
一、前言
上课直接做项目好无聊,写篇文章磨洋工😗。
Apache Hive 是一个分布式、容错的数据仓库系统,支持大规模分析,并利用 SQL 支持分布式存储中的 PB 级数据的读写和管理。
Hive 可以理解成把你写的 SQL,翻译成对大数据文件的处理任务的一个工具。
比如你把数据放在 HDFS 上,Hive 让你可以用这种 SQL 的方式查:
select user_id, count(*)
from orders
group by user_id;
而不是自己写 MapReduce、Spark、Tez 程序。
所以 Hive 的作用,不是 “存数据”(这是 HDFS 干的事),而是管理表,让你用 SQL 查大数据,记录表结构、分区、字段这些元数据(metadata)。
二、环境准备
Hive 是基于 Hadoop 的数据仓库工具,可以通过 SQL 操作大规模数据。
Hive 的前置环境,包括 VMWare 虚拟机下载和 Hadoop 伪集群配置,移步于:Hadoop 伪分布式集群环境配置 - 滕王阁 。
切换到运行 hadoop 的用户(我的就叫 hadoop):
su hadoop
三、安装 Hive
这里选择 Hive 3.1.3 版本。虽然当前 Hive 最新版为 4.0+,但还在更新中,所以选择较为稳定的 3.0+ 的最后这个版本。
Hive 官方下载地址:https://hive.apache.org/general/downloads/
选择历史版本下载。
这里再给一个百度网盘下载链接:
下载好后将软件压缩包上传至 Linux 虚拟机的 /opt/hadoop 目录下。
解压后删除软件包,重命名目录:
cd /opt/hadoop
tar -zxvf apache-hive-3.1.3-bin.tar.gz
rm -rf apache-hive-3.1.3-bin.tar.gz
mv apache-hive-3.1.3-bin/ hive-3.1.3
然后配置 Hive 的环境变量。
终端输入:
vim ~/.bashrc
按 i 进入编辑模式,添加:
export HIVE_HOME=/opt/hadoop/hive-3.1.3
export PATH=$PATH:$HIVE_HOME/bin
按 Esc,输入 :wq 回车保存并退出。
刷新环境变量:
source ~/.bashrc
四、在 MySQL 中创建 metastore 数据库和用户
1、什么是 metastore
metastore 翻译过来就是元数据仓库。它保存的不是你真正的数据内容(真正的数据保存在 HDFS),而是 “描述数据的数据”,也就是元数据。
比创建一张 Hive 表:
create table orders (
order_id string,
user_id string,
amount double
)
partitioned by (dt string);
Hive 会记住这些信息:表名叫 orders、这张表有哪些字段、字段类型是什么、分区字段是什么、数据文件实际放在哪个目录、这张表属于哪个 database、有没有外部表、内部表之类的属性🧐,而不是真正的数据。
2、为什么使用 MySQL 存放元数据
Hive 之所以常把元数据放在 MySQL 里,是因为它需要一个稳定的关系型数据库,来保存表结构、字段、分区和数据路径这类结构化信息。MySQL 成熟、易部署、运维成本低,所以在很多实际环境里都会拿它来做 metastore 的底层存储。
如果不用 MySQL,Hive 也不是就没法运行。Hive 的 metastore 本质上是把元数据持久化到一个关系型数据库里,官方文档说明它既可以使用内嵌的 Apache Derby,也可以连接外部的关系型数据库。官方文档参考:Apache Hive: AdminManual Metastore 3.0 管理 --- Apache Hive : AdminManual Metastore 3.0 Administration 。
3、安装 MySQL 数据库
Linux-CentOS Stream 安装 MySQL - 滕王阁 这是我之前写的,Rocky Linux 和 CentOS Stream 都是 RedHat 系的 Linux 发行版,所以都是通用的。
这里再简单赘述一遍。
在线安装 MySQL 数据库,命令行输入:
sudo yum localinstall https://dev.mysql.com/get/mysql84-community-release-el10-2.noarch.rpm
sudo yum install mysql-community-server
启动 MySQL 数据库:
sudo systemctl start mysqld
修改数据库密码策略
由于 MySQL 8.0+ 版本的设置,在安装时会自动分配一个复杂密码并且修改的密码也必须是复杂密码,改变密码策略为 "LOW" 还必须先设置一次复杂的初始密码😥。
查看 MySQL 第一次运行时生成的临时密码:
sudo grep "A temporary password" /var/log/mysqld.log
[ezekielx@RockyLinux ~]$ sudo grep "A temporary password" /var/log/mysqld.log
2026-04-02T02:24:46.106726Z 6 [Note] [MY-010454] [Server] A temporary password is generated for root@localhost: g=jcR<RLn3,r
[ezekielx@RockyLinux ~]$
比如这里我的临时密码就是:g=jcR<RLn3,r
现在将这个密码改为一个简单的密码。
使用 MySQL 的 root 用户登录 MySQL 命令行:
mysql -u root -p
设置一个复杂的初始密码:
ALTER USER 'root'@'localhost' IDENTIFIED BY 'Root123!';
在 MySQL 命令行中分别设置密码策略为 "LOW" 和最短密码长度为 6:
SET GLOBAL validate_password.policy=0;
set GLOBAL validate_password.length=6;
可以将 root 用户的密码改为一个简单密码来查看是否配置成功:
ALTER USER 'root'@'localhost' IDENTIFIED BY '123456';
创建 hive 数据库
创建数据库:
CREATE DATABASE hive;
创建了一个新的用于远程登录的 hive 用户:
CREATE USER 'hive'@'%' IDENTIFIED BY '123456';
GRANT ALL PRIVILEGES ON hive.* TO 'hive'@'%';
FLUSH PRIVILEGES;
退出 MySQL 命令行:
quit
安装 MySQL JDBC 驱动
Hive 远程连接 MySQL 作为元数据库需要安装 JDBC 驱动。官方文档参考:Apache Hive : AdminManual Metastore Administration 。
去 MySQL 官网下载页面(MySQL Community Downloads)下载 JDBC 驱动。
我这里直接下最新版的驱动了,感觉都不会有什么兼容性问题,你要是怕的话就选右边的 Archives,下 8.0+ 版本的。
选 tar.gz 还是 zip 都可以,这个不用上传 Linux,直接在物理机上解压。
打开下载的压缩包,找到 mysql-connector-j-9.6.0 这个 jar 文件,就要在一个上传虚拟机就可以了。
上传到 /opt/hadoop/hive-3.1.3/lib 目录。
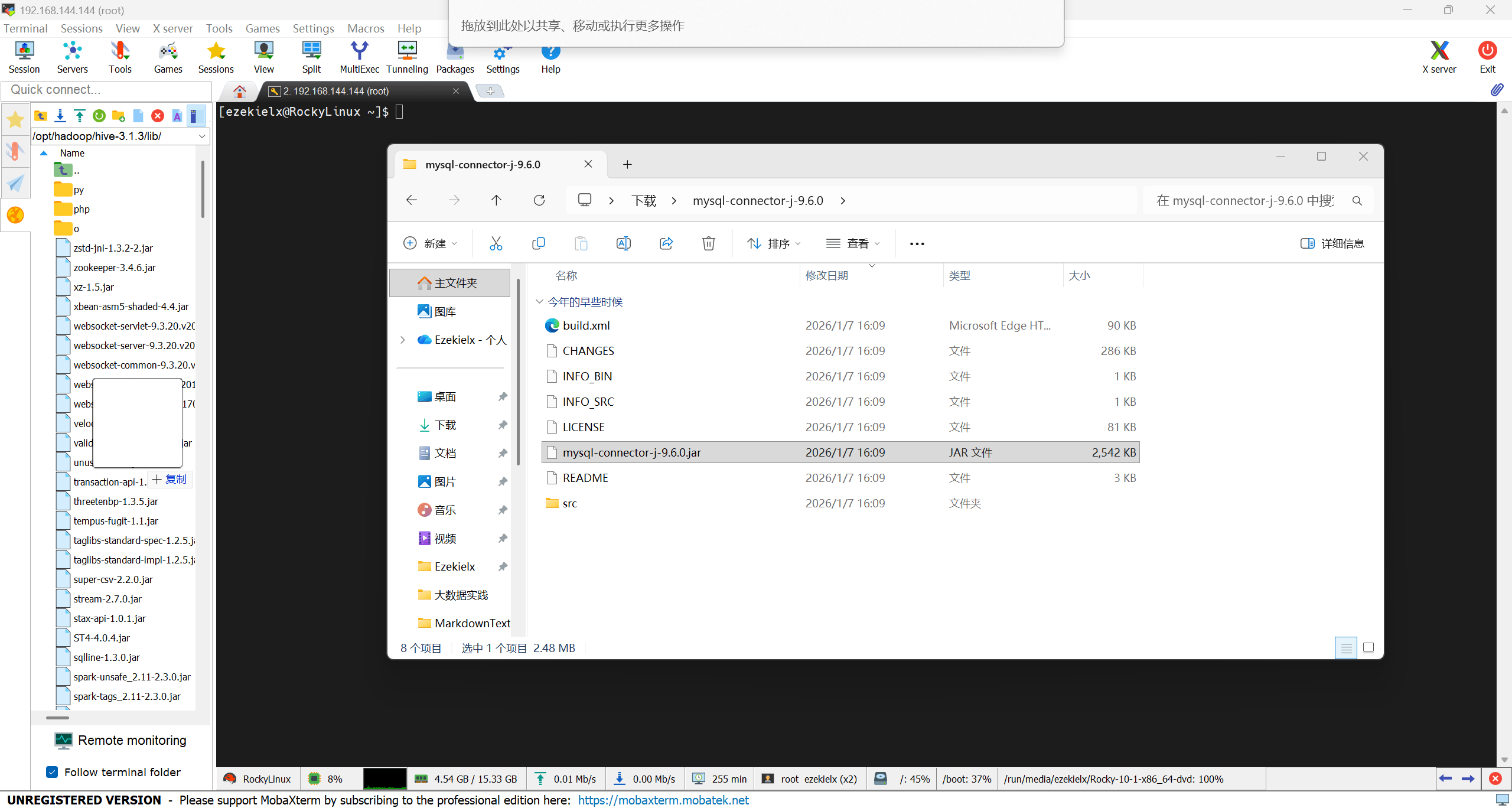
4、编辑 Hive 配置文件
创建配置文件:
vim /opt/hadoop/hive-3.1.3/conf/hive-site.xml
官方文档参考:Apache Hive : AdminManual Metastore Administration 。
添加以下内容:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!-- MySQL 连接地址 -->
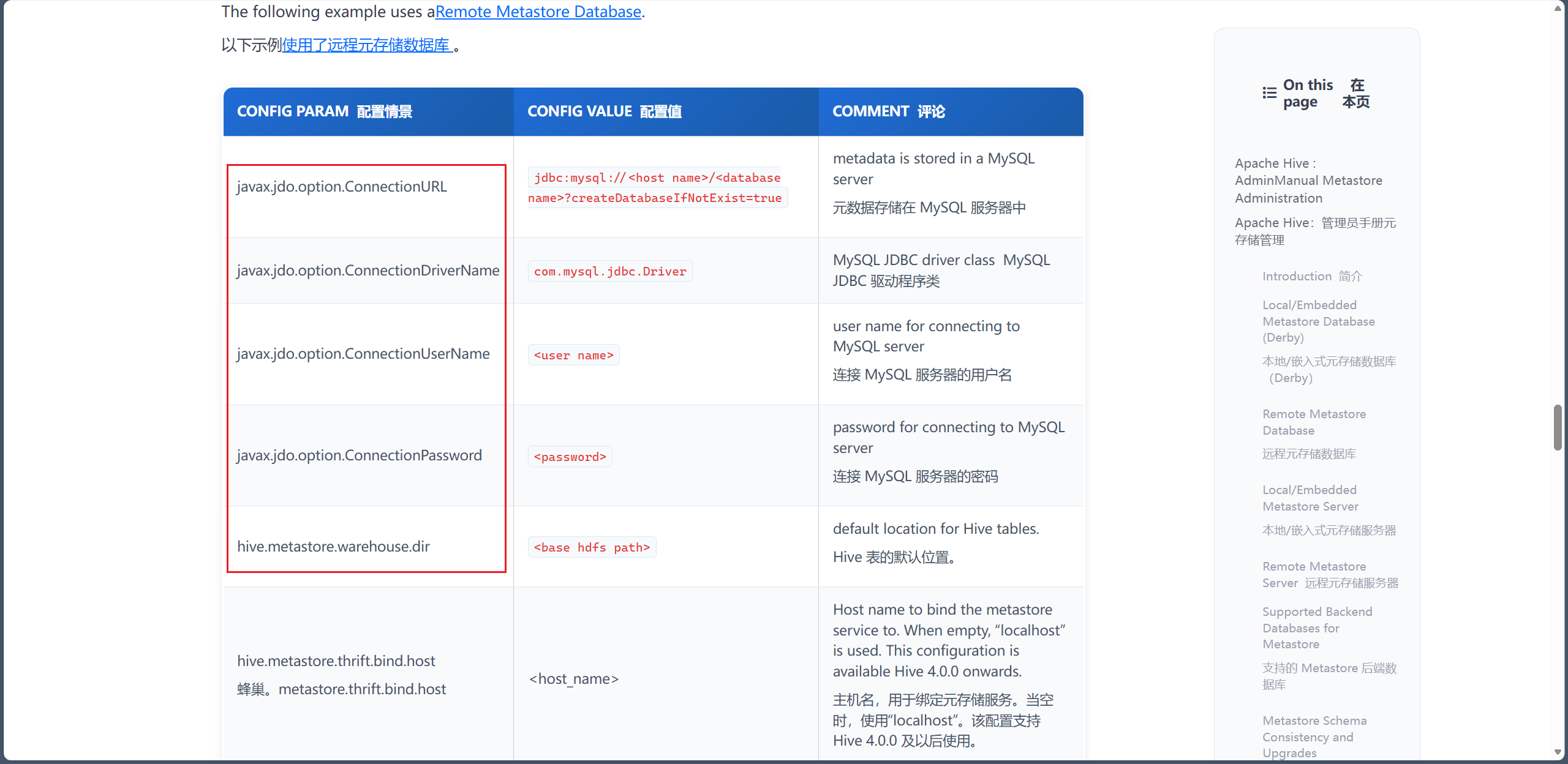
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://127.0.0.1:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<!-- MySQL JDBC 驱动类 -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<!-- MySQL 用户名 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<!-- MySQL 密码 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!-- Hive 默认仓库目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
</configuration>
5、初始化 schema
第一次启用外部数据库作为 metastore 时,必须执行 schematool 初始化 schema。
schematool -dbType mysql -initSchema
[hadoop@RockyLinux ~]$ schematool -dbType mysql -initSchema
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hadoop/hive-3.1.3/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop/hadoop-3.3.6/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Metastore connection URL: jdbc:mysql://127.0.0.1:3306/hive?createDatabaseIfNotExist=true
Metastore Connection Driver : com.mysql.cj.jdbc.Driver
Metastore connection User: hive
Starting metastore schema initialization to 3.1.0
Initialization script hive-schema-3.1.0.mysql.sql
Initialization script completed
schemaTool completed
[hadoop@RockyLinux ~]$
配置 Hadoop 允许代理用户访问
Hadoop 代理访问机制
如果此时直接使用 beeline -u jdbc:hive2://localhost:10000 -n hadoop 连接 HiveServer2 出现如下错误:
Failed to open new session: java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: hadoop is not allowed to impersonate hadoop (state=08S01,code=0)
这是由于 Hadoop 的代理用户(Proxy User / Impersonation)机制校验失败。
HiveServer2 在默认配置下会开启:
hive.server2.enable.doAs=true
这意味着:HiveServer2 会以客户端用户身份去执行任务(即代理用户)。
HiveServer2(服务进程用户)
↓ impersonate
客户端用户(这里是 hadoop)
而 Hadoop 出于安全考虑,默认不允许任何用户随意 impersonate(代理)其他用户。
官方文档参考:Apache Hadoop 3.5.0 – Proxy user - Superusers Acting On Behalf Of Other Users
所以需要在 Hadoop 中明确授权:允许 hadoop 用户进行代理操作。
允许本机 hadoop 用户代理访问 Hadoop
vim $HADOOP_HOME/etc/hadoop/core-site.xml
添加如下配置:
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>RockyLinux</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>hadoop</value>
</property>
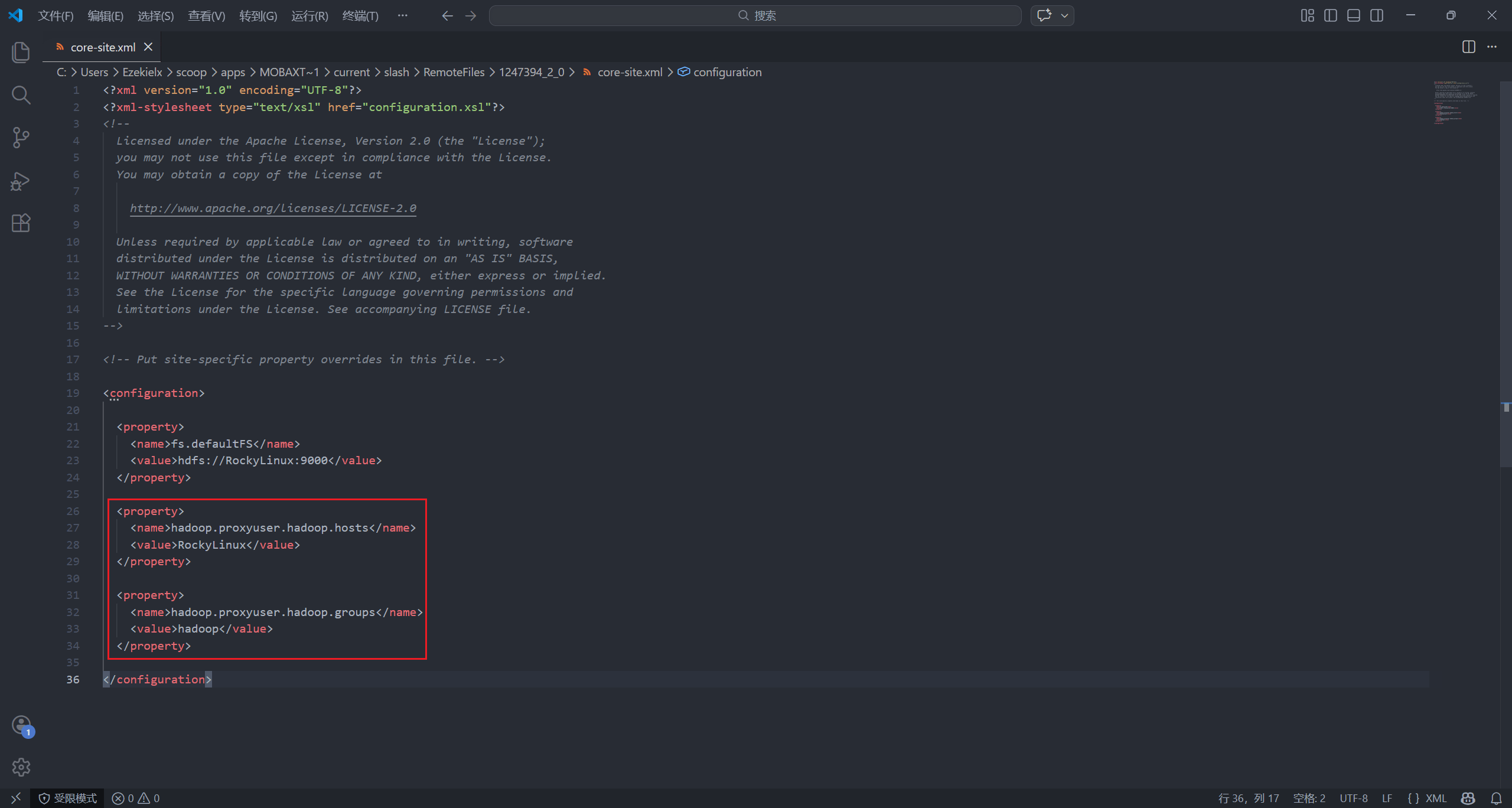
hadoop.proxyuser.hadoop.hosts:允许从哪些主机发起代理hadoop.proxyuser.hadoop.groups:允许代理哪些用户组
这是编辑 Hadoop 配置允许 hadoop 用户代理访问的方法。
还有一种修改 Hive 配置的方法,编辑
hive-site.xml,添加:<property> <name>hive.server2.enable.doAs</name> <value>false</value> </property>这是直接禁止 HiveServer2 使用代理用户执行。
HiveServer2 使用代理用户是因为它本质是给很多用户用的,所以必须 “按用户身份执行任务”,但我们测试环境就一个用户,所以关了也不影响🥰。
重启 Hadoop
stop-dfs.sh
stop-yarn.sh
start-dfs.sh
start-yarn.sh
五、启动 Hive
启动 Metastore 服务
当 Hive 使用 MySQL 存储表结构等元数据时,并不是由客户端直接访问 MySQL,而是通过一个中间服务 Metastore 来完成。为了让多个客户端共享这些元数据,通常需要将 Metastore 单独启动为一个服务。
hive --service metastore
这个命令是前台运行的,如果后台运行改为下面命令:
nohup hive --service metastore > metastore.log 2>&1 &
运行输出日志文件会生成到当前目录下的 metastore.log 文件,建议先 cd ~ 进入 hadoop 用户的家目录,将日志文件生成在这里🦈。
[hadoop@RockyLinux ~]$ nohup hive --service metastore > metastore.log 2>&1 &
[1] 145126
[hadoop@RockyLinux ~]$
上述命令会启动一个 基于 Thrift 协议的 Metastore 服务,默认监听端口为 9083。
在远程 Metastore 架构中,Hive 的访问路径如下:
Hive Client <--Thrift--> Metastore Server --> MySQL
比如以 SHOW TABLES 为例:
- Hive 客户端发起请求
- 通过 Thrift 协议调用 Metastore 接口
- Metastore 查询 MySQL 中的元数据
- 返回结果给客户端
Hive 不直接操作 MySQL 且所有元数据访问都经过 Metastore。
启动 HiveServer2
HiveServer2 为 Hive 的服务端,用于执行 SQL 查询服务,有自己的客户端命令行工具 Beeline。
旧版本的 HiveCLI 现已被 Beeline 取代,因为它缺乏 HiveServer2 的多用户、安全性及其他功能。
运行 HiveServer2:
hive --service hiveserver2
同样的,后台运行改为:
nohup hive --service hiveserver2 > hiveserver2.log 2>&1 &
[hadoop@RockyLinux ~]$ nohup hive --service hiveserver2 > hiveserver2.log 2>&1 &
[2] 145284
[hadoop@RockyLinux ~]$
运行 Beeline:
beeline -u jdbc:hive2://localhost:10000 -n hadoop
[hadoop@RockyLinux ~]$ beeline -u jdbc:hive2://localhost:10000 -n hadoop
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hadoop/hive-3.1.3/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop/hadoop-3.3.6/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Connecting to jdbc:hive2://localhost:10000
Connected to: Apache Hive (version 3.1.3)
Driver: Hive JDBC (version 3.1.3)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 3.1.3 by Apache Hive
0: jdbc:hive2://localhost:10000>
这样就成功了😋。