
一、Hive Introduction(Spark 简介)
Apache Hive 是一个开源的数据仓库软件,用于读取、写入和管理存储在 Apache Hadoop 分布式文件系统(HDFS)或其他数据存储系统(如 Apache HBase)中的大型数据集文件。Hive 允许 SQL 开发人员编写类似于标准 SQL 的 Hive 查询语言(HQL)语句,用于数据查询和分析。它的设计目的是让 MapReduce 编程更加简单,因为使用 Hive 时无需了解和编写冗长的 Java 代码,只需使用 HQL 更简洁地编写查询,Hive 就会自动生成对应的 Map 和 Reduce 函数。
Hive 的使用方式看起来像传统数据库中的 SQL 访问。但 Hive 是基于 Apache Hadoop 的,因此在操作上存在一些关键差异。首先,Hadoop 适用于长时间的顺序扫描,而 Hive 依赖于 Hadoop,所以查询延迟很高(通常需要几分钟)。这意味着 Hive 不适合需要快速响应的应用场景。其次,Hive 是以读取为主的系统,不适合需要大量写操作的事务处理。Hive 更适合执行数据仓库相关任务,例如抽取/转换/加载(Extract/Transform/Load,ETL)、报表和数据分析,并且提供了通过 SQL 方便访问数据的工具。
1、Hive Overview(Hive 概述)
Hive 是一种建立在 Hadoop 文件系统上的数据仓库架构,用于分析和管理存储在 HDFS 中的数据。它主要提供以下功能:
- 提供一系列工具,用于数据的抽取 / 转换 / 加载(Extract / Transform / Load,ETL);
- 提供一种机制,可以存储、查询和分析存储在 HDFS(或 HBase)中的大规模数据;
- 查询通过 MapReduce 完成(并非所有查询都需要 MapReduce,例如 select * from XXX);
- 在 Hive 3.1.1 中,类似于 select a, b from XXX 这样的查询可以通过配置来实现不依赖 MapReduce 的执行。
我们如何分析和管理数据?
Hive 定义了一种类似 SQL 的查询语言,称为 HQL。对于熟悉 SQL 的用户来说,可以直接使用 Hive 查询数据。同时,这种语言也允许熟悉 MapReduce 的开发人员编写自定义的 mapper 和 reducer,用来完成内置 mapper 和 reducer 无法完成的复杂分析任务。
Hive 允许用户编写自己的函数(UDF),并在查询中使用。Hive 中有三种类型的 UDF:
- 用户自定义函数(UDF, User Defined Functions);
- 用户自定义聚合函数(UDAF, User Defined Aggregation Functions);
- 用户自定义表生成函数(UDTF, User Defined Table Generating Functions)。
如今,Hive 已成为一个成功的 Apache 项目,许多组织将其作为通用的、可扩展的数据处理平台。当然,Hive 与传统关系型数据库有很大不同。Hive 会将外部任务解析成一个 MapReduce 可执行计划。启动 MapReduce 是一个高延迟事件,每次提交和执行任务都需要一定的时间开销。这往往决定了 Hive 只能处理一些高延迟的应用场景。同时,由于设计目标不同,Hive 目前存在以下缺点:
- Hive 目前不支持事务;
- 表数据不能被修改(不能更新、删除、插入),数据只能通过文件追加或重新导入;
- 列不能建立索引(Hive 虽然支持索引,但并不能提升查询速度。如果想要提升查询性能,需要学习 Hive 的分区和分桶机制)。
Hive 的数据存储模型
Hive 的数据分为表数据(table data)和元数据(metadata)。表数据就是 Hive 表中存放的数据;而元数据用于存储表名、列、分区及其属性、表的属性(是否为外部表等)、以及表数据所在的目录。下面分别介绍。
Hive 数据存储
Hive 基于 Hadoop 分布式文件系统,其数据存储在 HDFS 中。Hive 本身没有特殊的数据存储格式或数据索引。建表时只需告诉 Hive 列和行的分隔符,Hive 就能解析数据。因此,将数据导入 Hive 表本质上就是把数据移动到表所在的目录(如果数据本来就在 HDFS 中)。但是,如果数据在本地文件系统中,则需要将数据拷贝到表所在的目录中。
2、Hive Architecture(Hive 架构)
以下架构说明了向 Hive 提交查询的流程。
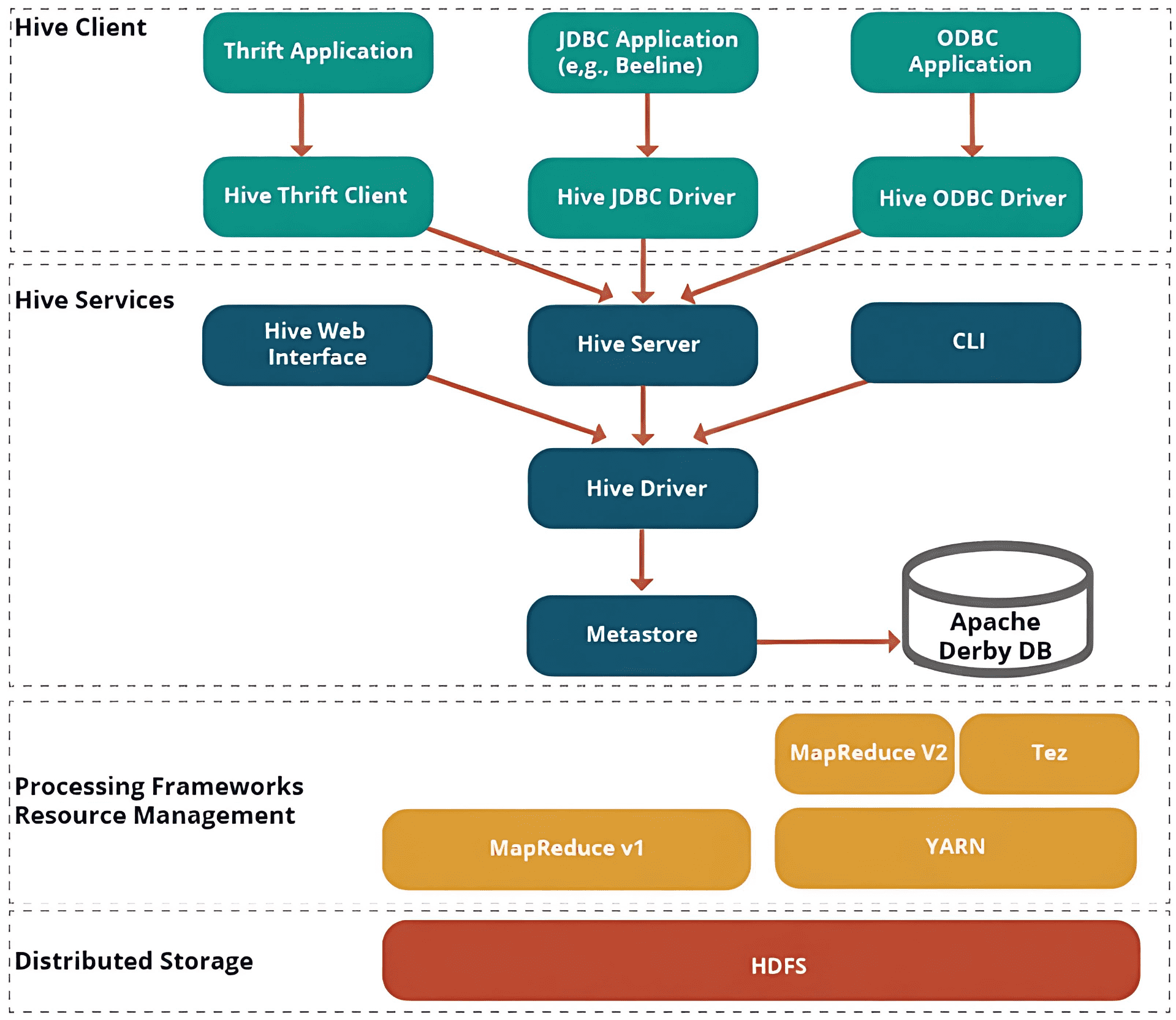
Hive 客户端
Hive 允许使用多种语言编写应用程序,包括 Java、Python 和 C++。它支持多种类型的客户端,例如:
- Thrift Server(Thrift 服务器) - 它是一个跨语言的服务提供平台,可以处理所有支持 Thrift 的编程语言发出的请求。
- JDBC Driver(JDBC 驱动) - 用于在 Hive 与 Java 应用程序之间建立连接。JDBC 驱动位于类 org.apache.hadoop.hive.jdbc.HiveDriver 中。
- ODBC Driver(ODBC 驱动) - 允许支持 ODBC 协议的应用程序连接到 Hive。
Hive 服务
Hive 提供以下服务:
- Hive CLI(Hive 命令行接口) - Hive CLI(命令行接口)是一个可以执行 Hive 查询和命令的 Shell。
- Hive Web User Interface(Hive Web 用户界面) - Hive Web UI 是 Hive CLI 的替代方案,提供基于 Web 的图形界面,用于执行 Hive 查询和命令。
- Hive MetaStore(Hive 元数据存储) - 它是一个中央存储库,用于存储仓库中各种表和分区的结构信息。还包括列及其类型信息的元数据、用于读写数据的序列化和反序列化器(serializer/deserializer),以及存储数据的对应 HDFS 文件。
- Hive Server(Hive 服务器) - 又称 Apache Thrift Server,它接收来自不同客户端的请求,并将请求提供给 Hive Driver。
- Hive Driver(Hive 驱动器) - 它接收来自 Web UI、CLI、Thrift 以及 JDBC/ODBC 驱动的查询请求,并将查询传递给编译器。
- Hive Compiler(Hive 编译器) - 编译器的作用是解析查询,对不同查询块和表达式进行语义分析,并将 HiveQL 语句转换为 MapReduce 作业。
- Hive Execution Engine(Hive 执行引擎) - 优化器以 MapReduce 任务和 HDFS 任务的有向无环图(DAG)形式生成逻辑计划。最终,执行引擎按照依赖关系顺序执行这些任务。
二、Hive Data Models(Hive 数据模型)
Hive 是一个建立在 Hadoop 之上的开源数据仓库系统,用于查询和分析存储在 Hadoop 文件中的大型数据集。它可以处理 Hadoop 中的结构化数据和半结构化数据。Apache Hive 中的数据可以分为:
- Table(表)
- Partition(分区)
- Bucket(分桶)
Tables(表)
Apache Hive 表类似于关系型数据库表。Hive 表由数据组成,其布局通过相关元数据进行描述。可以在这些表上执行筛选(filter)、连接(join)、投影(project)和并集(union)等操作。
通常,在 Hadoop 中,数据存储在 HDFS 中,但 Hive 将元数据存储在关系型数据库中,而不是 HDFS 中。Hive 中存在两种类型的表:
- Managed or Internal Tables(托管表或内部表)
- External Tables(外部表)
Partition(分区)
Hive 表通过根据某个列或分区键将相同类型的数据分组来组织成分区。每个表都有一个分区键用于标识。分区可以加快查询和切片处理速度。
分区通过只扫描相关数据而非整个数据集,从而减少延迟,提高查询速度。
Buckets(分桶)
Hive 中的表或分区还可以进一步划分为分桶,这需要使用哈希函数。
Hive 分桶本质上就是表目录中的文件,这些文件可以是分区的也可以是未分区的。你甚至可以选择 n 个桶来对数据进行划分。
三、Hive Data Types(Hive 数据类型)
Hive 中的数据类型用于指定 Hive 表中列的类型。Hive 的数据类型分为两类:Primitive Data Type(原始数据类型) 和 Complex Data Type(复杂数据类型)。
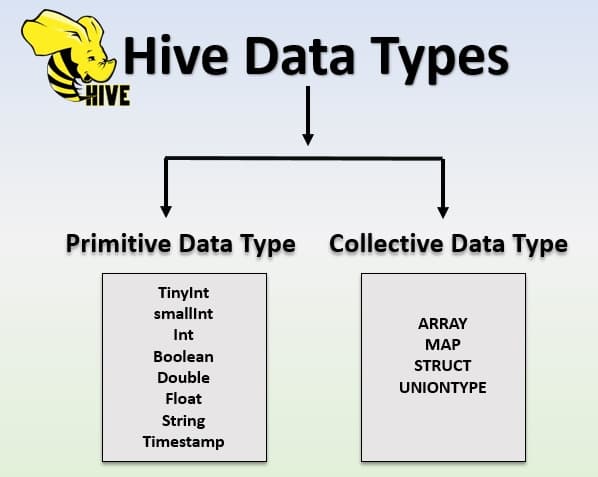
Primitive Data Types(原始数据类型)
Hive 支持多种大小的整数类型和浮点数类型、布尔类型,以及任意长度的字符串。自 Hive v0.8.0 起,还新增了时间戳类型和二进制字段类型。
Complex Data Types(复杂数据类型)
Hive 支持列类型为结构体(struct)、映射(map)、联合(union)和数组(array)。‘
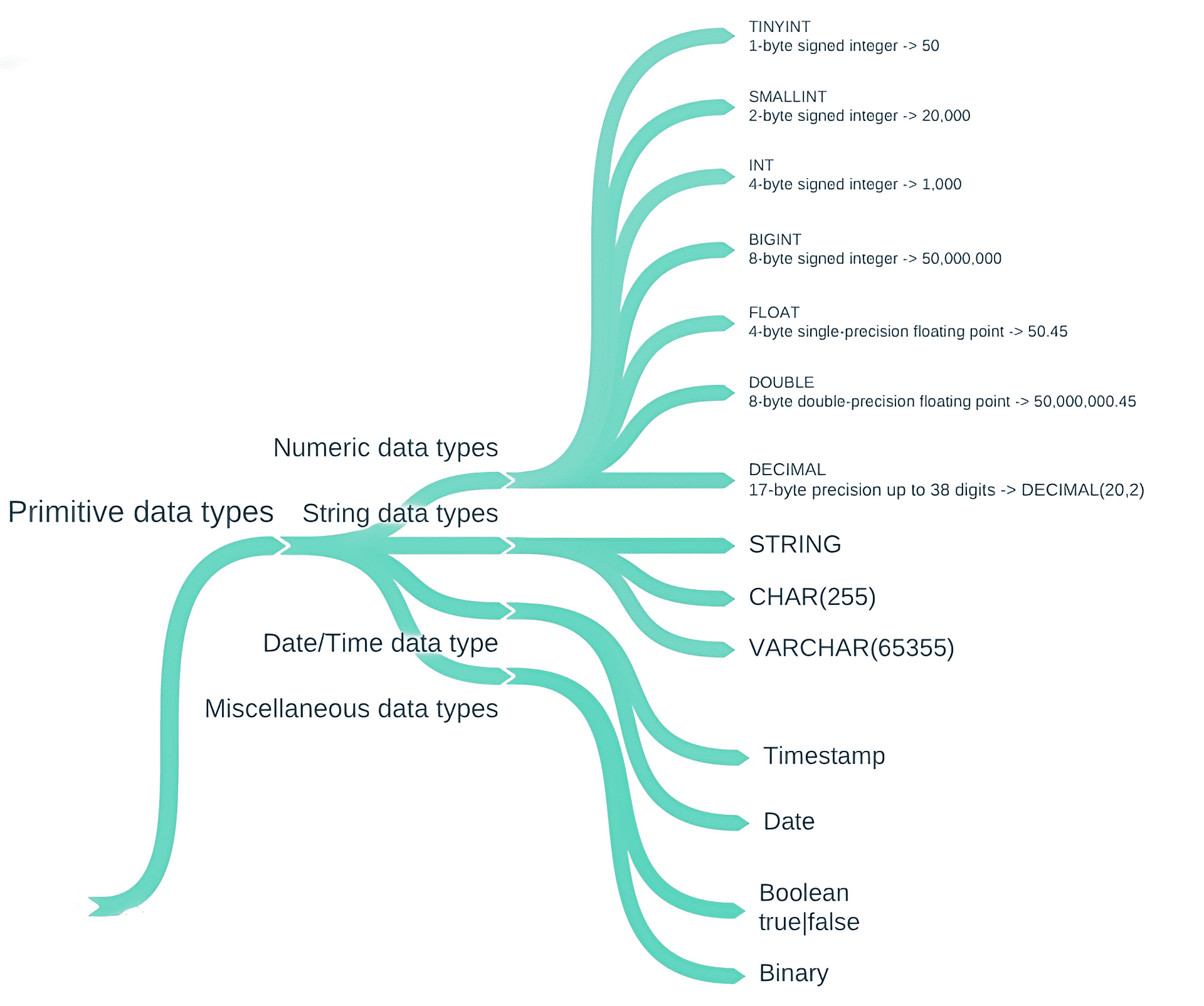
1、Hive Primitive Data Type(Hive 原始数据类型)
Hive 是用 Java 开发的,Hive 中的基本数据类型与 Java 中的基本数据类型一一对应,唯一的例外是字符串类型。
带符号的整数类型:TINYINT、SMALLINT、INT 和 BIGINT,分别对应 Java 的 byte、short、int 和 long 数据类型,它们分别是 1 字节、2 字节、4 字节和 8 字节的有符号整数。
Hive 的浮点数数据类型 FLOAT 和 DOUBLE,对应于 Java 的基本数据类型 float 和 double。
Hive 的 BOOLEAN 类型等价于 Java 的基本数据类型 Boolean。
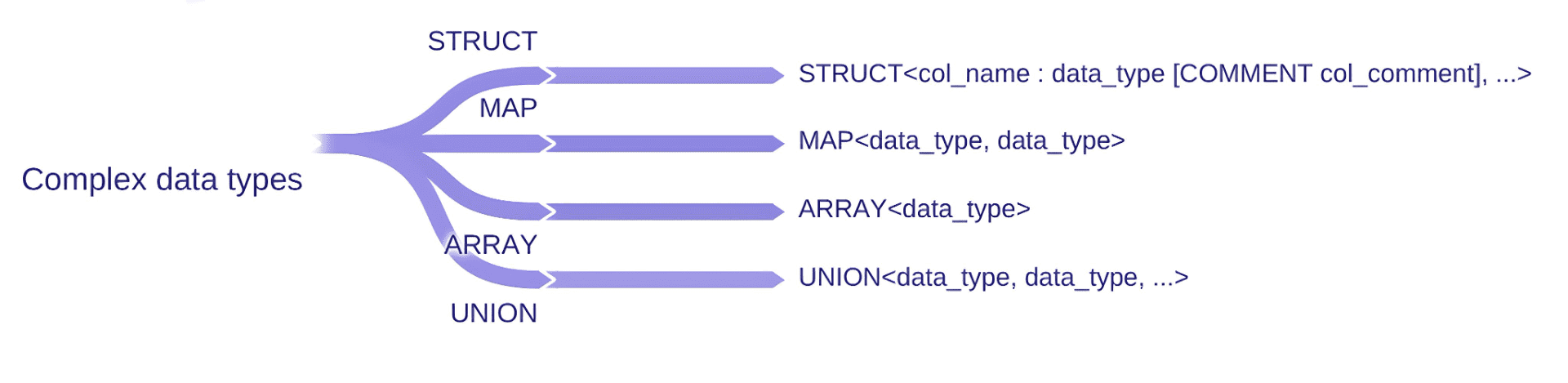
2、Hive Complex Data Type(Hive 复杂数据类型)
复杂数据类型包括数组(ARRAY)、映射(MAP)、结构体(STRUCT)和联合(UNION),如下表所示:
| 类型 (Type) | 描述 (Description) | 语法 (Syntax) | 示例 (Example) |
|---|---|---|---|
| ARRAY(数组) | 一个有序的字段集合,字段类型必须相同 | ARRAY | Array(1,2) |
| MAP(映射) | 一个无序的键值对集合。键必须是原子类型,值可以是任意类型。同一个映射中的键和值必须为相同类型 | MAP | Map(‘a’,1,‘b’,2) |
| STRUCT(结构体) | 一个具名字段的集合,各字段类型可以不同 | STRUCT | Struct(‘a’,1,1.0) |
| UNION(联合) | 一种复杂数据类型,可以一次保存其可能数据类型中的一个 | UNIONTYPE | Uniontype(1,‘a’) |
四、Introduction to HiveServer2 (HS2)
HiveServer2(HS2)是一个服务,它使客户端能够在 Hive 上执行查询。HiveServer2 是 HiveServer1 的继任者,而 HiveServer1 已被弃用。HS2 支持多客户端并发和认证,旨在为 JDBC 和 ODBC 等开放 API 客户端提供更好的支持。
HS2 是一个作为复合服务运行的单一进程,其中包括基于 Thrift 的 Hive 服务(支持 TCP 或 HTTP)以及用于 Web UI 的 Jetty Web 服务器。
HiveServer1,也称为 Thrift 服务器,基于 Apache Thrift 协议构建,用于处理与 Hive 的跨平台通信。它允许不同的客户端应用向 Hive 提交请求并获取最终结果。但由于它不能处理来自多个客户端的并发请求,因此被 HiveServer2 所取代。
1、HS2 Architecture(HS2 架构)
基于 Thrift 的 Hive 服务是 HS2 的核心,负责处理 Hive 查询。Thrift 是一个用于构建跨平台服务的 RPC 框架。它的架构包含四个层次:Server(服务器)、Transport(传输)、Protocol(协议)和 Processor(处理器)。
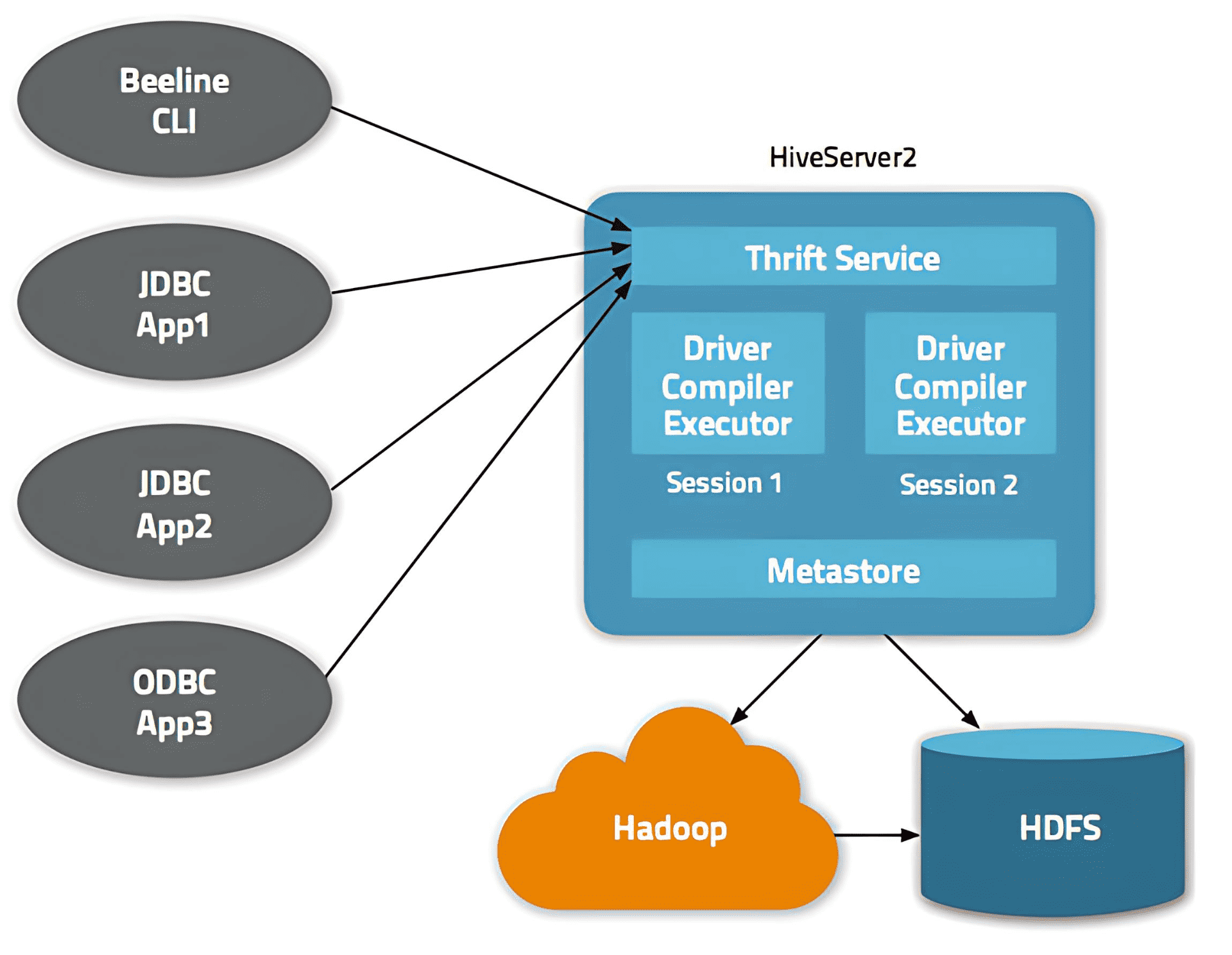
HS2 的依赖项
- Metastore(元存储)
Metastore 可以配置为嵌入式(与 HS2 在同一进程中)或远程服务器(也是基于 Thrift 的服务)。HS2 与 metastore 通信,以获取查询编译所需的元数据。 - Hadoop 集群
HS2 为各种执行引擎(MapReduce/Tez/Spark)准备物理执行计划,并将作业提交到 Hadoop 集群执行。
JDBC 客户端
建议客户端使用 JDBC 驱动与 HS2 交互。需要注意的是,在某些场景下(例如 Hadoop Hue),会直接使用 Thrift 客户端,绕过 JDBC。
以下是执行首次查询所涉及的 API 调用顺序:
- JDBC 客户端(例如 Beeline)通过初始化传输连接(如 TCP 连接)创建 HiveConnection,然后调用 OpenSession API 获取 SessionHandle。Session 由服务器端创建。
- 按照 JDBC 标准执行 HiveStatement,并通过 Thrift 客户端发出 ExecuteStatement API 调用。在 API 调用中,将 SessionHandle 信息与查询信息一起传递给服务器。
- HS2 服务器接收请求后,调用驱动程序(CommandProcessor)进行查询解析和编译。驱动程序启动一个后台作业与 Hadoop 通信,然后立即向客户端返回响应。这是 ExecuteStatement API 的异步设计。响应中包含由服务器端创建的 OperationHandle。
- 客户端使用 OperationHandle 与 HS2 通信,轮询查询执行状态。