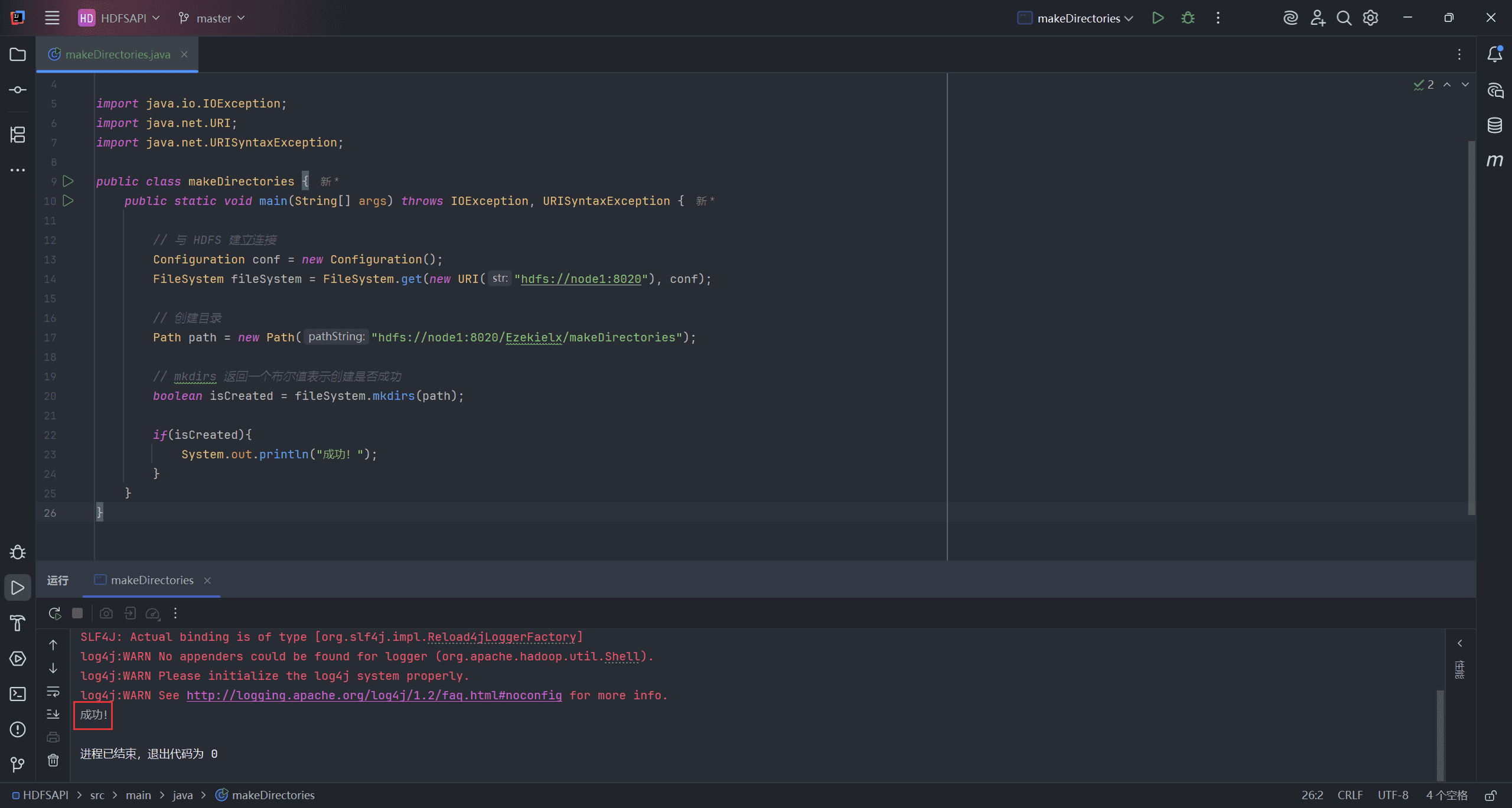
public class makeDirectories {
public static void main(String[] args) throws IOException, URISyntaxException {
// 与 HDFS 建立连接
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:8020"), conf);
// 创建目录
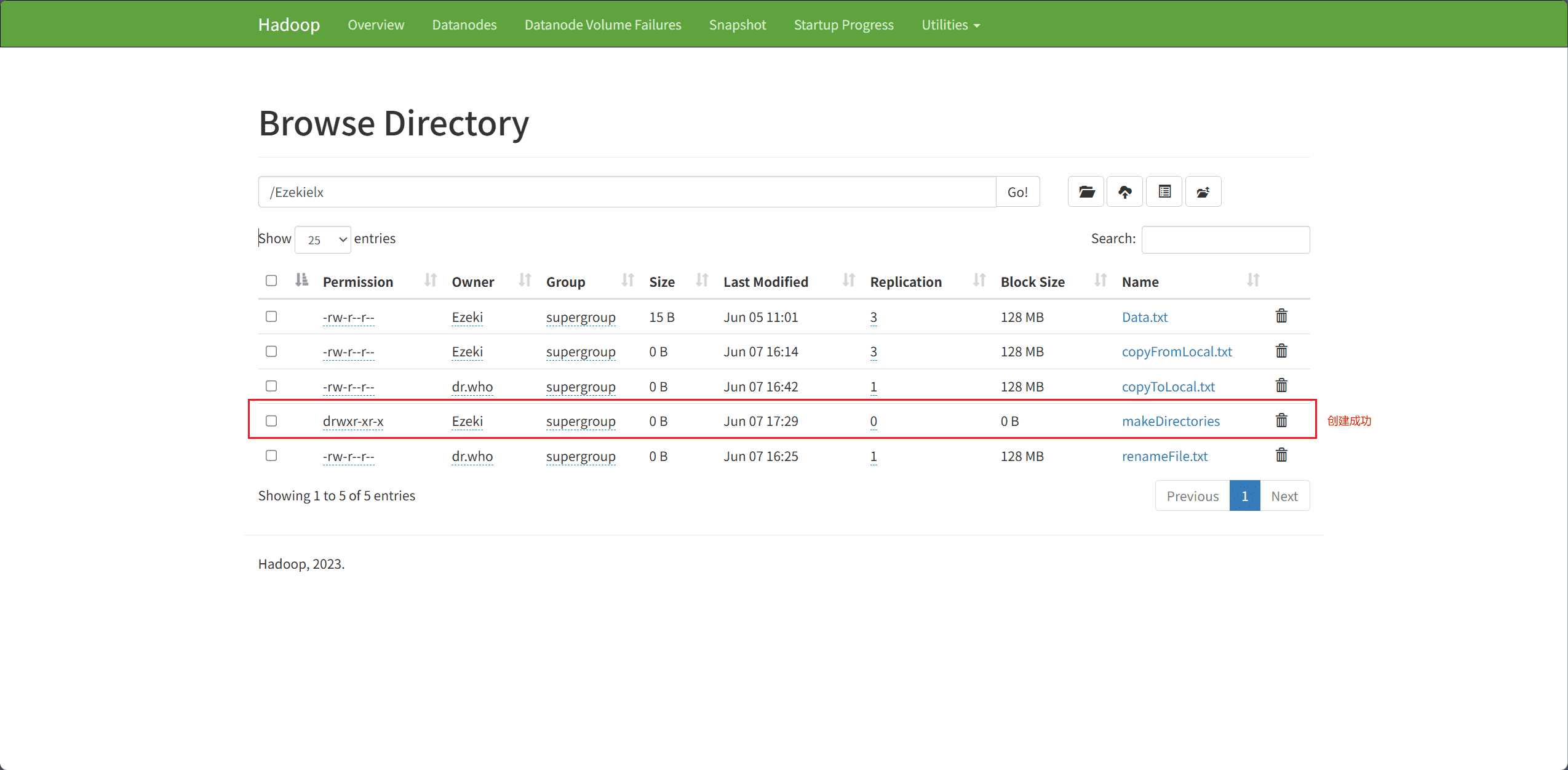
Path path = new Path("hdfs://node1:8020/Ezekielx/makeDirectories");
// mkdirs 返回一个布尔值表示创建是否成功
boolean isCreated = fileSystem.mkdirs(path);
if(isCreated){
System.out.println("成功!");
}
}
}
9、List Folder Contents(列出文件夹内容)
获取文件夹内容主要通过 listStatus 接口完成。
path表示选择获取信息的文件夹路径
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
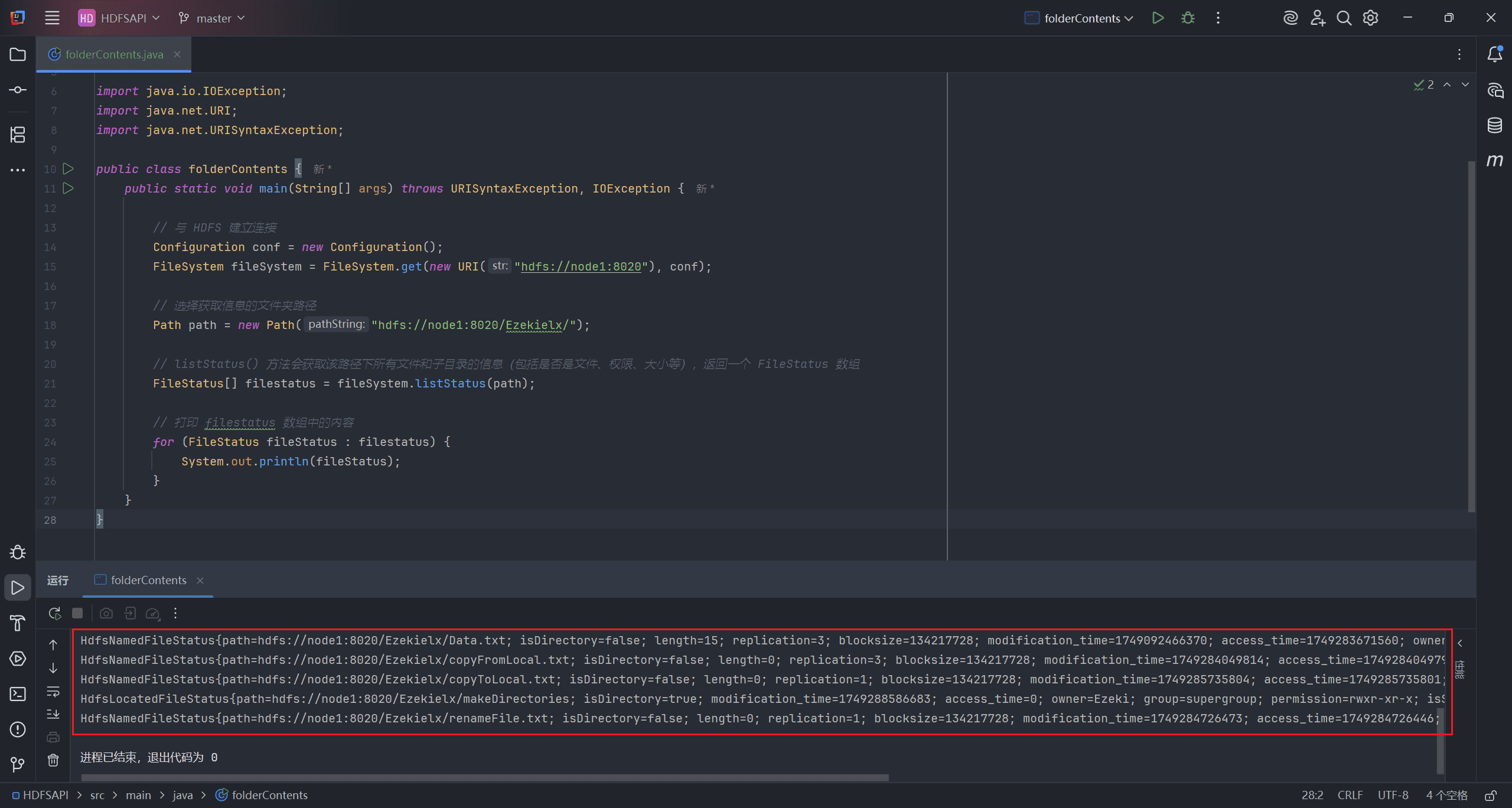
public class folderContents {
public static void main(String[] args) throws URISyntaxException, IOException {
// 与 HDFS 建立连接
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:8020"), conf);
// 选择获取信息的文件夹路径
Path path = new Path("hdfs://node1:8020/Ezekielx/");
// listStatus() 方法会获取该路径下所有文件和子目录的信息(包括是否是文件、权限、大小等),返回一个 FileStatus 数组
FileStatus[] filestatus = fileSystem.listStatus(path);
// 打印 filestatus 数组中的内容
for (FileStatus fileStatus : filestatus) {
System.out.println(fileStatus);
}
}
}
Chapter 5:Deep Insight of MapReduce(深入解析 MapReduce)
一、Introduction of MapReduce(MapReduce 简介)
MapReduce 是 Hadoop 的处理层。MapReduce 编程模型旨在通过将工作划分为一组独立的任务,来并行处理海量数据。你只需将业务逻辑融入 MapReduce 的工作方式中,其余的部分将由框架自动处理。用户提交给主节点的工作(完整作业)会被划分为多个小任务,并分配给从节点执行。
1、How MapReduce Works(MapReduce 的工作原理)
MapReduce 框架完全基于“键值对(key-value pairs)”进行操作,数据以一批“键值对”的形式输入,结果也以一批“键值对”的形式输出,且有时键值对的数据类型可能会不同。
Key 和 Value 类必须实现 Writable 接口,因为它们需要支持序列化操作;而 Key 类还必须实现 WritableComparable 接口,以便框架对数据集进行排序。
MapReduce 的运行机制包括以下作业执行阶段:Input Files(输入文件)、InputFormat(输入格式)、InputSplits(输入切片)、RecordReader(记录读取器)、Mapper(映射器)、Combiner(合并器)、Partitioner(分区器)、Shuffling and Sorting(洗牌与排序)、Reducer(归约器)、RecordWriter(记录写入器)以及 OutputFormat(输出格式)。
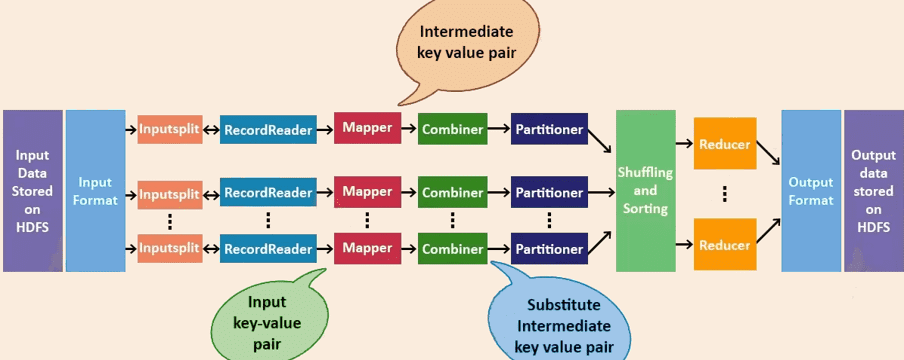
2、MapReduce Inputs and Outputs(MapReduce 输入与输出)
Input Files(输入文件):MapReduce 任务的数据存储在输入文件中,输入文件通常位于 HDFS 中。这些文件的格式是任意的,可以是基于行的日志文件,也可以是二进制格式。
InputFormat(输入格式):InputFormat 处理 MapReduce 中输入部分的内容,以确定 Map 的数量。InputFormat 的功能如下。
- 验证作业输入是否规范。
- 将输入文件划分为 InputSplit(输入切片)。
- 提供一个 RecordReader 实现类,用于将 InputSplit 读取为供 Mapper 处理的内容。
// InputFormat 代码示例
public abstract class InputFormat<K, V> {
// 将输入文件划分为 InputSplit
public abstract List<InputSplit> getSplits(JobContext context) throws IOException, InterruptedException;
// 将 InputSplit 读取为供 Mapper 处理的内容
public abstract RecordReader<K,V> createRecordReader(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException;
}
- 每个 Map 任务会处理一个 InputSplit,默认每个切片的大小为 128M。
createRecordReader方法将每个切片解析为记录,再将记录解析为 <K, V> 键值对。
FileInputFormat(文件输入格式):FileInputFormat 是所有使用文件作为数据源的基类,InputFormat 的实现类。它保存所有作业输入的文件,并实现了一个计算文件分片的方法。
// FileInputFormat 代码示例
public abstract class FileInputFormat<K, V> extends InputFormat<K, V>
InputSplits(输入切片):由 InputFormat 创建,逻辑上表示将由单个 Mapper 处理的数据。每一个切片对应一个 Map 任务,因此 Map 任务的数量等于 InputSplits 的数量。
getLength:返回文件大小。getLocations:返回数据所在的物理位置(如存储节点)。
// InputSplit 代码示例
public interface InputSplit extends Writable {
long getLength() throws IOException;
String[] getLocations() throws IOException;
}
- 在执行 MapReduce 前,原始数据会被划分成多个切片,每个切片作为一个 Map 任务的输入;在 Map 执行过程中,每个切片会进一步被解析为记录(键值对),Mapper 依次处理这些记录。
- FileInputFormat 只对大于 HDFS 块大小的文件进行切片,因此 FileInputFormat 的分区结果可能是整个文件或其一部分。
- 如果文件小于一个 HDFS 块的大小,则不会被切片,这也是 Hadoop 在处理大文件时比处理大量小文件更高效的原因。
- 当 Hadoop 处理大量小文件(小于块大小)时,FileInputFormat 不会将小文件划分切片,因此每个小文件被视为一个切片,会被分配一个 Map 任务,效率较低。
在 Hadoop 中,常用的 Map 输入类型:
-
TextInputFormat(文本输入):是 Hadoop 的默认输入方式。在TextInputFormat中,每个文件(或文件的一部分)被单独输入到一个 Map 中。它继承自FileInputFormat。在该模式下,每一行数据生成一个记录,表示为 <key, value>。key是数据记录在数据片段中的字节偏移量,数据类型为LongWritable。value是每一行的内容,数据类型为Text。
-
SequenceFileInputFormat:用于读取顺序文件(SequenceFile)。顺序文件是 Hadoop 用于以自定义格式存储数据的二进制文件。它有两个子类:SequenceFileAsBinaryInputFormat:以BytesWritable类型读取 key 和 value。SequenceFileAsTextInputFormat:以Text类型读取 key 和 value。
-
KeyValueInputFormat:将输入文件的每一行作为一个独立的记录,并通过查找 TAB(制表符)字符将其分割为 key 和 value。
Custom InputFormat(自定义输入模式):
-
继承
FileInputFormat基类。 -
重写
getSplits(JobContext context)方法。此接口的主要职责是将一堆输入文件分割为多个切片(每个切片由一个
InputSplit对象表示),每个InputSplit都会传递给不同的 Mapper 进行处理。但请注意,这些切片只是逻辑上的分片,实际上并不将文件物理划分成多个部分。一个切片可以表示为一个元组(输入文件路径,起始位置,偏移量)。
// getSplits(JobContext context) 方法定义
public abstract List<InputSplit> getSplits(JobContext Context) throws IOException, InterruptedException;
- 重写
createRecordReader(InputSplit split, TaskAttemptContext context)方法。
这个接口的职责是返回一个读取 InputSplit 切片的 RecordReader 实例,用于从切片中提取 <K, V> 对供 Mapper 使用。
// createRecordReader(InputSplit split, TaskAttemptContext context) 方法定义
public abstract RecordReader<K, V> createRecordReader(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException;
3、Map Output Format(Map 输出格式)
MapReduce 中常用的输出格式如下:
- TextOutputFormat:以纯文本文件的形式输出,格式为
key + "\t" + value(键与值之间用制表符分隔) - NullOutputFormat:类似于 Hadoop 中的
/dev/null,输出被丢弃,相当于写入黑洞,不会生成实际输出文件。 - SequenceFileOutputFormat:输出为 Sequence 文件格式,适用于二进制数据的写入。
- MultipleSequenceFileOutputFormat、MultipleTextOutputFormat:根据 key 的不同值,将数据分别输出到不同的文件中,适用于需要按 key 分类输出的场景。
RecordReader:它与 Hadoop MapReduce 中的 InputSplit 交互,将输入数据转换为适合 Mapper 读取的键值对。默认使用的是 TextInputFormat,将数据每行转换为一个 key-value 对,其中 key 是该行的字节偏移量(一个唯一数字)。RecordReader 会持续读取,直到文件读取完毕。
Mapper:处理 RecordReader 提供的每条输入记录,生成新的键值对。Mapper 的输出(也称为中间输出)是临时数据,不会存储在 HDFS 上,否则会导致不必要的数据副本产生。
Combiner:也称为“小型 Reducer”,在 Mapper 输出的基础上进行本地聚合,减少 Mapper 和 Reducer 之间传输的数据量。
Partitioner(分区器):在 Hadoop MapReduce 中,只有在使用多个 Reducer 时才会用到 Partitioner(如果只使用一个 Reducer,则不需要分区器)。
Partitioner 接收来自 Combiner 的输出数据,并根据 key 对数据进行分区。分区是基于 key 进行的,通常通过哈希函数对 key(或其子集)进行哈希,从而确定数据所属的分区。
在 MapReduce 中,每个具有相同 key 值的记录会被分到同一个分区,然后每个分区被分配给一个 Reducer。分区机制有助于将 Map 阶段的输出数据均匀分配到各个 Reducer 上,提高负载均衡性。
Shuffling and Sorting(洗牌与排序):Shuffling 指将中间输出数据“洗牌”后发送到 Reducer 节点(该节点是普通的从节点,但会运行 Reduce 阶段任务,因此称为 Reducer 节点)。
Shuffling 是数据通过网络进行的物理移动。当所有 Mapper 完成任务后,其输出会被传输到 Reducer 节点,并在该节点上进行合并与排序。
排序完成后的中间数据就是 Reduce 阶段的输入。
Reducer(归约器):Reducer 接收 Mapper 所产生的中间键值对,并对每一个 key 执行归约函数,生成最终的输出结果。Reducer 的输出就是最终结果,会被写入到 HDFS 上。
RecordWriter(记录写入器):该组件负责将 Reducer 阶段生成的键值对写入最终的输出文件。
OutputFormat(输出格式):RecordWriter 将键值对写入输出文件的方式由 OutputFormat 决定。Hadoop 提供的 OutputFormat 实例可以将文件写入到 HDFS 或本地磁盘。因此,Reducer 的最终输出结果是通过 OutputFormat 实例写入到 HDFS 的。
二、Key Processes of MapReduce(MapReduce 的关键处理流程)
一个作业包括 Map、Combiner、Partitioner、Reduce 和 Shuffle 等阶段,用于对大数据进行分析、处理和计算。
1、Mapper(映射器)
Mapper 只能处理以 <key, value> 形式表示的数据,因此在将数据传递给 Mapper 之前,必须先将数据转换成 <key, value> 对。
InputSplits(输入分片):它将物理数据块的表示转换为逻辑形式,供 Hadoop 的 Mapper 使用。例如,读取一个 200MB 的文件需要两个 InputSplit。每个数据块会生成一个 InputSplit,并且每个 InputSplit 会对应创建一个 RecordReader 和一个 Mapper。
不过,InputSplit 的数量不总是与数据块数量完全一致。我们可以通过在作业执行时设置 mapred.max.split.size 属性,来自定义特定文件的分片数量。
RecordReader(记录读取器):它负责持续读取和转换数据为 <key, value> 形式,直到文件末尾。RecordReader 会为文件中的每一行分配一个唯一的字节偏移量作为 key,行的内容作为 value。
生成的 key-value 对会被传递给 Mapper。Mapper 程序的输出被称为中间数据(即 Reducer 能理解的键值对)。
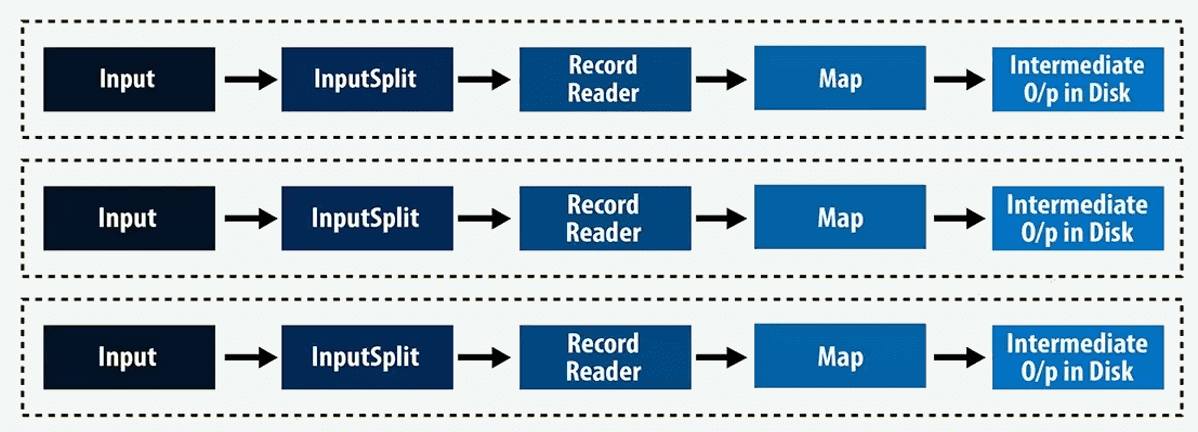
例子:如果数据块大小为128MB,且预计输入数据量为10TB,那么就会有约82000个 Mapper。也就是说,InputFormat 决定了 Mapper 的数量。
因此,Mapper 的数量计算公式为:Mapper 数量 = (总数据大小)÷(输入分片大小)
例如,若数据大小为1TB,InputSplit 大小为200MB,则:Mapper 数量 = (1000 × 1000) ÷ 200 = 5000 个 Mapper。
// Mapper 代码示例
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
// 初始化方法,作业开始时调用,通常用于初始化资源
protected void setup(Context context) throws IOException, InterruptedException {
}
// 处理每条输入记录的核心方法,将输入的 key 和 value 映射成新的 key-value 输出
protected void map(KEYIN key, VALUEIN value, Context context) throws IOException, InterruptedException {
context.write((KEYOUT) key, (VALUEOUT) value);
}
// 清理方法,作业结束时调用,通常用于释放资源
protected void cleanup(Context context) throws IOException, InterruptedException {
}
// 运行方法,控制整个 Mapper 任务的执行流程
public void run(Context context) throws IOException, InterruptedException {
setup(context); // 调用初始化
try {
while (context.nextKeyValue()) { // 迭代读取每个 key-value 对
map(context.getCurrentKey(), context.getCurrentValue(), context); // 调用 map 方法处理
}
} finally {
cleanup(context); // 最后调用清理
}
}
}
2、Partitioner(分区器)
在 Hadoop MapReduce 框架中,Mapper 处理完数据后,Partitioner 需要确定如何将 Mapper 的输出正确分配给各个 Reducer。
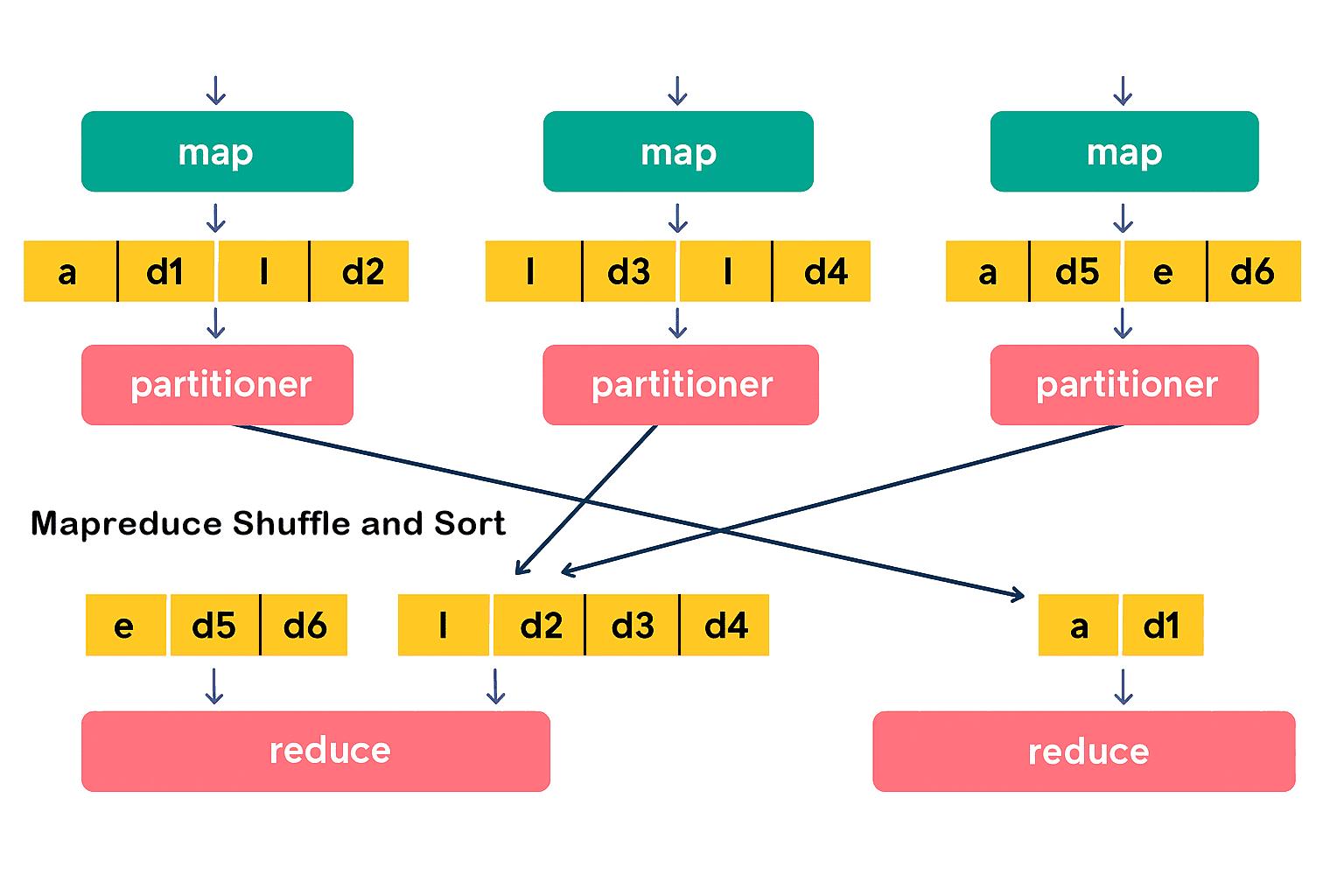
默认分区器:
默认情况下,Hadoop 会对 <key, value> 键值对中的 key 进行哈希处理,以确定该数据应该分配给哪个 Reducer。Hadoop 使用的是 HashPartitioner 来执行这个操作。但有时 HashPartitioner 并不能达到理想的效果。
// HashPartitioner 代码示例
public class HashPartitioner<K2, V2> implements Partitioner<K2, V2> {
// 初始化配置项
public void configure(JobConf job) {
}
// getPartition 方法用于根据 key 的哈希值决定分区编号(即选择哪个 Reducer)
public int getPartition(K2 key, V2 value, int numReduceTasks) {
// 先通过 hashCode() 获取 key 的哈希值
// 与 Integer.MAX_VALUE 做与运算,确保结果为正数
// 然后对 Reducer 数量取模,保证结果在 0 ~ numReduceTasks-1 之间
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
其中 (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks 是核心代码,意思是对 key 生成一个哈希码。由于 hashCode() 可能产生负数,而分区编号不能为负数,因此使用该哈希值与 Integer.MAX_VALUE(即 Java 中 Integer 类型所能表示的最大正整数)进行按位“与”运算,以确保结果是正数。然后再对传入的 Reducer 数量 numReduceTasks 进行取模运算,最终得到合法且正确的分区编号。
自定义分区器:
当默认的 HashPartitioner 无法满足特定业务需求,或在实际应用中出现数据倾斜现象时,就需要使用自定义的分区器类,以满足相关的业务要求。
自定义分区器必须实现 Partitioner 接口,并重写两个核心方法:getPartition() 和 configure()。
getPartition()方法用于返回一个整数值,该值位于 0 到 Reducer 总数之间,用于决定当前的<key, value>键值对应该被发送到哪个 Reducer。configure()方法则使用 Hadoop 的作业配置(Job Configuration)来对分区器进行设置,使得分区数量等配置信息可以在上下文和内存中的 Configuration 模块中生效。
3、Combiner(合并器)
Combiner 相当于一个本地的 Reducer。它将 Mapper 输出的大量本地文件进行合并,从而减少 Map 与 Reduce 之间在网络上传输的数据量。
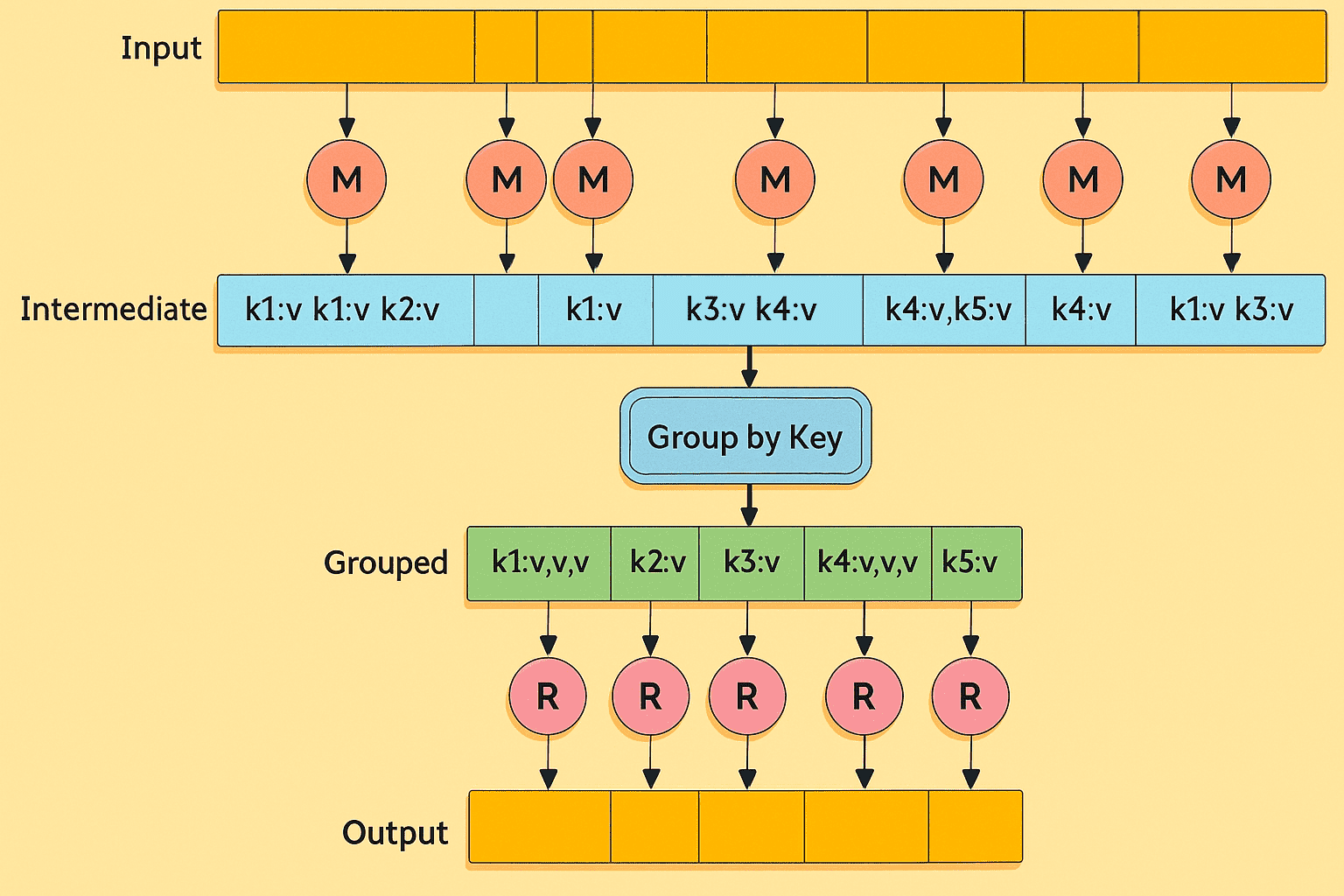
Combiner 最基本的功能是对本地的 key 进行聚合,对 Map 输出的 key 进行排序,并对 Map 输出中的 value 进行迭代计算。例如:
map: (key1,value1) → list(key2,value2)
combine: (key2,list(value2)) → list(key2,value2)
reduce: (key2,list(value2)) → list(key3,value3)
你可以使用 Combiner 在 MAP 端完成本地聚合,以减少网络上传输的数据量,从而提升性能。
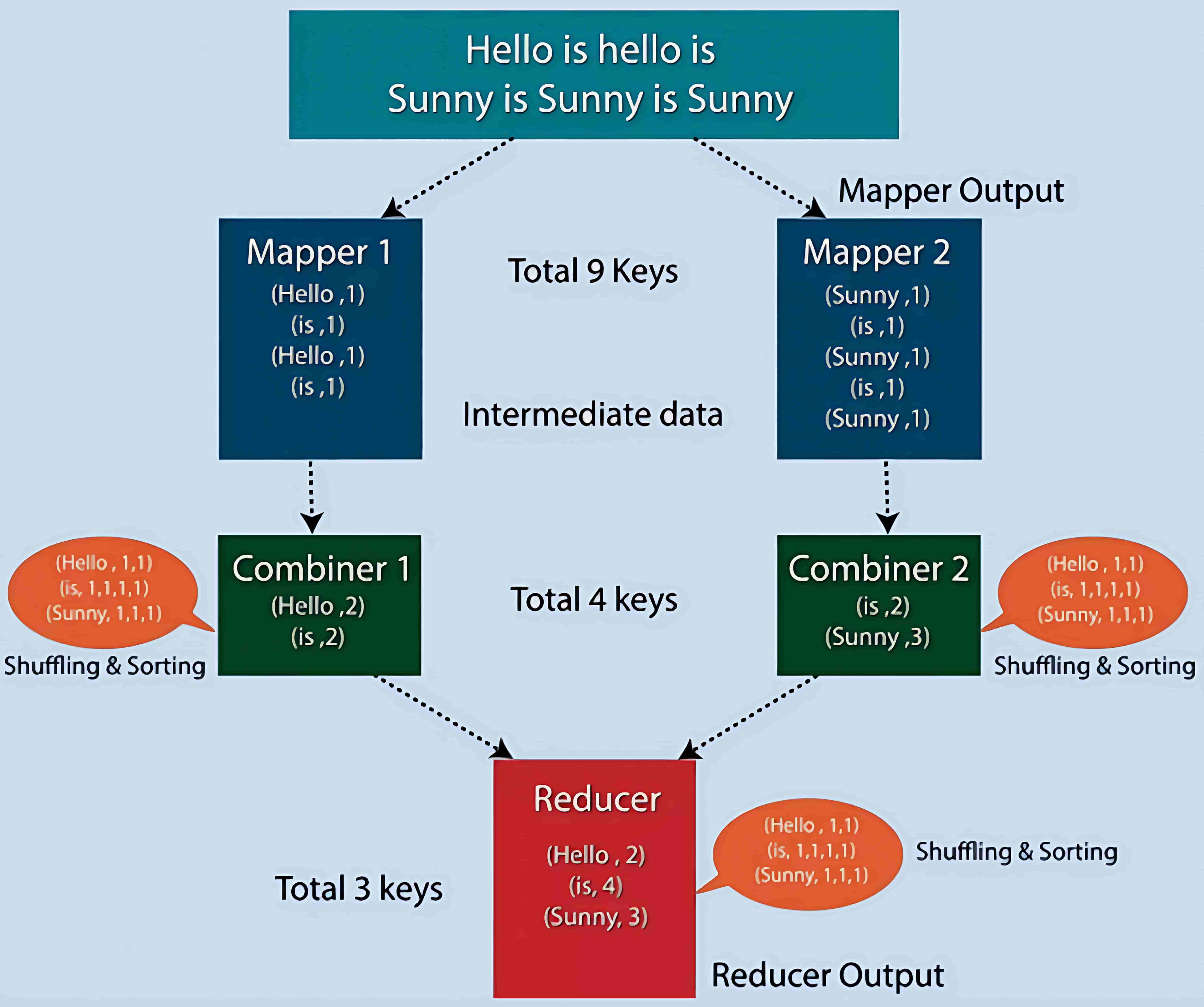
4、Reducer(归约器)
Hadoop 的 Reducer 将由 Mapper 生成的一组中间键值对作为输入,并在每个键值对上运行 Reducer 函数。用户可以以多种方式对这些 (key, value) 数据进行聚合、过滤和组合,以完成各种处理任务。Reducer 首先处理由 Map 函数生成的特定 key 的中间值,然后生成输出(可以是零个或多个键值对)。
每个 key 与 Reducer 之间是一对一映射。由于 Reducer 之间彼此独立,因此可以并行运行。用户可以自行决定 Reducer 的数量,默认情况下 Reducer 的数量为 1。
MapReduce 中 Reducer 的阶段:
如图所示,Hadoop MapReduce 中 Reducer 包括三个阶段:
-
Shuffle 阶段
在此阶段,Reducer 的输入是 Mapper 排序后的输出。在 Shuffle 阶段,框架通过 HTTP 协议从所有 Mapper 中获取对应分区的数据。
-
Sort 阶段
该阶段将来自不同 Mapper 的输入再次根据 key 进行排序,使得相同 key 的数据归并到一起。Shuffle 和 Sort 阶段是并发进行的。
-
Reduce 阶段
在经过 Shuffle 和 Sort 后,Reduce 任务开始对键值对进行聚合处理。通过调用
OutputCollector.collect()方法将 Reduce 任务的输出写入到文件系统中。需要注意的是,Reducer 的输出数据不会再进行排序。
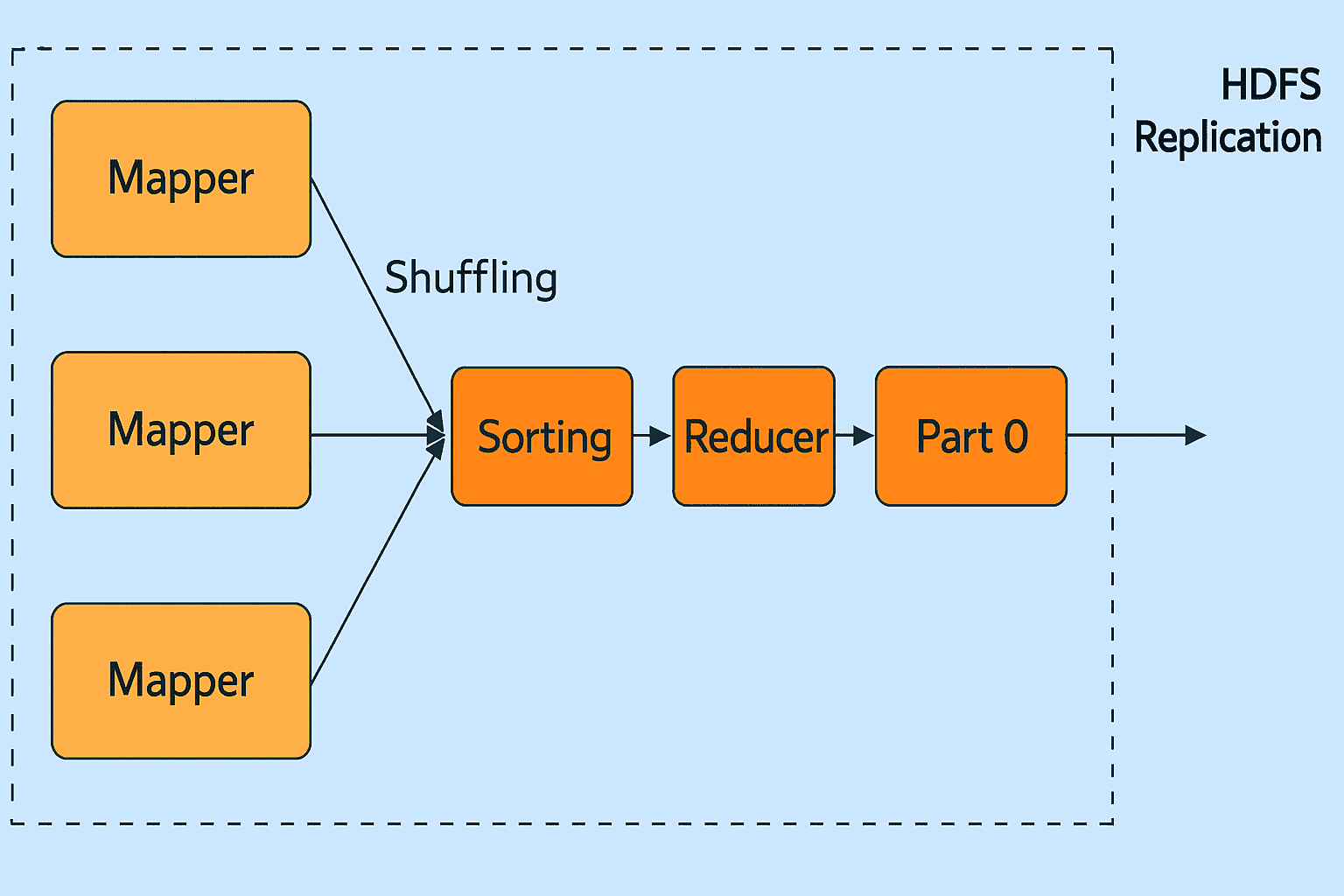
MapReduce 中 Reducer 的数量:
用户可以通过 Job.setNumreduceTasks(int) 方法来设置该作业的 Reducer 数量。
合理的 Reducer 数量通常是:0.95 或 1.75 ×(节点数 × 每个节点的最大容器数)。
- 如果使用 0.95,表示所有 Reducer 几乎可以在所有 Map 任务完成后立刻启动并开始传输 Map 的输出。
- 如果使用 1.75,则一部分较快节点会先完成第一批 Reducer 的工作,然后再启动第二批 Reducer,从而实现更好的负载均衡。
增加 MapReduce Reducer 数量的影响:
- 增加框架的开销(Framework overhead)
- 提高负载均衡能力
- 降低失败带来的代价(成本)
自定义 Reducer 类必须继承 Hadoop 内置的 Reducer 类,并重写其中的 reduce() 方法。
Reducer 类的源码需参考 Hadoop 提供的标准实现。
// 泛型定义:KEYIN 和 VALUEIN 是输入的 key 和 value 类型,KEYOUT 和 VALUEOUT 是输出的 key 和 value 类型
public class Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
// Context 是 Reducer 的上下文对象,用于获取输入数据以及写出结果
public abstract class Context
implements ReduceContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
}
// setup() 方法在 Reduce 任务开始前调用一次,可用于执行初始化操作(如资源创建)
protected void setup(Context context) throws IOException, InterruptedException {
}
// reduce() 是 Reducer 的核心逻辑:
// 对每个 key 调用一次,values 是该 key 对应的所有中间值(来自 Mapper 输出)
protected void reduce(KEYIN key, Iterable<VALUEIN> values, Context context
) throws IOException, InterruptedException {
for (VALUEIN value : values) {
// 将结果写入上下文中,默认将每个 key-value 对原样输出
context.write((KEYOUT) key, (VALUEOUT) value);
}
}
// run() 方法是 Reducer 的执行主流程,由 Hadoop 框架自动调用
public void run(Context context) throws IOException, InterruptedException {
// 首先执行初始化逻辑
setup(context);
try {
// 遍历所有 key,每次处理一个 key 及其对应的所有 value 集合
while (context.nextKey()) {
// 对当前 key 和对应的 value 集合调用 reduce() 处理逻辑
reduce(context.getCurrentKey(), context.getValues(), context);
// 获取当前 key 对应的 value 迭代器
Iterator<VALUEIN> iter = context.getValues().iterator();
// 如果当前的 values 迭代器是 ReduceContext.ValueIterator 类型,
// 说明在处理某些 key 时,value 的数量可能太多而无法全部加载进内存,
// Hadoop 会将一部分 value 临时写入磁盘(称为 backup store 备份存储)。
// 处理完该 key 后,需要调用 resetBackupStore() 方法清空或重置备份存储,
// 以释放磁盘空间并防止数据残留影响后续 key 的处理,保证资源效率和数据正确性。
if (iter instanceof ReduceContext.ValueIterator) {
((ReduceContext.ValueIterator<VALUEIN>) iter).resetBackupStore();
}
}
}
}
}
5、添加依赖
打开 IDEA,选择构建一个 Maven 项目。
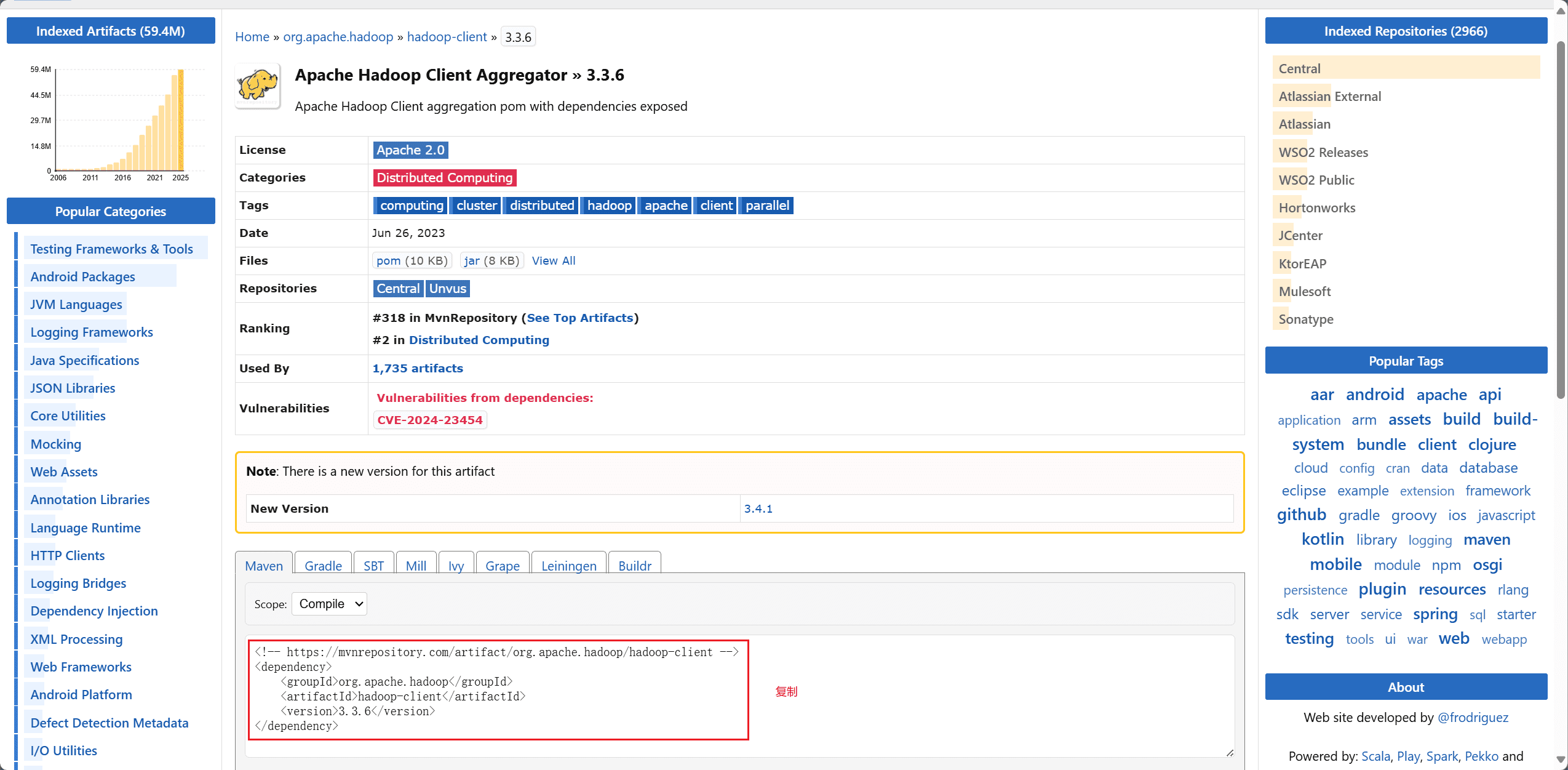
进入 maven 官方官网,搜索 hadoop-client,选择对应的 Hbase 版本,将依赖配置复制下来。
打开项目的 pom.xml 文件。
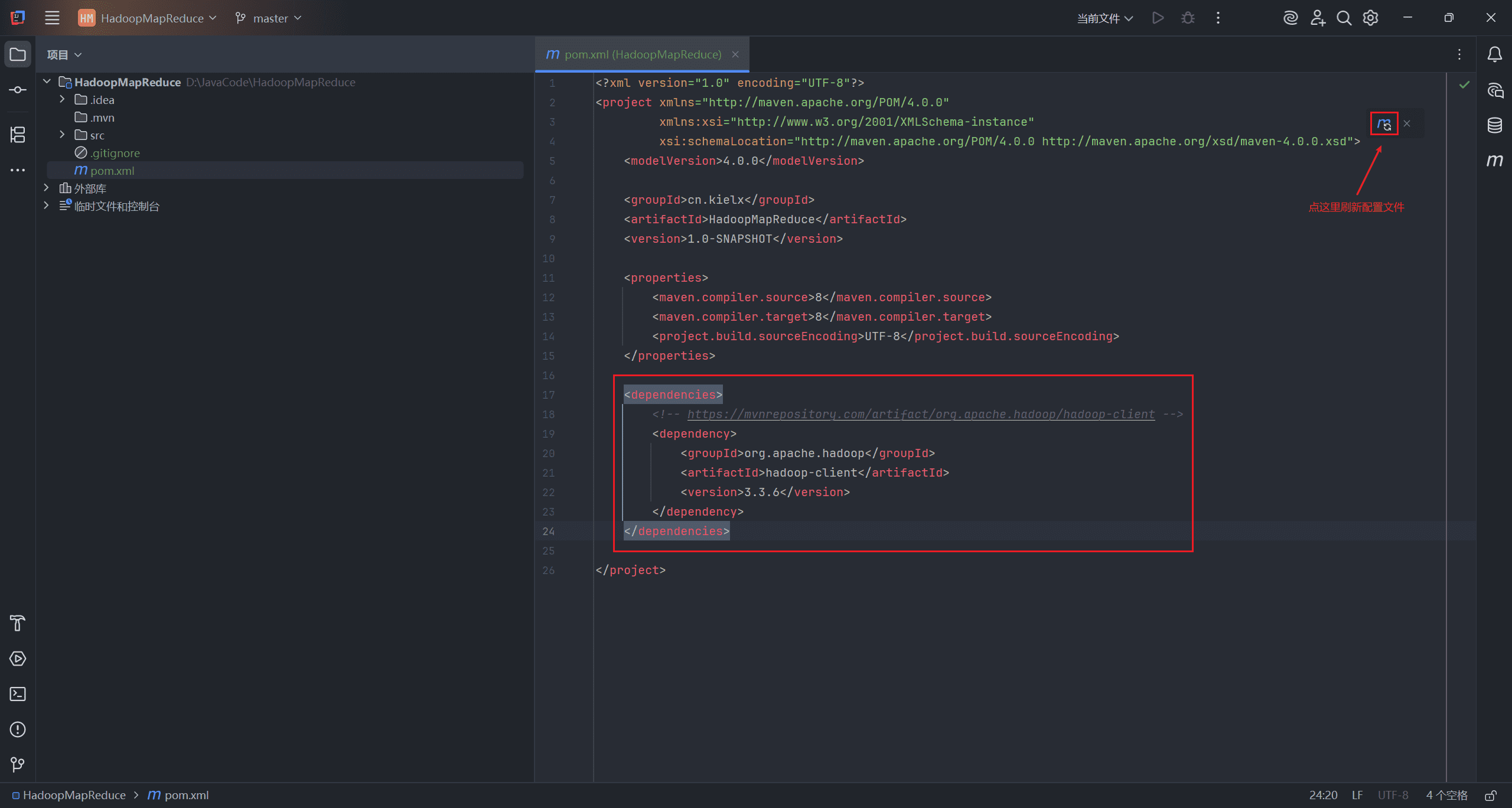
创建 <dependencies> 标签,将复制的配置粘贴进去,刷新配置文件。
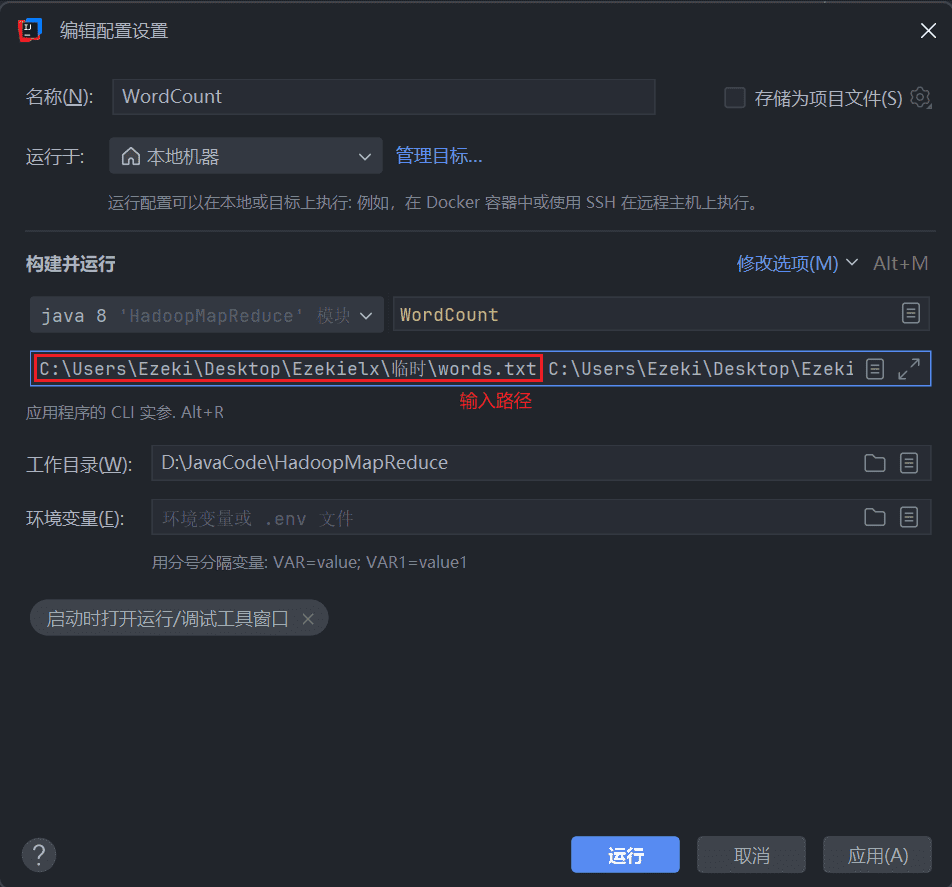
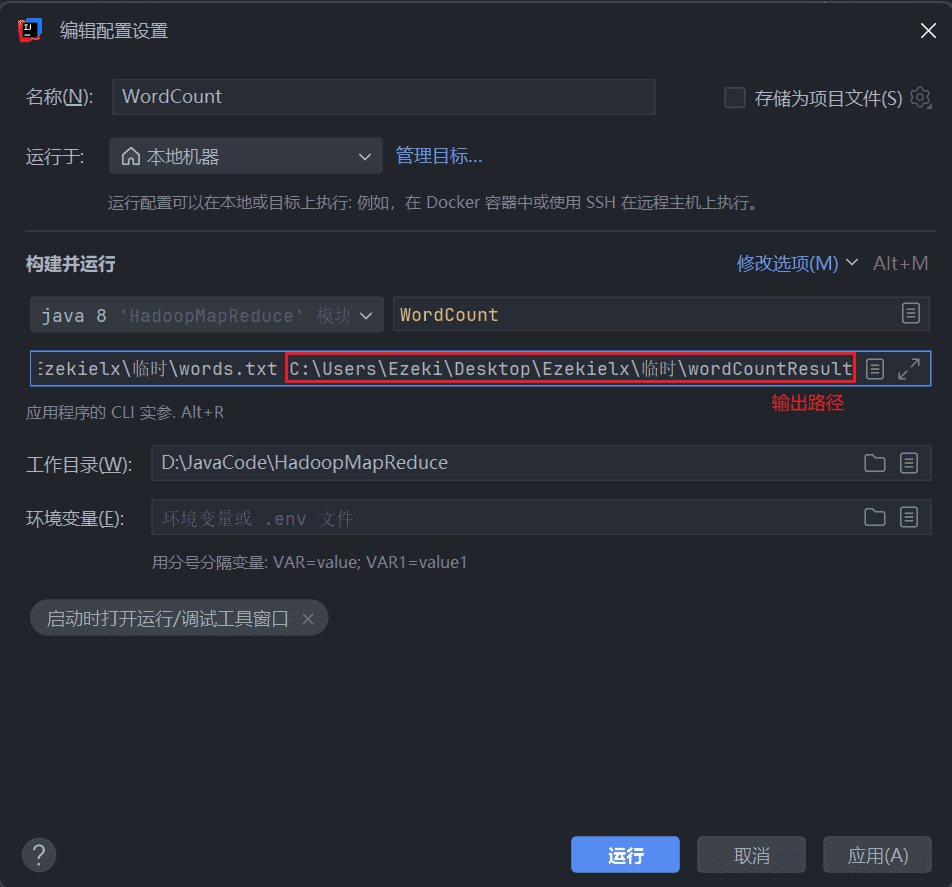
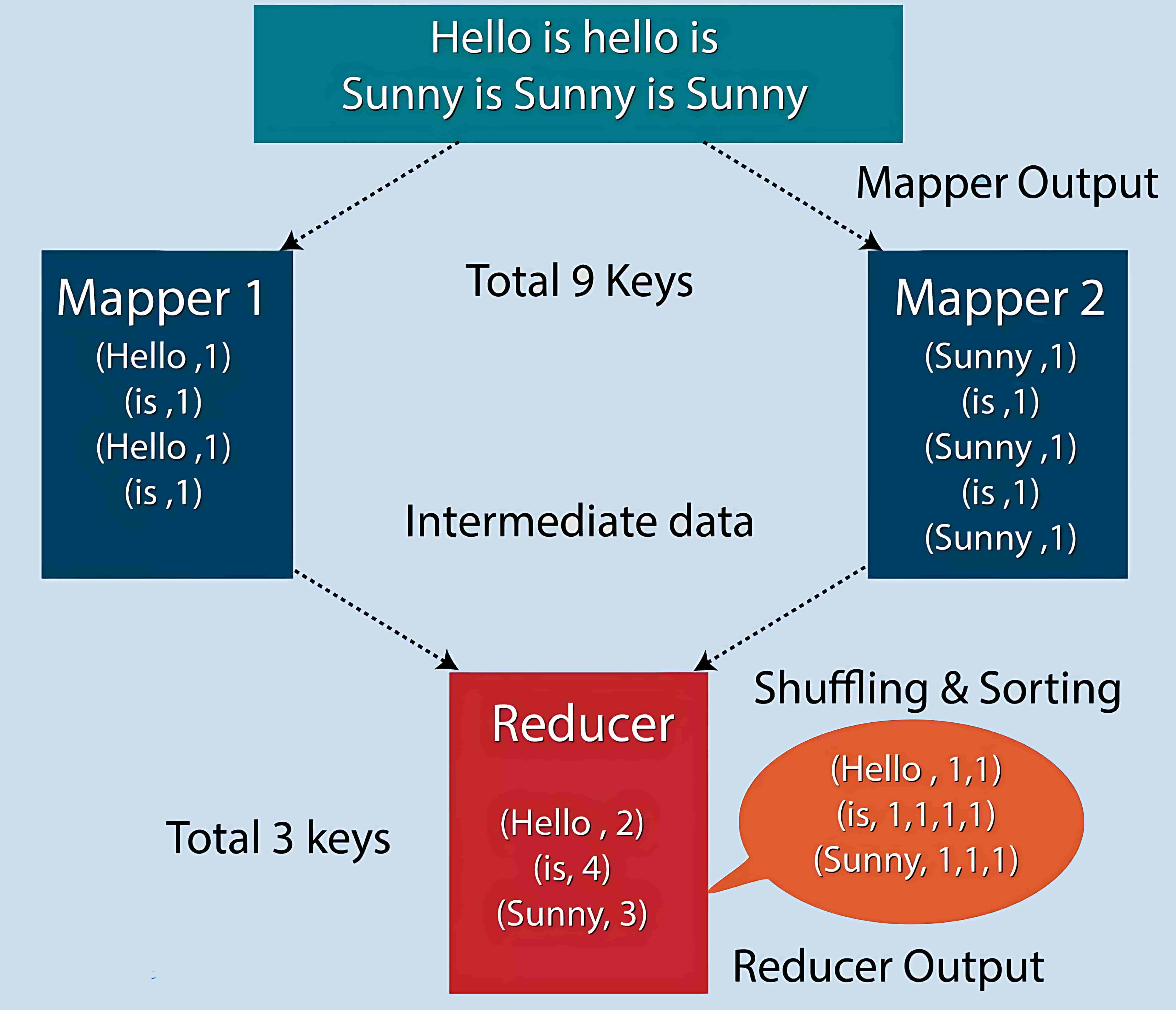
6、MapReduce Classic Example(MapReduce 经典示例)
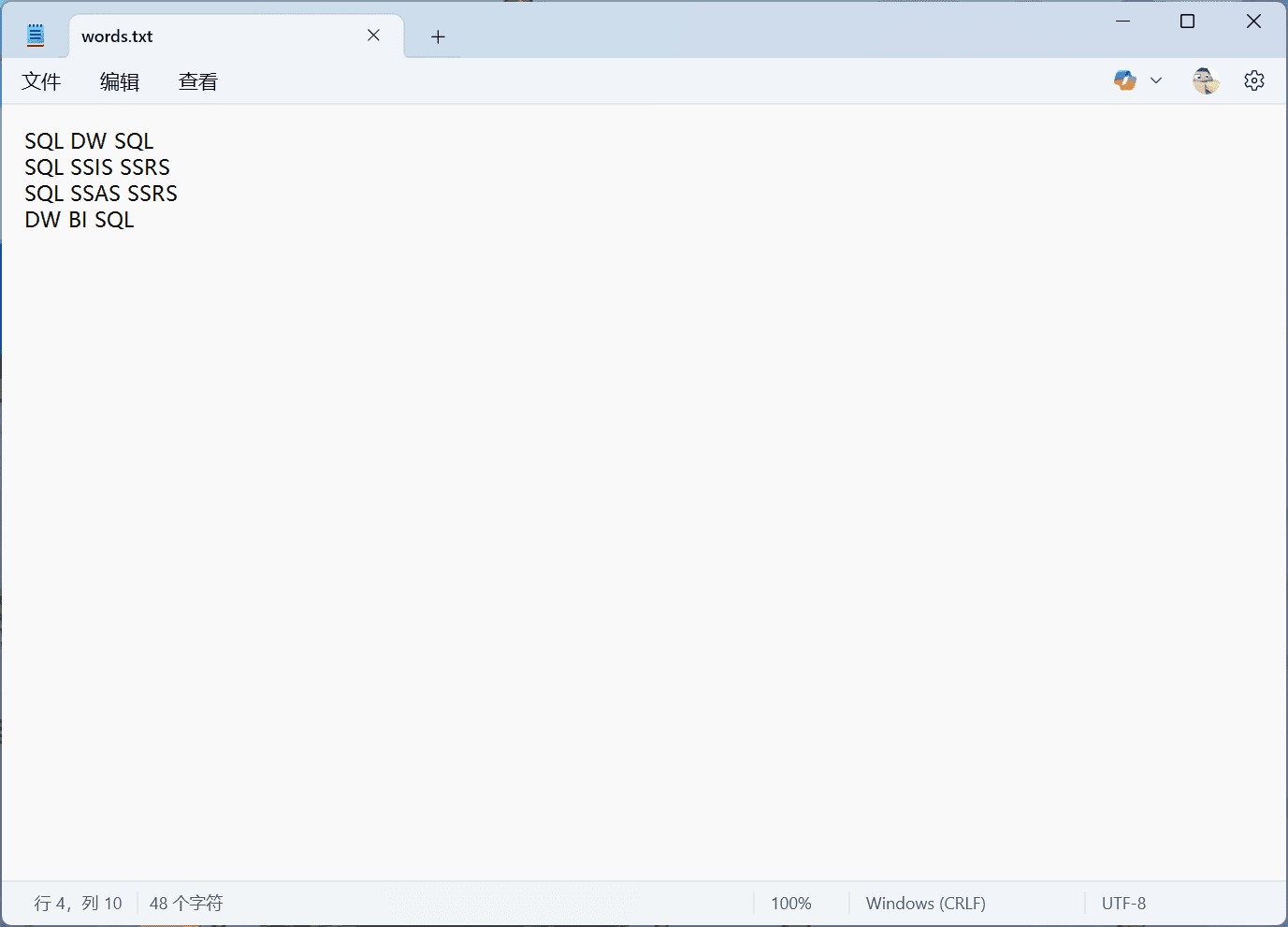
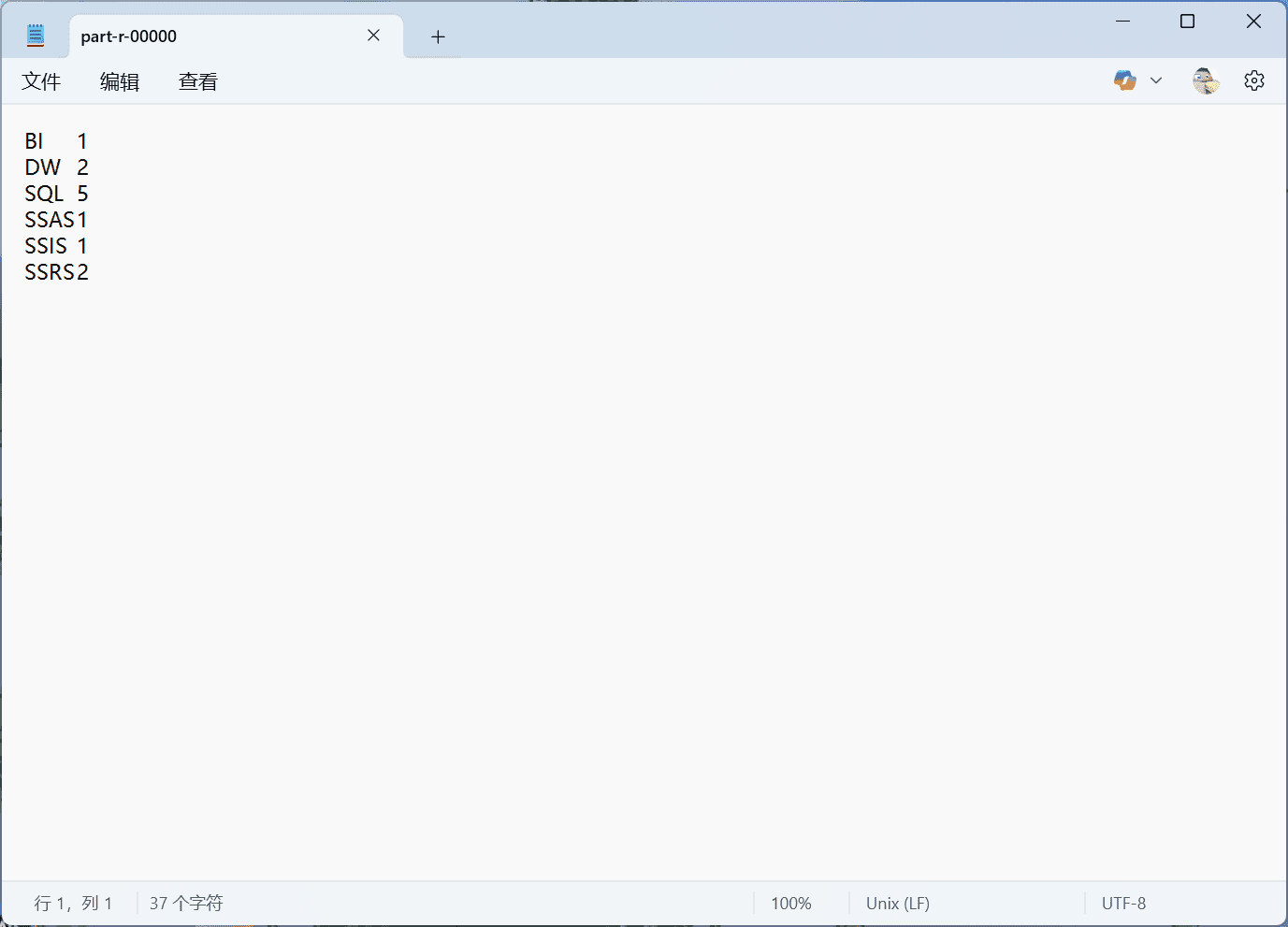
我们来看一个 MapReduce 的示例程序,以便对 MapReduce 环境中的实际运行方式有一个基本的了解。一个经典的入门示例是词频统计(word frequency statistics)。其目标是统计每个词在下列段落中出现的次数(作为 input.txt 文件):
SQL DW SQL
SQL SSIS SSRS
SQL SSAS SSRS
DW BI SQL
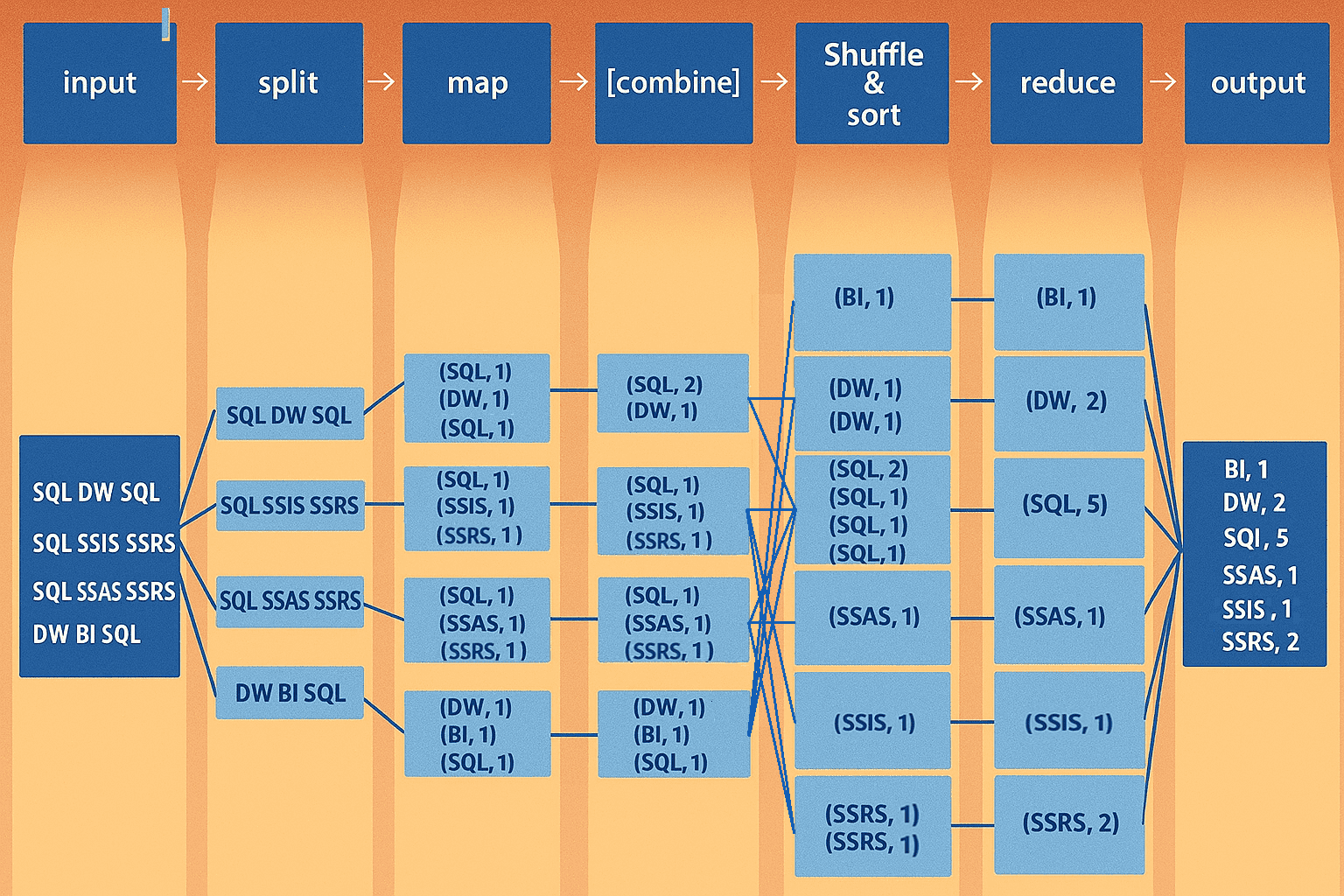
MapReduce 程序解释:
整个 MapReduce 程序基本上可以分为三个部分:
- Mapper 阶段代码
- Reducer 阶段代码
- Driver 代码
Mapper 阶段代码:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
// WordCountMapper 类继承自 Hadoop 的 Mapper 类
// 泛型参数说明:输入键类型为 LongWritable(行偏移量)+ 输入值类型为 Text(一行文本);输出键类型为 Text(单词),输出值类型为 IntWritable(单词出现次数)
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
// key:当前行在输入文件中的字节偏移量;value:当前行的文本内容;context:上下文,用于输出中间结果<单词, 1>
protected void map(LongWritable key, Text value, Context context) throws InterruptedException, IOException {
// toString() 方法会将输入的 Text 类型转换为普通的字符串,方便处理
String line = value.toString();
// 创建一个 StringTokenizer 对象,用于将整行文本按空格等分隔符拆分为单词
String[] words = line.split(" ");
// 遍历每个单词
for (String word : words){
// 忽略空字符串(例如多个连续空格可能造成空单词)
if (!word.isEmpty()) {
// 输出 <单词, 1>,表示该单词出现一次
context.write(new Text(word), new IntWritable(1));
}
}
}
}
Reducer 阶段代码:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
// WordCountReducer 类继承自 Hadoop 的 Reducer 类
// 泛型参数说明:输入键类型为 Text(单词),输入值类型为 IntWritable(一组表示次数的值);输出键类型为 Text(单词),输出值类型为 IntWritable(总次数)
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
// reduce 方法会被 Hadoop 自动调用,每处理一个单词及其所有的值时执行一次
// key:当前单词;values:该单词出现次数的集合;context:用于输出结果
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws InterruptedException, IOException {
// 用于累加该单词出现的总次数
int sum = 0;
// 遍历所有的值,累加求和
for (IntWritable val : values) {
// get() 方法获取 IntWritable 对象中的 int 值
sum += val.get();
}
// 输出 <单词, 总次数>
context.write(key, new IntWritable(sum));
}
}
Driver 代码:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static void main(String[] args) throws Exception {
// 创建配置对象
Configuration conf = new Configuration();
// 创建 Job 实例,并设置任务名称
Job job = Job.getInstance(conf, "WordCount");
// 设置主类,用于打包 JAR 时指定入口点
job.setJarByClass(WordCount.class);
// 设置 Mapper 和 Reducer 类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 设置 Mapper 输出键值类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 设置 Reduce 输出键值类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 设置输入和输出路径(从命令行参数传入)
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 提交任务并等待完成
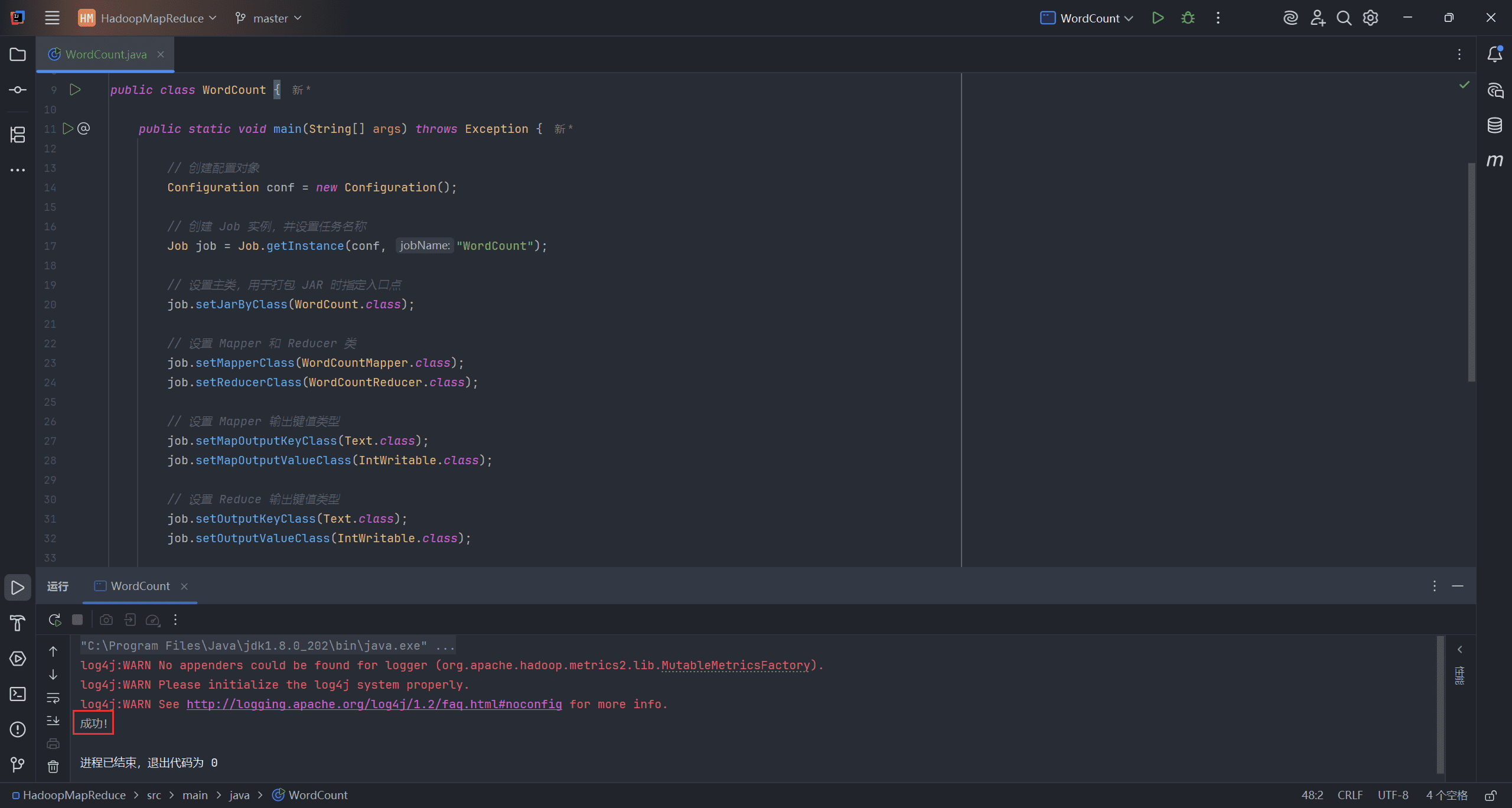
boolean completed = job.waitForCompletion(true);
// 打印结果
if (completed) {
System.out.println("成功!");
} else {
System.out.println("失败!");
}
}
}