
一、Table Management(表管理)
下面将介绍 Hive 中常用的表管理语句,例如创建数据库、创建表以及创建分区等。
1、Databases in Hive(Hive 中的数据库)
在 Hive 中,数据库表示一组表,这些表用于相似的目的或属于同一分组。如果没有指定数据库,则使用默认数据库。
每当新建数据库时,Hive 会在 /user/hive/warehouse 目录下为每个数据库创建一个目录,该目录由 hive.metastore.warehouse.dir 定义。
例如,数据库 hivedb 位于 /user/hive/datawarehouse/hivedb.db。
但是,默认数据库没有自己独立的目录。
以下是 Hive 数据库的核心 DDL 操作:
-
不检查数据库是否存在,直接创建数据库
CREATE DATABASE hivedb; -
检查数据库是否存在后再创建数据库
CREATE DATABASE IF NOT EXISTS hivedb; -
描述数据库
DESCRIBE DATABASE hivedb; -
创建带注释的数据库
CREATE DATABASE IF NOT EXISTS hivedb COMMENT "Example Hive Database"; -
创建带有 dbproperties 的数据库
CREATE DATABASE IF NOT EXISTS hivedb2 WITH DBPROPERTIES('creator'='Ezekielx','date'='2025-09-24'); -
显示 Hive 中的所有数据库
SHOW DATABASES; -
描述数据库并查看 dbproperties
DESCRIBE DATABASE EXTENDED hivedb; -
删除一个没有任何表的数据库
DROP DATABASE hivedb;默认模式是 RESTRICT,如果数据库中还有表,则阻止删除。
-
删除数据库及其所有表(级联删除)
DROP DATABASE IF EXISTS hivedb CASCADE; -
使用某个数据库
USE hivedb; -
使用通配符显示和描述数据库
SHOW DATABASES LIKE 'hive.*';
2、Creating Tables in Hive(在 Hive 中创建表)
CREATE TABLE 是 Hive 中用于创建表的语句。语法与示例如下:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)]
INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[FIELDS TERMINATED BY file_format]
[STORED AS file_format]
[LOCATION hdfs_path];
-
CREATE TABLE
创建一个指定名称的表。如果已存在同名表,会抛出异常;若使用
IF NOT EXISTS选项,则忽略该异常。 -
EXTERNAL
关键字用于创建外部表,并在创建时通过
LOCATION指定实际数据路径。- 内部表:Hive 会将数据移动到数仓指定的路径。删除表时,元数据和数据会一起删除。
- 外部表:只记录数据所在路径,不会改变数据位置。删除表时,仅删除元数据,数据仍保留。
-
ROW FORMAT DELIMITED
用于设置表加载数据时的列分隔符。
-
STORED AS file_format
指定文件存储格式。默认是
TEXTFILE。如果文件是纯文本,则使用
STORED AS TEXTFILE,数据会直接从本地复制到 HDFS。 -
PARTITIONED BY
用于创建分区表。一个表可以有一个或多个分区,每个分区存放在单独的目录中。
-
CLUSTERED BY / SORTED BY
表或分区可以通过某个字段进行 分桶 (Bucket),并可对数据排序。这在某些应用中能提升性能。
创建表(Create Table):
-
创建普通表
CREATE TABLE Manager( name STRING, id INT, address STRING, age INT ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' STORED AS TEXTFILE;指定了字段分隔符。Hive 仅支持单字符分隔符,默认分隔符是
\001。 -
创建分区表
CREATE TABLE IF NOT EXISTS part_table( deptno INT, empname STRING, sal INT ) PARTITIONED BY (deptname STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' STORED AS TEXTFILE; -
创建分桶表
CREATE TABLE test_bucket(
id INT,
name STRING,
no INT
)
PARTITIONED BY (dt STRING)
CLUSTERED BY (id) INTO 3 BUCKETS
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;
- **创建外部表**
```sql
CREATE EXTERNAL TABLE manager(
name STRING,
id INT,
address STRING,
age INT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS TEXTFILE
LOCATION '/user/niit/manager';
- **复制表结构**
```sql
CREATE TABLE test_like_table LIKE test_bucket;
上述命令只复制表结构,不复制表内容。
修改表 (Alter Table):
-
重命名表 (Rename Table)
语法:
ALTER TABLE table_name RENAME TO new_table_name;示例:
ALTER TABLE test_partition RENAME TO new_test_partition;说明:表的数据位置和分区名不会改变。
-
修改列类型 (Change Column Type)
语法:
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name];示例:
ALTER TABLE test_col_change CHANGE a a1 INT; -
添加列 (Add Column)
语法:
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...);示例:
ALTER TABLE test_col_change ADD COLUMNS (d INT); -
修改列名 (Rename Column)
ALTER TABLE emp CHANGE COLUMN name new_name STRING; -
替换列 (Replace Columns)
示例:
ALTER TABLE emp REPLACE COLUMNS ( id INT, name STRING );
说明:删除原有所有列,再创建新列。
3、Managed Tables and External Tables(托管表和外部表)
托管表 (Managed Table)
托管表也称为 内部表。Hive 控制表和表中数据的生命周期。数据存储在 hive-site.xml 配置文件中参数 hive.metastore.warehouse.dir 指定的目录下。当 Hive 创建内部表时,会将数据移动到数仓目录所指向的路径。
当删除托管表时,表中的数据也会被同时删除。
使用 CREATE TABLE ... 命令可以创建托管表:
CREATE TABLE manager(
name STRING,
id INT,
address STRING,
age INT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;
关于 Hive 内部表(托管表):
- 内部表由 Hive 控制。
- 元数据(存储在 metastore 中)和实际数据(存储在 HDFS 中)都由 Hive 管理。
- 内部表的数据只能通过 Hive 访问,不论数据在 HDFS 还是 Hive 的数仓目录,Hive 不允许其他应用访问这些数据。
- 如果需要访问内部表数据,只能通过 Hive 查询。
- 当删除内部表时,元数据和实际数据都会丢失,因为二者都由 Hive 控制。
- 默认情况下,如果创建表时没有使用
EXTERNAL关键字,该表就是内部表。
外部表 (External Table)
外部表的数据不由 Hive 管理,Hive 仅建立对数据的引用。当外部表被删除时,只有表的元数据会被删除,数据不会被删除。因此,外部表相对更安全,数据组织更灵活,便于共享源数据。
使用 CREATE EXTERNAL TABLE ... 命令可以创建外部表:
CREATE EXTERNAL TABLE manager(
name STRING,
id INT,
address STRING,
age INT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;
关于 Hive 外部表:
- 外部表中,只有存储在 metastore 中的元数据由 Hive 管理。
- 存储在 HDFS 中的实际数据不受 Hive 控制。
- 当删除外部表时,仅会丢失元数据,实际数据仍然存在。
- 外部表中的数据可以被其他应用程序(如 HBase 等)访问。
- 如果创建表时使用了
EXTERNAL关键字,该表就是外部表。
4、Loading Data into Hive(将数据加载到 Hive 中)
当数据被加载到 Hive 表或分区后,原始位置的数据将不再存在。下面是一些将本地或 HDFS 文件中的数据移动到 Hive 表或分区的示例。
LOCAL关键字:指定文件位于本地主机。如果不指定LOCAL,则默认会从以下位置加载文件:INPATH后指定的完整 URI(统一资源标识符);- 或 Hive 配置属性
fs.default.name所设定的路径。
INPATH后面的路径可以是相对路径或绝对路径。该路径可以指向一个文件,也可以指向一个文件夹(会加载文件夹下所有文件),但 不能包含子文件夹。- 如果数据要加载到 分区表,必须同时指定分区列。
OVERWRITE关键字:用于决定是 追加数据 还是 覆盖表/分区中已有的数据。
示例:将文件加载到 Hive 表:
-
从本地加载数据到 Hive 表
-
追加数据到表:
LOAD DATA LOCAL INPATH '/opt/datafiles/employee.csv' INTO TABLE emp; -
覆盖数据到表(旧数据会被删除):
LOAD DATA LOCAL INPATH '/opt/datafiles/employee.csv' OVERWRITE INTO TABLE emp;
-
-
从 HDFS 加载数据到 Hive 表(使用系统默认路径)
LOAD DATA INPATH '/user/files/employee.txt' OVERWRITE INTO TABLE emp;
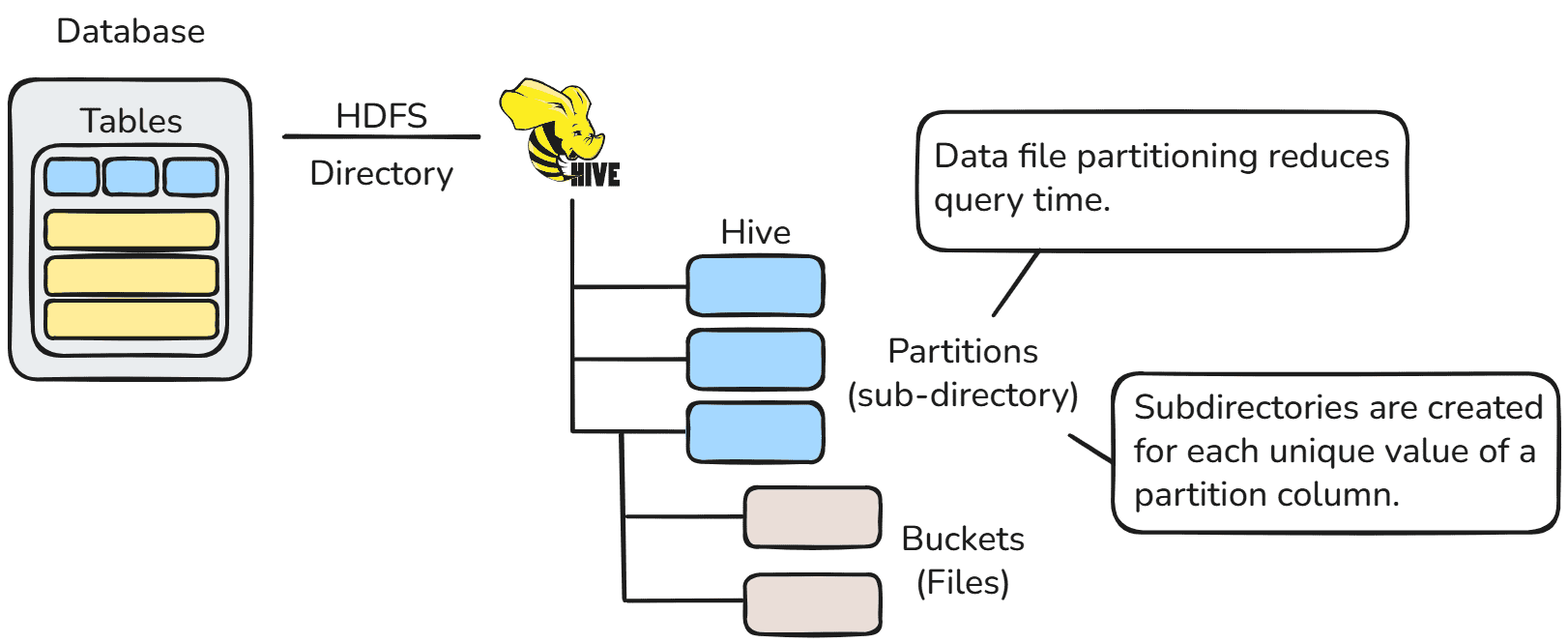
二、Hive Partitions(Hive 分区)
Apache Hive 分区机制
Apache Hive 将表组织为分区。分区是一种基于某些列(例如日期、城市和部门)的值,把表划分为相关部分的方式。
在 Hive 中,每个表都可以有一个或多个分区键,用来标识特定的分区。通过分区,可以很方便地对数据的某些切片进行查询。
为什么分区很重要?
在当今时代,大量的数据(以 PB 级计)被存储在 HDFS 中。由于数据量庞大,Hadoop 用户在查询时会遇到很大的困难。Hive 的引入,正是为了减轻这种数据查询的负担。Hive 会将 SQL 查询 转换为 MapReduce 作业,然后提交到 Hadoop 集群中。但是,如果直接对一张大表运行 SQL 查询,Hive 需要读取整个数据集,这样会导致效率极低。
为了解决这一问题,可以通过对表进行 分区 来优化。Hive 在建表时就能很方便地通过自动分区方案来实现这一点。
分区的工作原理
在分区机制下,表的数据会被划分为多个分区。每个分区对应于分区列的某个具体值,并作为子目录存放在 HDFS 中的表目录下。
当查询某个表时,Hive 只会扫描包含查询条件的相关分区,而不是整个表。这样就显著减少了 I/O 操作时间,从而提升了查询性能。
1、Partition Table(分区表)
假设有一张表 Tab1,表中包含客户信息:id、name、dept、yoj(入职年份)。
如果我们要查询 2012 年入职的客户,在未分区的情况下,需要扫描整张表。
但如果根据年份对数据进行分区并存储到不同文件中,就能减少查询时间。
原始数据(未分区):
clientdata/file1
id, name, dept, yoj
1, sunny, SC, 2009
2, animesh, HR, 2009
3, sumeer, SC, 2010
4, sarthak, TP, 2010
分区后数据:
clientdata/2009/file2
1, sunny, SC, 2009
2, animesh, HR, 2009
clientdata/2010/file3
3, sumeer, SC, 2010
4, sarthak, TP, 2010
这样,在查询时,只会访问指定年份对应的分区文件,而不是扫描整个表。
2、Types of Hive Partitioning(Hive 分区的类型)
Apache Hive 中有两种分区方式:
- 静态分区(Static Partitioning)
- 动态分区(Dynamic Partitioning)
Hive 静态分区(Static Partitioning):
-
将输入数据文件单独插入到分区表中称为静态分区。
-
通常在将大文件加载到 Hive 表时,推荐使用静态分区。
-
静态分区相比动态分区可以节省加载数据的时间。
-
在静态分区中,用户需要手动添加分区,并将文件移动到该分区对应的目录中。
-
在静态分区中可以对分区进行 ALTER 操作。
-
分区列的值可以直接从文件名、日期等中获得,而无需读取整个大文件。
-
如果要在 Hive 中使用静态分区,需要设置以下属性:
set hive.mapred.mode = strict;该属性在
hive-site.xml中默认启用。 -
静态分区属于 严格模式(Strict Mode)。
-
使用静态分区时,必须在
WHERE子句中使用LIMIT。 -
静态分区可用于 Hive 的 内部表(Managed Table) 和 外部表(External Table)。
创建静态分区表示例:
CREATE TABLE table_tab1 (
id INT,
name STRING,
dept STRING,
yoj INT
)
PARTITIONED BY (year STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;
加载静态分区数据:
LOAD DATA LOCAL INPATH '/clientdata/2010/file3'
OVERWRITE INTO TABLE table_tab1
PARTITION (year='2010');
Hive 动态分区(Dynamic Partitioning):
- 一次性插入到分区表称为动态分区。
- 通常,动态分区会从非分区表中加载数据。
- 动态分区相比静态分区,加载数据时间更长。
- 当表中存储的数据量非常大时,动态分区更合适。
- 如果需要对多个字段进行分区,但事先不知道有多少个字段时,动态分区也很适用。
- 动态分区中,
WHERE子句不是必须的。 - 动态分区不能执行 ALTER 操作。
- 动态分区可以用于 Hive 的 内部表 和 外部表。
- 在 Hive 中使用动态分区时,模式需要是 非严格模式(Non-Strict Mode)。
Hive 动态分区属性(需要开启):
Hive 默认关闭动态分区,需要先启用:
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
创建动态分区表示例:
CREATE TABLE table_tab1 (
id INT,
name STRING,
dept STRING,
yoj INT
)
PARTITIONED BY (year STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;
加载动态分区数据:
INSERT INTO TABLE table_tab1 PARTITION (year)
SELECT id, name, dept, year FROM Tab1;
分区操作:
增加分区(Increase partition):
语法:
ALTER TABLE table_name
ADD partition_spec [LOCATION 'location1']
partition_spec [LOCATION 'location2'];
partition_spec 的格式为:
PARTITION (partition_col = partition_col_value, partition_col = partition_col_value, ...)
示例:
ALTER TABLE test_partition
ADD PARTITION (dt='2015-06-15')
LOCATION '/opt/data/hive/test_hive.txt';
删除分区(Delete partition):
语法:
ALTER TABLE table_name DROP partition_spec;
示例:
ALTER TABLE test_partition
DROP PARTITION (dt='2015-06-15');
说明:删除分区后,该分区的 元数据和数据都会一并删除。
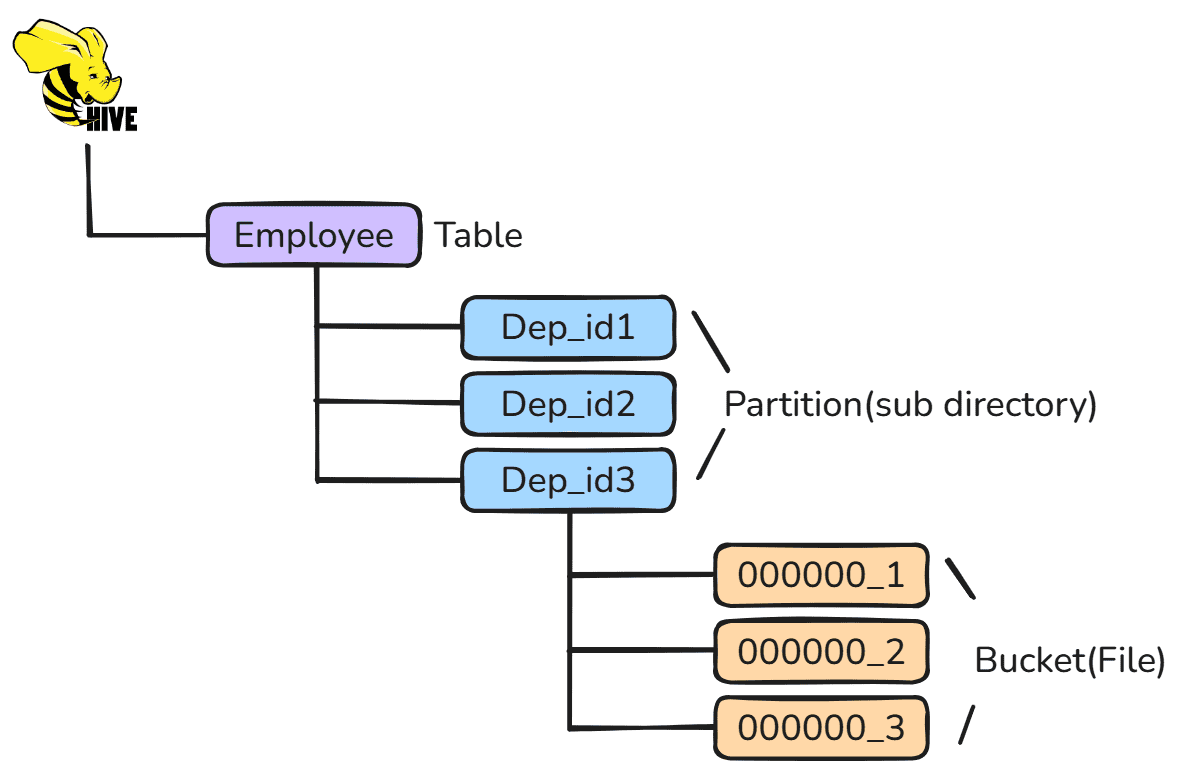
3、Bucketing in Hive(Hive 中的分桶)
Hive 中的 分桶 是一种将数据划分为若干范围(称为桶 buckets)的概念。通过给数据增加额外的结构,可以让查询执行得更加高效。
桶的范围是由数据集(或 Hive 元数据库表)中一个或多个列的 哈希值 来决定的。
这些列称为 分桶列(bucketing columns / clustered by columns)。
基本上,Hive 分区(Partitioning) 提供了一种将表数据拆分为多个文件或目录的方法。但它只在某些场景下效果显著,例如:
- 分区数量有限时。
- 各个分区大小比较均衡时。
然而,这并不适用于所有情况。比如,当我们按地理位置(如国家)对表进行分区时:
- 大国的数据会形成非常大的分区(可能只有 4-5 个国家就贡献了 70–80% 的数据)。
- 而小国的数据会形成非常小的分区(世界上其他所有国家加起来可能只占 20–30% 的数据)。
在这种情况下,分区并不是理想方案。
为了解决 过度分区(over-partitioning) 的问题,Hive 提供了 分桶(Bucketing) 的概念。
分桶是另一种有效的技术,用于将表数据集拆分为更易管理的部分,从而提升查询性能。
在进行分桶操作前,需要设置以下属性:
set hive.enforce.bucketing=true;
set hive.exec.dynamic.partition.mode=nonstrict;
创建动态分区表示例:
分桶语法:
CREATE TABLE table_tab1 (
id INT,
name STRING,
dept STRING,
yoj INT
)
PARTITIONED BY (year STRING)
CLUSTERED BY (location) INTO 4 BUCKETS
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;
-
CLUSTERED BY 子句:用于指定按哪些列进行分桶,以及桶的数量。
-
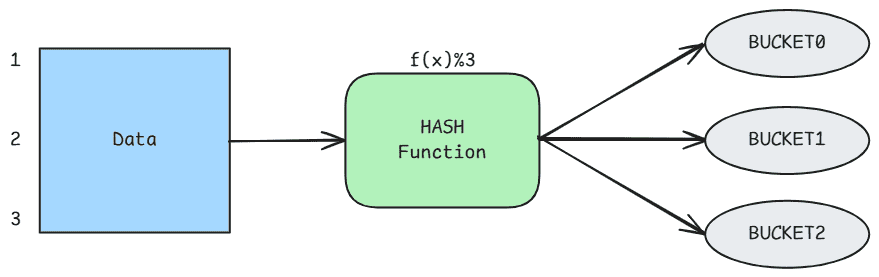
Hive 分桶机制:Hive 会根据分桶列计算哈希值,并用桶数取余:
id.hash() % 4根据结果将数据分配到对应的桶中。
-
开启强制分桶:为了让 Hive 按照定义的桶数量来写数据,需要设置属性:
set hive.enforce.bucketing = true;这样 Hive 才会根据表定义创建相应数量的桶。
向分桶表加载数据:
INSERT INTO TABLE table_tab1 PARTITION (year)
SELECT id, name, dept, location
FROM Tab1;
分区 (Partitioning) 与 分桶 (Bucketing) 的区别:
分桶和分区有相似之处——两者都是对数据进行分隔和存储——但它们之间存在一些关键差异:
- 分区 (Partitioning):分区是 Hive 提供的一种将大表拆分成小表的技术。它根据某个列的取值把数据拆分存储到不同的目录下,每个分区就是一个独立的目录。
- 分桶 (Bucketing):分桶是 Hive 的另一种数据组织方式。它根据哈希函数将数据分配到固定数量的桶中,每个桶就是一个文件。
使用场景对比:
- 分区适用场景:更适合小规模数据。如果数据量大,可能会导致生成过多的小分区和过多的目录,带来管理负担。
- 分桶适用场景:能够保证每个桶中的数据量大致相等,因此在执行 Map 端的 Join 时效率更高。
三、Pattern design(模式设计)
本章描述了 Hive 的一些设计模式是如何在实际应用中被使用的,以及哪些设计方法应该避免。
1、Table by Date(按日期分表)
按日期建表,也就是每天一个表,表名一般为 tablename_yyyy-mm-dd,例如 log_2025_10_22。这种设计模式在实际应用中非常常见,特别适合数据量快速增长的应用场景。
创建表:
create table log_2025_10_20(id int, part string);
create table log_2025_10_21(id int, part string);
create table log_2025_10_22(id int, part string);
查询方式:
select id, part from log_2025_10_20
union all
select id, part from log_2025_10_21
union all
select id, part from log_2025_10_22;
这种方式的缺点是需要每天手动创建表,查询也不方便。在 Hive 中,可以使用日期分区来创建分区表,查询效率更高,结构也更清晰。
创建表:
create table log (id int, part string) partitioned by (int day);
查询方式:
select id, part from log where day >= '20251020' and day <= '20251022';
2、Table Partitioning(表分区)
在 Hive 中执行查询时,通常会进行全表扫描以满足查询需求。当数据量非常大时,扫描速度会非常慢。其中有些数据其实并不是我们需要的,但仍会被扫描和过滤。
因此,Hive 引入了分区(partition)的概念,根据一定的规则存储数据,从而减少数据扫描范围和磁盘 I/O 操作,提高查询效率。
如果按日期分区后数据量仍然很大,可以使用二级分区(secondary partitioning),例如先按日期分区,再按地区分区,以进一步缩小查询范围。
创建表:
create table logs (
id int,
part string
)
partitioned by (day int, area string);
查询:
select id, part from logs where day = '20251022';
或
select id, part from logs where day = '20251022' and area = 'haikou';
总结:
分区后的数据应当考虑数据量的均衡性。即:各个分区中的数据量应尽量保持一致,不能某个分区过大或过小。因为在 MapReduce 执行过程中,每个文件对应一个 Map 任务,过多的小文件会导致 Map 任务数量过多,从而造成资源浪费。
3、Load multiple processes at once(同时加载多个进程)
Hive 在加载一个数据源后,可以一次执行多个操作,而不需要每次都重新加载数据。
例如:
insert overwrite table logUserInfo
select * from log where area = 'haikou';
insert overwrite table pvInfo
select * from log where day = '20251022';
这种语法虽然是正确的,但 Hive 会对 log 表执行两次数据扫描,效率不高。
更高效的写法是:
from log
insert overwrite table logUserInfo select * where area = 'haikou'
insert overwrite table pvInfo select * where day = '20251022';
这样,Hive 只需扫描一次 log 表,即可完成多个插入操作,从而提升整体执行效率。
4、Reasonable use of Intermediate Tables(合理使用中间表)
许多 ETL 处理流程都包含多个处理步骤。通常,每个步骤都会生成一个或多个临时表(temporary tables),这些表仅供下一个任务使用。
由于临时表中的数据量通常也非常大,因此在创建临时表时,需要增加分区(partition),以减少磁盘的读取范围,从而提高查询和处理效率。
5、Bucket Tables Store Data(桶表存储数据)
分区(Partitioning)为数据隔离和查询优化提供了一种方便的方法,但并不是所有数据集都适合进行分区。
如果数据集不适合分区,那么如何提高查询速度呢?
Hive 引入了 分桶(Bucketing) 的概念,这是一种将数据集划分为更易管理部分的技术。
例如,当表的主分区是日期字段 dt,二级分区是 user_id 时,这种方式会产生大量小分区。
create table log (
url string,
source_ip string
)
partitioned by (dt string, user_id int);
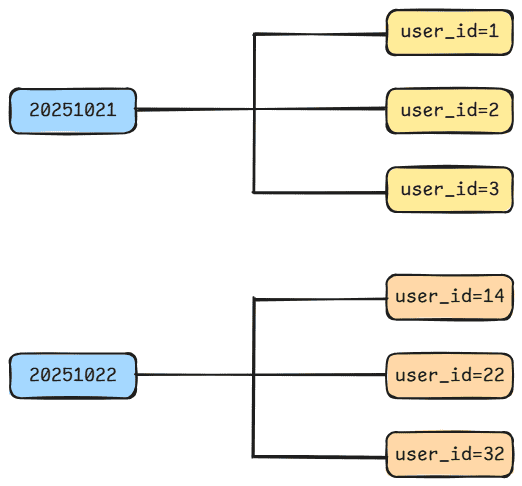
这种模式会导致生成许多小分区。
为了解决这个问题,可以将 user_id 字段作为 分桶字段(bucket field),Hive 会根据用户指定的桶数量对字段值进行哈希计算,然后将数据分配到不同的桶中。
create table log (
url string,
source_ip string
)
partitioned by (dt string)
clustered by (user_id) into 3 buckets;
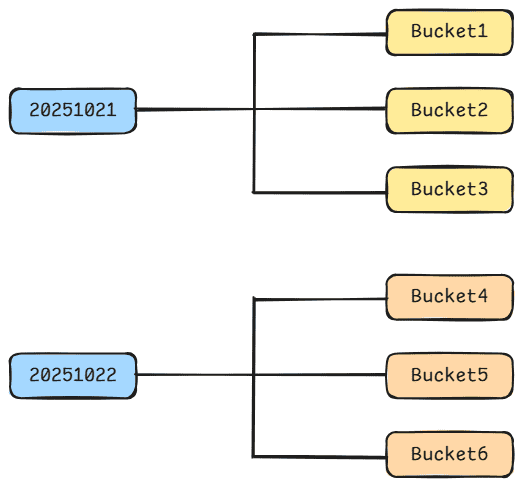
Hive 会对分桶字段进行哈希计算,根据结果确定数据进入哪个桶。
使用示例如下:
set hive.enforce.bucketing = true;
from logs
insert overwrite table weblog
partition (dt = '20251022')
select user_id, url
where dt = '2025-10-22';
分桶的优点:
- 桶的数量固定,不会随着数据量变化而波动。
- 写入桶的 Reduce 数量固定,有助于提升处理效率。
四、Different types of files in Hive(Hive 中的不同文件类型)
Hive 文件存储格式包括以下几类:
-
TEXTFILE
这是 Hive 的默认文件格式。数据不压缩,占用磁盘空间大,解析开销高。
文本文件可以是 CSV(逗号分隔)或 TSV(制表符分隔)格式,这两种格式在 Hadoop 和非 Hadoop 环境中都很常见。
-
SEQUENCEFILE
一种由 Hadoop API 提供的二进制文件格式,使用方便、可分割、可压缩。
SequenceFile 以键值对(key-value)形式存储记录,记录以二进制方式保存,占用空间较小。
-
自定义格式(Custom Format)
当 Hive 无法识别用户的数据文件格式时,可以自定义文件格式。
用户可以通过实现
InputFormat和OutputFormat接口,来自定义输入和输出方式。 -
AVRO 文件(AVRO Files)
AVRO 不仅是一种文件格式,同时也是一种序列化和反序列化框架。
它定义了文件结构及数据的读写方式。
-
列式存储格式(Columnar File Formats)
这种格式越来越流行,因为它能以列的方式存储数据,而不是像传统方式那样按行存储。
在列式存储中,数据集在水平和垂直方向上都进行了分区。
Hive 常用的三种列式文件格式是:RCFile、ORCFile 和 Parquet。
-
RCFile(Record Columnar File)
Hadoop 中最早采用的列式文件格式,由二进制键值对组成的扁平文件,与 SequenceFile 类似。
-
ORCFile(Optimized Record Columnar File)
RCFile 的改进版本。读取速度更快,压缩效率更高,但写入性能略有下降。
-
Parquet File
Hadoop 生态中最常用的列式存储格式。支持嵌套数据结构的扁平化存储,读取性能高,写入性能相对较弱。
-
**文件格式的选择取决于使用场景和运行环境。**没有一种文件格式能满足所有需求,每种格式都有自己的优缺点:
- 数据简单、调试方便时用 TEXTFILE。
- MapReduce 中间结果可用 SEQUENCEFILE。
- 需要高查询性能和压缩比时用 ORC 或 Parquet。
五、Exporting Hive Data(导出 Hive 数据)
要将 Hive 表导出为 CSV 文件,可以使用 INSERT OVERWRITE DIRECTORY,或者将查询结果通过管道重定向到 CSV 文件中。
下面介绍如何在 HDFS、本地目录、Hive CLI 和 Beeline 中使用 HiveQL 脚本将 Hive 表导出为 CSV 文件,并在导出的数据中包含列名。
步骤 1:创建输出目录
mkdir /opt/files/output
步骤 2:进入 Hive CLI,执行以下代码:
set hive.cli.print.header = true;
INSERT OVERWRITE LOCAL DIRECTORY '/opt/files/output'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
SELECT * FROM table_name;
语句说明:
insert overwrite:表示如果目标文件已存在,第二次运行时会覆盖旧文件。- 需要指定在第一步中创建的本地目录,输出文件将生成在该目录下。
fields terminated by ',':定义字段分隔符,这里使用逗号(,)分隔列。select *:表示导出表中的所有数据,这里以infostore表为例;如果只想导出部分数据,可以在查询中添加过滤条件(如where子句)。
步骤 3:查看输出结果
检查生成的文件是否存在于目录 /opt/files/output 该文件即为导出的 CSV 文件,包含表头和数据内容。