
一、Introduction of Spark Running Mode(Spark 运行模式介绍)
Spark 可以在多种模式下运行,可以在单机上以本地模式或伪分布式模式运行。当在集群中以分布式模式运行时,底层的资源调度可以使用 Mesos、YARN,或者 Spark 自带的 Standalone 模式。在介绍每种模式之前,先了解一些基本概念和模型。
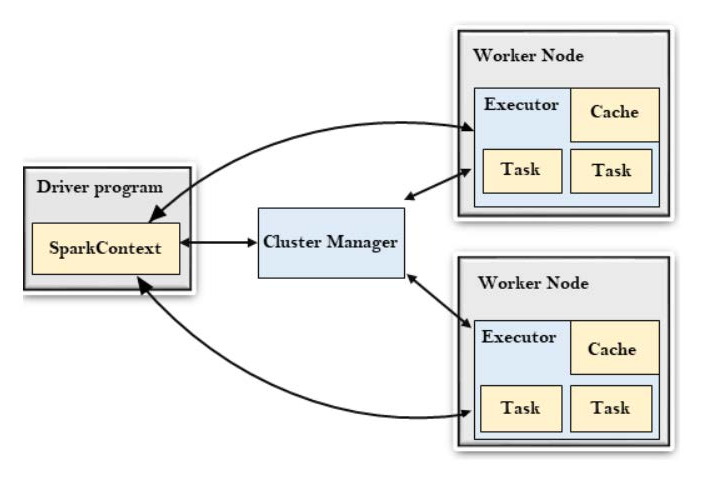
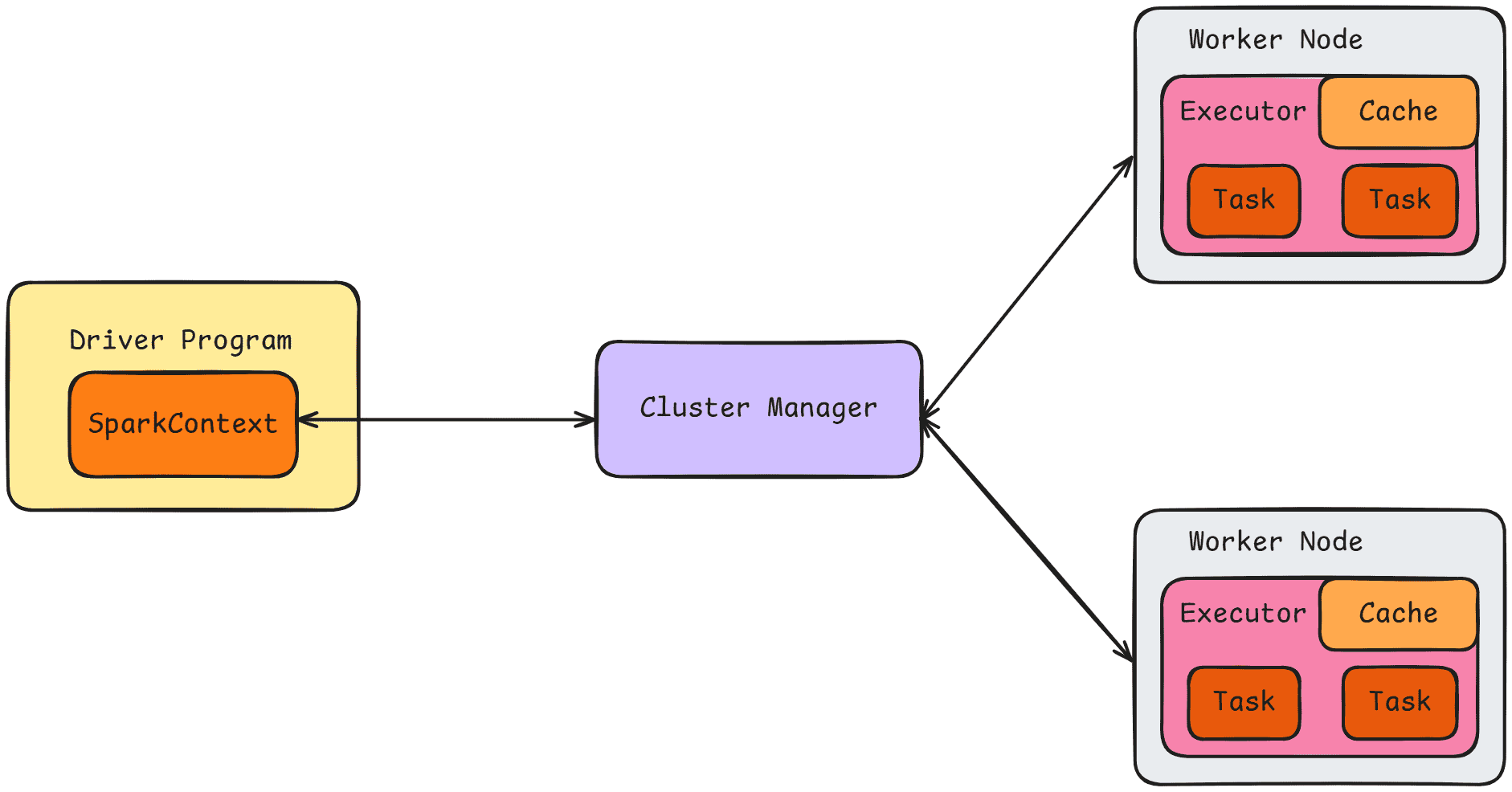
- Application(应用):类似于 Hadoop MapReduce,是用户编写的 Spark 应用程序,其中包含 Driver 函数的代码,以及在集群多个节点上运行的 Executor 代码。
- Driver(驱动程序):Spark 中的 Driver 运行应用程序的 main() 函数,并创建 SparkContext,用于为 Spark 应用准备运行环境。
- Executor(执行器):在 Worker 节点上运行的进程,负责执行具体任务,并将数据存储在内存或磁盘中。
- Cluster Manager(集群管理器):指获取集群资源的外部服务。
- Worker(工作节点):集群中能够运行应用程序代码的任意节点。
- Task(任务):发送给 Executor 的工作单元,是运行应用程序的基本执行单位。
- Job(作业):由多个任务组成的并行计算,由 Spark 的 Action 操作触发。
- Stage(阶段):每个作业会被划分为若干任务组(Task Set)。
- RDD(弹性分布式数据集):Spark 的基本数据单元,可以通过一系列算子进行操作。
- Shared variables(共享变量):在运行 Spark 应用程序时,可能需要共享一些变量,以供 Task 或 Driver 使用。
- Shuffle Dependency(洗牌依赖):需要计算父 RDD 的所有分区数据,然后在不同节点之间执行 Shuffle。
- Narrow Dependency(窄依赖):一个子 RDD 的分区(partition)只依赖于父 RDD 的一个或少数几个分区。不需要进行 Shuffle 操作。
- DAG Scheduler(DAG 调度器):基于作业(Job)构建基于阶段的有向无环图(DAG),并将阶段提交给任务调度器(Task Scheduler)。
1、The running mode and process of Spark(Spark 的运行模式与运行过程)
当应用提交到 Spark Context 时,各种运行模式需要额外的接口程序来配合使用。
目前 Spark 的 Master 支持 local、Yarn-Client、Yarn-Cluster、Spark、Mesos 等模式,而 deploy mode 必须是 cluster 或 client 之一。
这些运行模式的工作流程大致相似,主要区别在于它们各自有不同的 资源分配 和 任务调度模块,用于执行实际的计算任务。
当 Spark 应用运行时,Spark Context 首先在 Driver 程序中被创建,作为调度的入口。在初始化过程中,会创建两个模块:
- DAG Scheduler(阶段调度器)
- Task Scheduler(任务调度器)
DAG Scheduler 是基于阶段的调度模块,它会为每个 Spark Job 计算带有依赖关系的多个 Stage,并将每个 Stage 划分成一组具体任务(Task),然后以 Task 集合的形式提交给底层的 Task Scheduler 进行具体执行。
Task Scheduler 负责启动具体任务,并进行任务的监控和性能报告。而任务执行所需的资源则需要向 Cluster Manager 申请。
2、Spark Standalone Mode(Spark 独立模式)
Spark 自带有独立集群(Standalone Cluster)。它的架构简单,安装和配置都很方便。
独立集群由 Master 和 Worker(也称为 Slave) 进程组成:
- Master 进程作为集群管理器,负责接收需要运行的应用,并在 Worker 节点之间分配资源(可用的 CPU 核心)。
- Worker 进程负责启动应用程序的 Executor(在 cluster 部署模式下还会启动 Driver),用于执行具体任务。
回顾前面的概念:
- Driver 负责协调和监控 Spark 作业的执行;
- Executor 则负责运行作业中的具体任务。
Master 和 Worker 可以运行在同一台机器上,从而实现 Spark 的本地集群模式(Local Cluster Mode),但这并不是 Spark 独立集群的典型使用方式。在实际应用中,通常会将 Worker 分布在多台节点上,以避免单机资源的限制。
以一个运行在两台节点、包含两个 Worker 的 Spark 独立集群为例,执行流程如下:
- 客户端进程向 Master 提交一个应用程序;
- Master 指示其中一个 Worker 启动 Driver;
- Worker 启动一个 Driver JVM;
- Master 指示两个 Worker 启动该应用程序的 Executor;
- Worker 启动 Executor JVM;
- Driver 与 Executor 之间直接通信,而不依赖集群的 Master 或 Worker 进程。
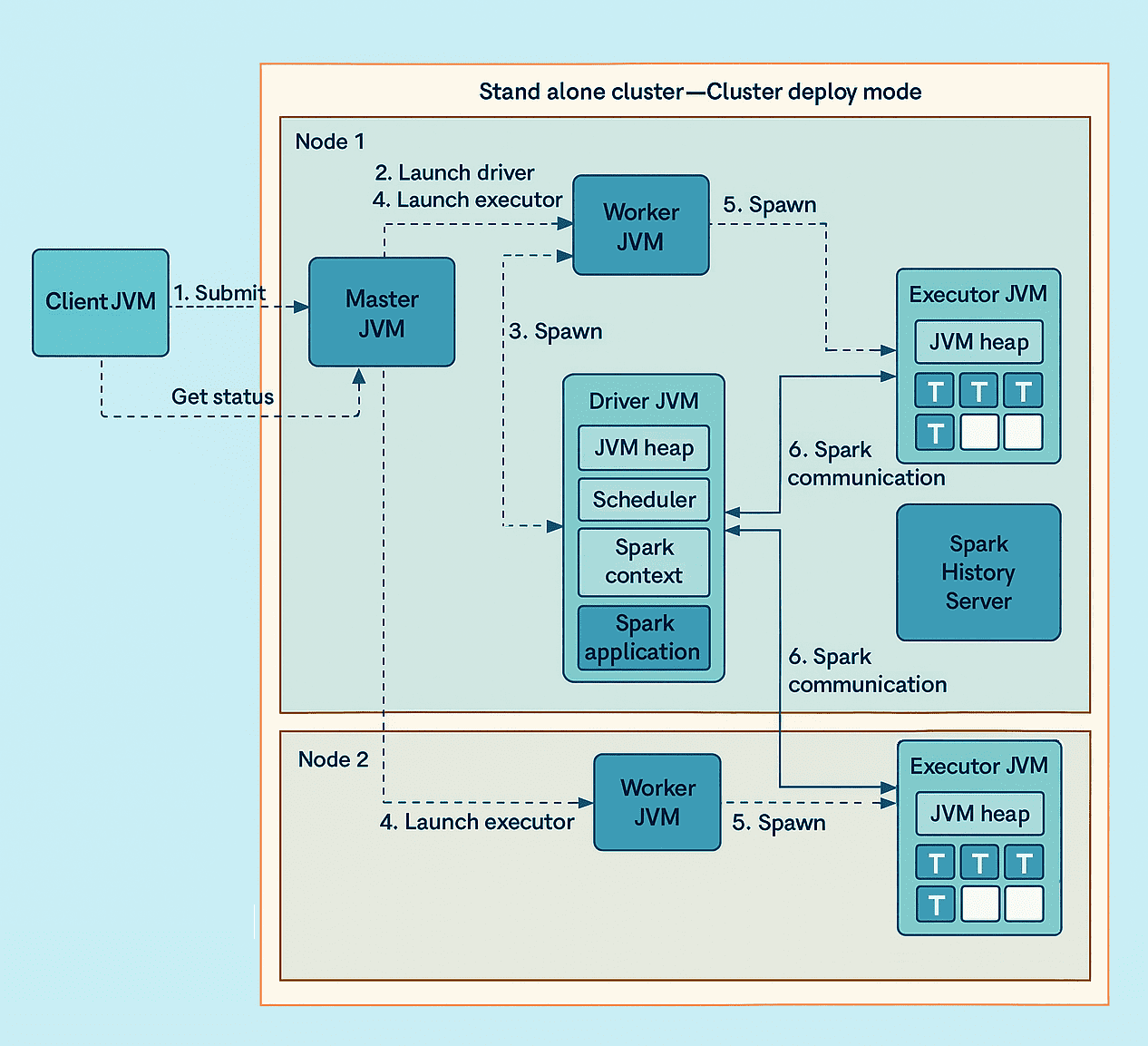
图中仅展示了一个应用程序在集群中运行的情况。如果有多个应用程序同时运行,每个应用程序都会拥有自己独立的一组 Executor,以及一个独立的 Driver(根据 deploy 模式运行在集群中或客户端 JVM 中)。
Spark Standalone 部署:
在 Standalone 模式 下部署 Spark 时,需要将 Spark 的部署包放置到每个节点上,并且各节点的部署目录必须保持一致。同时,Master 节点必须配置为免密登录,以便能够访问其他节点。
需要修改的配置文件位于 $SPARK_HOME/conf/ 目录下,主要包括:
spark-defaults.confslaves
在 slaves 文件 中保存 Worker 节点的主机名或 IP 地址,例如:
192.168.144.145
192.168.144.146
192.168.144.147
在 spark-env.sh 文件中,可以配置如下属性:
-
SPARK_MASTER_PORT:Master 服务端口,默认值为 7077。
-
SPARK_WORKER_INSTANCES:每个 Worker 节点上运行的 Worker 进程数。
-
SPARK_MASTER_WEBUI_PORT:Master 节点对应的 Web 服务端口。
-
SPARK_DAEMON_JAVA_OPTS:
-
-Dspark.deploy.recoveryMode=ZOOKEEPER -
-Dspark.deploy.zookeeper.url=host1:port,host2:port -
-Dspark.deploy.zookeeper.dir=/spark用于指定 Master HA,依赖 Zookeeper 集群。
-
-
SPARK_JAVA_OPTS="-d spark rests.max =4":用于限制每个提交的 Spark 应用可以使用的 CPU 核心数。因为默认情况下,应用会使用整个集群所有剩余的 CPU 核心。
完成配置后,需要将修改后的 Spark 配置文件复制到集群中每个节点的相同路径下。
此外,可以在系统环境变量中配置 SPARK_HOME,这样就能更方便地使用 spark-shell 或其他 Spark 命令脚本。
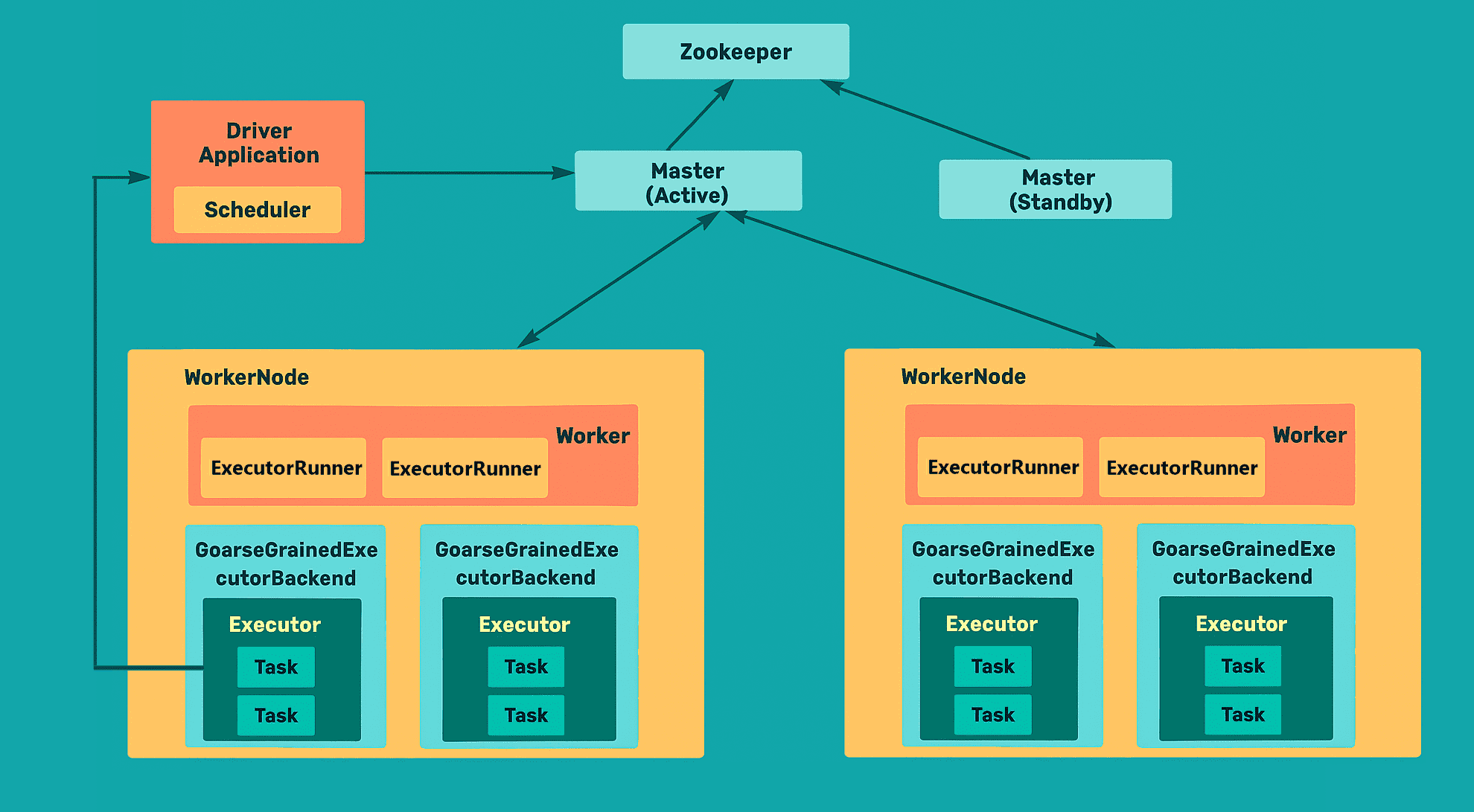
Spark Standalone 进程分析:
在 Spark Standalone 模式 中涉及的节点主要包括:
- Master 节点
- Worker 节点
- Client 节点
在运行过程中,主要涉及的进程有:
- Client
- Client 向 Master 提交应用
- Worker
- CoarseGrainedExecutorBackend(Executor 的后端实现类)
Spark 应用程序提交的具体步骤:
- 当 Spark 集群启动后,Worker 节点会通过 心跳机制(heartbeat) 与 Master 保持通信;
- SparkContext 连接到 Master 后,会向 Master 申请资源,Master 根据 Worker 的心跳信息来分配资源,并在 Worker 上启动 Executor 进程;
- SparkContext 将程序代码解析为 DAG(有向无环图)结构,并提交给 DAG Scheduler;
- DAG Scheduler 会将 DAG 拆分为多个 Stage,每个 Stage 又包含多个 Task;
- Stage 会被提交给 Task Scheduler,Task Scheduler 将任务分配给 Worker,并提交给 Executor 进程。Executor 会创建线程池来执行任务,并将执行结果汇报给 SparkContext,直到任务完成;
- 当所有任务执行完成后,SparkContext 会向 Master 注销并释放资源。
3、Spark Yarn-Cluster Mode(Spark Yarn-Cluster 模式)
在 Yarn-Cluster 模式 下,客户端(Client)通过 Yarn Client API 在 Yarn 集群中启动 Spark Driver 作为 Application Master。然后,Application Master 会向 Resource Manager 请求资源,并进一步启动 Executor 来运行具体的 Task。
Yarn-Cluster 部署:
- 需要一个客户端(Client),即能够向 Yarn 集群提交 Spark 应用的节点。
- Spark 需要部署在所有要运行的机器上。
- 在客户端的配置文件中需要设置 Yarn 和 HDFS 相关的属性,因为客户端需要读取 Yarn 的集群配置文件。
- 不需要启动 Spark 自带的 Worker 和 Master 节点。
- Spark 的部署包必须根据对应版本正确的 Yarn,否则会出现 Spark 与 Yarn 的兼容性问题。
当使用 Yarn-Cluster 模式时,需要修改 $SPARK_HOME/conf/spark-env 文件:
export HADOOP_HOME=/opt/hadoop-3.3.6
export HADOOP_CONF_DIR=/opt/hadoop-3.3.6/etc/hadoop
其中:
- HADOOP_HOME:当前节点的 HDFS 部署路径。
- HADOOP_CONF_DIR:HDFS 节点的配置文件路径,通常为
$HADOOP_HOME/etc/hadoop。
Yarn-Cluster 进程分析:
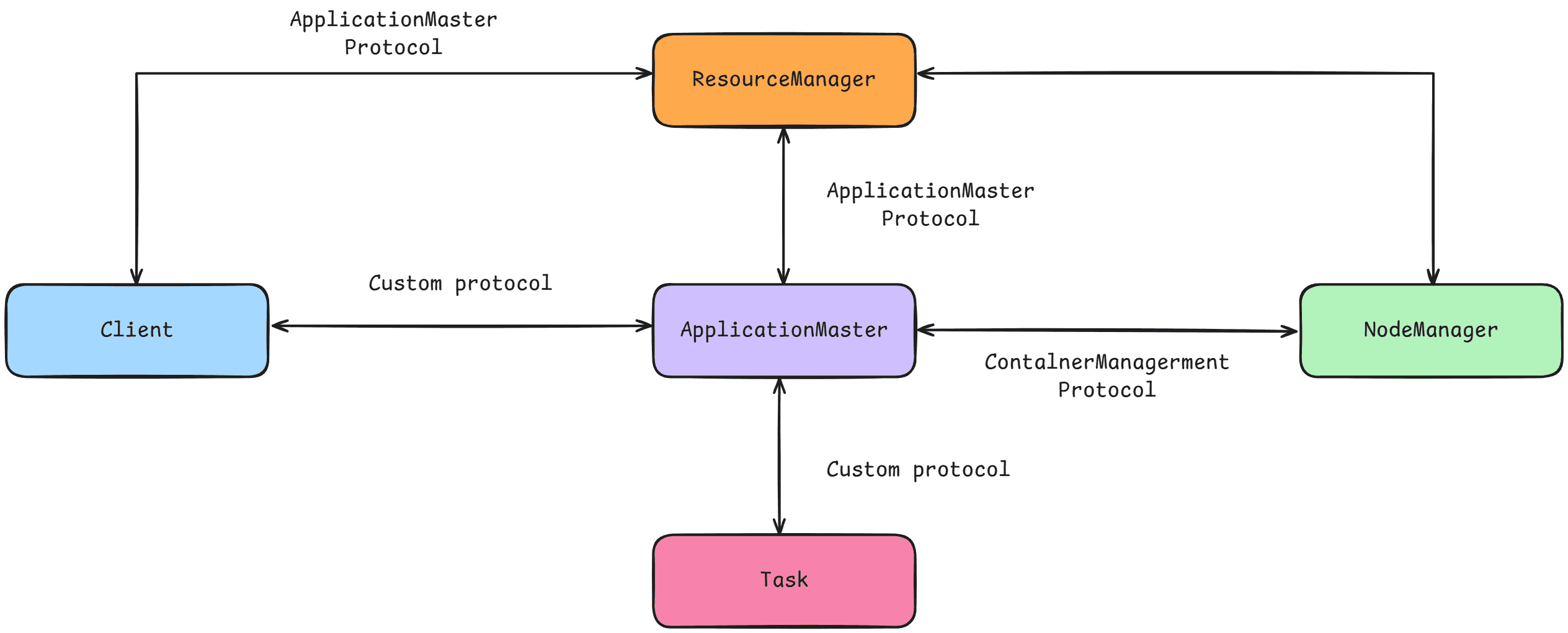
Yarn 的运行依赖于几个基本组件:
- Resource Manager(资源管理器)
- Node Manager(节点管理器)
- Container(容器)
这些是 Yarn 的基础。
在开发基于 Yarn 的应用时,用户需要自行开发以下模块:
- Application Master(应用程序调度器,负责资源申请、任务调度与监控)
- Client(应用提交入口,用户用来提交 Spark 作业的节点或进程)
- Task(最小计算单元,运行在 Executor 的线程池中执行具体逻辑)
在 Client 与 Resource Manager 之间是 Application Client Protocol 协议,主要用于 应用程序的提交。
在 Application Master 与 Resource Manager 之间是 Application Master Protocol 协议,Application Master 通过该协议向 Resource Manager 注册并申请相关资源。
在 Application Master 与 Node Manager 之间是 Container Management Protocol 协议,Application Master 通过该协议控制 Node Manager 启动 Container 并运行 Task。
在 Spark Yarn-Cluster 模式 中:
- Application Master 对应
org.apache.spark.deploy.yarn.ApplicationMaster - Client 对应
org.apache.spark.deploy.yarn.Client - Task 在运行过程中依附于 CoarseGrainedExecutorBackend
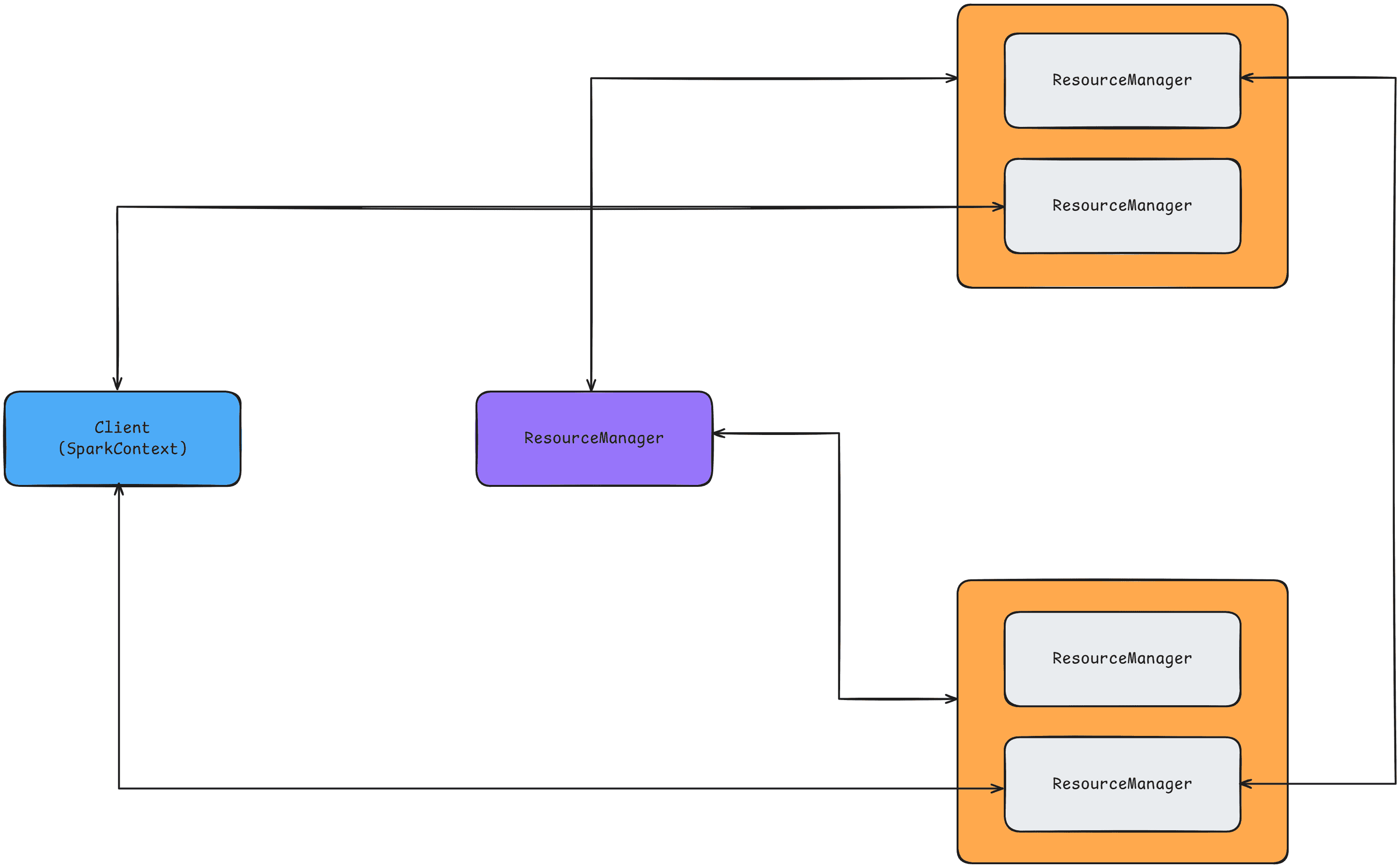
Spark Application 提交流程:
-
客户端提交应用
客户端将 Spark 应用提交到 YARN,提交工具可以是spark-submit等。 -
启动 ApplicationMaster
YARN 接收到请求后,会为应用分配第一个 Container,用于启动 ApplicationMaster,其中包含 SparkContext 的初始化。申请 -
资源启动 Executor
ApplicationMaster 通过 Yarn Allocation Handle 向 ResourceManager 申请资源,以便运行 Executor。 -
分配并启动 Executor
ResourceManager 将 Container 分配给 ApplicationMaster,随后 ApplicationMaster 与相应的 NodeManager 通信,在获得的节点上启动 Coarse-Grained Executor。在启动过程中,Executor 会向 ApplicationMaster 中的 SparkContext 注册,并申请任务。这与 Standalone 模式类似,只是 SparkContext 在 Yarn 模式下使用的是 Yarn Cluster Scheduler(它本质上是 TaskSchedulerImpl 的一个简单封装,增加了等待逻辑等)。
-
任务分发与执行
ApplicationMaster 中的 SparkContext 会将任务分发给 Coarse-Grained Executor Backend 执行。Executor 执行任务的同时,会将执行状态汇报给 SparkContext。
4、Spark Yarn-Client
在 Yarn-Client 模式 下,Driver 在客户端本地运行,适用于需要在本地进行交互的场景,例如 Spark Shell、Shark 等,因为运行结果可以直接获得。
Yarn-Client 部署:
在部署方面,Yarn-Client 和 Yarn-Cluster 模式差别不大,只是有几个参数需要在 spark-env.sh 文件中进行配置:
- SPARK_EXECUTOR_INSTANCES:在 Yarn 集群中启动的 ExecutorBackend 数量,默认值为 2。
- SPARK_EXECUTOR_CORES:每个 ExecutorBackend 占用的 CPU 核数。
- SPARK_EXECUTOR_MEMORY:每个 ExecutorBackend 使用的内存大小。
- SPARK_DRIVER_MEMORY:Spark 应用 Driver 运行时占用的内存大小,在 Yarn 中对应 ApplicationMaster。
- SPARK_YARN_APP_NAME:Spark 应用在 Yarn 中的名称。
- SPARK_YARN_QUEUE:应用提交到 Yarn 的队列,默认是
default。 - SPARK_YARN_DIST_FILES:程序执行时需要分发到每个 ExecutorBackend 的文件列表(以逗号分隔)。
- SPARK_YARN_DIST_ARCHIVES:程序执行时需要分发到每个 ExecutorBackend 的归档文件列表(以逗号分隔)。
Yarn-Client 运行过程分析:
在 Spark Yarn-Client 模式中,Client 指的是:org.apache.spark.deploy.yarn.Client,在运行过程中,任务会附着在 CoarseGrainedExecutorBackend 上执行。
当 SparkContext 启动时,在 Yarn-Client 模式下,Client 会调用 YarnClientSchedulerBackend 的 start 方法。此时,会指定 ApplicationMaster 为:org.apache.spark.deploy.yarn.ExecutorLauncher。
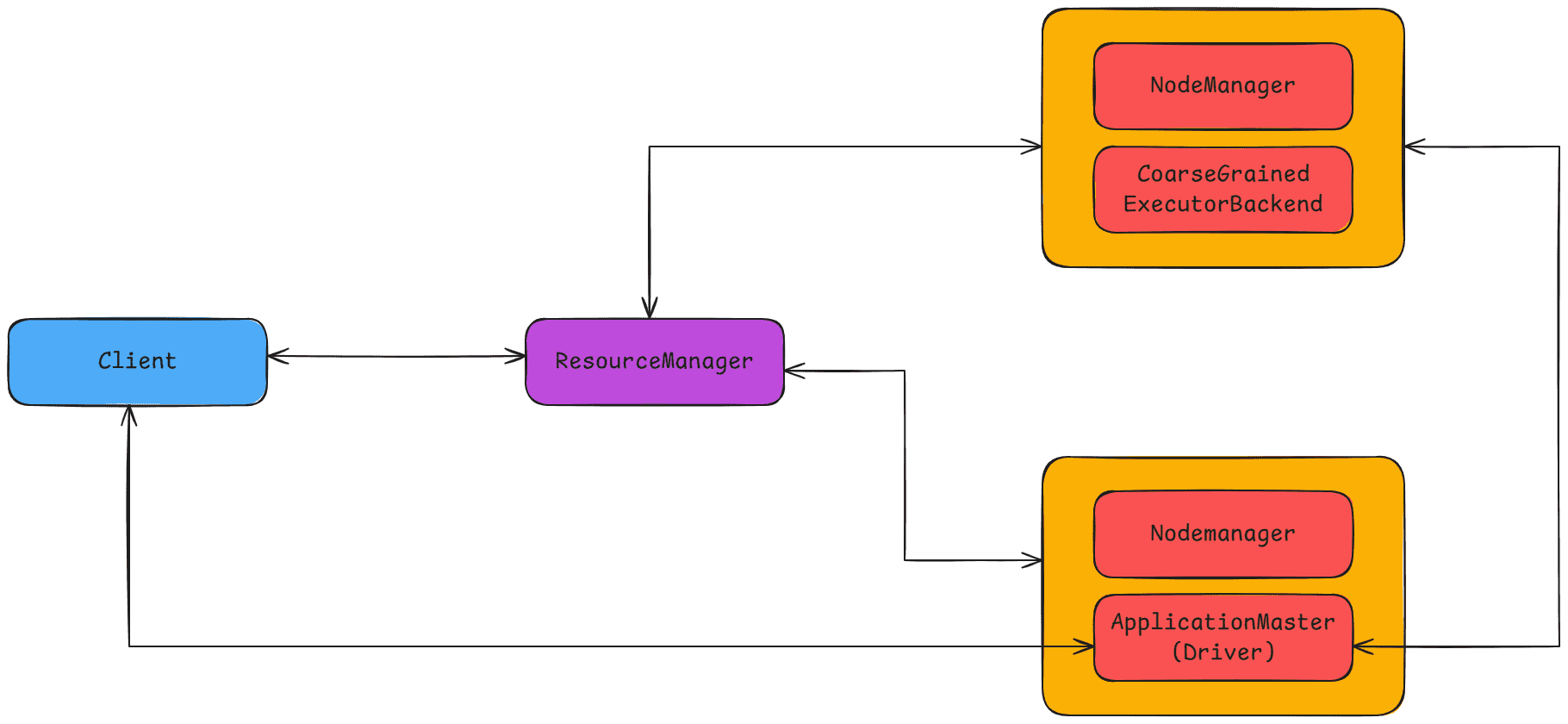
Spark Application 提交流程如下:
-
**客户端提交应用:**客户端将 Spark 应用提交到 Yarn,提交工具可以是
spark-submit等。此时,Driver 在客户端本地启动。 -
**启动 ApplicationMaster:**Yarn 接收到请求后,会为应用分配第一个 Container,用于运行 ApplicationMaster(即 ExecutorLauncher)。
需要注意的是,这里的 ApplicationMaster 不包含 Driver,它只负责 启动 Executor 并与客户端 Driver 通信。 -
申请资源启动 Executor:
ExecutorLauncher 通过 Yarn Allocation Handle 向 ResourceManager 申请资源,以便运行 Executor。 -
**分配并启动 Executor:**ResourceManager 将 Container 分配给 ExecutorLauncher,ExecutorLauncher 再与相应的 NodeManager 通信,在分配到的 Container 上启动 CoarseGrainedExecutorBackend。
当 CoarseGrainedExecutorBackend 启动后,会向运行在客户端的 SparkContext 注册,并请求任务。
这与 Yarn-Cluster 模式不同:在 Yarn-Client 模式下,SparkContext 在应用初始化时使用的是 YarnClientSchedulerBackend,与 Yarn-Client Cluster Scheduler 配合进行任务调度。而 Yarn-Client Cluster Scheduler 只是 对 TaskSchedulerImpl 的一个简单封装,例如增加 Executor 等待逻辑。
-
**任务分发与执行:**运行在客户端的 SparkContext 将任务分配给 CoarseGrainedExecutorBackend 执行。
Executor 执行任务的同时,会将运行状态汇报给客户端的 SparkContext。
5、Spark On Mesos(在 Mesos 上运行 Spark)
在 Standalone 集群部署 中,下图中的集群管理器(Cluster Manager)是一个 Spark Master 实例。
当使用 Mesos 时,Mesos Master 会取代 Spark Master,作为集群管理器。
当 Driver 创建一个作业并开始发出任务进行调度时,Mesos 决定由哪些机器来处理哪些任务。
由于 Mesos 在调度这些大量短生命周期任务时会考虑到其他框架,因此多个框架可以在同一个集群中共存,而无需进行静态的资源划分。
Spark on Mesos 是许多公司采用的一种模式,也是官方推荐的模式。Spark 在开发时就考虑了对 Mesos 的支持,因此相比于 YARN,Spark 在 Mesos 上运行更灵活、更自然。
在 Spark on Mesos 环境中,用户可以选择两种调度模式来运行他们的应用:
粗粒度模式(Coarse-grained Mode):
- 每个应用的运行环境由一个 Driver 和若干个 Executor 组成。
- 每个 Executor 会消耗固定数量的资源,并在内部运行多个任务(即“slots”)。
- 在应用的任何任务开始之前,必须先分配好所需的全部资源,并且在整个应用的生命周期内,这些资源始终被占用,即使它们没有被完全利用。
比如,如果一个应用需要 5 个 Executor,每个 Executor 需要 5GB 内存和 5 个 CPU,那么 Mesos 必须先分配好这些资源并启动 Executor,之后才能调度任务。
在执行过程中,Mesos Master 和 Mesos Slave 并不会监控每个 Executor 内部任务的状态。Executor 会通过内部通信机制直接向 Driver 汇报任务状态。
本质上,每个应用在 Mesos 上都会为自己创建一个虚拟集群来使用。
细粒度模式(Fine-grained Mode):
由于粗粒度模式存在资源浪费问题,Spark on Mesos 还提供了另一种调度方式:细粒度模式。
这种模式类似于当今的云计算,体现了“按需分配”的理念。
运行流程:
-
与粗粒度模式相同,应用启动时会首先启动 Executor。
-
但在细粒度模式下,Executor 初始只占用运行所需的基本资源,而不需要提前为未来的任务预留资源。
-
Mesos 会为每个 Executor 动态分配资源:
- 一旦分配到一些资源,就可以运行新的任务;
- 每个任务运行结束后,相应的资源会立即释放。
-
每个 Task 会将状态汇报给 Mesos Slave 和 Mesos Master,
-
这使得细粒度模式可以实现更精细的管理和更强的容错能力。
-
这种调度模式类似于 MapReduce 的调度方式,每个任务都是完全独立的。