
一、Basic Scala Concept(Scala 基本概念)
Scala 结合了面向对象和函数式编程,是一种简洁的高级语言。
Scala 的静态类型系统有助于在复杂应用中避免错误,它既能运行在 JVM 上,也能运行在 JavaScript 平台上,从而可以轻松构建高性能系统,并访问庞大的类库生态。
它有六个主要特性:
- 无缝的 Java 集成(Seamless Java interop)—— Java 与 Scala 可以混合使用。
- 类型推断 —— 编译器可以自动推断类型。
- 并发与分布式编程(Concurrency & Distribution)—— Scala 提供了多种并发模型(如
Future、Promise、Actor),能方便地处理多线程任务。。 - 特质(Traits)与特性 —— 类似于 Java 中的接口(interface)和抽象类(abstract)。
- 模式匹配(Pattern Matching)—— 类似 Java 的
switch,但更强大,可以根据值、类型或结构选择不同逻辑。 - 高阶函数(Higher-order Functions)—— 可以把函数作为参数或返回值,实现灵活的函数式编程。
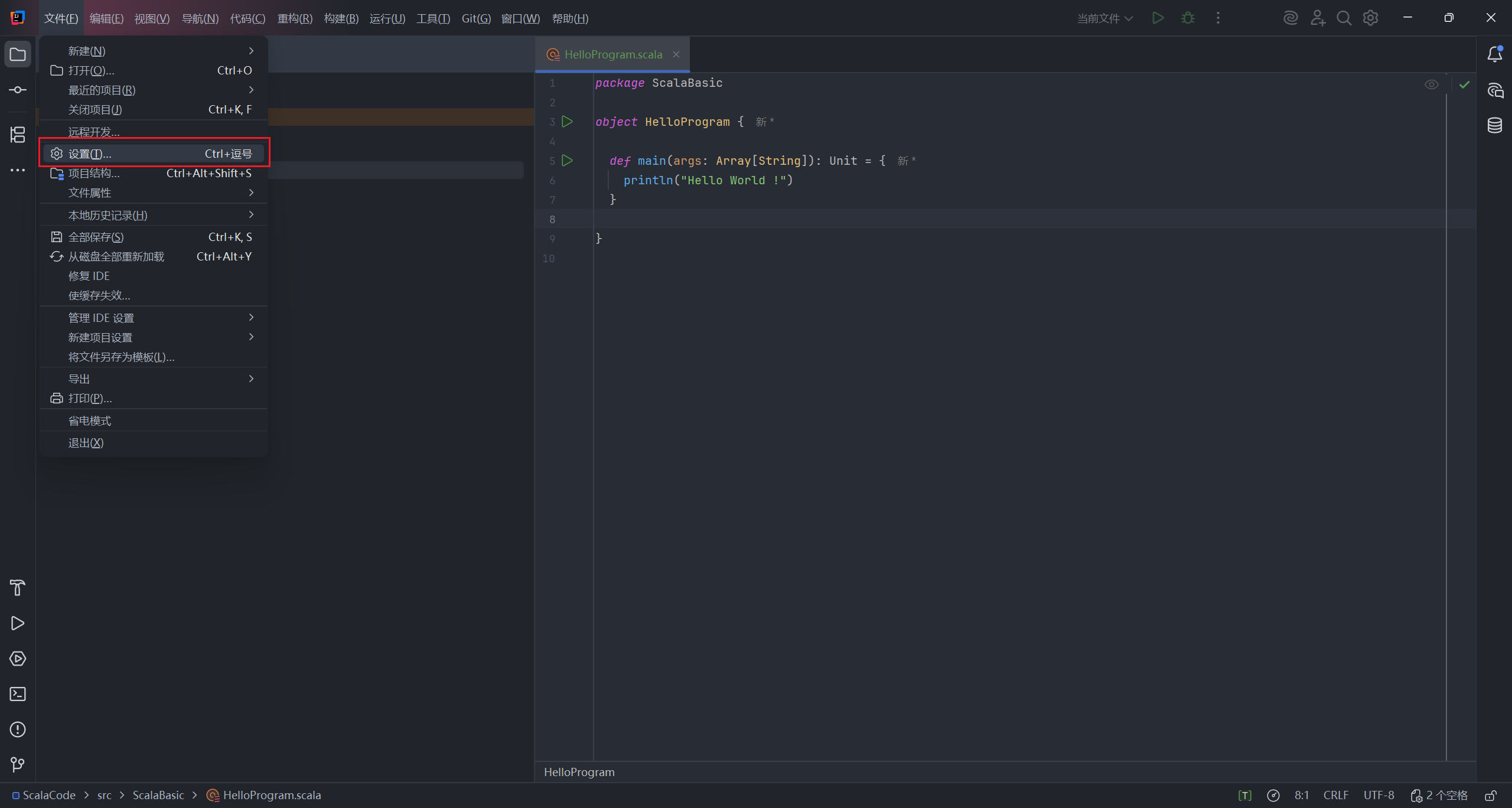
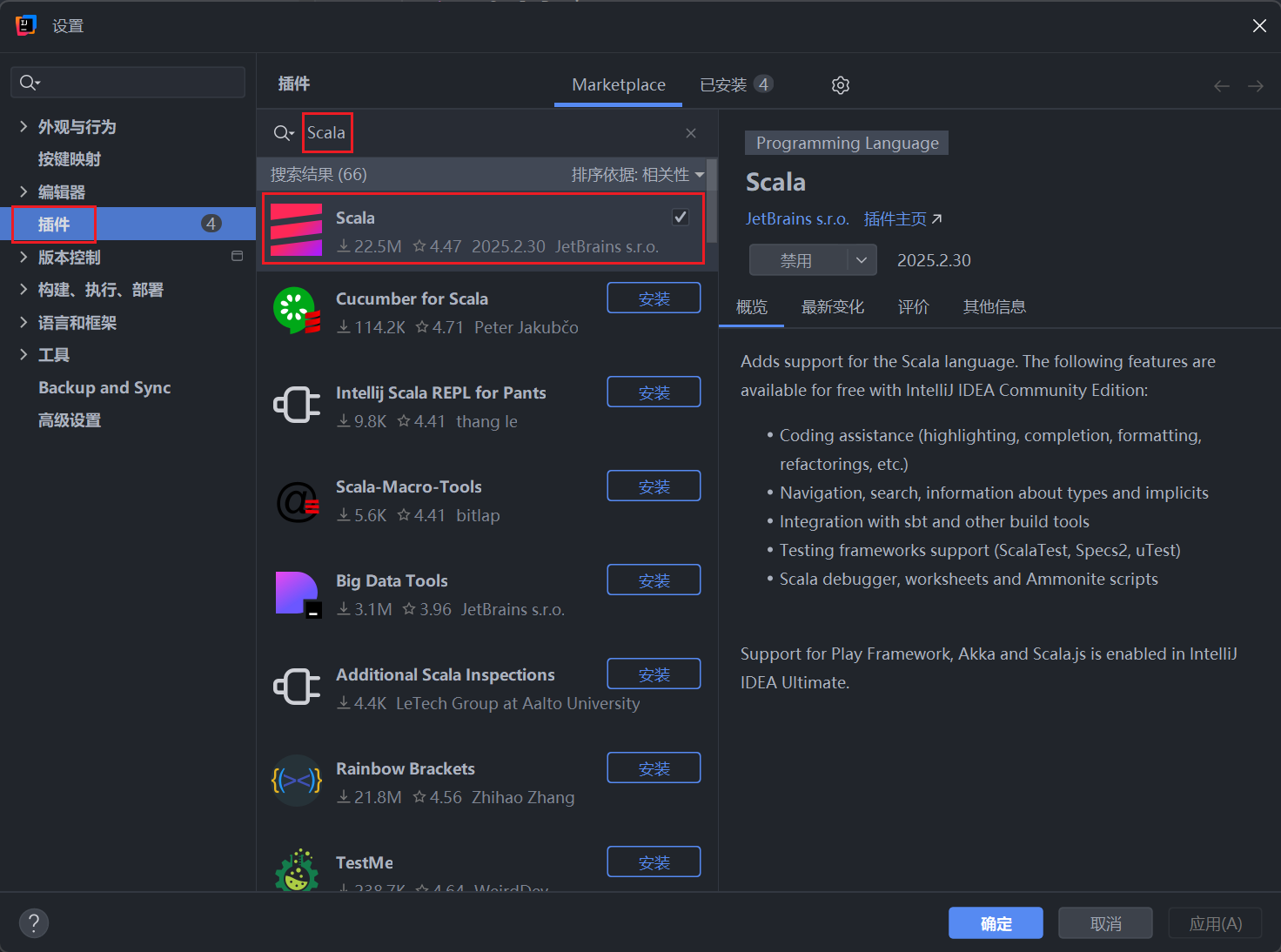
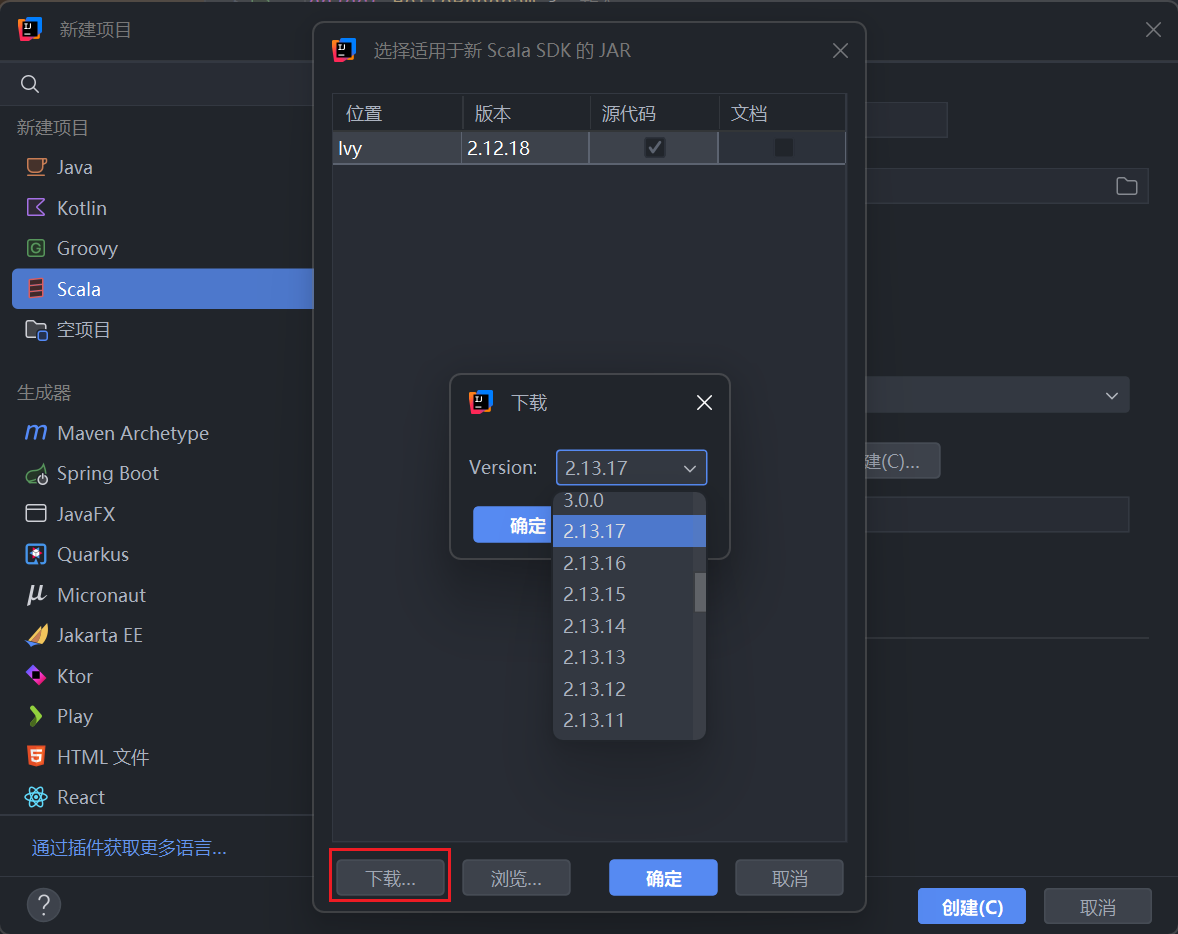
1、Installing Scala in IntelliJ IDEA(在 IntelliJ IDEA 中安装 Scala)
在设置中选择插件,搜索 Scala 插件,下载。
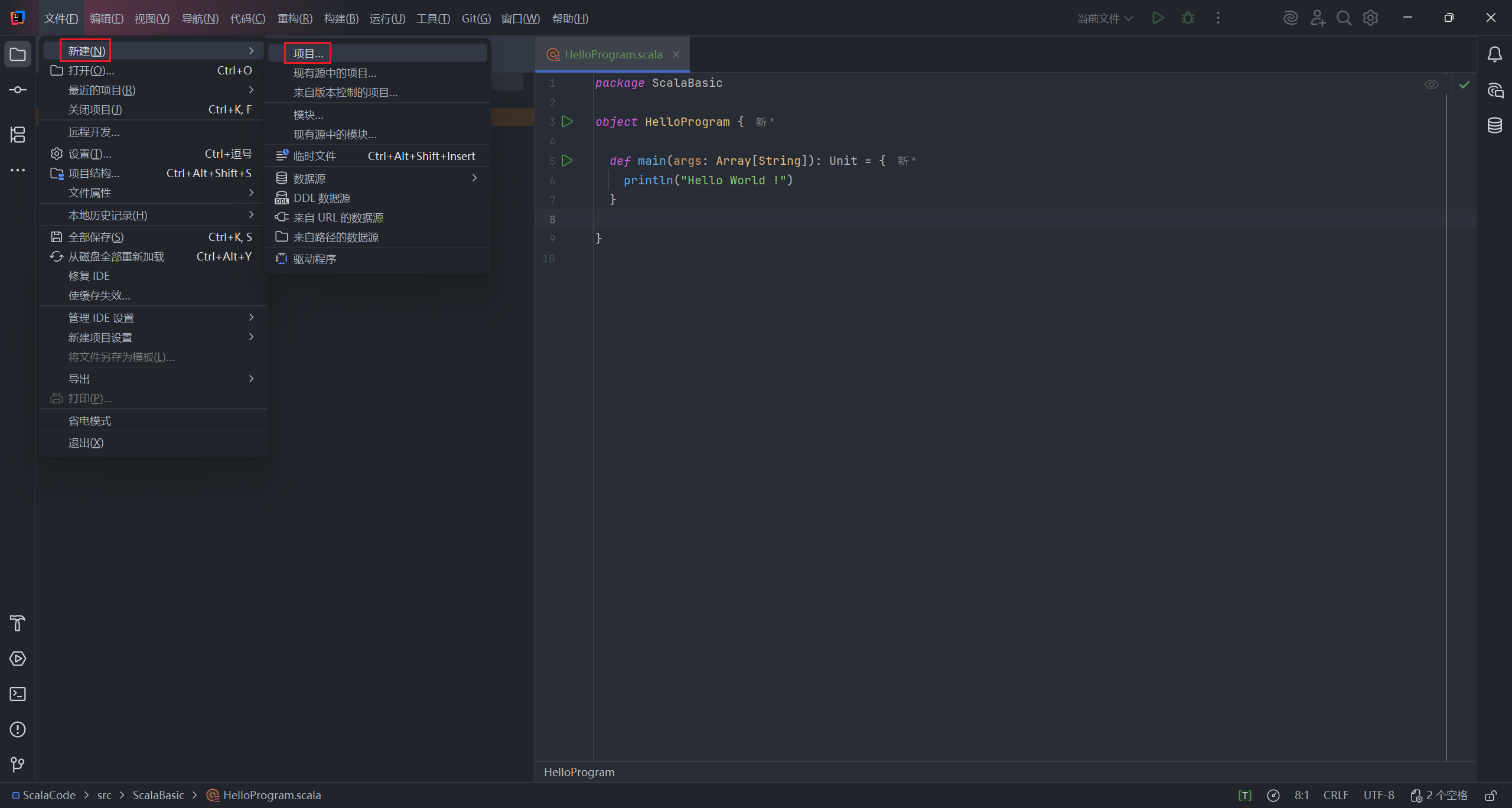
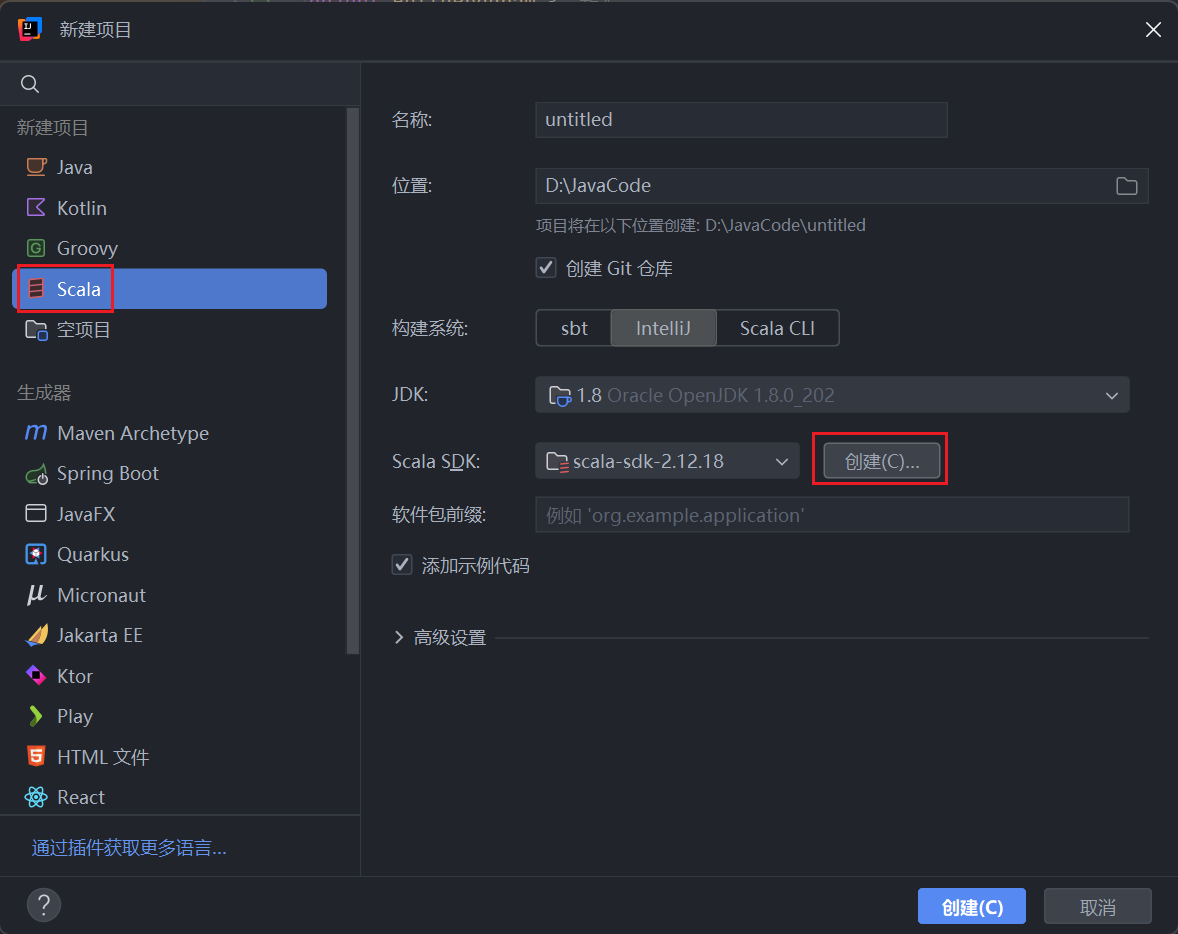
选择创建一个 Scala 项目,选择对应版本的 Scala SDK 下载。
二、Scala Objects(Scala 对象)
数据类型:
| 数据类型 (Data type) | 描述 (Description) |
|---|---|
| Byte | 8 位有符号整数,范围:-128 到 127 |
| Short | 16 位有符号整数,范围:-32768 到 32767 |
| Int | 32 位有符号整数,范围:-2147483648 到 2147483647 |
| Long | 64 位有符号整数,范围:-9223372036854775808 到 9223372036854775807 |
| Float | 32 位 IEEE 754 单精度浮点数 |
| Double | 64 位 IEEE 754 双精度浮点数 |
| Char | 16 位无符号 Unicode 字符,范围:U+0000 到 U+FFFF |
| String | 字符序列(由多个 Char 组成) |
| Boolean | 布尔值:true 或 false |
| Unit | 表示“无值”,类似 Java 的 void |
| Null | 表示空引用或空值 |
| Nothing | 所有其他类型的子类型,没有任何实例值 |
| Any | 所有类型的超类型,所有对象都属于 Any |
| AnyRef | 所有引用类型的超类型(相当于 Java 中的 Object) |
变量与常量的声明:
/**
* 定义变量和常量
* 变量:使用 var 定义,可变
* 常量:使用 val 定义,不可变
*/
var name = "zhangsan"
println(name)
name = "lisi"
println(name)
val gender = "m"
// gender = "f" // 错误:常量不能被重新赋值
1、Create the Class(创建类)
类可以被定义为一个模板,用来描述与该类相关的行为和状态。
下面的代码示例:
class Person {
val name = "zhangsan"
val age = 18
def sayName() = {
"my name is " + name
}
}
2、Create Objects(创建对象)
对象具有状态和行为,是类的一个实例。
object Lesson_class {
def main(args: Array[String]): Unit = {
val person = new Person()
println(person.age)
println(person.sayName())
}
}
3、Apply methods in the object(调用对象中的方法)
当创建一个对象时,如果传入了参数,会自动找到对象中与参数个数对应的 apply 方法。
/**
* Object(单例对象)本身不能直接传递构造参数,
* 如果在创建对象时传入了参数,
* Scala 会根据参数的数量自动找到对象中合适的 apply 方法。
*/
object Lesson_ObjectWithParam {
def apply(s: String) = {
println("name is " + s)
}
def apply(s: String, age: Int) = {
println("name is " + s + ", age = " + age)
}
def main(args: Array[String]): Unit = {
Lesson_ObjectWithParam("Ezekielx")
Lesson_ObjectWithParam("Ezekielx", 18)
}
}
4、Associated classes and associated objects(伴生类和伴生对象)
类与对象 (Class & Object):
class Person(xname: String, xage: Int) {
var name = Person.name
val age = xage
var gender = "m"
// 辅助构造函数
def this(name: String, age: Int, g: String) {
this(name, age) // 必须先调用主构造函数
gender = g
}
def sayName() = {
"my name is " + name
}
}
object Person {
val name = "zhangsanfeng"
def main(args: Array[String]): Unit = {
val person = new Person("wagnwu", 10, "f")
println(person.age)
println(person.sayName())
println(person.gender)
}
}
注意事项:
- 类名建议首字母大写,方法名建议小写,并且类名、方法名推荐使用驼峰命名法。
- 在 Scala 中,每行结尾都有 自动分号推断,无需手写
;。 - 对象 (object) 在 Scala 中是 单例对象,相当于 Java 的工具类,可以看作是一种定义。
- 静态类方法 由
object实现;object不能传递参数。trait也不能传递参数。 - 类 (class) 在 Scala 中默认可以传参,这就是默认构造器。
- 如果覆盖(重写)构造函数,必须调用默认构造器。
- 类的属性会自动带有 getter / setter。
- 使用
object时不需要new;使用class时必须new。 - 在
class里,除了方法体之外的所有代码都会立即执行。 - 如果在同一文件中
class和object名字相同,则这个object就是该类的 伴生对象,两者可以互相访问私有成员。
if else 语句:
/**
* if else
*/
val age = 18
if (age < 18) {
println("allowed")
} else if (18 <= age && age <= 20) {
println("allow with other")
} else {
println("allowed")
}
for、while、do…while 语句:
to和until的用法:
/**
* to 和 until
* 案例:
* 1 to 10 返回从 1 到 10 的范围数组,包含 10
* 1 until 10 返回从 1 到 10 的范围数组,不包含 10
*/
println(1 to 10) // 打印 1 到 10
println(1.to(10)) // 同上
println(1 to (10, 2)) // 步长为 2,打印 1,3,5,7,9
println(1 until 10) // 不包含最后一个,打印 1 到 9
println(1.until(10)) // 同上
println(1 until (10, 3)) // 步长为 3,打印 1,4,7
- 创建 for 循环:
/**
* for 循环
*/
for (i <- 1 to 10) {
println(i)
}
- 创建多层 for 循环:
// 多个变量赋值用分号分隔,形成多层 for 循环
// 注意:Scala 中不能写 count++,只能写 count += 1
var count = 0
for (i <- 1 to 10; j <- 1 until 10) {
println("i = " + i + " j = " + j)
count += 1
}
println(count)
// 示例:打印九九乘法表
for (i <- 1 until 10; j <- 1 until 10) {
if (i >= j) {
print(i + " * " + j + " = " + i * j + " ")
}
if (i == j) {
println()
}
}
- 带条件的 for 循环:
// for 循环中可以添加条件判断
for (i <- 1 to 10; if (i % 2) == 0; if (i == 4)) {
println(i)
}
- Scala 不使用
count++:
在 Scala 中,递增要写成:count = count + 1 或 count += 1。
- for 循环结合
yield返回集合:
// 使用 yield 将符合条件的元素收集到集合中
val list = for (i <- 1 to 10; if (i > 5)) yield i
for (w <- list) {
println(w)
}
- while 与 do…while 循环:
/**
* while 循环
*/
var index = 0
while (index < 100) {
println("loop count: " + index)
index += 1
}
// do…while 循环
var idx = 0
do {
idx += 1
println("loop " + idx + " run successfully")
} while (idx < 100)
三、Scala Functional Programming(Scala 函数式编程)
函数式编程是一种编程范式,它将计算机操作视为函数运算,并避免使用程序状态和可变对象。
其中,λ 演算 (lambda calculus) 是该语言最重要的理论基础。
在 λ 演算中,函数既可以接收函数作为输入(参数),也可以将函数作为输出(返回值)。
与命令式编程相比,函数式编程更强调 程序执行的结果 而非 执行的过程。
它提倡使用若干个简单的执行单元,通过逐步推导与组合,得到复杂的计算结果,而不是事先设计一个复杂的执行流程。
1、Concept of Functional Programming(函数式编程的概念)
在学习 Scala 中的方法、函数和函数式编程时,需要解释以下几个概念:
-
方法 (Method) 和函数 (Function) 在 Scala 中几乎是相同的
它们的定义、使用和运行方式基本一致。
只是函数的使用更加灵活。 -
函数式编程 (Functional Programming) 是一种编程风格(编程范式)
可以理解为:函数式编程把函数当作普通值一样使用,充分利用函数,并支持多种使用方式。
在 Scala 中,函数可以像变量一样使用:-
作为参数传递给其他函数;
-
作为返回值从函数中返回。
函数还可以直接赋值给变量来创建,而不依赖类或对象(不像 Java,函数必须依赖类、抽象类或接口)。
-
-
面向对象编程 (OOP) 是一种以对象为核心的编程方式。
-
在 Scala 中,函数式编程和面向对象编程是融合在一起的。
可以这样理解函数式编程:
- 函数式编程是一种编程范式。
- 它属于“结构化编程”的一种,核心思想是:尽可能把操作过程写成一系列嵌套的函数调用。
- 在函数式编程中,函数也被视为数据类型,所以函数既可以作为输入参数传递,也可以作为返回值输出。
- 在函数式编程中,函数是最核心的组成部分。
什么是函数?为什么需要函数?
举个例子:需求是输入两个数字和一个运算符(+ 或 -),输出计算结果。
没有函数时的 Scala 代码:
val n1 = 10
val n2 = 20
var oper = "-"
if (oper == "+") {
println("res=" + (n1 + n2))
} else if (oper == "-") {
println("res=" + (n1 - n2))
}
println("------ does other work.....")
val n3 = 10
val n4 = 20
oper = "+"
if (oper == "+") {
println("res=" + (n3 + n4))
} else if (oper == "-") {
println("res=" + (n3 - n4))
}
问题:传统写法中,逻辑重复,代码冗余,不易维护。
使用函数改写:
def calculate(a: Int, b: Int, oper: String): Unit = {
if (oper == "+") {
println("res=" + (a + b))
} else if (oper == "-") {
println("res=" + (a - b))
}
}
calculate(10, 20, "-")
println("------ does other work.....")
calculate(10, 20, "+")
是否发现,用传统方式解决这个问题时存在一些问题?
代码出现了冗余,而且不容易维护,所以我们将重复的逻辑抽取出来,形成一个函数。
函数就是:为了完成某个功能而编写的一组语句的集合。
函数的定义可以参考下图所示。
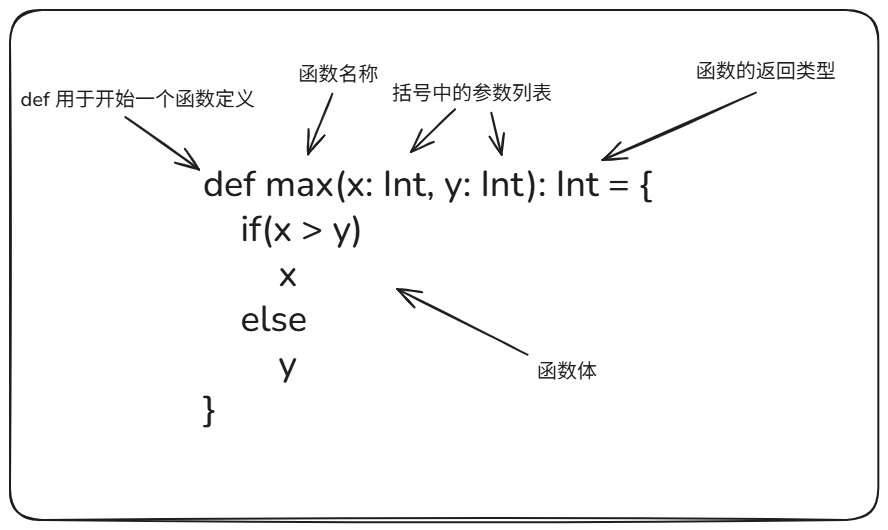
- 方法定义语法使用
def关键字; - 可以定义传入的参数,并指定参数的类型;
- 方法的返回值类型可以写也可以不写。Scala 会自动推断,但在某些情况下(比如递归方法,或返回值是函数类型时)必须显式写出返回值类型;
- 在 Scala 中,如果方法有返回值,可以使用
return,也可以不写。当不写return时,方法中最后一行的表达式就是返回结果。如果写了return,则必须写明方法的返回值类型; - 如果方法体只有一行逻辑,可以省略
{}; - 方法参数在方法体中可以使用,并且 Scala 规定传入的方法参数是
val,而不是var; - 如果在方法定义前去掉等号
=, 那么该方法的返回类型一定是Unit,无论方法体的逻辑如何。Scala 会自动将任何返回类型转换为Unit。例如,即使方法体返回一个字符串,最终返回值也会被丢弃并转换为Unit。
递归方法(Recursive Method):
一个函数在函数体内调用自己,这种调用就称为递归调用。
def test(n: Int) {
if (n > 2) {
test(n - 1)
}
println("n=" + n)
}
def test2(n: Int) {
if (n > 2) {
test2(n - 1)
} else {
println("n=" + n)
}
}
test(5)
test2(5)
递归函数需要遵循的重要原则:
- 程序在执行一个函数时,会创建一个新的受保护的独立空间(新的函数栈);
- 函数的局部变量是独立的,互不影响;
- 递归必须逐步接近递归出口条件,否则会陷入无限递归;
- 当函数执行完毕或遇到
return时,就会返回,结果也会返回给调用它的地方。
匿名函数(Anonymous Functions):
/**
* 匿名函数
* 1. 带参数的匿名函数
* 2. 无参数的匿名函数
* 3. 带返回值的匿名函数
*
* 注意:
* 匿名函数可以赋值给一个变量
*/
// 带参数的匿名函数
val value1 = (a: Int) => {
println(a)
}
value1(1)
// 无参数的匿名函数
val value2 = () => {
println("I love Fashion School")
}
value2()
// 带返回值的匿名函数
val value3 = (a: Int, b: Int) => {
a + b
}
println(value3(4, 4))
嵌套方法(Nested Method):
/**
* 嵌套方法
* 示例:嵌套方法计算 5 的阶乘
*/
def fun5(num: Int) = {
def fun6(a: Int, b: Int): Int = {
if (a == 1) {
b
} else {
fun6(a - 1, a * b)
}
}
fun6(num, 1)
}
println(fun5(5))
2、Higher-Order Function(高阶函数)
函数的参数是函数,或者函数的返回值是函数,或者函数的参数和返回值都是函数。
函数的参数是函数。
// 函数的参数是函数
def hightFun(f: (Int,Int) => Int, a: Int): Int = {
f(a, 100)
}
def f(v1: Int, v2: Int): Int = {
v1 + v2
}
println(hightFun(f, 1))
函数的返回值是函数。
// 函数的返回值是函数
def hightFun2(a: Int, b: Int): (Int,Int)=>Int = {
def f2(v1: Int, v2: Int): Int = {
v1 + v2 + a + b
}
f2
}
println(hightFun2(1, 2)(3, 4))
函数的参数是函数,返回值也是函数。
// 函数的参数是函数,返回值也是函数
def hightFun3(f: (Int,Int) => Int): (Int,Int) => Int = { f }
println(hightFun3(f)(100, 200))
println(hightFun3((a, b) => { a + b })(200, 200))
// 上一句也可以写成这样:
// 如果函数参数在方法体中只用了一次,可以写成 _
println(hightFun3(_ + _)(200, 200))
柯里化函数(Coriolis Function):
柯里化是高阶函数的一种简化形式。
// 柯里化函数
def fun7(a: Int, b: Int)(c: Int, d: Int) = {
a + b + c + d
}
println(fun7(1, 2)(3, 4))
函数的注意事项和细节:
-
函数的形式参数列表可以有多个;如果函数没有形式参数,可以在调用时不写
()。 -
参数列表和返回值列表的数据类型既可以是值类型,也可以是引用类型。
-
Scala 函数可以根据函数体最后一行代码推断返回值类型,因此在这种情况下
return关键字可以省略。 -
因为 Scala 有类型推断,所以在省略
return关键字时,返回值类型也可以省略。 -
如果函数显式使用了
return关键字,则函数的返回值类型不能被推断。 -
如果函数显式声明无返回值(
Unit),即使函数体中写了return也不会有返回值。 -
如果函数显式无返回值,或者不确定返回值类型,返回值类型可以省略(或者声明为
Any)。 -
Scala 语法很灵活,任何结构都可以嵌套在其他语法中。也就是说:函数可以在函数中定义,类可以在类中定义,方法可以在方法中定义。
-
Scala 函数参数在声明时可以直接赋默认值,调用时如果没有传参,就会使用默认值。
-
如果函数有多个参数,每个参数都可以设置默认值,此时传入的参数可能会导致歧义(是覆盖默认值,还是赋值给没有默认的参数)。
-
Scala 函数参数默认是
val,不能在函数体内修改。 -
递归函数的返回值类型在执行前无法推断,因此必须显式写明返回值类型。
-
Scala 函数支持可变参数:
// 支持 0 个到多个参数 def sum(args: Int*): Int = {} // 支持至少 1 个参数 def sum(n1: Int, args: Int*): Int = {}args是一个集合,可以通过for循环访问每个值;- 可变参数必须写在参数列表的最后。
四、Scala Collections(Scala 集合)
基本介绍:
-
Scala 支持 不可变集合 和 可变集合,它们都可以被安全地并发访问;
-
Scala 默认使用 不可变集合。对于几乎所有的集合类,Scala 都提供了 可变(mutable)版本 和 不可变(immutable)版本;
-
两个主要的包:
- 不可变集合:
scala.collections.immutable - 可变集合:
scala.collections.mutable
- 不可变集合:
-
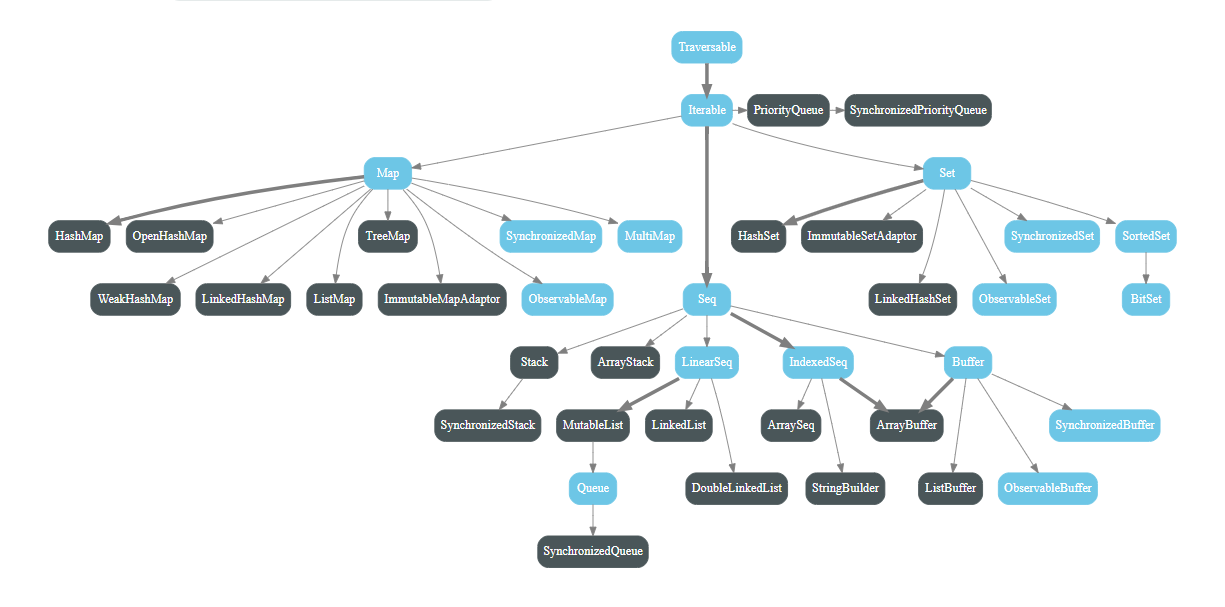
Scala 集合分为三大类:序列(Seq)、集(Set)、映射(Map),这三大类都继承自 Iterable 特质。
下图显示了scala.collection.immutable中所有的集合类。
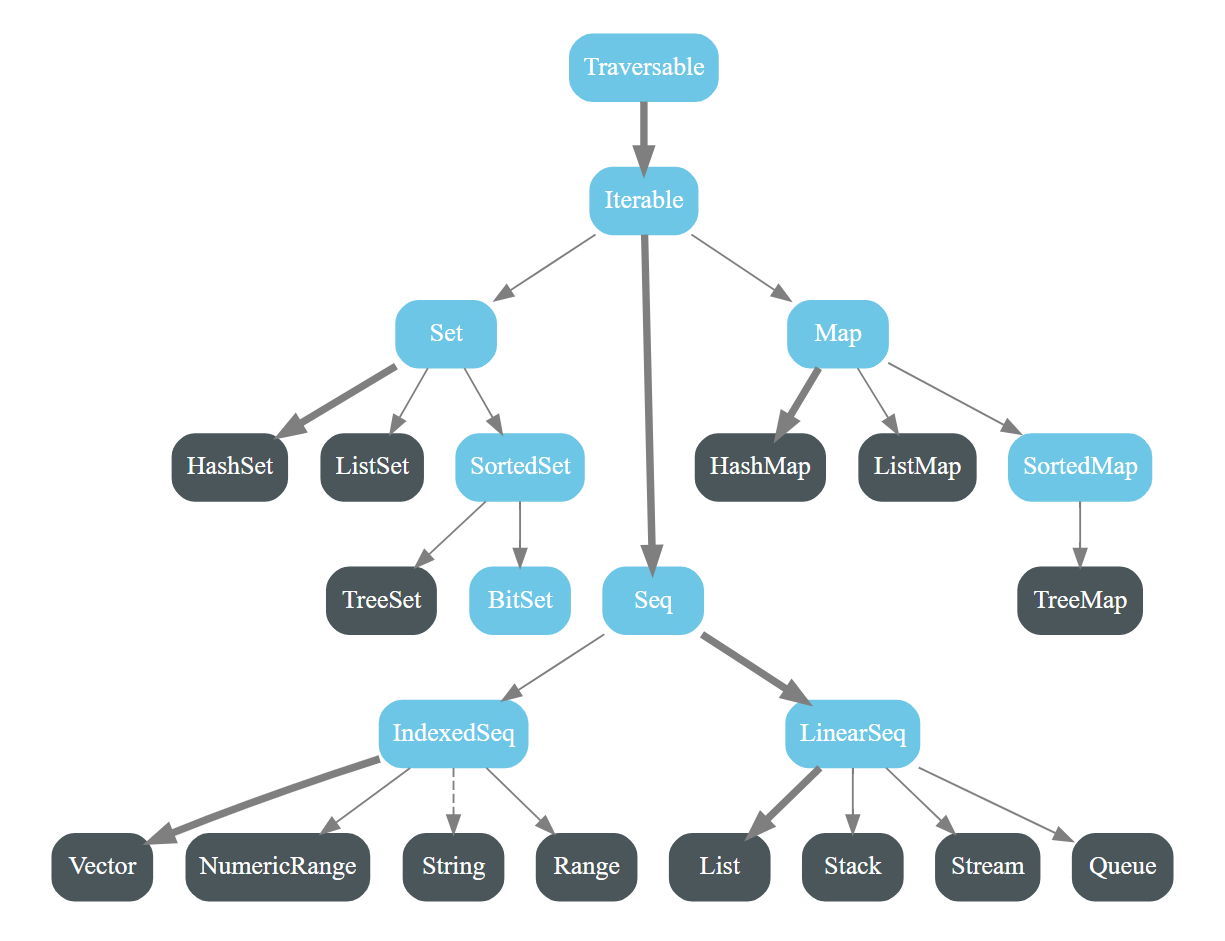
下图显示了scala.collection.mutable中所有的集合类。
1、Array(数组)
创建数组:
// 创建一个长度为 3 的整型数组
val Arr1 = new Array
// 创建一个字符串数组并直接赋值
val Arr2 = Array[String]("s1", "s2", "s3")
// 赋值操作
Arr1(0) = 100
Arr1(1) = 200
Arr1(2) = 300
数组遍历:
// 使用 for 遍历
for (i <- Arr1) {
println(i)
}
// 使用 foreach 遍历
Arr1.foreach(i => println(i))
for (s <- Arr2) {
println(s)
}
Arr2.foreach(x => println(x))
一维与二维数组:
// 创建二维数组
val Arr3 = new Array
Arr3(0) = Array("1", "2", "3")
Arr3(1) = Array("4", "5", "6")
Arr3(2) = Array("7", "8", "9")
// 普通 for 循环遍历
for (i <- 0 until Arr3.length) {
for (j <- 0 until Arr3(i).length) {
print(Arr3(i)(j) + " ")
}
println()
}
也可以写成嵌套遍历:
var count = 0
for (arr <- Arr3; i <- arr) {
if (count % 3 == 0) println()
print(i + " ")
count += 1
}
// foreach 写法
Arr3.foreach(arr => arr.foreach(println))
再看一个二维整型数组的例子:
val arr4 = Array[Array[Int]](
Array(1, 2, 3),
Array(4, 5, 6)
)
arr4.foreach(arr => arr.foreach(i => println(i)))
println("-------")
for (arr <- arr4; i <- arr) {
println(i)
}
数组常用方法:
// 合并数组
Array.concat(Arr1, Arr1)
// 创建一个固定长度并初始化的数组
val arr5 = Array.fill(5)("Ezekielx")
可变数组 ArrayBuffer:
import scala.collection.mutable.ArrayBuffer
val arr = ArrayBuffer[String]("a", "b", "c")
arr.append("Hello", "Scala") // 添加多个元素
arr += "end" // 末尾添加
arr.+=:("start") // 开头添加
arr.foreach(println)
2、Collection Tuples(集合与元组)
1. List(列表)
创建列表:
val list = List(1, 2, 3, 4)
Nil 表示空列表。
遍历列表:
for (i <- list) println(i)
list.foreach(println)
常用方法:
val list = List(1, 2, 3, 4, 5)
// filter:过滤
val list1 = list.filter(x => x > 3)
list1.foreach(println)
// count:计数
val value = list1.count(x => x > 3)
println(value)
// map:对每个元素操作
val nameList = List(
"Hello Scala",
"Hello Ezekielx",
"Hello Tom"
)
val mapResult: List[Array[String]] = nameList.map(x => x.split(" "))
mapResult.foreach(arr => println(arr.mkString(",")))
// flatMap:扁平化
val flatMapResult: List[String] = nameList.flatMap(x => x.split(" "))
flatMapResult.foreach(println)
2. Set(集合)
创建集合:
val numbers = Set(1, 2, 3, 4, 4)
val set2 = Set(1, 2, 5)
Set 会自动去重。
遍历:
numbers.foreach(println)
for (n <- numbers) println(n)
常用方法:
// 交集
val intersection = numbers.intersect(set2)
intersection.foreach(println)
// 差集
numbers.diff(set2).foreach(println)
// 是否子集
println(numbers.subsetOf(set2))
// 最大最小
println(numbers.max)
println(numbers.min)
// 转换
numbers.toArray.foreach(println)
numbers.toList.foreach(println)
// mkString:转为字符串
println(numbers.mkString(", "))
可变集合:
import scala.collection.mutable.Set
val set = Set[Int](1, 2, 3, 4, 5)
set.add(100)
set += 200
set ++= Seq(300, 400)
set.foreach(println)
3. Map(映射)
创建 Map:
val map = Map("1" -> "Ezekielx", 2 -> "Scala", 3 -> "Tom")
取值:
println(map.get("1").get)
val result = map.get(8).getOrElse("no value")
println(result)
遍历 Map:
for ((k, v) <- map) {
println(s"key: $k, value: $v")
}
遍历键和值:
// 键
for (key <- map.keys) {
println(s"key: $key, value: ${map.get(key).get}")
}
// 值
for (value <- map.values) {
println(s"value: $value")
}
合并 Map:
val map1 = Map((1, "A"), (2, "B"), (3, "C"))
val map2 = Map((1, "AA"), (2, "BB"), (4, "DD"))
val merged = map1 ++ map2
merged.foreach(println)
常用方法:
// count:统计满足条件的键值对数量
val countResult = map.count(_._2 == "Scala")
println(countResult)
// filter:过滤出符合条件的元素
map.filter(_._2 == "Scala").foreach(println)
// contains:判断是否包含键
println(map.contains(2))
// exists:是否存在符合条件的元素
println(map.exists(_._2 == "Tom"))
可变 Map:
import scala.collection.mutable.Map
val mutableMap = Map[String, Int]()
mutableMap.put("hello", 100)
mutableMap.put("world", 200)
mutableMap.foreach(println)
4. Tuple(元组)
定义:
元组与列表类似,但可以包含不同类型的元素。
创建与访问:
val tuple1 = new Tuple1(1)
val tuple2 = ("Ezekielx", 25)
val tuple3 = (1, "Scala", true)
val tuple4 = (1, 2, 3, 4)
// 访问元素
println(tuple2._1 + "\t" + tuple2._2)
// 嵌套元组
val t = ((1, 2), ("Tom", "Jerry"))
println(t._1, t._2)
遍历:
val tupleIterator = tuple4.productIterator
while (tupleIterator.hasNext) {
println(tupleIterator.next())
}
常用方法:
// swap:交换(仅限二元组)
println(tuple2.swap)
// toString:转字符串
println(tuple3.toString())
五、Advanced Features of Scala(Scala 高级特性)
以下是一些在开发中经常使用的 Scala 高级特性。
1、Trait Characteristics(Trait 的特性)
Trait 是 Scala 中代码复用的基本单元。
它封装了方法和字段的定义,并且可以通过“混入(mixin)”的方式复用到类中。
Scala 的 Trait 类似于 Java 的接口(interface),但功能更强大。
Trait 不仅可以定义抽象方法,也可以包含具体的实现。
Trait 的定义方式与类相似,只是使用关键字 trait:
trait Philosophical {
def philosophize() {
println("I consume memory, therefore I am!")
}
}
定义好 Trait 之后,可以使用 extends 或 with 关键字将其混入类中。
在 Scala 中,这种用法被称为“混入”,而不是“继承”,因为它与其他语言中的多重继承机制不同。
如果多个 Trait 中定义了相同名称的方法或属性,必须在类中使用 override 重新定义。
此外,Trait 中不能定义带参数的构造器。
示例:
class Animal
class Frog extends Animal with Philosophical {
override def toString = "green"
}
也可以混入多个 Trait:
trait HasLegs
class Frog extends Animal with Philosophical with HasLegs {
override def toString = "green"
}
Trait 的定义在语法上与类基本相同,但有两个重要区别:
第一,Trait 不能带构造参数。
例如:
class Point(x: Int, y: Int)
是合法的,而:
trait NoPoint(x: Int, y: Int) // 无法编译
是非法的。
第二,super 的调用方式不同。
在类中,super 调用是静态绑定的,也就是说明确知道要调用哪个父类的方法。
而在 Trait 中,super 调用是动态绑定的,具体调用哪个实现要等到 Trait 被混入具体类时才确定。
这种机制使得 Trait 可以“堆叠”使用,即多个 Trait 混入时可以依次修改行为,这种特性称为“可堆叠修改(stackable modifications)”。
下面的代码展示了在 Trait 中定义带方法实现的属性:
trait Read {
val readType = "Read"
val gender = "m"
def read(name: String): Unit = {
println(name + " is reading")
}
}
trait Listen {
val listenType = "Listen"
val gender = "m"
def listen(name: String): Unit = {
println(name + " is listening")
}
}
class Person extends Read with Listen {
override val gender = "f"
}
object Test {
def main(args: Array[String]): Unit = {
val person = new Person()
person.read("Ezekielx")
person.listen("Scala")
println(person.listenType)
println(person.readType)
println(person.gender)
}
}
还可以在 Trait 中定义未实现的方法,由子类去实现。
trait Equal {
def isEqual(x: Any): Boolean
def isNotEqual(x: Any): Boolean = {
!isEqual(x)
}
}
类中实现该 Trait:
class Point(x: Int, y: Int) extends Equal {
val xx = x
val yy = y
def isEqual(p: Any): Boolean = {
p.isInstanceOf[Point] && p.asInstanceOf[Point].xx == xx
}
}
object TraitExample {
def main(args: Array[String]): Unit = {
val p1 = new Point(1, 2)
val p2 = new Point(1, 3)
println(p1.isEqual(p2))
println(p1.isNotEqual(p2))
}
}
2、Implicit Conversion(隐式转换)
你的代码与别人编写的库函数之间有一个根本区别:
你可以随意修改或扩展自己的代码,但无法直接修改他人提供的类或函数。
为了解决这个问题,不同语言提出了不同方案:
- Ruby 引入了模块(module),
- Smalltalk 允许不同的包向类中动态添加方法,
- C# 3.0 提供了静态扩展方法(static extension methods)。
这些方法虽然强大,但也很危险,因为它们直接改变了类的行为,可能导致难以预料的问题。
Scala 的解决方案是:
隐式转换(implicit conversion) 和 隐式参数(implicit parameters)。
它们的作用是让代码更简洁、更具表达性。
当使用得当时,Scala 编译器会自动帮你完成类型推断和参数传递,让代码更关注业务逻辑而不是细节。
1. 隐式值与隐式参数(Implicit Values and Parameters)
当 Scala 编译器在匹配类型时,如果找不到合适的类型,就会在作用域中查找是否有可用的隐式值(implicit value),自动完成匹配。
隐式值(implicit value):
是指用 implicit 修饰的变量或常量。
隐式参数(implicit parameter):
是方法定义中标记为 implicit 的参数。
当调用方法时,如果没有显式传入这些参数,编译器会自动在当前作用域中寻找相应的隐式值并传入。
注意事项:
- 同一作用域中,同类型的隐式值只能出现一次。
implicit关键字必须出现在参数定义最前面。- 如果方法只有一个隐式参数,可以直接创建类型实例而不显式传参。
- 如果方法有多个参数,其中部分需要隐式转换,必须使用柯里化(Currying),并且
implicit参数必须出现在最后一组参数中,只能出现一次。
示例:
object ImplicitValueExample {
def Student(age: Int)(implicit name: String, score: Int): Unit = {
println(s"Student: $name, age = $age, score = $score")
}
def Teacher(implicit name: String): Unit = {
println(s"Teacher name is $name")
}
def main(args: Array[String]): Unit = {
implicit val studentName = "Ezekielx"
implicit val studentScore = 100
Student(18)
Teacher
}
}
运行结果:
Student: Ezekielx, age = 18, score = 100
Teacher name is Ezekielx
2. 隐式转换函数(Implicit Conversion Functions)
隐式转换函数是使用 implicit 修饰的函数。
当编译器在某类型上调用不存在的方法时,会自动在作用域中寻找合适的隐式函数,将该类型转换为包含该方法的另一类型。
换句话说:
如果对象 A 没有某方法,而对象 B 有该方法,并且存在一个 隐式函数 能将 A 转换为 B,那么 Scala 编译器会自动调用该函数,从而让 A 也能调用这个方法。
注意:
隐式转换函数只与参数类型和返回类型相关,与函数名无关。
因此,在同一作用域内不能定义两个参数类型相同、返回类型不同的隐式函数。
示例:
class Animal(name: String) {
def canFly(): Unit = {
println(s"$name can fly...")
}
}
class Rabbit(xname: String) {
val name = xname
}
object ImplicitFunctionExample {
implicit def rabbitToAnimal(rabbit: Rabbit): Animal = {
new Animal(rabbit.name)
}
def main(args: Array[String]): Unit = {
val rabbit = new Rabbit("Rabbit")
rabbit.canFly()
}
}
运行结果:
Rabbit can fly...
这里,Rabbit 类型并没有 canFly() 方法,但编译器在作用域内找到隐式转换函数 rabbitToAnimal,自动将 Rabbit 转换成 Animal,因此能调用 canFly()。
3. 隐式类(Implicit Class)
用 implicit 修饰的类称为隐式类。当某个类型的变量没有特定的方法或属性时,如果存在与该类型对应的隐式类,Scala 会自动创建该类的实例,从而“扩展”该类型的功能。
注意事项:
- 隐式类必须定义在 类、伴生对象(companion object) 或 包对象(package object) 中。
- 隐式类的构造函数只能有 一个参数。
- 同一个作用域中,不能定义多个针对同一类型的隐式类。
示例:
class Rabbit(name: String) {
val n = name
}
object ImplicitClassExample {
implicit class Animal(rabbit: Rabbit) {
val tp = "Animal"
def canFly(): Unit = {
println(rabbit.n + " can fly...")
}
}
def main(args: Array[String]): Unit = {
val rabbit = new Rabbit("Rabbit")
rabbit.canFly()
println(rabbit.tp)
}
}
运行结果:
Rabbit can fly...
Animal
这里,Rabbit 类本身并没有 canFly() 方法或 tp 属性。但通过隐式类 Animal,编译器在编译时自动为 Rabbit 类型添加了这些功能。
3、Pattern Matching(模式匹配)
概念理解:
Scala 提供了一种功能强大的模式匹配机制(Pattern Matching),在开发中被广泛使用。
模式匹配由一系列分支组成,每个分支以关键字 case 开头。
每个分支包含一个匹配模式(pattern)和一个或多个表达式(expression),两者之间用箭头符号 => 分隔。
注意事项:
- 模式匹配不仅可以匹配值(value),也可以匹配类型(type)。
- Scala 按从上到下的顺序进行匹配,一旦匹配成功,就不会再继续向下匹配。
- 如果没有任何分支匹配成功,就会执行
case _,相当于 Java 的default分支。 - 在语法上,最外层的
{}可以省略,直接将match结构作为一个语句使用。
示例代码:
object Lesson_Match {
def main(args: Array[String]): Unit = {
// 定义一个包含多种类型的元组
val tuple = (1, 2, 3f, 4, "ABC", 55d) // 实际类型:Tuple6(Int, Int, Float, Int, String, Double)
// 通过迭代器遍历元组中的每个元素
val tupleIterator = tuple.productIterator
while (tupleIterator.hasNext) {
matchTest(tupleIterator.next())
}
}
// 定义模式匹配函数
def matchTest(x: Any): Unit = {
x match {
case x: Int => println("type is Int")
case 1 => println("result is 1")
case 2 => println("result is 2")
case 3 => println("result is 3")
case 4 => println("result is 4")
case x: String => println("type is String")
case _: Float => println("type is Float")
case _: Double => println("type is Double")
case _ => println("no match")
}
}
}
代码说明:
-
tuple.productIterator将元组转换为迭代器,逐个取出元素进行匹配。 -
matchTest()函数中使用match ... case结构进行类型和值匹配:case x: Int:匹配所有整数类型(包括 1、2、3、4 之前的匹配)。case x: String:匹配字符串类型。case _: Float:匹配浮点数。case _: Double:匹配双精度浮点数。case _:兜底分支,当以上都不匹配时执行。
-
匹配是顺序执行的,所以
case x: Int会先捕获所有整数类型,后面的case 1、case 2等实际上不会执行到。若要优先匹配具体值,应将数值匹配的
case放在前面。
程序输出示例:
type is Int
type is Int
type is Float
type is Int
type is String
type is Double
4、Sample Class(样例类)
概念理解:
使用 case 关键字定义的类称为 样例类(case class),它是一种特殊的类。
样例类会自动为构造参数实现 getter 方法(构造参数默认是 val 类型)。如果构造参数被声明为 var,Scala 也会自动生成相应的 setter 和 getter。
样例类默认实现以下方法:
toString:用于打印对象内容equals:按字段值比较对象是否相等copy:快速复制对象hashCode:支持哈希集合存储
样例类对象可以用或不用 new 关键字创建。
示例:
case class Person1(name: String, age: Int)
object CaseClassExample {
def main(args: Array[String]): Unit = {
val p1 = new Person1("Ezekielx", 10)
val p2 = Person1("Tom", 20)
val p3 = Person1("Jerry", 30)
val list = List(p1, p2, p3)
list.foreach { x =>
x match {
case Person1("Ezekielx", 10) => println("Ezekielx")
case Person1("Tom", 20) => println("Tom")
case _ => println("no match")
}
}
}
}
说明:
-
定义样例类
Person1(name: String, age: Int),自动具备toString、equals、hashCode、copy等功能。 -
创建对象时可以写成:
val p2 = Person1("Tom", 20)
不需要加 new。
-
样例类支持 模式匹配(Pattern Matching)。
在上面的代码中,通过
match语句判断不同对象并输出结果。 -
程序运行输出:
Ezekielx Tom no match
5、Actor Model(Actor 模型)
概念理解:
Actor 模型(Actor Model) 用于编写并行计算(parallel computing)和分布式系统(distributed system)的高级抽象结构。
它与 Java 的线程(Thread)类似,但让程序员不必再担心**共享锁(shared lock)和多线程模式(multithreaded mode)**等复杂问题。
Actor 模型最早被用于 Erlang 语言,该语言以极高的可用性著称——每年可用率达 99.9999999%(即全年仅约 31 毫秒宕机时间)。
在该模型中,Actor 封装了状态(state)和行为(behavior),它们存在于轻量级的进程或线程中,但不会与其他 Actor 共享状态。每个 Actor 都有自己的 “世界观”(world view)。当它们需要与其他 Actor 交互时,是通过**发送事件或消息(event and message)**来完成的。
消息的发送是异步且非阻塞的(asynchronous and non-blocking)——也就是说,发送后无需等待回复,也不需要暂停执行(称为 “fire-and-forget” 机制)。
每个 Actor 都有一个自己的消息队列(message queue),传入的消息按**先进先出(FIFO)**顺序排列处理。
Actor 的特征:
- Actor 模型是基于消息传递的模型(messaging model),其核心特征就是“消息通信”。
- 消息发送是异步且非阻塞的(asynchronous and non-blocking)。
- 消息一旦发送成功,就不可更改(immutable after sending)。
- 在 Actor 之间传递消息时,是否检查或处理消息由 Actor 自身决定,这种机制是异步的、非阻塞的。
什么是 Akka?
Akka 是一个用 Scala 编写的库,用于简化编写容错(fault-tolerant)、**高扩展性(highly scalable)**的 Java 和 Scala Actor 模型应用程序。
它的底层实现基于 Actor 模型。Akka 既是一个开发库(development library),也是一个运行时环境(runtime environment),用于构建基于 JVM 的高并发、分布式、容错、事件驱动系统(event-driven system),使得开发此类系统更加简单高效。
在 Spark 1.6 之前,Spark 的分布式节点通信使用的就是 Akka(底层为 Actor 通信机制);从 1.6 版本之后,则改为使用 Netty 作为传输层(transport layer)。
**示例 1:**简单的 Actor 发送与接收消息:
import scala.actors.Actor
class myActor extends Actor {
def act() {
while (true) {
receive {
case x: String => println("get String = " + x)
case x: Int => println("get int")
case _ => println("get default")
}
}
}
}
object Lesson_Actor {
def main(args: Array[String]): Unit = {
// 创建 actor 并启动消息接收与传递
val actor = new myActor()
actor.start()
// 发送消息
actor ! "i love you !"
}
}
**示例 2:**Actor 之间的通信:
case class Message(actor: Actor, msg: Any)
class Actor1 extends Actor {
def act() {
while (true) {
receive {
case msg: Message => {
println("i save msg! = " + msg.msg)
msg.actor ! "i love you too !"
}
case msg: String => println(msg)
case _ => println("default msg!")
}
}
}
}
class Actor2(actor: Actor) extends Actor {
actor ! Message(this, "i love you !")
def act() {
while (true) {
receive {
case msg: String => {
if (msg.equals("i love you too !")) {
println(msg)
actor ! "could we have a date!"
}
}
case _ => println("default msg!")
}
}
}
}
object Lesson_Actor2 {
def main(args: Array[String]): Unit = {
val actor1 = new Actor1()
actor1.start()
val actor2 = new Actor2(actor1)
actor2.start()
}
}